本文主要是介绍【文献阅读】A synchronous deep reinforcement learning model for automated multi-stock trading,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 本文解决了什么问题/主要贡献有什么?
- 使用 深度信念网络(DBN) 提取金融数据规律并降低其维数。
- 扩展 synchronous multi-agent 深度强化算法,并利用 LSTM 作为 policy-based 和 value-based 算法的 actor-critic 控制器函数。
- 设计灵活的动作空间和相关的奖励计算,以适应不同(policy-based / value-based)强化学习算法的性质。
2 解决方法是什么?
2.1 Background
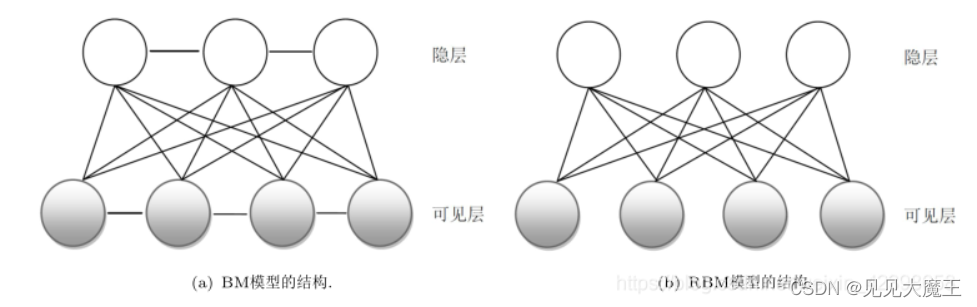
受限玻尔兹曼机 (RBM)
RBM 是一个浅层的两层神经网络,它学习以无监督的方式近似/重构输入数据。它的拓扑对应于一个对称的二分图,其中一组/层可见节点接收数据,而另一个集/层对从可见层提取的特征进行编码,约束条件是 同一层中的节点是条件独立的。RBM 构成了深度信念网络的构建块。
深度信念网络(Deep belief networks)
深度信念网络是一类特殊的深度神经网络,它是由简单的堆叠自动编码器或 RBM 组成的概率生成模型。DBN 中隐含层的联合分布如下:
P ( x , h 1 , h 2 , … , h l ) = P ( x ∣ h 1 ) P ( h 1 ∣ h 2 ) … P ( h l − 1 ∣ h l ) P\left(x, h_{1}, h_{2}, \ldots, h_{l}\right)=P\left(x \mid h_{1}\right) P\left(h_{1} \mid h_{2}\right) \ldots P\left(h_{l-1} \mid h_{l}\right) P(x,h1,h2,…,hl)=P(x∣h1)P(h1∣h2)…P(hl−1∣hl)
其中, x x x 为 DBN 的输入, h i h_i hi 为第 i i i 层的隐藏层。
基于上述等式,Hinton[引用] 提出了一种快速有效的无监督学习算法,该算法分别训练 DBN 中的每一层。
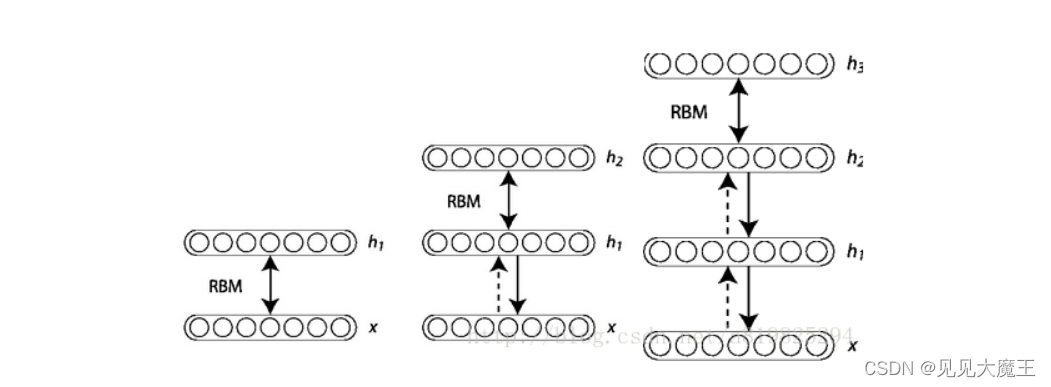
【预训练】逐层贪婪无监督训练[Bengio,2007] 为 DBN(由堆叠的 RBM 组成)提供了一种有效的贪婪逐层训练技术,可总结如下:
-
