本文主要是介绍Robust Data Augmentation Generative Adversarial Networkfor Object Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
基于生成对抗性网络(GAN)的数据扩充用于提高目标检测模型的性能。它包括两个阶段:训练GAN生成器以学习小目标数据集的分布,以及从训练的生成器中采样数据以提高模型性能。在本文中,我们提出了一种流程化的模型,称为鲁棒数据增强GAN(RDAGAN),旨在增强用于目标检测的小型数据集。首先,将干净的图像和包含来自不同域的图像的小数据集输入RDAGAN,然后RDAGAN生成与输入数据集中的图像相似的图像。然后,将图像生成任务划分为两个网络:目标生成网络和图像翻译网络。目标生成网络生成位于输入数据集的边界框内的目标的图像,并且图像转换网络将这些图像与干净的图像合并。 定量实验证实,生成的图像提高了YOLOv5模型的火灾检测性能。对比评价表明,RDAGAN能够保持输入图像的背景信息,定位目标生成位置。此外,消融研究表明,RDAGAN中包括的所有组件和物体都发挥着关键作用。
1、介绍
基于神经网络的目标检测模型优于传统模型,已成为目标检测技术中的一个里程碑。然而,基于神经网络的模型的惊人性能源于数百万个参数和大量的训练数据,这使得模型能够得到充分的训练。MS COCO和Pascal VOC是一般目标检测任务中众所周知的数据集。这些数据集包含许多普通物体的图像和准确的注释,这缓解了研究人员对他们使用的数据集的担忧,并使他们能够专注于研究。然而,创建高质量的数据集是一项劳动密集、耗时且成本高昂的任务。因此,不经常发生的事件的数据集是不够的。数据集的缺乏引发了小数据集和类不平衡问题,这限制了模型的性能。
已经提出了图像数据增强方法,通过使用来自现有数据集的图像以较低的成本增加数据集的大小。图像数据扩充的一种方法是基本的图像操作,它涉及到简单的操作,如裁剪或折叠图像。尽管这种方法计算成本低,并且可以增加数据集的大小,但如果数据集的规模不够,它可能会导致过度拟合问题。另一种方法是使用深度学习的图像数据增强,最常用的方法是基于生成对抗性网络(GANs)。在用要增强的图像数据集训练GAN模型之后,这些方法通过从训练的模型中采样图像来增强数据集。一些研究提出了基于GAN的图像数据增强方法,它们比使用现有数据集训练的方法获得了更好的目标检测性能。
尽管任何物体都可以通过基于GAN的图像数据增强作为目标,但大多数研究都是在医学领域进行的。其中一个原因是,由于医学领域的特点,如隐私和疾病罕见,很难获得大量的医学图像数据。真实的图像也遇到了类似的数据短缺问题。在火灾的情况下,由于安全问题,很难生成数据,并且现有数据集包含的图像数量不足。此外,与一般物体不同,火焰很难创建,因为火焰是一个没有清晰边缘的非结构化物体。因此,影片和背景之间的平稳过渡非常重要。此外,由于火焰是由燃烧物体产生的,许多真实世界的火焰图像似乎与背景物体混合在一起。因此,如果在图像插入的目标位置有物体,使用剪切粘贴方法创建真实图像的方法是不合适的,因为物体和图像应该看起来自然协调。
这项研究的目标是通过用少量的一般数据扩充目标检测数据集来生成标记数据。结构化目标具有足够的数据并且易于标记,但非结构化目标则不然。为了缓解这些问题,我们专注于在给定非结构化目标的小数据集时通过数据增强来提高检测性能。我们选择fire作为非结构化目标的代表。在这项研究中,我们使用了显示各种火灾情况的火灾图像,如图1所示。这些图像包含遮挡,并且图像的尺度变化是显著的。为了解决这些问题,我们提出了一种新的基于GAN的数据扩充模型,称为鲁棒数据扩充GAN(RDAGAN)。 RDAGAN使用包含少量具有强遮挡的精细图像的数据集,将干净的无精细图像转换为精细图像。由于生成的图像用于训练目标检测模型,RDAGAN必须在目标区域中插入一个将用作生成图像的边界框的帧。通过最大限度地利用给定的数据集,它可以生成逼真的细节图像,从而提高对象检测模型的性能。本研究的贡献可总结如下。
