本文主要是介绍股票量化分析工具QTYX使用攻略——每日涨停数据选股(更新2.6.0),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

搭建自己的量化系统

如果要长期在市场中立于不败之地!必须要形成一套自己的交易系统。
如何学会搭建自己的量化交易系统?
边学习边实战,在实战中学习才是最有效地方式。于是我们分享一个即可以用于学习,也可以用于实战炒股分析的量化系统——QTYX。
分享QTYX系统目的是提供给大家一个搭建量化系统的模版,最终帮助大家搭建属于自己的系统。因此我们提供源码,可以根据自己的风格二次开发。
QTYX系统结构如下所示:
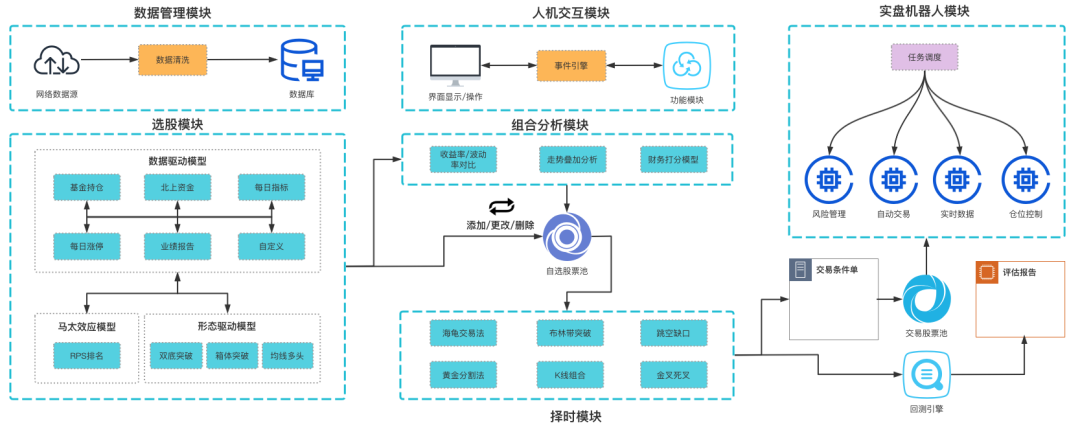
由于QTYX一直迭代更新,当前介绍对应于版本V2.6.0。后续升级版本会同步更新文档内容。

功能概述

目前A股市场的股票每天是有限制最大涨幅的,也就是涨停的概念。比如主板个股最大涨幅是10%,创业板个股最大涨幅是20%等。
对于个股而言并不是随随便便就能被推到涨停板的。或是因为股票发生了重大的利好(资产重组、政策利好、业绩暴增等)引起市场的投资者争相购买,或是因为主力特意的行为(长期洗盘震仓后快速拉高价格、拉涨停使该股进入龙虎榜引起市场关注)
无论如何,追击涨停板是可以在短时间内收益最大化的行为,受到短线交易者的青睐。
为了更高效地选出市场上短期内的强势股,我们的股票量化分析工具QTYX支持A股全市场个股涨停板明细分析。