在每一层 i i i,可见层 v i v_i vi 接收输入向量并将其映射到隐藏层 ( h i h_i hi):
h i ( v i ) = σ ( W i v i + b i ) h_{i}\left(v_{i}\right)=\sigma\left(W_{i} v_{i}+b_{i}\right) hi(vi)=σ(Wivi+bi)
其中, W i W_i Wi 是隐藏层的权重, b i b_i bi 是隐藏层的偏置向量。 -
下一层通过将隐藏向量数据 h i ( v i ) h_i(v_i) hi(vi) 映射到下一个可见层来重构输入向量:
v i + 1 = σ ( W j h i ( v i ) + c j ) v_{i+1}=\sigma\left(W_{j} h_{i}\left(v_{i}\right)+c_{j}\right) vi+1=σ(Wjhi(vi)+cj)
其中,sigmoid 函数 σ \sigma σ 为:
σ ( t ) = 1 1 + e − t \sigma(t)=\frac{1}{1+e^{-t}} σ(t)=1+e−t1 -
优化函数最小化第 i i i 层的输入向量 v ( i ) v_{(i)} v(i) 与其重建 v ( i + 1 ) v_{(i+1)} v(i+1) 之间的误差,公式为:
Argmin W i , W j , b i , c j [ J ] = Argmin W i , W j , b i , c j [ 1 2 ∑ k = 1 n ∥ v i − v i + 1 ∥ 2 ] \begin{aligned} &\operatorname{Argmin}_{W i, W j, b i, c j}[J] =\operatorname{Argmin}_{W i, W j, b i, c j}\left[\frac{1}{2} \sum_{k=1}^{n}\left\|v_{i}-v_{i+1}\right\|^{2}\right] \end{aligned} ArgminWi,Wj,bi,cj[J]=ArgminWi,Wj,bi,cj[21k=1∑n∥vi−vi+1∥2]
更多相关介绍:https://www.cnblogs.com/jiangkejie/p/10720227.html
其中 J J J 是误差成本函数的二分之一平方, n n n 是训练数据集的大小。贪心无监督训练技术将最小化函数分别应用于每一层,从第一层开始使用训练数据集学习其参数 ( w 1 , w j 1 , b 1 , c j 1 ) \left(w_{1}, w_{j_{1}}, b_{1}, c_{j_{1}}\right) (w1,wj1,b1,cj1)。然后,它固定第一层的学习参数,并使用其输出数据 $ (v_{i+1})$ 作为第二层的训练数据集,并递归处理 DBN 中存在的尽可能多的层。
