本文主要是介绍SparkListener血缘——Openlineage插件实现思路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、SparkListener
- 1.1 源码剖析
- 1.2 Listener 提供的方法
- 二、OpenLineage 的SparkListener插件实现
- 2.1 初始化参数
- 2.2 类加载信息
- 2.3 触发执行
- 2.4 逻辑计划解析
- 2.5 获取元数据
- 三、Visitor的具体实现思路(后续)
- 四、总结
一、SparkListener
1.1 源码剖析
Spark listener主要用于监控Spark应用程序的各项活动,SparkListener可以通过注册到ListenerBus实现事件的监听。只要在启动Spark 时参数加上"spark.extraListeners",spark就会通过Utils.classForName解析并植入我们实现的Listener。
private def setupAndStartListenerBus(): Unit = {// Use reflection to instantiate listeners specified via `spark.extraListeners`try {val listenerClassNames: Seq[String] =conf.get("spark.extraListeners", "").split(',').map(_.trim).filter(_ != "")for (className <- listenerClassNames) {// Use reflection to find the right constructorval constructors = {val listenerClass = Utils.classForName(className)listenerClass.getConstructors.asInstanceOf[Array[Constructor[_ <: SparkListenerInterface]]]}val constructorTakingSparkConf = constructors.find { c =>c.getParameterTypes.sameElements(Array(classOf[SparkConf]))}lazy val zeroArgumentConstructor = constructors.find { c =>c.getParameterTypes.isEmpty}val listener: SparkListenerInterface = {if (constructorTakingSparkConf.isDefined) {constructorTakingSparkConf.get.newInstance(conf)} else if (zeroArgumentConstructor.isDefined) {zeroArgumentConstructor.get.newInstance()} else {throw new SparkException(s"$className did not have a zero-argument constructor or a" +" single-argument constructor that accepts SparkConf. Note: if the class is" +" defined inside of another Scala class, then its constructors may accept an" +" implicit parameter that references the enclosing class; in this case, you must" +" define the listener as a top-level class in order to prevent this extra" +" parameter from breaking Spark's ability to find a valid constructor.")}}listenerBus.addListener(listener)logInfo(s"Registered listener $className")}} catch {case e: Exception =>try {stop()} finally {throw new SparkException(s"Exception when registering SparkListener", e)}}listenerBus.start()
listenerBus 是所有listern的总线,start方法会启动listenerThread线程,在有事件进入时,会把事件传递给所有已经注册的listener
/** Post the application start event */private def postApplicationStart() {// Note: this code assumes that the task scheduler has been initialized and has contacted// the cluster manager to get an application ID (in case the cluster manager provides one).listenerBus.post(SparkListenerApplicationStart(appName, Some(applicationId),startTime, sparkUser, applicationAttemptId, schedulerBackend.getDriverLogUrls))}
上述代码事例描述了App启动时,listenerBus 传递event(事件)的过程。post方法会将event先塞入队列,然后listenerThread会循环拿取event,并且根据类型判断应该触发所有已注册监听器的哪个方法。
