本文主要是介绍数据血缘分析工具SQLFLow自动画出数据库的 ER 模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
马哈鱼数据血缘分析器通过分析你所提供的 SQL 脚本,或者连接到数据库,可以自动画出数据库的 ER 模型,可视化表和字段的关系,帮助你迅速了解数据库的设计模型,进行高效的团队沟通。
马哈鱼通过两种途径来为你自动可视化 ER 模型。
一、SQL 脚本
你只需要提供创建数据库的 SQL 脚本,马哈鱼数据血缘分析工具可以自动分析这些 SQL,然后把 SQL 脚本转化为可视化的 ER 模型。为了创建 ER Diagram,用户提供的 create table, alter table 等语句 SQL 脚本中需包含 foreign key。
二、连接数据库
你可以让马哈鱼数据血缘分析器连接到你的数据库,获取数据库中的元数据,然后自动可视化整个数据库的 ER 模型。
可视化 ER 模型的三种途径
下面我们介绍如何利用马哈鱼数据血缘分析工具来实现自动可视化数据库 ER 模型。
1. 直接把 SQL 语句 paste到编辑器中进行分析
Paste SQL 到马哈鱼数据血缘分析工具的编辑器中,
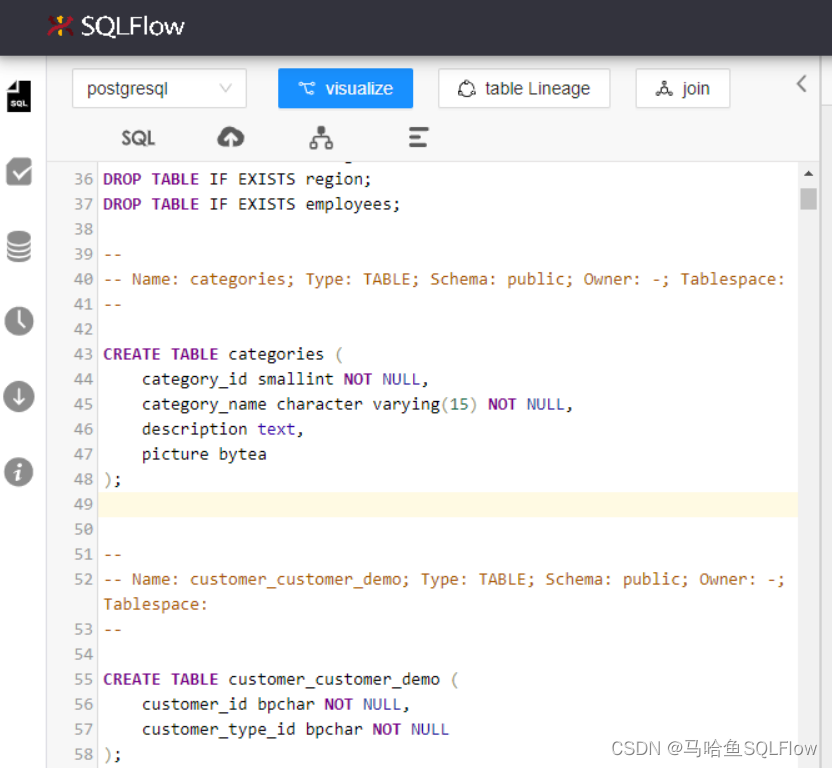
点击 ER 模型的图标,可以马上看到 ER 模型。
2. 上传 SQL 文件进行分析
点击 upload sql 图标
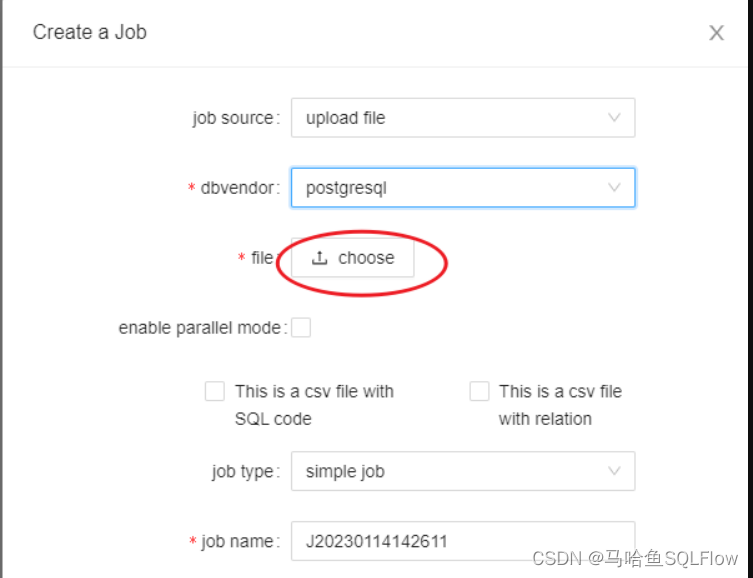
在 job source 下拉栏中选择 upload file, 在 dbvendor 中选择 SQL 所属的 数据库类型,上传 SQL 文件,
然后点击 OK 按钮创建该任务。
完成分析后,在 Job List 面板中,点击刚才创建的 Job,