1.我们提出了RDAGAN来解决目标检测任务中的小数据集问题。RDAGAN包括两个网络:目标生成网络和图像翻译网络。目标生成网络通过生成作为图像翻译网络指南的模糊补丁来减轻图像翻译网络的负担。图像翻译网络通过混合生成的图像和干净的图像,将整个图像翻译成真实场景。
2.我们提出了信息损失的概念,通过最大化两个网络输出的互信息来绑定两个网络,以在图像翻译网络中保留生成的同一补丁的信息。
3.提出了背景损失来提高RDAGAN的性能。背景损失比较输入图像和通过图像翻译网络生成的图像之间的差异,并使它们尽可能相似。因此,生成的图像具有尖锐的边缘和不同的颜色分布。
4.定量实验表明,使用RDAGAN增强的数据集可以实现比基线模型更好的故障检测性能。此外,通过对比实验和消融研究,我们表明RDAGAN可以生成更多图像的标记数据。

2、相关工作
2.1、纠缠表示学习与InfoGAN
解纠缠表示学习是一种无监督的学习技术。其目标是找到一种只影响数据一个方面,而不影响其他方面的混乱表示。
为了确定解纠缠表示,提出了InfoGAN,这是GAN的一个变体,它确定了可解释的解纠缠表示而不是未知噪声。InfoGAN允许模型通过在表示学习过程中使用约束来学习解纠缠的表示。此外,它将输入划分为不可压缩噪声和潜在代码,并使潜在代码和生成器分布之间的相互信息最大化。也就是说,在生成过程中保留潜在代码信息。
2.2、图像到图像翻译
图像到图像翻译技术将一个域的图像映射到另一个域。尽管这项任务看起来类似于风格转换,但它们有一个关键的区别。风格转移旨在翻译图像,使其具有一个目标图像的风格,同时保持图像的内容。相比之下,I2I翻译旨在创建图像组之间的映射。
Pix2Pix是第一个用于学习两个成对图像组之间映射的基于监督I2I条件GAN的模型。然而,由于Pix2Pix具有基于翻译图像和真实图像之间的损失的目标函数,因此无法使用未配对的数据集进行训练。已经提出了无监督的I2I翻译模型来解决这个问题。循环一致对抗性网络是最著名的无监督I2I翻译模型之一。它包含两对生成器和鉴别器。每个生成器和鉴别器对学习将图像映射到相反的域上。此外,还提出了循环一致性损失,这是使用原始图像和从转换到另一个域的图像中恢复的图像之间的
距离来定义的。循环一致性损失可以缓解由于缺乏配对数据集而造成的问题。 非配对图像到图像翻译的对比学习(CUT)是一种基于对比学习的无监督I2I翻译模型。其目标是确保翻译图像的补丁包含输入图像的内容。CUT通过对比损失最大化相互信息来实现这一目标。对比度损失最大化了输入图像和输出图像中相同位置的补丁的相似性,并最小化了不同位置的补丁相似性。
2.3、基于GAN的图像数据生成
基于GAN的图像数据增强方法广泛应用于医学成像或遥感等许多领域。这些领域很难获得足够的数据来训练神经网络,因为它们需要大量的训练数据。当数据点数量较少时,模型很容易被过度拟合或陷入类不平衡问题。基于GAN的图像数据增强方法可以通过从数据分布中生成新的样本来缓解这些问题。Frid Adar等人提出了一种使用GANs生成肝脏病变图像的方法。在这项研究中,尽管他们只使用了182张肝脏病变计算机断层扫描图像来训练GAN模型,但卷积神经网络模型在肝脏病变分类方面的性能有所提高。 此外,由于I2I翻译模型将一个领域的图像翻译成另一个领域,一些研究已经使用I2I翻译生成了用于目标检测和图像分割的标记数据集。在这种情况下,翻译的目标域成为要增强的数据集,而作为翻译主题的图像成为源图像。Lv等人提出了一种基于GAN的遥感图像增强模型,用于图像分割任务。他们提出了深度监督GAN(D-sGAN),可以自动生成遥感图像及其标签。D-sGAN接受随机噪声和目标分割图,并合成与输入分割图相对应的遥感图像。D-sGAN生成的图像使遥感解释模型的精度提高了9%。行人合成GAN(PS-GAN)是为了降低行人图像注释的成本而提出的。PS-GAN使用带有插入噪声的图像。将物体放置在噪声区域中,将行人图像插入噪声框中,并使用一个鉴别器对整个图像进行评估,另一个鉴别器对生成的行人块进行评估。使用该模型增强的数据集已被证明可以提高基于区域的卷积神经网络的检测性能。
2.4、火焰图像生成的图像数据增强