protected override def doPostEvent(listener: StreamingListener,event: StreamingListenerEvent): Unit = {event match {case receiverStarted: StreamingListenerReceiverStarted =>listener.onReceiverStarted(receiverStarted)case receiverError: StreamingListenerReceiverError =>listener.onReceiverError(receiverError)case receiverStopped: StreamingListenerReceiverStopped =>listener.onReceiverStopped(receiverStopped)case batchSubmitted: StreamingListenerBatchSubmitted =>listener.onBatchSubmitted(batchSubmitted)case batchStarted: StreamingListenerBatchStarted =>listener.onBatchStarted(batchStarted)case batchCompleted: StreamingListenerBatchCompleted =>listener.onBatchCompleted(batchCompleted)case outputOperationStarted: StreamingListenerOutputOperationStarted =>listener.onOutputOperationStarted(outputOperationStarted)case outputOperationCompleted: StreamingListenerOutputOperationCompleted =>listener.onOutputOperationCompleted(outputOperationCompleted)case _ =>}}
1.2 Listener 提供的方法
@DeveloperApi
abstract class SparkListener extends SparkListenerInterface {override def onStageCompleted(stageCompleted: SparkListenerStageCompleted): Unit = { }override def onStageSubmitted(stageSubmitted: SparkListenerStageSubmitted): Unit = { }override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = { }override def onTaskGettingResult(taskGettingResult: SparkListenerTaskGettingResult): Unit = { }override def onTaskEnd(taskEnd: SparkListenerTaskEnd): Unit = { }override def onJobStart(jobStart: SparkListenerJobStart): Unit = { }override def onJobEnd(jobEnd: SparkListenerJobEnd): Unit = { }override def onEnvironmentUpdate(environmentUpdate: SparkListenerEnvironmentUpdate): Unit = { }override def onBlockManagerAdded(blockManagerAdded: SparkListenerBlockManagerAdded): Unit = { }override def onBlockManagerRemoved(blockManagerRemoved: SparkListenerBlockManagerRemoved): Unit = { }override def onUnpersistRDD(unpersistRDD: SparkListenerUnpersistRDD): Unit = { }override def onApplicationStart(applicationStart: SparkListenerApplicationStart): Unit = { }override def onApplicationEnd(applicationEnd: SparkListenerApplicationEnd): Unit = { }override def onExecutorMetricsUpdate(executorMetricsUpdate: SparkListenerExecutorMetricsUpdate): Unit = { }override def onExecutorAdded(executorAdded: SparkListenerExecutorAdded): Unit = { }override def onExecutorRemoved(executorRemoved: SparkListenerExecutorRemoved): Unit = { }override def onBlockUpdated(blockUpdated: SparkListenerBlockUpdated): Unit = { }override def onOtherEvent(event: SparkListenerEvent): Unit = { }
}
二、OpenLineage 的SparkListener插件实现
openlineage相关介绍可以参见我的专栏
Openlineage数据地图
2.1 初始化参数
OpenLineage的Spark监听器实现代码类为io.openlineage.spark.agent.OpenLineageSparkListener,每次在监听器初始化时,都会从Spark Conf 中拿取对应的参数,参数主要包含解析血缘完成后,需要发送的目标信息(比如发送给kafka的server地址或者是http通信的url)
@Overridepublic void onApplicationStart(SparkListenerApplicationStart applicationStart) {initializeContextFactoryIfNotInitialized();}private void initializeContextFactoryIfNotInitialized() {if (contextFactory != null || isDisabled) {return;}SparkEnv sparkEnv = SparkEnv$.MODULE$.get();if (sparkEnv != null) {try {ArgumentParser args = ArgumentParser.parse(sparkEnv.conf());contextFactory = new ContextFactory(new EventEmitter(args));··· ······ ···// how argument parser workspublic static ArgumentParser parse(SparkConf conf) {ArgumentParserBuilder builder = ArgumentParser.builder();adjustDeprecatedConfigs(conf);conf.setIfMissing(SPARK_CONF_DISABLED_FACETS, DEFAULT_DISABLED_FACETS);conf.setIfMissing(SPARK_CONF_TRANSPORT_TYPE, "http");if (conf.get(SPARK_CONF_TRANSPORT_TYPE).equals("http")) {findSparkConfigKey(conf, SPARK_CONF_HTTP_URL).ifPresent(url -> UrlParser.parseUrl(url).forEach(conf::set));}findSparkConfigKey(conf, SPARK_CONF_APP_NAME).filter(str -> !str.isEmpty()).ifPresent(builder::appName);findSparkConfigKey(conf, SPARK_CONF_NAMESPACE).ifPresent(builder::namespace);findSparkConfigKey(conf, SPARK_CONF_JOB_NAME).ifPresent(builder::jobName);findSparkConfigKey(conf, SPARK_CONF_PARENT_RUN_ID).ifPresent(builder::parentRunId);builder.openLineageYaml(extractOpenlineageConfFromSparkConf(conf));return builder.build();注意这里的 extractOpenlineageConfFromSparkConf 方法主要是为了将conf解析成可以序列化的openLineageYaml类用于发送,见下述代码
/** Configuration for {@link OpenLineageClient}. */
public class OpenLineageYaml {@Getter@JsonProperty("transport")private TransportConfig transportConfig;@Getter@JsonProperty("facets")private FacetsConfig facetsConfig;
}
2.2 类加载信息
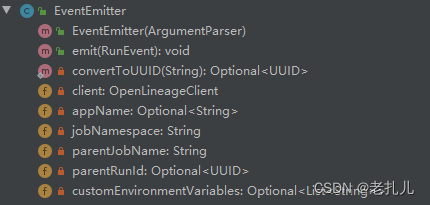
在listener初始化时,会生成EventEmitter类,该类会对openlineageyaml进行信息解析,生成具体的client通信类,用于发送给元数据地图或者是消息中间件(如kafka)
this.client =OpenLineageClient.builder().transport(new TransportFactory(argument.getOpenLineageYaml().getTransportConfig()).build()).disableFacets(disabledFacets).build();}
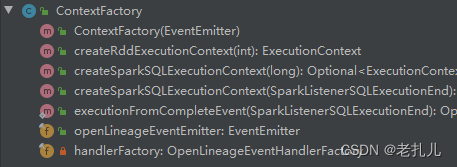
ContextFactory接收EventEmitter参数,并且根据spark环境识别spark版本(目前Openlineage支持Spark2,3的血缘解析),内部生成对应版本的VisitorFactory。VistoryFactory会根据spark 不同的版本加载访问器。
static VisitorFactory getInstance() {String version = package$.MODULE$.SPARK_VERSION();try {return (VisitorFactory) Class.forName(getVisitorFactoryForVersion(version)).newInstance();} catch (Exception e) {throw new RuntimeException(String.format("Can't instantiate visitor factory for version: %s", version), e);}}··· ······ ···static String getVisitorFactoryForVersion(String version) {if (version.startsWith("2.")) {return SPARK2_FACTORY_NAME;} else if (version.startsWith("3.2")) {return SPARK32_FACTORY_NAME;} else {return SPARK3_FACTORY_NAME;}}··· ······ ···private static final String SPARK2_FACTORY_NAME ="io.openlineage.spark.agent.lifecycle.Spark2VisitorFactoryImpl";private static final String SPARK3_FACTORY_NAME ="io.openlineage.spark.agent.lifecycle.Spark3VisitorFactoryImpl";private static final String SPARK32_FACTORY_NAME ="io.openlineage.spark.agent.lifecycle.Spark32VisitorFactoryImpl";
同时ContextFactory还负责创建 具体的ExecutionContext(每次触发监听事件都会在Registry的HashMap中更新一个Context),成员变量runEventBuilder(内含handlerFactory)主要用于处理分析Spark逻辑计划。runEventBuilder在初始化时,会注册元数据构造器,以及具体的Input/Output逻辑计划访问器(从handlerFactory中获取先前加载好的对应版本的访问器)。
public Optional<ExecutionContext> createSparkSQLExecutionContext(SparkListenerSQLExecutionEnd event) {return executionFromCompleteEvent(event).map(queryExecution -> {SparkSession sparkSession = queryExecution.sparkSession();OpenLineageContext olContext =OpenLineageContext.builder().sparkSession(Optional.of(sparkSession)).sparkContext(sparkSession.sparkContext()).openLineage(new OpenLineage(Versions.OPEN_LINEAGE_PRODUCER_URI)).queryExecution(queryExecution).customEnvironmentVariables(this.openLineageEventEmitter.getCustomEnvironmentVariables()).build();OpenLineageRunEventBuilder runEventBuilder =new OpenLineageRunEventBuilder(olContext, handlerFactory);return new SparkSQLExecutionContext(event.executionId(), openLineageEventEmitter, olContext, runEventBuilder);});}2.3 触发执行
