本文主要是介绍Elasticsearch实践:ELK+Kafka+Beats对日志收集平台的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
可以在短时间内搜索和分析大量数据。
Elasticsearch 不仅仅是一个全文搜索引擎,它还提供了分布式的多用户能力,实时的分析,以及对复杂搜索语句的处理能力,使其在众多场景下,如企业搜索,日志和事件数据分析等,都有广泛的应用。
本文将介绍 ELK+Kafka+Beats 对日志收集平台的实现。
文章目录
- 1、关于ELK与BKELK
- 1.1、ELK架构及其影响
- 1.2、基于BKLEK架构的日志分析系统实现
- 2、利用ELK+Kafka+Beats来实现一个统一日志平台
- 2.1、应用场景
- 2.2、环境准备
- 2.3、基于Docker的ES部署
- 2.4、基于Docker的kibana部署
- 2.5、基于Docker的Zookeeper部署
- 2.6、基于Docker的Kafka部署
- 2.7、基于Docker的Logstash部署
- 2.8、基于Docker的Filebeat部署
1、关于ELK与BKELK
1.1、ELK架构及其影响
当我们在开源日志分析系统的领域,谈及 ELK 架构可谓是家喻户晓。然而,这个生态系统并非 Elastic 有意为之,毕竟 Elasticsearch 的初衷是作为一个分布式搜索引擎。其广泛应用于日志系统,实则是一种意料之外,这是社区用户的推动所致。如今,众多云服务厂商在推广自己的日志服务时,往往以 ELK 作为参照标准,由此可见,ELK 的影响力之深远。
ELK 是 Elasticsearch、Logstash 和 Kibana 的首字母缩写,这三个产品都是 Elastic 公司的开源项目,通常一起使用以实现数据的搜索、分析和可视化。
-
Elasticsearch:一个基于 Lucene 的搜索服务器。它提供了一个分布式、多租户的全文搜索引擎,具有 HTTP 网络接口和无模式 JSON 文档。
-
Logstash:是一个服务器端数据处理管道,它可以同时从多个来源接收数据,转换数据,然后将数据发送到你选择的地方。
-
Kibana:是一个用于 Elasticsearch 的开源数据可视化插件。它提供了查找、查看和交互存储在 Elasticsearch 索引中的数据的方式。你可以使用它进行高级数据分析和可视化你的数据等。
这三个工具通常一起使用,以便从各种来源收集、搜索、分析和可视化数据。
1.2、基于BKLEK架构的日志分析系统实现