关于为特定任务创建更多图像的研究很少。对其中一些进行了研究,以提高进一步分类的性能。Campose和Silva提出了一种基于CycleGAN的模型,将非红外航空图像转换为有红外的航空图像。该模型将非彩色航空图像转换为有彩色的航空图像。该模型基于剪切粘贴算法来控制缺陷生成区域。Park等人提出了一种基于CycleGAN的模型来缓解野生缺陷检测的类别不平衡问题。该模型将非真实图像转换为真实图像。由于图像分类任务不需要对更多区域进行注释,因此无需控制图像生成。因此,这些研究使用了几乎没有修改的CycleGAN架构,这些架构只能将干净的图像转换为真实的图像。
已经进行了其他研究来提高图像分割性能。杨等人提出了一种创建模糊图像的模型,以提高仓库中的模糊分割性能。他们研究的一个局限性是,正方形区域和生成图像的背景之间的边界可以清楚地区分,因为模型只在插入图像周围的正方形区域执行图像转换。秦等人提出了一个创建逼真的真实图像的模型,包括动画的效果。他们的模型使用剪切粘贴算法将火焰粘贴到图像上,然后创建包括光源效果的自然火焰图像,例如图像平移的光晕。在这项研究中,通过解决先前研究中遇到的问题,创建了更自然的细节图像。 这两项研究都有局限性,因为它们没有对一般的室内图像进行建模,而是只考虑室内图像,并且这些图像在火焰和背景物体之间几乎没有杂乱和遮挡。
3、方法和材料
在本节中,我们将介绍所提出的RDAGAN模型。目标是建立一个模型,将干净图像域(![]() )中的干净图像映射到目标图像域(
)中的干净图像映射到目标图像域(![]() )中的目标图像。所提出的模型是使用包含少量图像的目标检测数据集进行训练的,并且大多数图像都有遮挡。
)中的目标图像。所提出的模型是使用包含少量图像的目标检测数据集进行训练的,并且大多数图像都有遮挡。
该模型采用分而治之的方法,将模型分为两个网络:对象生成网络和图像翻译网络。该模型不仅努力在图像中插入逼真的目标(![]() ),而且还将整个图像变换为诸如目标域(
),而且还将整个图像变换为诸如目标域(![]() )中的那些图像。由于训练变得不稳定,使用单个GAN模型很难实现这些目标。
)中的那些图像。由于训练变得不稳定,使用单个GAN模型很难实现这些目标。
3.1、目标生成网络
对象生成网络创建要插入![]() 的目标对象的图像。从对象生成网络生成的图像被用作图像翻译网络的输入。由于对象创建和图像翻译的目标,图像减轻了图像翻译网络中的训练不稳定性。该网络采用InfoGAN架构来获得目标对象的解纠缠表示。在图像翻译网络中使用从对象生成网络获得的解纠缠表示来构建损失函数。我们使用对象图像
的目标对象的图像。从对象生成网络生成的图像被用作图像翻译网络的输入。由于对象创建和图像翻译的目标,图像减轻了图像翻译网络中的训练不稳定性。该网络采用InfoGAN架构来获得目标对象的解纠缠表示。在图像翻译网络中使用从对象生成网络获得的解纠缠表示来构建损失函数。我们使用对象图像![]() 训练网络,这些对象图像是使用裁剪和调整大小模块
训练网络,这些对象图像是使用裁剪和调整大小模块![]() 从图像
从图像![]() 中裁剪和调整的。
中裁剪和调整的。
如图2所示,生成器![]() 接受不可压缩噪声z和潜在代码c作为输入,它们是从正态分布中采样的。鉴别器
接受不可压缩噪声z和潜在代码c作为输入,它们是从正态分布中采样的。鉴别器![]() 不仅验证输入图像,而且预测输入潜在代码
不仅验证输入图像,而且预测输入潜在代码![]() 。
。
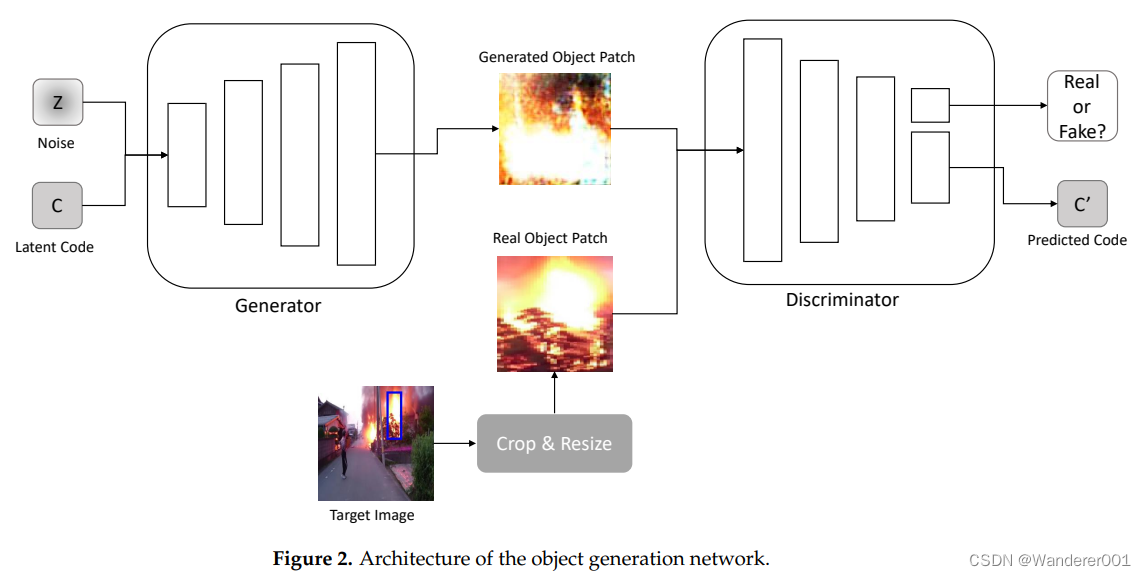
目标
由于对象生成网络使用InfoGAN架构,因此模型目标![]() 包括两种损失:对抗性损失
包括两种损失:对抗性损失![]() 和信息损失
和信息损失![]() 。
。
对抗性损失![]() 用于使生成的补丁
用于使生成的补丁![]() 类似于目标域图像
类似于目标域图像![]() 的补丁,如下所示:
的补丁,如下所示:
![]()
信息损失![]() 测量潜在代码c和生成图像
测量潜在代码c和生成图像![]() 之间的相互信息。它是使用来自鉴别器