当每次触发Listener的某个方法时,会生成RunEvent(RunEvent就是具体的元数据信息)。
拿 触发 onJobStart 方法举例,会自动初始化上述对象,并且去适配Context用以执行逻辑计划访问器:
@Overridepublic void onJobStart(SparkListenerJobStart jobStart) {if (isDisabled) {return;}initializeContextFactoryIfNotInitialized();Optional<ActiveJob> activeJob =asJavaOptional(SparkSession.getDefaultSession().map(sparkContextFromSession).orElse(activeSparkContext)).flatMap(ctx ->Optional.ofNullable(ctx.dagScheduler()).map(ds -> ds.jobIdToActiveJob().get(jobStart.jobId()))).flatMap(ScalaConversionUtils::asJavaOptional);Set<Integer> stages =ScalaConversionUtils.fromSeq(jobStart.stageIds()).stream().map(Integer.class::cast).collect(Collectors.toSet());if (sparkVersion.startsWith("3")) {jobMetrics.addJobStages(jobStart.jobId(), stages);}Optional.ofNullable(getSqlExecutionId(jobStart.properties())).map(Optional::of).orElseGet(() ->asJavaOptional(SparkSession.getDefaultSession().map(sparkContextFromSession).orElse(activeSparkContext)).flatMap(ctx ->Optional.ofNullable(ctx.dagScheduler()).map(ds -> ds.jobIdToActiveJob().get(jobStart.jobId())).flatMap(ScalaConversionUtils::asJavaOptional)).map(job -> getSqlExecutionId(job.properties()))).map(Long::parseLong).map(id -> getExecutionContext(jobStart.jobId(), id)).orElseGet(() -> getExecutionContext(jobStart.jobId())).ifPresent(context -> {// set it in the rddExecutionRegistry so jobEnd is calledactiveJob.ifPresent(context::setActiveJob);// startcontext.start(jobStart);});}
context.start方法是解析器的入口(p.s. 如果是监听器的End事件,那就对应context.end),调用runEventBuilder.run执行逻辑计划解析,这里只放入口代码,解析细节会在下小节深入:
@Overridepublic void start(SparkListenerSQLExecutionStart startEvent) {log.debug("SparkListenerSQLExecutionStart - executionId: {}", startEvent.executionId());if (!olContext.getQueryExecution().isPresent()) {log.info(NO_EXECUTION_INFO, olContext);return;} else if (EventFilterUtils.isDisabled(olContext, startEvent)) {log.info("OpenLineage received Spark event that is configured to be skipped: SparkListenerSQLExecutionStart");return;}RunEvent event =runEventBuilder.buildRun(buildParentFacet(),openLineage.newRunEventBuilder().eventTime(toZonedTime(startEvent.time())),buildJob(olContext.getQueryExecution().get()),startEvent);log.debug("Posting event for start {}: {}", executionId, event);eventEmitter.emit(event);}
2.4 逻辑计划解析
这里主要解释逻辑计划访问器拿取元数据信息的思路,先简略无关的入口代码
RunEvent event =runEventBuilder.buildRun(buildParentFacet(),openLineage.newRunEventBuilder().eventTime(toZonedTime(startEvent.time())),buildJob(olContext.getQueryExecution().get()),startEvent);
··· ···
··· ···RunEvent buildRun(Optional<ParentRunFacet> parentRunFacet,RunEventBuilder runEventBuilder,JobBuilder jobBuilder,SparkListenerSQLExecutionStart event) {runEventBuilder.eventType(RunEvent.EventType.START);return buildRun(parentRunFacet, runEventBuilder, jobBuilder, event, Optional.empty());}
··· ···