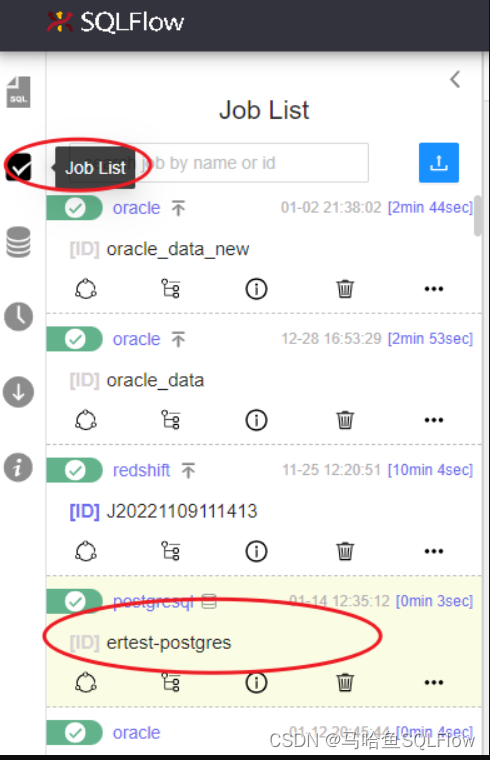
可以在 Schema explorer中选择 show ER diagram 查看结果。
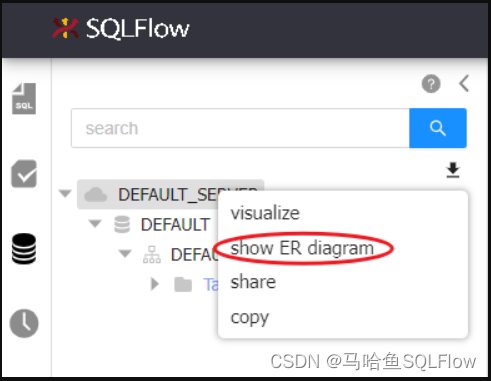
3. 连接数据库进行分析
通过输入数据库连接信息,连接需要获取 ER 模型的数据库,
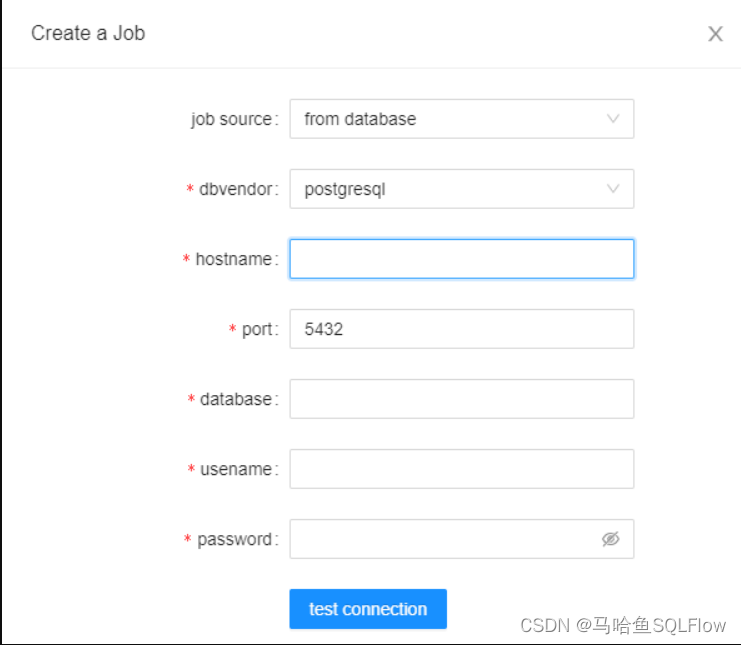
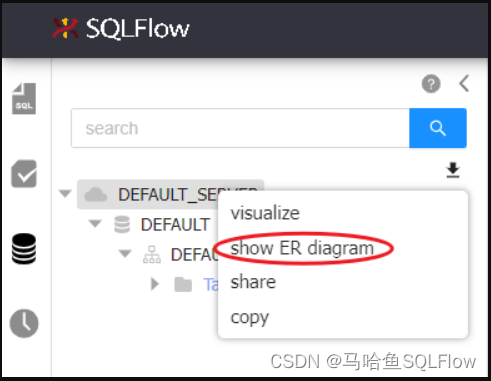
完成分析后,在 Job List 面板中,点击刚才创建的 Job,
可以在 Schema explorer中选择 show ER diagram 查看结果。
可视化 ER 模型的结果
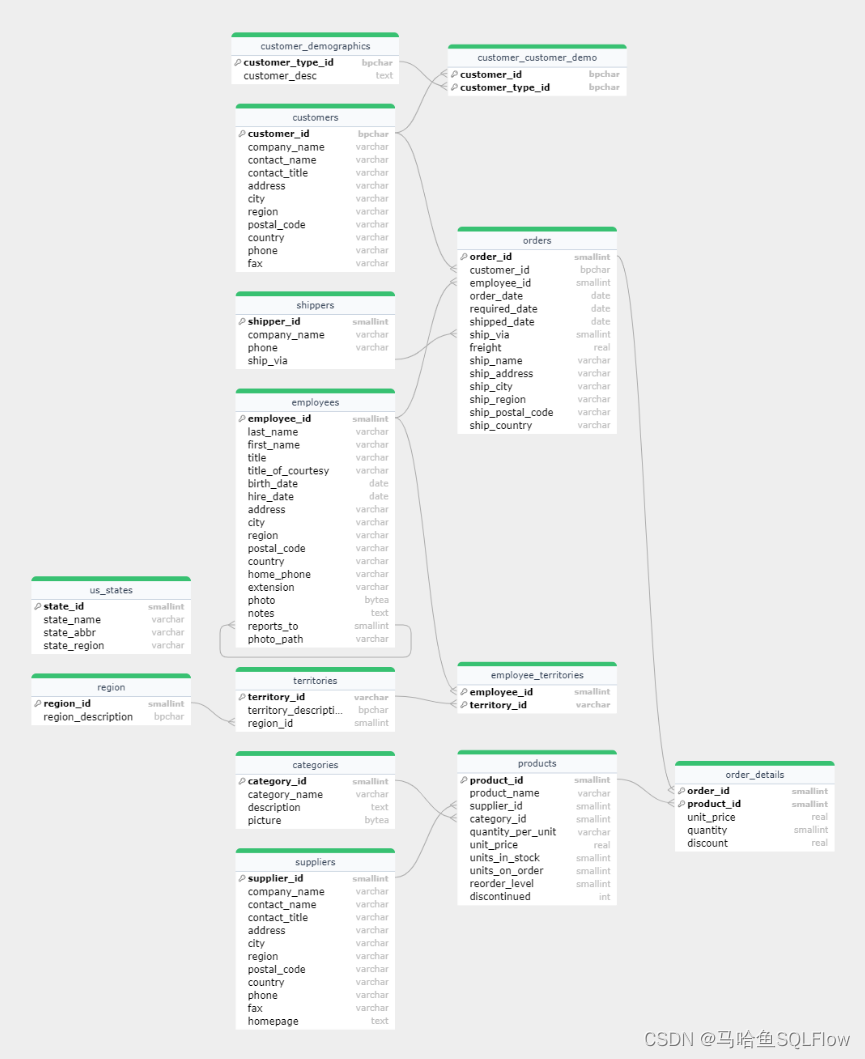
下图是马哈鱼数据血缘分析工具自动绘制的 Northwind database 的 ER 模型。可以看到 ER 模型中包含表、字段、字段的数据类型,以及用不同图标表示的不同类型的键(key)。
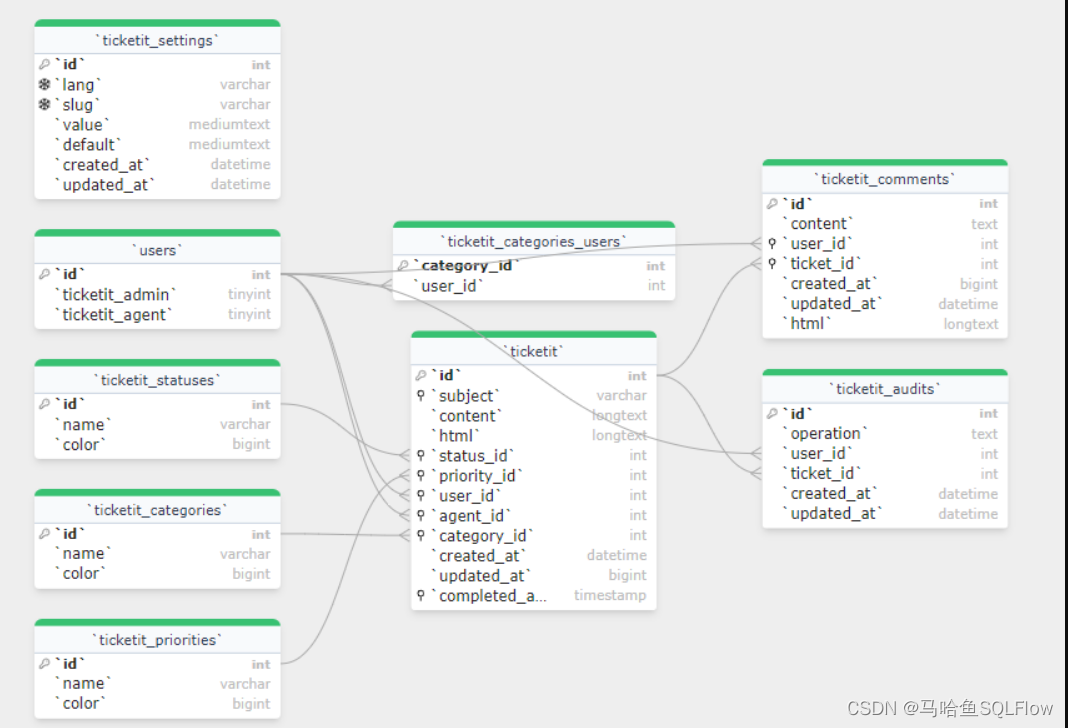
这是马哈鱼数据血缘分析工具分析了 SQL 文件后自动画出的 github 上一个简单票务系统的数据库 ER 模型图。
创建 ER Diagram 所需的 SQL
为了创建 ER Diagram,用户提供的 SQL 脚本需包含 foreign key ,其他的例如 primary key, index key, unique key 不是必须的。
A) Foreign key
Foreign key用来在各个表之间建立 ER 关联。通常在 create table 和 alter table 中包含这个信息。