之间的相互信息。它是使用来自鉴别器![]() 的输入潜在码
的输入潜在码和预测码
的均方误差来计算的,如下所示:
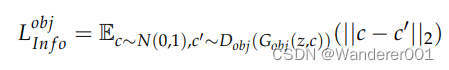
全部目标![]() 是之前损失的总和:
是之前损失的总和:

其中λ表示信息丢失的强度。通过最小化全部目标来训练模型。
3.2、图像翻译网络
图像转换网络将干净图像![]() 和由对象补丁网络生成的对象补丁
和由对象补丁网络生成的对象补丁![]() 合并,同时使图像
合并,同时使图像与目标图像
![]() 相似。然而,使用原始GAN模型和单个对抗性损失同时执行这些复杂任务是具有挑战性的。因此,所提出的模型包括局部鉴别器和额外的损失函数,以减轻复杂任务的负担。
相似。然而,使用原始GAN模型和单个对抗性损失同时执行这些复杂任务是具有挑战性的。因此,所提出的模型包括局部鉴别器和额外的损失函数,以减轻复杂任务的负担。
3.2.1、生成器
如图3所示,图像转换网络生成器![]() 具有一个编码器-解码器体系结构,中间包含剩余网络(ResNet)块,类似于CycleGAN中使用的生成器。然而,与[23]不同的是,生成器在生成图像的形状变化方面具有灵活性,因为所有特征都是下采样和上采样的。
具有一个编码器-解码器体系结构,中间包含剩余网络(ResNet)块,类似于CycleGAN中使用的生成器。然而,与[23]不同的是,生成器在生成图像的形状变化方面具有灵活性,因为所有特征都是下采样和上采样的。
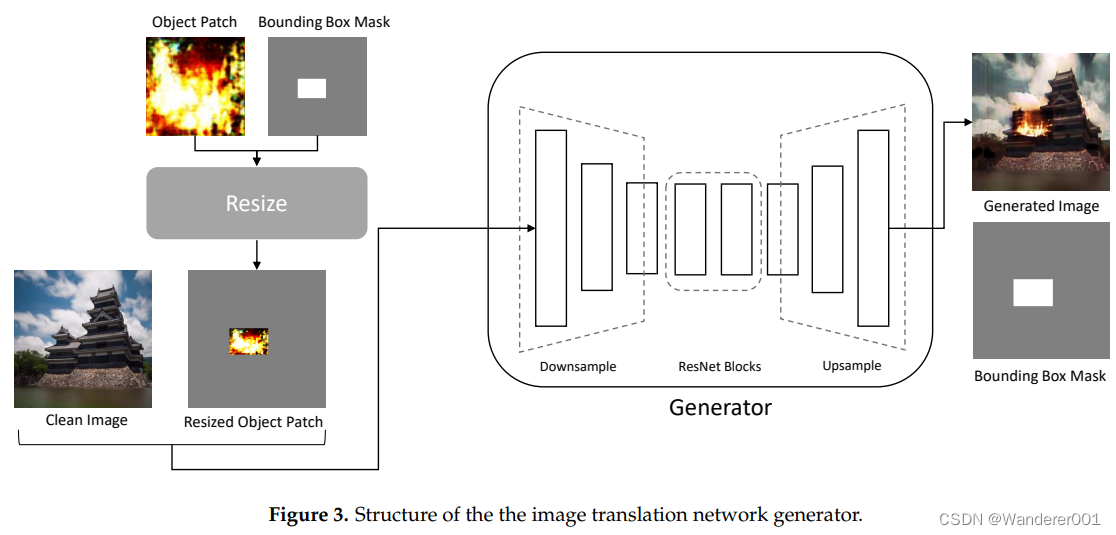
要创建图像,生成器需要一个边界框掩码,该掩码指示插入图像的位置。如等式(4)所示,遮罩值为0的位置表示背景,值为1的位置表示火焰。没有用于确定边界框区域的特定算法。边界框区域的每个点是从图像的高度和宽度内的离散均匀随机分布中随机采样的。
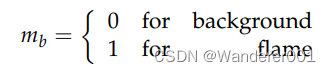
调整大小的目标patch ![]() 是通过调整目标patch的大小来获得的,其中patch位于边界框掩码的值为1的区域中。调整大小的对象补丁与干净的图像连接在一起,并用作生成器输入。生成器通过自然地混合六个通道组合图像并平移它们以使它们类似于目标域图像
是通过调整目标patch的大小来获得的,其中patch位于边界框掩码的值为1的区域中。调整大小的对象补丁与干净的图像连接在一起,并用作生成器输入。生成器通过自然地混合六个通道组合图像并平移它们以使它们类似于目标域图像![]() 来创建生成的图像
来创建生成的图像![]() 。
。
3.2.2、鉴别器
如图4所示,图像翻译网络包括两个鉴别器:全局![]() 和局部
和局部![]() 。这些鉴别器执行图像翻译和自然融合的图像翻译网络任务。
。这些鉴别器执行图像翻译和自然融合的图像翻译网络任务。
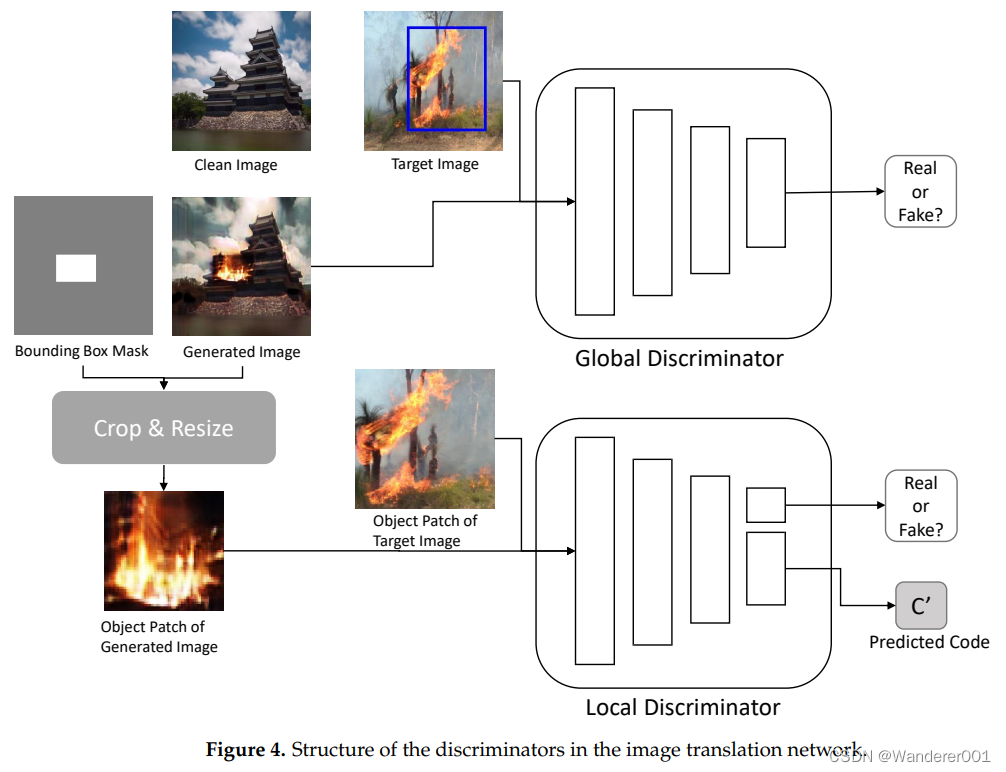
全局鉴别器![]() 评估由生成器生成的图像
评估由生成器生成的图像![]() 。其结构基于PatchGAN鉴别器,该鉴别器评估图像的块而不是整个图像。它评估该图像是否与目标域图像T的图像相似。该评估结果构成对抗性损失。
。其结构基于PatchGAN鉴别器,该鉴别器评估图像的块而不是整个图像。它评估该图像是否与目标域图像T的图像相似。该评估结果构成对抗性损失。
局部鉴别器![]() 确定对象补丁
确定对象补丁![]() 是否真实,以及是否可以使用生成的图像的掩码通过裁剪和调整
是否真实,以及是否可以使用生成的图像的掩码通过裁剪和调整![]() 大小操作
大小操作![]() 来获得对象patch
来获得对象patch 。局部鉴别器的结构与全局鉴别器类似。然而,与InfoGAN鉴别器一样,它包含一个额外的辅助层,用于从图像的特征图中生成预测代码
。局部鉴别器的真实性评估结果包含在对抗性损失中,并且预测的代码用于构建信息损失。
3.2.3、对抗损失
我们使用对抗性损失![]() 来允许生成器学习从C到T的映射。目标如下:
来允许生成器学习从C到T的映射。目标如下:
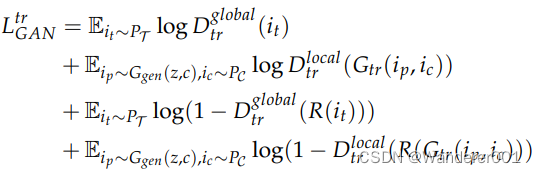
其中![]() 试图生成与从目标域T获得的图像相似的图像,并且目标对象表现为真实对象,而全局鉴别器
试图生成与从目标域T获得的图像相似的图像,并且目标对象表现为真实对象,而全局鉴别器![]() 旨在将生成的图像
旨在将生成的图像![]() 与从T获得的图片区分开。局部鉴别器
与从T获得的图片区分开。局部鉴别器![]() 努力将生成的对象
努力将生成的对象![]() 与从T获得的对象区分开来。
与从T获得的对象区分开来。
3.2.4、信息损失
图像翻译网络的目标不能单独使用对抗性损失来实现,因为目标图像包含目标对象和遮挡。因此,局部鉴别器不仅同时学习对象本身的形状和纹理,还学习其他对象引起的遮挡。这阻碍了生成器使用对象补丁并将其与干净图像
混合,并在生成的图像中产生伪影。此外,它会导致生成器陷入模式崩溃。为了解决这个问题,我们引入了信息损失来约束输入对象补丁
![]() 和生成图像R的裁剪对象
和生成图像R的裁剪对象![]() 具有相似的特性,这允许生成器将对象补丁
具有相似的特性,这允许生成器将对象补丁与干净图像
混合。
然而,通过直接使用输入对象补丁和生成的图像对象补丁
![]() ,很难创建两个具有相似特征的图像。因此,我们通过最大化两者之间的相互信息来实现这一点。互信息表示为
,很难创建两个具有相似特征的图像。因此,我们通过最大化两者之间的相互信息来实现这一点。互信息表示为![]() ,其中
,其中![]() 是随机变量X和Y之间的互信息。互信息被定义为H(X)−H(X|Y),其中H(X)和H(X| Y)分别是边际熵和条件熵。
是随机变量X和Y之间的互信息。互信息被定义为H(X)−H(X|Y),其中H(X)和H(X| Y)分别是边际熵和条件熵。
最大化![]() 也是有问题的,因为
也是有问题的,因为和
![]() 具有相同的维度。最大化
具有相同的维度。最大化![]() 意味着使两个图像尽可能相同,并且可以通过用
意味着使两个图像尽可能相同,并且可以通过用替换生成的图像补丁
![]() 来实现。因此,我们试图最大化
来实现。因此,我们试图最大化![]() ,而不是
,而不是![]() 。这是因为对象生成网络
。这是因为对象生成网络![]() 被训练为最大化
被训练为最大化和
之间的相互信息。在[6]中,证明了最大化互信息
![]() 与最小化潜在码c和来自局部鉴别器
与最小化潜在码c和来自局部鉴别器![]() 的预测码
的预测码之间的差相同。
3.2.5、背景损失
背景损失用于确定输入图像和生成图像
![]() 之间的差异,边界框掩码区域
之间的差异,边界框掩码区域除外。由于具有编码器-解码器结构的生成器
的性质,图像首先被压缩为低维表示,然后被恢复。这样做的优点在于生成的图像的结构相对自由;然而,有一个权衡是图像的清晰度降低了。因此,图像的边缘成分变得模糊,图像的色调发生了显著变化,生成的图像中的颜色变化也减少了。
为了消除生成器的重建问题,引入了背景损失。背景损失是输入干净图像和生成图像
![]() 之间的逐像素L1距离,除了掩模
之间的逐像素L1距离,除了掩模区域。这是因为火焰在掩模指示的区域中融合。为了排除模糊区域,我们获得反转掩模1−
,并将其与生成的图像
![]() 和干净图像
和干净图像相乘。背景损失强烈引导生成器
![]() ,稳定训练,并允许
,稳定训练,并允许![]() 生成清晰的图像。目标函数
生成清晰的图像。目标函数![]() 表示如下:
表示如下:
![]()
3.2.6、全部目标函数
最后,图像翻译网络的全部目标如下:
![]()
其中和
分别是背景和信息损失的强度。
3.3、整体结构
RDAGAN的总体架构如图5所示。对于RDAGAN数据生成,使用图像生成和翻译网络的生成器。![]() 接收不可压缩噪声z和潜在编码c,并创建对象补丁
接收不可压缩噪声z和潜在编码c,并创建对象补丁![]() 。RDAGAN从均匀分布中对边界框遮罩
。RDAGAN从均匀分布中对边界框遮罩进行采样,并使用它来创建调整大小的对象面片
。调整大小的对象补丁与干净的图像
一起传递给