【微调训练】监督微调训练 由于每个 RBM 的权重是独立于下一层权重学习的,因此 DBN 需要一个有监督的训练阶段,其中应用反向传播技术来微调所有 DBN 层,使用无监督训练的权重作为初始权重。
2.2 Proposed deep reinforcement learning model
模型大致框架如下,它专门用于多股交易。每个交易日,模型都会自动输入从金融市场接收到的数据,根据这些数据,系统会为给定的多只股票生成交易决策(买入/持有/卖出)。然后,计算交易决策的回报,并应用反向传播学习技术来更新模型神经网络的权重。
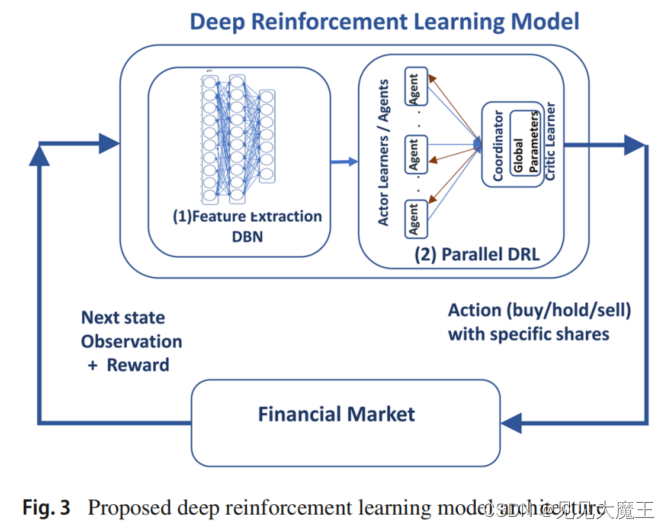
该模型主要包含两个部分:
- DBN. 从高维原始金融数据中提取降维判别特征。
- Multi-agent DRL module. 使用 DBN 提出处的特征作出决策。
模型的离线训练阶段基于以下假设:
- 交易决策在股票价格不变的情况下 立即执行(不考虑滑点等市场摩擦);
- 系统的交易决策 不会影响金融市场 上的股票价格。这个假设是通过使用少量的交易资金来实现的。
2.2.1 Raw financial data
作者使用以下金融数据:
- OHLCV data. 包含了开市价格、最高价格、最低价格、收市价格和成交量。
- Technical indicators. 根据 OHLCV 计算出的相关技术面因子。这里作者使用了开源的技术面分析软件 “TA_LIB”,该软件提供超过 200 个股票市场技术指标,分为七个不同的类别。
- Financial market indices. 它对应于一组股票的 OHLCV 数据的平均值,用于获取整个市场方向的指示,例如包含 30 只美国市场工业股票的“道琼斯工业平均指数”。
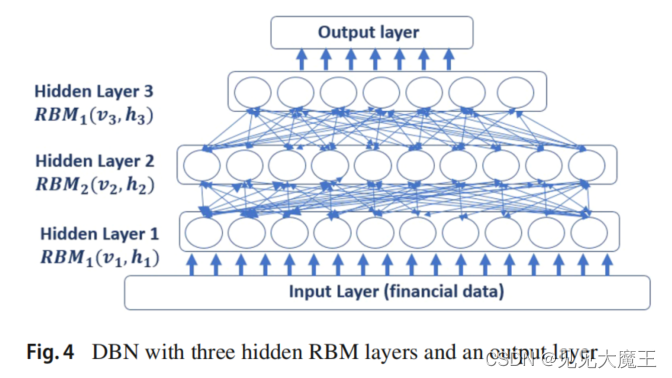
2.2.2 The DBN network
一部分负责从金融数据市场中提取高度不相关的特征。下图所示的 DBN 网络有 125 个输入,它们通过三个 RBM 隐藏层,分别具有(100、80、60)个神经元,以及一个具有 40 个神经元的输出层。
2.2.3 The deep reinforcement learning module
同步并行 DRL 技术依赖于一组 actors’ learners(agent)以及一个中央 critic learner。 critic learner 根据从每个 actor 的参数接收到的信息更新其全局参数,并为所有 actor 提供全局参数的最终版本。LSTM 被选为 actors 和 critic 的深度神经网络控制器。LSTM 能够学习序列财务数据中的长期依赖关系,记住 agent 的决策,并通过避免由于频繁的买卖决策而导致的不必要的交易成本 (TC) 来防止不必要的交易波动。
