本文主要是介绍NLP Bi-Encoder和Re-ranker,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Retrieve & Re-Rank
https://www.sbert.net/examples/applications/retrieve_rerank/README.html
Bi-Encoder vs. Cross-Encoder
https://www.sbert.net/examples/applications/cross-encoder/README.html
Bi-Encoder会用BERT对输入文本编码,再根据cosine相似度分数筛选文本。Cross-Encoder会直接计算两个句子的相关性分数。
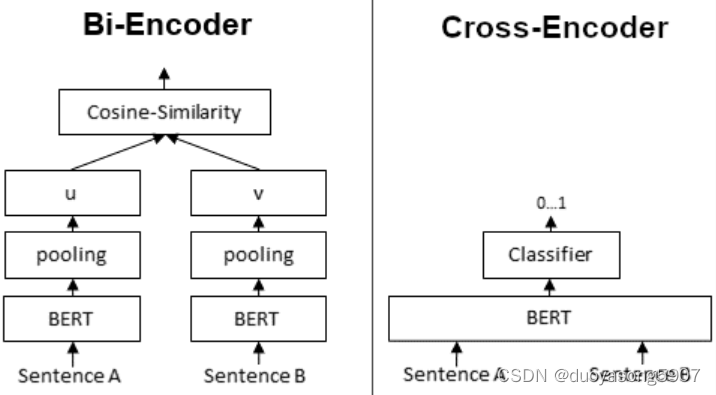
如何将BI和Cross Encoder配合使用?可以先用BI-Encoder选出top 100个候选项,再用Cross-Encoder挑选最佳选项。
Combining Bi- and Cross-Encoders
Cross-Encoder achieve higher performance than Bi-Encoders, however, they do not scale well for large datasets.
Here, it can make sense to combine Cross- and Bi-Encoders, for example in Information Retrieval / Semantic Search scenarios:
First, you use an efficient Bi-Encoder to retrieve e.g. the top-100 most similar sentences for a query.
Then, you use a Cross-Encoder to re-rank these 100 hits by computing the score for every (query, hit) combination.
这篇关于NLP Bi-Encoder和Re-ranker的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