··· ···RunEvent buildRun(Optional<ParentRunFacet> parentRunFacet,RunEventBuilder runEventBuilder,JobBuilder jobBuilder,SparkListenerStageSubmitted event) {Stage stage = stageMap.get(event.stageInfo().stageId());RDD<?> rdd = stage.rdd();List<Object> nodes = new ArrayList<>();nodes.addAll(Arrays.asList(event.stageInfo(), stage));nodes.addAll(Rdds.flattenRDDs(rdd));return populateRun(parentRunFacet, runEventBuilder, jobBuilder, nodes);}
核心代码逻辑在 populateRun中,它负责包装元数据,拿取元数据信息,并且调用先前的RunEventBuilder注册好的访问器进行逻辑计划的解析。仅拿获取逻辑计划中的Input数据集举例,RunEventBuilder在类加载时拿取Visitor(访问器)的逻辑如下:
@Overridepublic Collection<PartialFunction<LogicalPlan, List<InputDataset>>>createInputDatasetQueryPlanVisitors(OpenLineageContext context) {List<PartialFunction<LogicalPlan, List<InputDataset>>> inputDatasets =visitorFactory.getInputVisitors(context);ImmutableList<PartialFunction<LogicalPlan, List<InputDataset>>> inputDatasetVisitors =ImmutableList.<PartialFunction<LogicalPlan, List<InputDataset>>>builder().addAll(generate(eventHandlerFactories,factory -> factory.createInputDatasetQueryPlanVisitors(context))).addAll(inputDatasets).build();context.getInputDatasetQueryPlanVisitors().addAll(inputDatasetVisitors);return inputDatasetVisitors;}每次触发监听时,populateRun 会调用handler 中的visitor 收取 Input数据集的逻辑(即map(inputVisitor)):
Function1<LogicalPlan, Collection<InputDataset>> inputVisitor =visitLogicalPlan(PlanUtils.merge(inputDatasetQueryPlanVisitors));List<InputDataset> datasets =Stream.concat(buildDatasets(nodes, inputDatasetBuilders),openLineageContext.getQueryExecution().map(qe ->fromSeq(qe.optimizedPlan().map(inputVisitor)).stream().flatMap(Collection::stream).map(((Class<InputDataset>) InputDataset.class)::cast)).orElse(Stream.empty())).collect(Collectors.toList());
2.5 获取元数据
populateRun 在获取完所有元数据后,会包装成一个RunEvent
private RunEvent populateRun(Optional<ParentRunFacet> parentRunFacet,RunEventBuilder runEventBuilder,JobBuilder jobBuilder,List<Object> nodes) {OpenLineage openLineage = openLineageContext.getOpenLineage();RunFacetsBuilder runFacetsBuilder = openLineage.newRunFacetsBuilder();OpenLineage.JobFacetsBuilder jobFacetsBuilder =openLineageContext.getOpenLineage().newJobFacetsBuilder();parentRunFacet.ifPresent(runFacetsBuilder::parent);OpenLineage.JobFacets jobFacets = buildJobFacets(nodes, jobFacetBuilders, jobFacetsBuilder);List<InputDataset> inputDatasets = buildInputDatasets(nodes);List<OutputDataset> outputDatasets = buildOutputDatasets(nodes);··· ······ ···return runEventBuilder.build();
最后调用emit方法,进行runEvent的元信息发送
public void emit(OpenLineage.RunEvent event) {try {this.client.emit(event);log.debug("Emitting lineage completed successfully: {}", OpenLineageClientUtils.toJson(event));} catch (OpenLineageClientException exception) {log.error("Could not emit lineage w/ exception", exception);}}
这里报红可以忽略,因为openlineage采用@slf4j注解,代码会在compile后生成
三、Visitor的具体实现思路(后续)
这块留个新坑,Vistor的主要逻辑就是Spark逻辑计划(树)的遍历操作,涉及到的内容会比较复杂,不同的插件遍历思路不一样,所以博主会先从Spark本身如何遍历逻辑计划来作铺垫,后续逐步拓展到每个插件Vistor的实现思路。
四、总结
后续还会介绍的有:Atlas 血缘插件实现思路、Spline血缘插件实现思路、数据血缘Antlr4解析、Atlas-Openlineage-Spline多系统元数据同步。欢迎大家留言评论~
这篇关于SparkListener血缘——Openlineage插件实现思路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