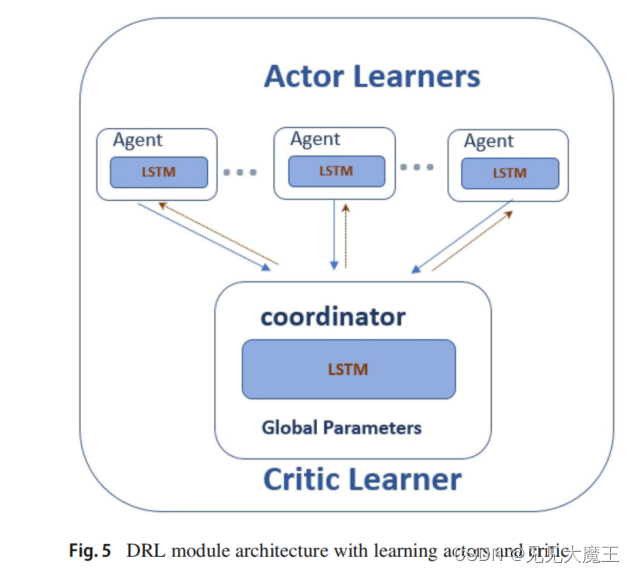
在本文中,作者使用两种不同的强化学习技术实现了同步并行 DRL。
- Synchronous Advantage Actor-Critic (A2C). 每个 actor 控制器函数都是一个三层网络,第一层是一个前馈层,由 40 个神经元组成,接收来自 DBN 网络的输入。第二层由 128 个 LSTM 单元组成,而 输出层有五个神经元,每个神经元在 [-1…1] 中生成一个连续值。critic 控制器函数也是一个三层的 5-128-1 前馈网络,它接收来自 actor 网络的五个输入,它的隐藏层有 128 个 LSTM 单元,它的输出有一个神经元来计算价值函数。
- Multi-step Q-learning algorithm. 每个 actor 控制器功能是一个三层网络,类似于 policy-based 的 actor 控制器,但 输出层由 21 个神经元组成。每个神经元根据它们在层中的顺序分别代表 {-1, -0.9, -0.8,…, -0.1, 0, 0.1,…, 1} 中的一个值。softmax 激活函数与输出层一起使用,以确保一次生成一个值。critic 控制器是类似于 policy-based 的 critic 控制器,但 第一层由 21 个神经元组成。
2.2.4 The action-domain Design
动作域根据所使用的 RL 技术而有所不同。value-based 的技术产生离散的动作,而 policy-based 的技术产生连续的动作,如下所述:
Value-based RL (DQN) technique
Value-based 模型一次交易一支股票。输出是一个离散的数值,并属于集合 { − 1 , − 0.9 , − 0.8 , … , − 0.1 , 0 , 0.1 , … , 1 } \{-1,-0.9,-0.8,\ldots,-0.1,0,0.1, \ldots, 1\} {−1,−0.9,−0.8,…,−0.1,0,0.1,…,1} 共有 21 个可能的动作。负值、正值或零值分别对应于卖出、买入或无操作。 例如,动作 “+0.9” 表示用 90% 的可用现金买入,而动作 “-0.5” 表示卖出 50% 的可用现金。如果该过程不适用则 agent 不执行任何操作,例如,动作是买入,但没有可用现金,或者动作是卖出,但不存在资产。