实际上,在流行的架构中并非只有 ELKB。当我们利用 ELKB 构建一套日志系统时,除了 Elasticsearch、Logstash、Kibana、beats 之外,还有一个被广泛应用的工具 —— Kafka。在这个体系中,Kafka 的角色尤为重要。作为一个中间件和缓冲区,它能够提升吞吐量,隔离峰值影响,缓存日志数据,快速落盘。同时,通过 producer/consumer 模式,使得 Logstash 能够进行横向扩展,还能用于数据的多路分发。因此,大多数情况下,我们看到的实际架构,按照数据流转的顺序排列,应该是 BKLEK 架构。
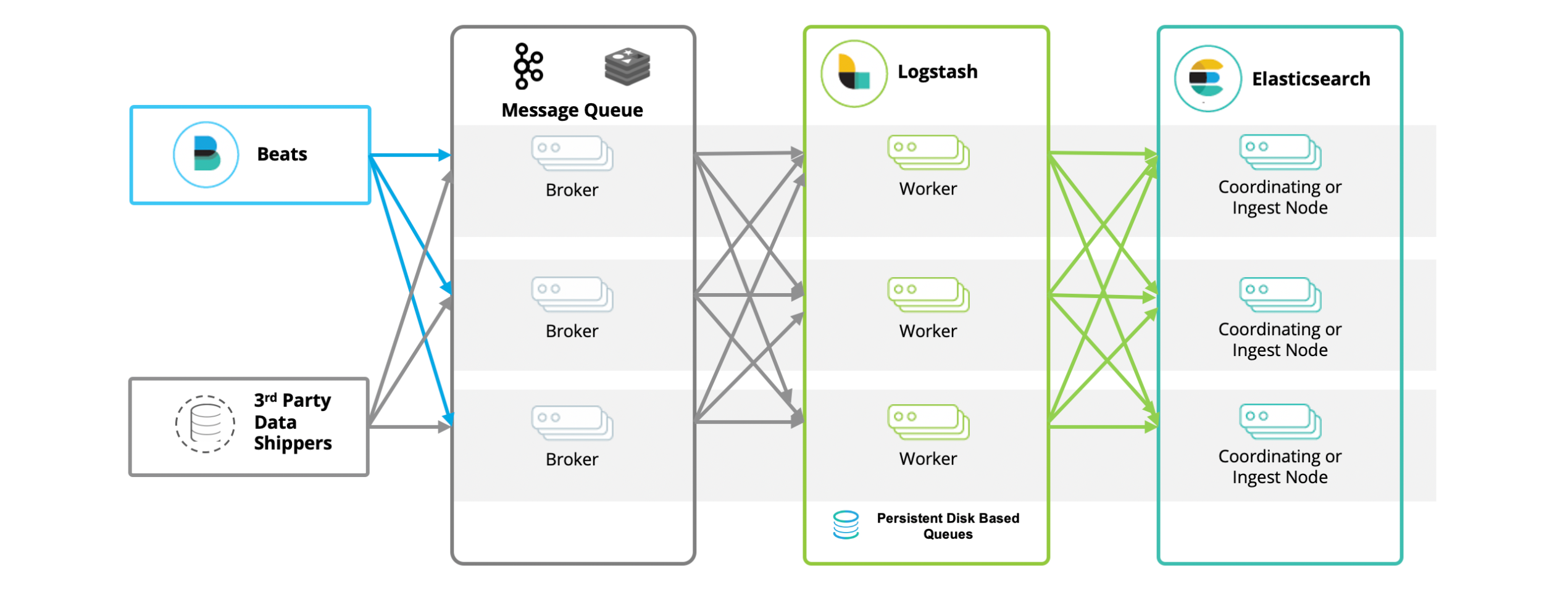
BKLEK 架构即 ELK+Kafka+Beats ,这是一种常见的大数据处理和分析架构。在这个架构中:
-
Beats:是一种轻量级的数据采集器,用于从各种源(如系统日志、网络流量等)收集数据,并将数据发送到 Kafka 或 Logstash。
-
Kafka:是一个分布式流处理平台,用于处理和存储实时数据。在这个架构中,Kafka 主要用于作为一个缓冲区,接收来自 Beats 的数据,并将数据传输到 Logstash。
-
Logstash:是一个强大的日志管理工具,可以从 Kafka 中接收数据,对数据进行过滤和转换,然后将数据发送到 Elasticsearch。
-
Elasticsearch:是一个分布式的搜索和分析引擎,用于存储、搜索和分析大量数据。
-
Kibana:是一个数据可视化工具,用于在 Elasticsearch 中搜索和查看存储的数据。
这种架构的优点是:
- 可以处理大量的实时数据。
- Kafka 提供了一个强大的缓冲区,可以处理高速流入的数据,保证数据的完整性。
- Logstash 提供了强大的数据处理能力,可以对数据进行各种复杂的过滤和转换。
- Elasticsearch 提供了强大的数据搜索和分析能力。
- Kibana 提供了直观的数据可视化界面。
这种架构通常用于日志分析、实时数据处理和分析、系统监控等场景。
2、利用ELK+Kafka+Beats来实现一个统一日志平台
2.1、应用场景
利用 ELK+Kafka+Beats 来实现一个统一日志平台,这是一个专门针对大规模分布式系统日志进行统一采集、存储和分析的 APM 工具。在分布式系统中,众多服务部署在不同的服务器上,一个客户端的请求可能会触发后端多个服务的调用,这些服务可能会互相调用或者一个服务会调用其他服务,最终将请求结果返回并在前端页面上展示。如果在这个过程中的任何环节出现异常,开发和运维人员可能会很难准确地确定问题是由哪个服务调用引起的。统一日志平台的作用就在于追踪每个请求的完整调用链路,收集链路上每个服务的性能和日志数据,从而使开发和运维人员能够快速发现并定位问题。
