ranker专题

ranker-Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning
论文Scaling Up Crowd-Sourcing to Very Large Datasets A Case for Active Learning提出两种AL算法。 首先找到分类器θ对未标注数据的不确定程度。然后让crowd对这些数据进行标定。下边介绍两种不确定性方法。 下边的u是未标记数据,但是是指未标注数据的每一个,而不是整体。 一:Uncertainty Algorithm
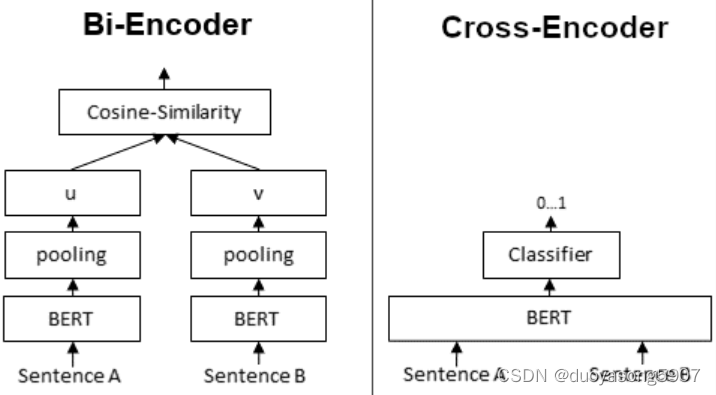
NLP Bi-Encoder和Re-ranker
Retrieve & Re-Rank https://www.sbert.net/examples/applications/retrieve_rerank/README.html Bi-Encoder vs. Cross-Encoder https://www.sbert.net/examples/applications/cross-encoder/README.html Bi-Encode