Policy-based RL (DDPG) technique
Policy-based 模型生成连续的动作,每个动作都位于区间 [-1…1] 中,其中 agent 可以使用离散动作过程的相同规则购买/出售资产的任何部分,例如动作 “+ 0.145” 表示用可用现金的 14.5% 购买所需的股票,动作 “-0.2” 表示出售可用资产的 20%。由于模型交易多只股票,因此系统输出是 [ − 1..1 ] n [-1 . .1]^{n} [−1..1]n 中的向量,其中 n n n 表示交易过程中的资产数量。因此,输出向量中的每个值都代表相应股票所需的操作。
首先执行销售流程以获得更多的交易现金,然后是购买流程。如果购买过程所需的现金少于可用现金的 100%,则按顺序执行购买动作;否则,购买金额首先被标准化,然后执行。最后,如果可用现金不足,则不执行购买过程。
例如,给定动作向量 [ 0 , 0.9 , − 0.2 , − 0.4 , 0.6 ] [0,0.9,-0.2,-0.4,0.6] [0,0.9,−0.2,−0.4,0.6],agent 将在第三维度和第四维度分别卖出 20% 和 40% 的股票,以增加用于购买过程的可用现金。因为购买所需的现金是可用现金的150%,所以购买金额被规范化为 60% 和 40%)。因此,agent 将分别用可用现金的 60% 和 40% 购买第二和第五股股票。如果用于执行购买过程的现金不足以完成购买过程,就不执行。当系统衡量其行为的适用性时,要考虑交易成本。按已交易股票数量的 0.5% 计算,最高不超过交易价值的 1%。
-
交易决定在股票价格不变的情况下立即执行;
-
系统的交易决定不会影响金融市场上的股票价格。这个假设是通过使用少量的交易资金来实现的
2.2.5 Reward calculation
假设 n n n, S t ∈ R n S_{t} \in R^{n} St∈Rn, P t ∈ R n P_{t} \in R^{n} Pt∈Rn 和 A v c t A v c_{t} Avct 分别代表交易股票的数量、系统拥有的股票数量、股票的收市价格和在时间 t t t 的可用现金。由此可以得出投资组合总价值 V t V_t Vt 为:
V t = A v c t + S t × P t V_{t}=A v c_{t}+S_{t} \times P_{t} Vt=Avct+St×Pt
在时间 t t t 的损益 P L t PL_t PLt 计算为时间 t t t 和 t − 1 t-1 t−1 的投资组合值之间的差:
P L t = V t − V t − 1 P L_{t}=V_{t}-V_{t-1} PLt=Vt−Vt−1