每日涨停数据源

接下来说说怎么使用吧!
首先点击“选股流程”—> “开始数据驱动选股” —>“刷新选股数据”。
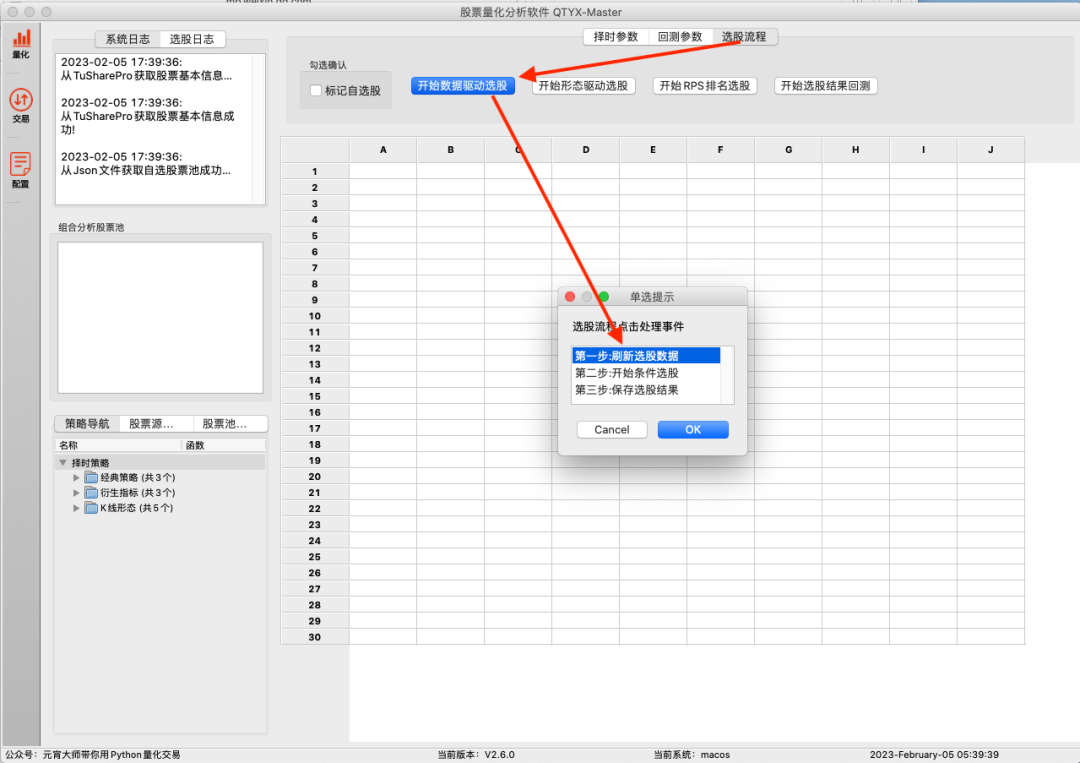
在“当前日期”框中选择当前最近的交易日期,比如2023年03月03日。
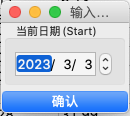
在“选股数据源”列表下选择“爬虫每日涨停”。
可以看到界面中出现了如下数据:
股票代码、股票名称、最新价、涨跌幅、成交额(亿)、流通市值(亿)、流通市值(亿)、换手(%)、连板天数、首次封板时间、最终封板时间、封板资金(亿)、炸板次数、所属行业、涨停统计、封成比。
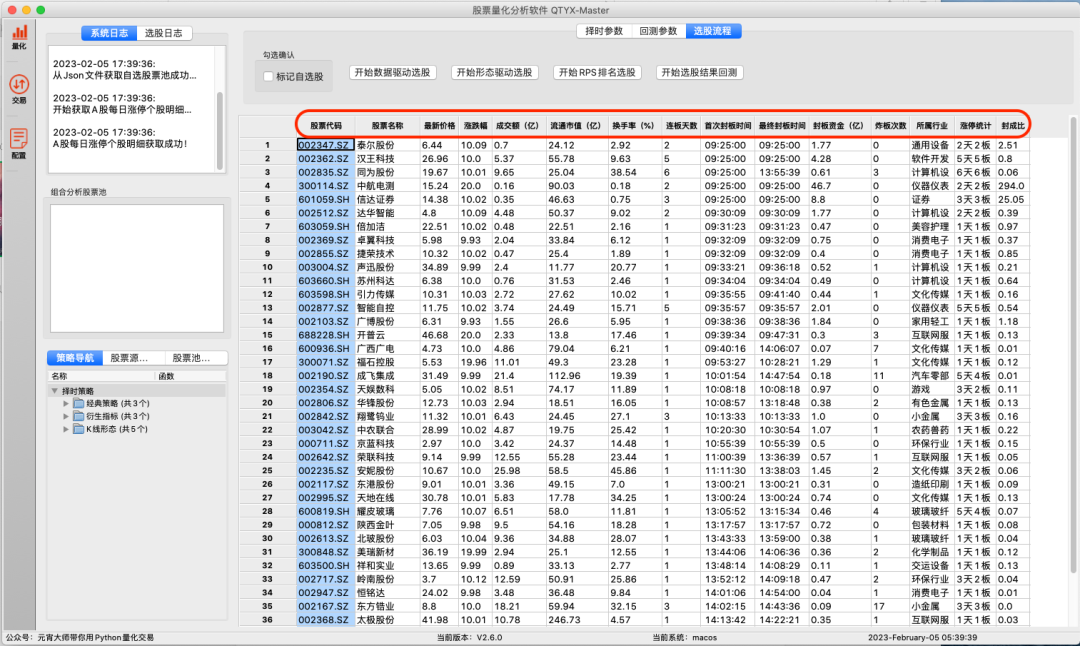
这个就是当日A股全市场的涨停股票数据。当然如果把 “当前日期”更改为之前的交易日期,比如2022年11月21日,就可以获取到那天的A股全市场的涨停股票数据。
这个时候会出现提示对话框,询问“是否查看板块内涨停个股数量”。
点击“Yes”后会出现如下图表,横轴表示板块类型,纵轴表示板块内个股的数量。
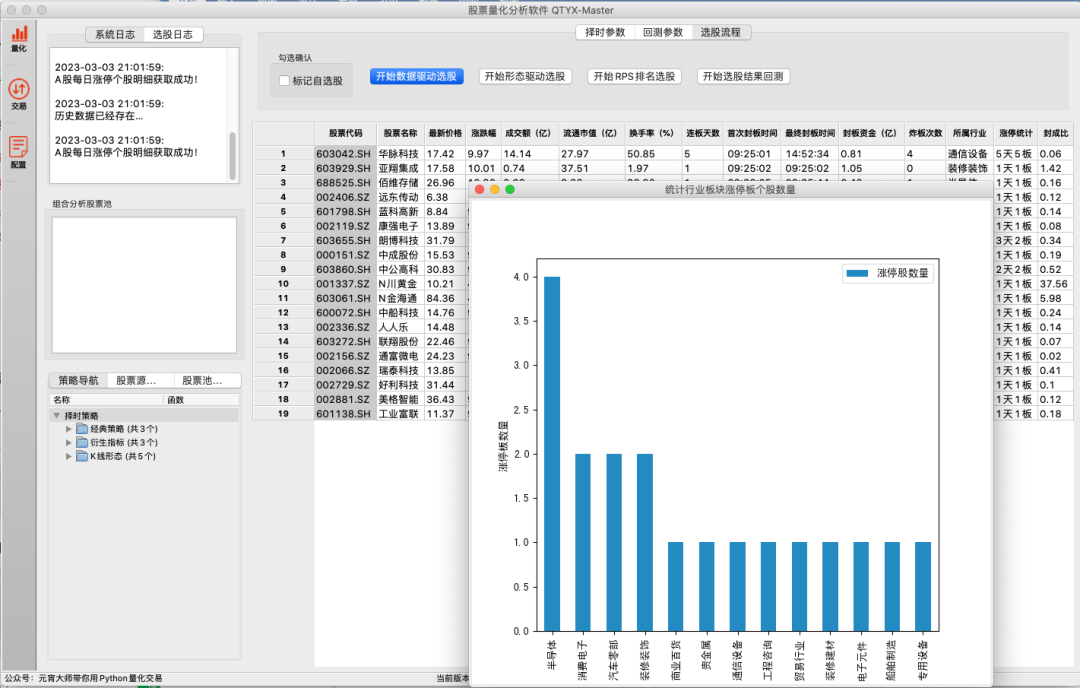
由于目前A股市场主旋律仍然是以行业及题材板块的热点轮动为主,因此从某种意义上来说,个股的强弱体现了对应板块的强弱。
比如在一个板块启动的初期,在每日涨停个股明细中,发现所属某个板块的个股数量占了大部分,则说明这个板块正在启动一轮上涨,然后再结合该板块的行情走势二次确认。
QTYX的统计行业板块内涨停板数量功能,目的是为了更高效地分析出市场上启动的热点板块。