1. foreign key in create table
CREATE TABLE SCOTT.EMP ( EMPNO NUMBER(4,0), ENAME VARCHAR2(10), DEPTNO NUMBER(2,0), CONSTRAINT PK_EMP PRIMARY KEY (EMPNO),FOREIGN KEY(DEPTNO) REFERENCES SCOTT.DEPT(DEPTNO)) ;
2. foreign key in alter table
ALTER TABLE SCOTT.EMP ADD CONSTRAINT FK_DEPTNO FOREIGN KEY ("DEPTNO")REFERENCES SCOTT.DEPT ("DEPTNO") ENABLE;
B) primary key, index key, unique key
1. 主键(primary key)
Primary key can be speicified in create table and alter table statement.
CREATE TABLE SCOTT.EMP ( EMPNO NUMBER(4,0), ENAME VARCHAR2(10), DEPTNO NUMBER(2,0), CONSTRAINT PK_EMP PRIMARY KEY (EMPNO),FOREIGN KEY(DEPTNO) REFERENCES SCOTT.DEPT(DEPTNO));
ALTER TABLE SCOTT.DEPT
ADD CONSTRAINT dept_pk PRIMARY KEY (DEPTNO);
Icon of primary key in ER diagram
2. 唯一键(unique key)
Unique key can be specified in create table and alter table statement.
CREATE TABLE SCOTT.DEPT (DEPTNO NUMBER(2,0), DNAME VARCHAR2(14), LOC VARCHAR2(13),CONSTRAINT constraint_name UNIQUE (DEPTNO)) ;
ALTER TABLE SCOTT.DEPT
ADD CONSTRAINT constraint_name UNIQUE (DEPTNO);
Icon of unique key in ER diagram
3. 索引键(index key)
Index key can be specified using create index statement.
-- Oracle
CREATE INDEX SCOTT.DEPT_INDEX
ON SCOTT.DEPT (LOC);
Or alter table add index-- MySQL
ALTER TABLE`ticketit` ADD INDEX `ticketit_subject_index`(`subject`);
Icon of index key in ER diagram
参考
马哈鱼数据血缘关系分析工具中文网站: https://www.sqlflow.cn
马哈鱼数据血缘关系分析工具英文网站: https://docs.gudusoft.com
马哈鱼数据血缘关系分析工具在线使用: https://sqlflow.gudusoft.com
这篇关于数据血缘分析工具SQLFLow自动画出数据库的 ER 模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