时间 t t t 的夏普比率 ( S R t SR_t SRt) 计算为在相同时间间隔内,根据所赚取收益的波动率(波动率由平均偏差表示)高于无风险收益 ( F R t FR_t FRt) 的平均收益时间间隔 δ δ δ 内的损益)。无风险收益由美国国库券 F R t FR_t FRt 的收益来衡量:
S R t = ∑ t ∈ 1 T ( P L t − F R t ) δ P L t ) S R_{t}=\frac{\sum_{t \in 1}^{T}\left(P L_{t}-F R_{t}\right)}{\left.\delta P L_{t}\right)} SRt=δPLt)∑t∈1T(PLt−FRt)
3 有什么关键实验结果?
3.1 Datasets used
使用“Yahoo Finance”下载 1980 年 1 月至 2020 年 1 月过去四十年的数据集。
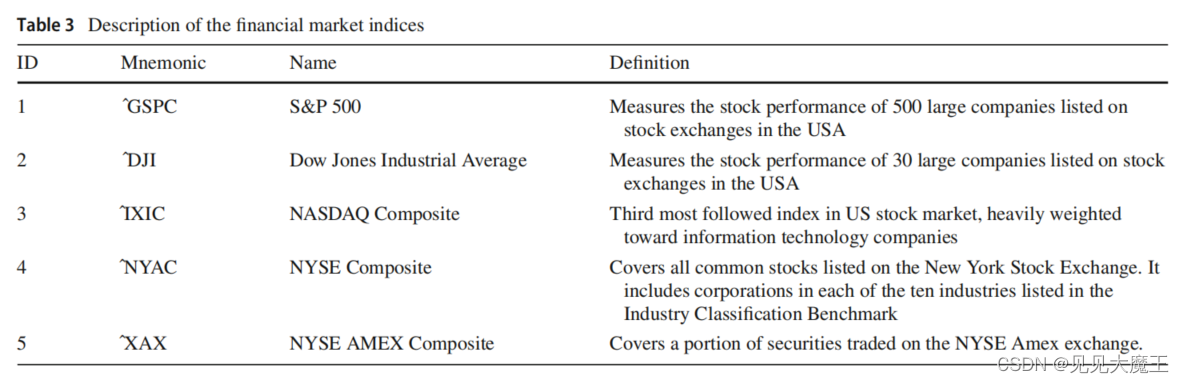
下面的表格是金融市场基准的选择。
3.2 Model setting
DBN 由一个接收 125 个输入特征的输入层、三个分别具有 100、80 和 60 个神经元的隐藏层和一个具有 40 个神经元的输出层组成。
每个 action-learner 和 critic-learner LSTM 神经网络控制器由 40 个输入(从 DBN 接收)、一个具有 128 个单元的隐藏层和一个具有基于运行模型的动作值数量的输出层(一个神经元用于单个股票 或 五个神经元用于五只股票交易)。

作者使用 OpenAI 框架实现以下算法:
- DBN-LSTM-DDPG-M 模型,以交易多股。该模型中的动作域是 [ − 1 … 1 ] n [-1 \ldots 1]^{n} [−1…1]n 中的向量。
- DBN-LSTM-DDPG-S 模型,以交易单股。该模型中的动作域是 [ − 1..1 ] [-1 . .1] [−1..1] 中的向量。该模型的损益计算为分别对五只股票运行该技术所产生的平均损益。
- DBN-LSTM-DQN 模型,以交易单股。
- DDPG-FF 模型。使用前馈 (FF) 控制器函数,具有一个具有 128 个神经元的隐藏层,直接馈入环境特征。
- Buy-Hold 策略。作为基准交易策略,在测试期开始时买入股票并持有至该期末,然后卖出,根据开始时的股价计算利润 和这个时期的结束。
作者使用下面五个 metrics 作为评估标准:
-
Accumulated Wealth Rate (AWR):
A W R T = ∑ t ∈ 1 T P L t A v c t = 0 \mathrm{AWR}_{T}=\frac{\sum_{t \in 1}^{T} P L_{t}}{A v c_{t=0}} AWRT=Avct=0∑t∈1TPLt -