![]() ,该图像用作创建生成的图像
,该图像用作创建生成的图像![]() 的背景。在执行最终图像生成以生成对象检测数据集的图像后,将掩码
的背景。在执行最终图像生成以生成对象检测数据集的图像后,将掩码转换为边界框。

4、实验
我们进行了定性和定量评估,以证明RDAGAN的图像生成性能,并验证它是否可以提高客观检测性能。首先,我们设计了一个定量评估,以证明RDAGAN可以生成足以提高深度学习模型检测性能的标记数据。然后,我们进行了定性评估,以确定图像翻译网络的图像生成能力。定性评估包括比较评估和消融研究。在比较评价中,比较了图像翻译模型和基线模型的能力。在消融研究中,对RDAGAN及其消融进行了比较。
4.1、实现细节
对于所有实验,对象生成网络包括112维噪声和16维潜在代码,生成的对象补丁的大小为128×128像素。图像翻译网络的生成器包括两个下采样层、11个ResNet块和两个上采样层。图像翻译网络使用256×256像素图像作为生成器和全局鉴别器,使用64×64像素图像作为局部鉴别器的裁剪对象图像。
为了评估所提出的模型,我们使用两个数据集进行了实验:FiSmo和Google Landmarks v2数据集。FiSmo数据集是一个更精细的数据集,包含用于对象检测和分割任务的更精细情况的图像和注释。在实验中,我们使用FiSmo数据集的图像和边界框作为最终图像的来源。谷歌地标v2数据集是一个大型数据集,包含约500万幅地标图像。在我们的模型中,Google Landmarks v2数据集被用作生成更多图像的非真实背景图像。
在定量实验中,使用具有8670万个参数的YOLOv5模型来评估目标检测性能。构建了两个数据集来训练模型:一个数据集包括从FiSmo数据集采样的800幅图像,另一个数据集中包括从第一个数据集增强的图像。第二个数据集由800张FiSmo图像和从RDAGAN采样的3000张图像组成。为了测试YOLOv5模型,使用了从FiSmo数据集中采样的200幅图像的数据集。
在定性评估中,使用FiSmo数据集作为目标图像数据集来训练所有模型。使用Google Landmarks v2数据集作为干净图像数据集。为了训练RDAGAN,我们使用了从数据集中随机选择的1500个样本。为了通过RDAGAN生成图像,使用从Google Landmarks v2数据集采样的图像作为输入。实验中使用的数据集中没有一个图像与其他图像重叠。
比较实验中使用的基线模型是CycleGAN和CUT,它们是广泛使用的无监督I2I翻译模型。为了确保公平的比较,我们在训练期间向网络提供了对象补丁和干净的图像。这些补丁减少了生成对象的负担。对于CycleGAN,生成器网络被提供了一个额外的对象掩码,该掩码将目标域T映射到干净的图像域C。这使得网络能够容易地定位目标对象。
4.2、定量评估
对于定量评估,YOLOv5模型使用FiSmo数据集进行训练,并使用RDAGAN进行增强。增强数据集与使用RDAGAN采样的图像相一致,RDAGAN使用与比较实验中使用的数据集相同的数据集进行训练。我们评估了训练模型的性能,以确定生成的图像和边界框是否可以提高检测性能。
4.2.1、评估标准
为了评估所提出的模型,我们重点关注YOLOv5模型的准确性。我们采用了四个指标来衡量YOLOv5模型的准确性:准确度、召回率、F1分数和平均准确度(AP)。对象检测包括两个子任务:边界框回归和对象分类。我们通过测量精确度和召回率来评估分类性能。边界框回归容量可以使用AP进行缩放。精确度是真阳性(tp)在真阳性和假阳性总数(fp)中的百分比。回忆是(tp)在(tp)和假阴性(fn)总数中的百分比。这些指标计算如下:

精确度和召回率随检测器的置信阈值而变化。在这个评估中,我们将阈值设置为F1分数最大化的值。准确度和召回率之间存在权衡关系。也就是说,在大多数情况下,如果精确度提高,召回率就会被抑制。为了评估分类结果,F1分数可以用作准确性的整体评估指标,而不是精确度和召回率。它可以通过计算精度和召回率的谐波平均值得出,如下所示:

由于准确度和召回率之间的权衡关系,我们转而使用F1分数来量化结果。平均精度(AP)是用于评估目标检测模型的一种广泛使用的精度度量。AP是通过计算通过改变模型置信度获得的精度-召回曲线的面积来获得的[27]。可以考虑重叠阈值,即并集上的交集(IOU),其定义为地面实况边界框和区域并集上预测边界框
之间的重叠区域的交集的分数[2],如下所示:

使用IOU阈值,其中IOU小于阈值的预测被认为是误报[27]。我们通过应用两个IOU阈值设置来获得AP。在第一个设置中,IOU阈值设置为0.5,在另一个设置中为0.5–0.95,步长为0.5。我们将这些欠条表示为AP@0.5和AP@0.5分别为0.95。
4.2.2、比较实验
我们比较了RDAGAN和基线模型CycleGAN和CUT生成的图像和对象块。我们评估了整个图像的翻译,以及生成的图像的本地化和质量。
4.3、消融研究
4.3.1、图像生成
我们将RDAGAN生成的图像与其消融生成的图像进行了比较。消融包括四个消除了不同部分的模型:一个没有背景损失,一个没有物体补丁和信息损失,一一个没有局部鉴别器和信息丢失,以及一个没有目标补丁和局部鉴别剂。
4.3.2、目标生成
通过比较RDAGAN及其消融产生的物体,评估了信息丢失、背景丢失和局部鉴别器的重要性。
5、结果和讨论
5.1、定量评估结果
表1列出了经过训练的YOLOv5模型的性能。用RDAGAN生成的数据扩充的数据集显示AP@0.5从0.5082到0.5493以及AP@0.5:0.95从0.2917到0.3182,其中IOU阈值在0.5到0.95之间。

尽管用增强数据集训练的模型的召回率略有下降2.6%,但精度从0.5497大幅提高到0.6922,提高了14.2%。此外,用增强数据训练的模型F1得分从0.5465提高到0.5921。因此,RDAGAN可以增强数据并提高对象检测模型的性能,而不需要额外的目标数据集或图像。
5.2、比较实验结果
图6显示了RDAGAN和基线模型生成的图像和对象补丁。图6a–c分别显示了使用RDAGAN、CycleGAN和CUT生成的图像和对象补丁。我们评估了整个图像的翻译,以及生成的图像的本地化和质量。

关于整个图像的平移,RDAGAN显示出图像色调的轻微变化。然而,很明显,背景的总体特征得到了保持。相比之下,CycleGAN显著地改变了整个图像。生成的火焰区域变红,背景变为光晕并变暗。尽管CUT没有改变大多数图像的背景,但它未能在其中生成动画。关于火焰定位,RDAGAN在给定区域内生成了一个火焰,但CycleGAN在不同位置生成了火焰,CUT要么在不同位置产生了火焰,要么根本没有产生火焰。此外,CUT很难将这些味道融合在一起;因此,图6c中只有一个样本具有相同的特征。
总之,RDAGAN在保持背景特征的同时,准确地在目标位置创建了动画。然而,尽管CycleGAN在所有图像中都生成了模糊,但背景被降级,定位被完全忽略。尽管CUT的一些样本在一定程度上显示了火焰并保持了背景特征,但其在火焰生成和定位方面获得的结果不足。
5.3、消融研究
5.3.1、图像生成性能的比较
图7显示了RDAGAN及其消融的图像生成结果。图7a显示了RDAGAN生成的图像,图7b显示了不带![]() 的模型生成的图像。图7c显示了无
的模型生成的图像。图7c显示了无和
![]() 的模型生成图像。 图7d显示了没有
的模型生成图像。 图7d显示了没有![]() 和
和![]() 的模型生成的图像,图7e显示了没有
的模型生成的图像,图7e显示了没有![]() 的模型所生成的图像。
的模型所生成的图像。
我们比较了RDAGAN生成的整体图像与其消融之间的差异。在图7b中,背景色调固定,背景本身几乎无法识别。图7c中的图像显示了类似于RDAGAN的背景平移。在图7d中,在目标点处生成了曲面,但定位较差,从而降低了目标检测性能。此外,图7d中的图像包含背景退化。图7e中的图像似乎受到LtrBG的强烈影响,因此在给定区域生成了图像。然而,火焰的形状表明生成器经历了模式崩溃。

因此,我们可以确定,![]() 对于保持背景的清晰度至关重要,
对于保持背景的清晰度至关重要,对于对象生成至关重要,而
![]() 对于生成的图像的定位至关重要。