条件表达式编辑

获取到了涨停股票数据,接下来可以用条件表达式来选股。
比如我们知道了“半导体”板块的涨停个股数量最多,可以过滤该板块的全部个股。
点击“选股流程”—> “开始数据驱动选股” —>“开始条件选股”。
比如选择“所属行业”“等于”“半导体”,然后点击 “确认”。

可以看到界面中出现了符合条件的股票:

如果要重新选股,只需再次“刷新选股数据”即可。然后再次条件表达式选股,比如选择“连板天数”“小于”“2”。

可以看到界面中出现了符合条件的股票:
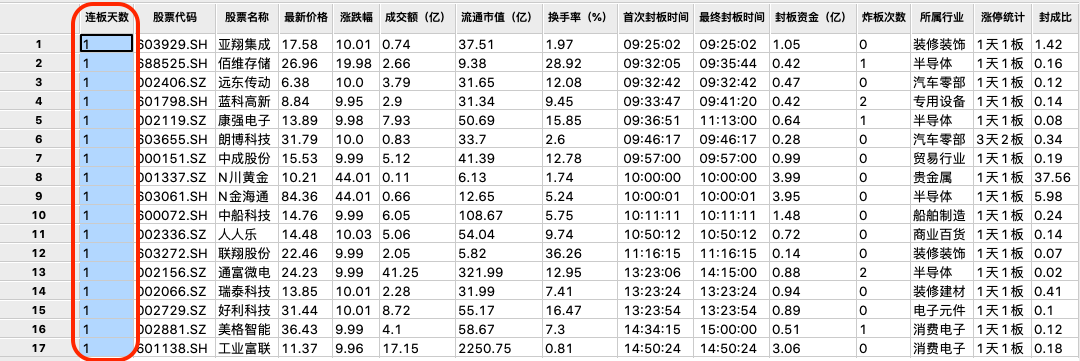
依照这个方式再设置其他叠加条件,比如选择“封成比”大于“0.2”。

依次类推,用这个方式逐步筛选出符合我们要求的股票。
如果要把结果保存到自选股票池中,可以点击“选股流程”—> “开始数据驱动选股” —>“保存选股结果”。
也可以点击股票代码单独添加股票,这个时候会触发“高级分析功能”,比如加入组合分析池、查看行情走势、查看现金流量、查看F10 资料等等。
加入到“自选股票池”之后,就可以展开更多选股流程体系中的二级分析了,比如查看行情走势、查看基本面、查看衍生技术指标,可以和其他个股对比分析,也可以用策略对该股历史数据回测。
以我个人的使用经验来看,追击涨停板是收益和风险并存的策略,大家在追击的同时一定要设置好止损点,有时候高赔率比高胜率更重要!
说明
想要加入知识星球《玩转股票量化交易》的小伙伴记得先微信call我获取福利!
知识星球介绍点击:知识星球《玩转股票量化交易》精华内容概览

这篇关于股票量化分析工具QTYX使用攻略——每日涨停数据选股(更新2.6.0)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