Average Profifit Return (APR):
A P R T = ∑ t ∈ 1 T ( A W R t ) T \mathrm{APR}_{T}=\frac{\sum_{t \in 1}^{T}\left(A W R_{t}\right)}{T} APRT=T∑t∈1T(AWRt) -
Average Sharp Ratio (ASR) :
A S R T = ∑ t ∈ 1 T ( S R t ) T \mathrm{ASR}_{T}=\frac{\sum_{t \in 1}^{T}\left(S R_{t}\right)}{T} ASRT=T∑t∈1T(SRt) -
Average Maximum Draw Down (AMDD):
M D D t = ( max v t − min v t ) t ∈ T v T A M D D T = ∑ t ∈ 1 T ( M D D t ) T \begin{aligned} \mathrm{MDD}_{t} &=\frac{\left(\max v_{t}-\min v_{t}\right)_{t \in T}}{v_{T}} \\ \mathrm{AMDD}_{T} &=\frac{\sum_{t \in 1}^{T}\left(M D D_{t}\right)}{T} \end{aligned} MDDtAMDDT=vT(maxvt−minvt)t∈T=T∑t∈1T(MDDt) -
Average Calmar Ratio (ACR):
C R t = A P R t M D D t A C R T = ∑ t ∈ 1 T ( C R t ) T \begin{aligned} C R_{t} &=\frac{A P R_{t}}{M D D_{t}} \\ A C R_{T} &=\frac{\sum_{t \in 1}^{T}\left(C R_{t}\right)}{T} \end{aligned} CRtACRT=MDDtAPRt=T∑t∈1T(CRt) -
Annualized Terms (ARR: Annualized Return Rate and ANSR: ANnualized Sharp Ratio):
A R R T = ( 1 + A W R T ) ( 1 / T ) − 1 . \mathrm{ARR}_{T}=\left(1+A W R_{T}\right)^{(1 / T)}-1 \text {. } ARRT=(1+AWRT)(1/T)−1.ANSR t = ∑ t ∈ 1 T ( P L t − F R t ) δ ( P L T ) \operatorname{ANSR}_{t}=\frac{\sum_{t \in 1}^{T}\left(P L_{t}-F R_{t}\right)}{\delta\left(P L_{T}\right)} ANSRt=δ(PLT)∑t∈1T(PLt−FRt)