对于生成的图像的定位至关重要。
5.3.2、生成目标的比较
图8显示了从图7中截取的生成的对象。这些图像按照与图7中相同的顺序进行排序。我们评估了生成的图像的质量以及输入和生成的图像之间的关系。
图8a、b中的图像受![]() 的影响,而图8c-e中的图像则不受影响。
的影响,而图8c-e中的图像则不受影响。![]() 的影响可以通过评估输入和输出图像之间的关系来确定。尽管输入图像不是一个只需要修复的完美补丁,但RDAGAN在保持输入图像特性的同时生成了完美的补丁。在生成的补丁中显示为暗的区域在输入图像中也显示为暗,反之亦然。生成图8d中所示对象的模型被提供ip作为输入;然而,由于模型没有经历
的影响可以通过评估输入和输出图像之间的关系来确定。尽管输入图像不是一个只需要修复的完美补丁,但RDAGAN在保持输入图像特性的同时生成了完美的补丁。在生成的补丁中显示为暗的区域在输入图像中也显示为暗,反之亦然。生成图8d中所示对象的模型被提供ip作为输入;然而,由于模型没有经历![]() ,对象显示出与输入的关系较小。
,对象显示出与输入的关系较小。![]() 的影响可以通过比较图8a、b来确定。由于
的影响可以通过比较图8a、b来确定。由于![]() ,它们表现出类似的飞行模式,但缺少
,它们表现出类似的飞行模式,但缺少![]() 使图8b中生成的飞行看起来不现实。
使图8b中生成的飞行看起来不现实。
由于![]() ,它们表现出类似的飞行模式,但缺少
,它们表现出类似的飞行模式,但缺少![]() 使图8b中生成的飞行看起来不现实。图8c中的图像显示了
使图8b中生成的飞行看起来不现实。图8c中的图像显示了![]() 的重要性。图8c中所示的用于生成图像的模型为给定区域赋予了明亮的颜色,但它未能合成逼真的火焰,尽管它包含了
的重要性。图8c中所示的用于生成图像的模型为给定区域赋予了明亮的颜色,但它未能合成逼真的火焰,尽管它包含了![]() ,该
,该![]() 教授Gtr生成的物体是否看起来像真实的火焰。在用于生成图8e所示图像的模型中,删除了
教授Gtr生成的物体是否看起来像真实的火焰。在用于生成图8e所示图像的模型中,删除了![]() 。图8e中的图像显示了相似的形状和颜色。这表示模型中发生了模式崩溃。
。图8e中的图像显示了相似的形状和颜色。这表示模型中发生了模式崩溃。

因此,我们可以确定,![]() 在目标对象生成中起着至关重要的作用,即使没有它们中的一个,生成的对象的质量也会受到严重损害。
在目标对象生成中起着至关重要的作用,即使没有它们中的一个,生成的对象的质量也会受到严重损害。
6、结论
在本文中,我们提出了一种新的方法,称为RDAGAN,用于增强对象检测模型的图像数据。RDAGAN使用小数据集生成用于对象检测模型的训练数据。为了实现这一点,我们引入了两个子网络:对象生成网络和图像翻译网络。对象生成网络生成对象图像以减少图像翻译网络用于生成新对象的负担。图像翻译网络使用局部和全局鉴别器来执行图像到图像的翻译。此外,我们引入了信息丢失(![]() )来指导对象补丁和干净图像的混合,以及背景丢失(
)来指导对象补丁和干净图像的混合,以及背景丢失(![]() )来维护干净图像的背景信息。
)来维护干净图像的背景信息。
定量评估证明,与原始FiSmo数据集相比,使用RDAGAN生成的数据集可以提高YOLOv5模型的火灾检测性能。特别是,增强的数据集提高了YOLOv5模型的对象定位性能。比较评估表明,RDAGAN不仅可以生成逼真的细节图像,还可以确定细节生成区域,而基线模型则不能。消融研究表明,RDAGAN中一个或多个成分的缺失会严重损害模型的生成能力,这表明了RDAGAN所包含的所有成分的重要性。总之,RDAGAN可以在相对较短的时间内以较低的成本扩充对象检测数据集,而不需要手动收集和标记新数据来增加数据集的大小。
这篇关于Robust Data Augmentation Generative Adversarial Networkfor Object Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