其中 T = 10 T = 10 T=10。
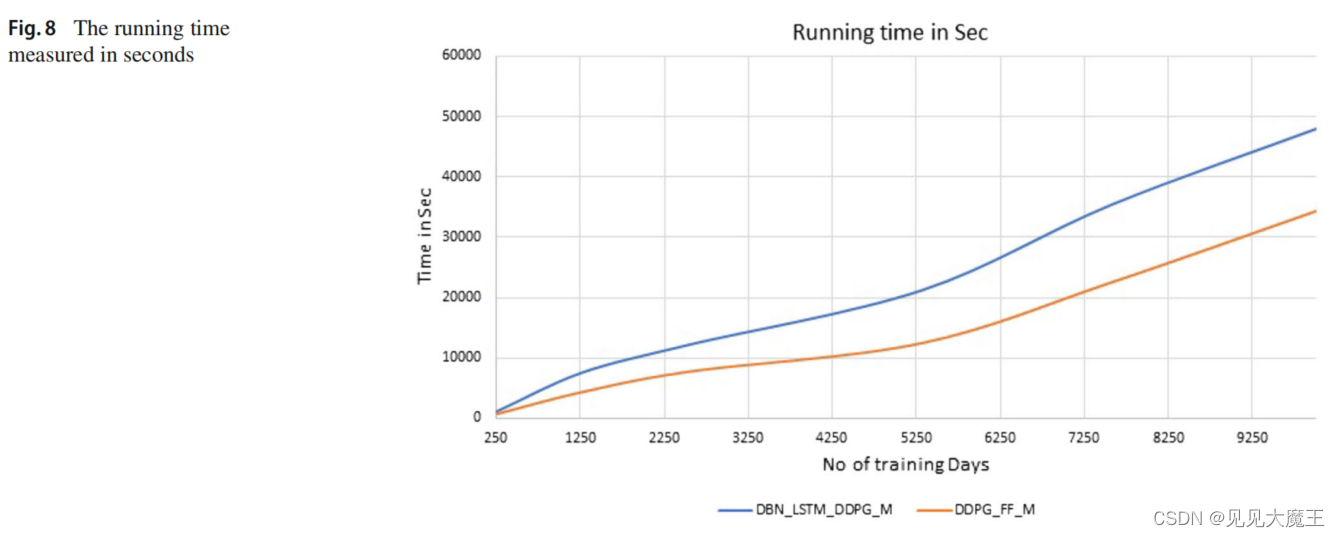
3.3 时间复杂度
为了估计 DBN 和 LSTM 神经网络结合强化学习技术引入的时间复杂度,使用30年的历史数据训练模型所需的时间,与移除 DBN 并将 LSTM 替换为一个由单个隐含层 (128个神经元) 前馈神经网络表示的控制器所需要的时间进行比较,该前馈神经网络直接由原始数据提供。
从图中可以看出,本文提出的多股 A2C 算法(带 DBN 和 LSTM)模型比普通(带 feed 正向神经网络的A2C算法)模型消耗的运行时间更大。正如预期的那样,运行时间随着训练数据集大小的增加而增加,但是框架的并行设计使消耗的时间可以接受。模型的训练首先在线下完成(offline),大约 13 个小时(针对30年的历史数据)。接下来,每天进行在线培训,只需要几分钟。
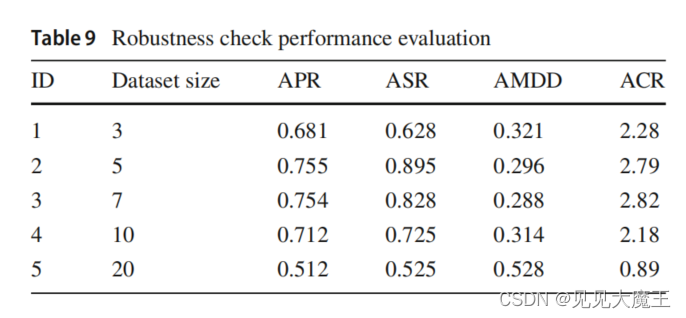
3.4 模型鲁棒性
从 20 只股票中随机选择不同的股票,考察业绩评价指标。结果表明,在5-10只股票之间选择股票数量可以获得更好的业绩。因此,使用 5 支股票似乎是合理的选择。
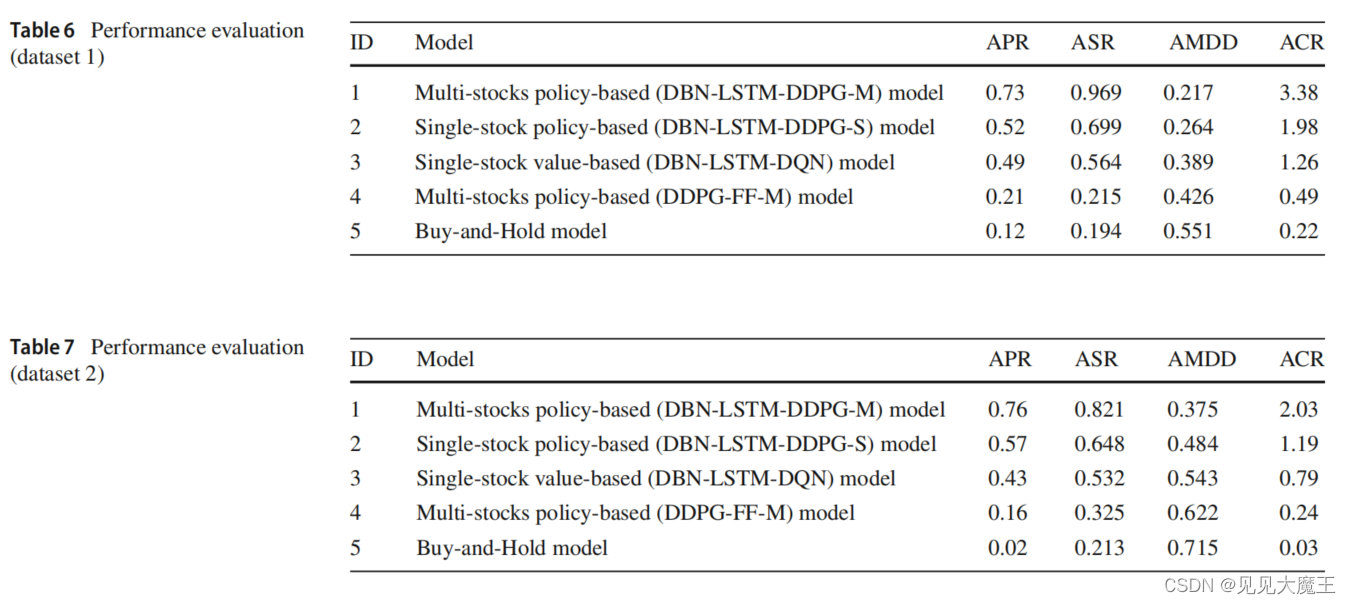
3.5 实验结果
总体而言,该模型的性能优于其他模型。由于平均夏普比率是最高的比率,所提出的模型以较低的风险获得最高的累积财富回报。风险较低的另一个指示是 Maximum Draw Down (MDD) 和 Calmar Ratio (CR) 的值,它们代表了其他技术中最低的值。报告的结果代表了在尝试每种技术的不同参数集后发现的最佳结果。这些结果表明,我们的交易模型分别受益于 DB N和 LSTM 的特征提取和缩减以及时间序列预测。

有什么值得阅读的文献?
- 关于股票预测:Applications of deep learning in stock market prediction: recent progress.
这篇关于【文献阅读】A synchronous deep reinforcement learning model for automated multi-stock trading的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