统一日志平台通过采集模块、传输模块、存储模块、分析模块实现日志数据的统一采集、存储和分析,结构图如下:
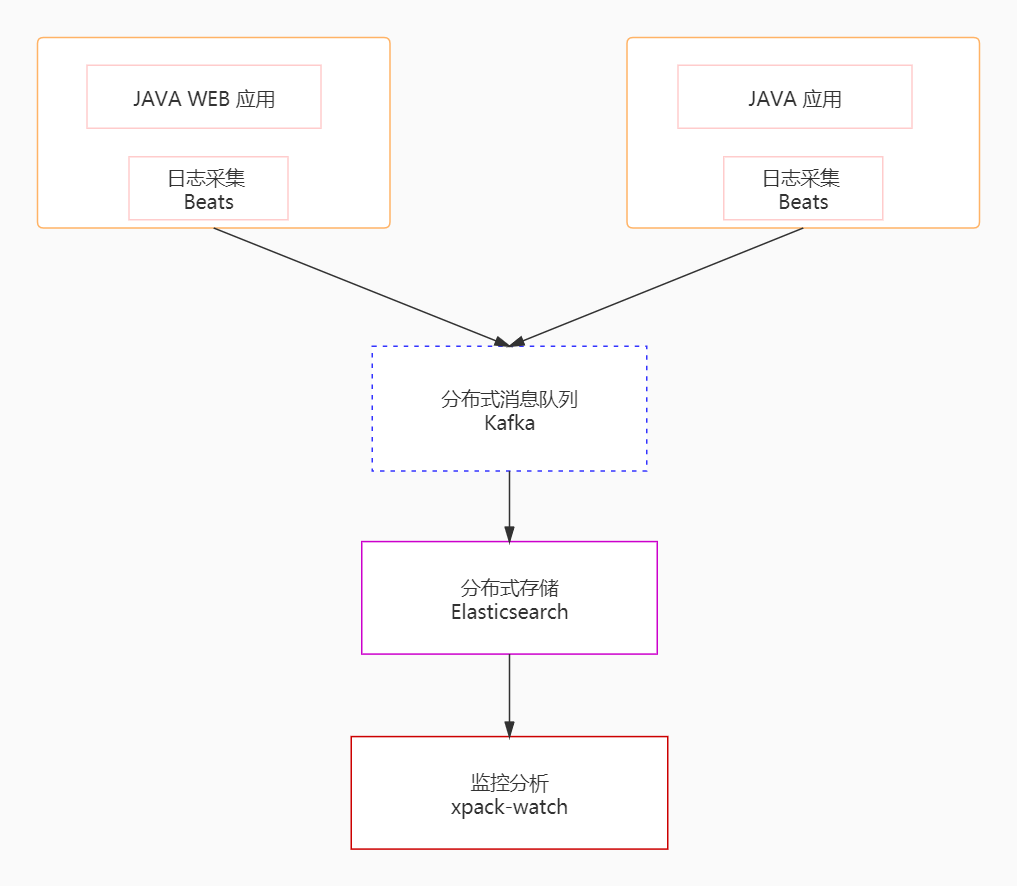
为了实现海量日志数据的收集和分析,首先需要解决的是如何处理大量的数据信息。在这个案例中,我们使用 Kafka、Beats 和 Logstash 构建了一个分布式消息队列平台。具体来说,我们使用 Beats 采集日志数据,这相当于在 Kafka 消息队列中扮演生产者的角色,生成消息并发送到 Kafka。然后,这些日志数据被发送到 Logstash 进行分析和过滤,Logstash 在这里扮演消费者的角色。处理后的数据被存储在 Elasticsearch 中,最后我们使用 Kibana 对日志数据进行可视化展示。
2.2、环境准备
本地
- Kafka
- ES
- Kibana
- filebeat
- Java Demo 项目
我们使用 Docker 创建以一个 名为 es-net 的网络
在 Docker 中,网络是连接和隔离 Docker 容器的方式。当你创建一个网络,我们定义一个可以相互通信的容器的网络环境。
docker network create es-net
docker network create 是 Docker 命令行界面的一个命令,用于创建一个新的网络。在这个命令后面,你需要指定你想要创建的网络的名称,在这个例子中,网络的名称是 “es-net”。
所以,docker network create es-net 这句命令的意思就是创建一个名为 “es-net” 的 Docker 网络。
2.3、基于Docker的ES部署
加载镜像:
docker pull elasticsearch:7.12.1
运行容器:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \elasticsearch:7.12.1-v es-data:/Users/lizhengi/elasticsearch/data \-v es-plugins:/Users/lizhengi/elasticsearch/plugins \
这个命令是使用 Docker 运行一个名为 “es” 的 Elasticsearch 容器。具体参数的含义如下:
-
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。 -
--name es:设置容器的名称为 “es”。 -
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":设置环境变量ES_JAVA_OPTS,这是 JVM 的参数,用于控制 Elasticsearch 使用的最小和最大内存。这里设置的是最小和最大内存都为 512MB。 -
-e "discovery.type=single-node":设置环境变量discovery.type,这是 Elasticsearch 的参数,用于设置集群发现类型。这里设置的是单节点模式。 -
-v es-data:/Users/lizhengi/elasticsearch/data和-v es-plugins:/Users/lizhengi/elasticsearch/plugins:挂载卷(volume)。这两个参数将主机上的es-data和es-plugins目录挂载到容器的/Users/lizhengi/elasticsearch/data和/Users/lizhengi/elasticsearch/plugins目录。 -
--privileged:以特权模式运行容器。这将允许容器访问宿主机的所有设备,并且容器中的进程可以获取任何 AppArmor 或 SELinux 的权限。 -
--network es-net:将容器连接到es-net网络。 -
-p 9200:9200和-p 9300:9300:端口映射。这两个参数将容器的 9200 和 9300 端口映射到主机的 9200 和 9300 端口。 -
elasticsearch:7.12.1:要运行的 Docker 镜像的名称和标签。这里使用的是版本为 7.12.1 的 Elasticsearch 镜像。
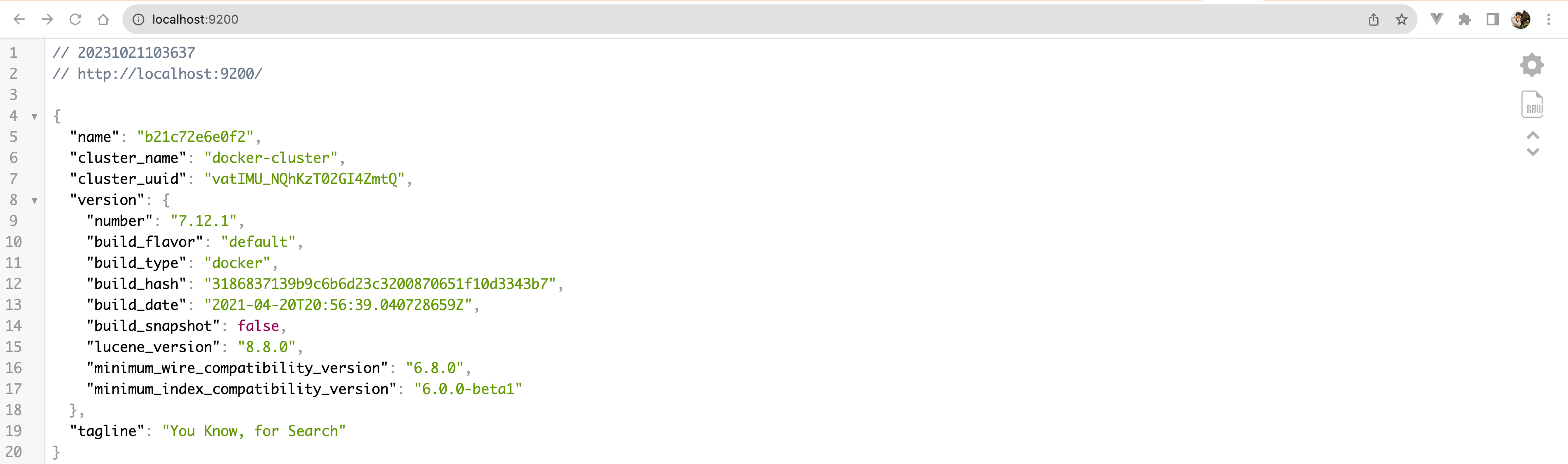
运行结果验证:随后便可以去访问 IP:9200,结果如图:
2.4、基于Docker的kibana部署
加载镜像:
docker pull kibana:7.12.1
运行容器:
docker run -d \--name kibana \-e ELASTICSEARCH_HOSTS=http://es:9200 \--network=es-net \-p 5601:5601 \
kibana:7.12.1
这是一个 Docker 命令,用于运行一个 Kibana 容器。下面是每个参数的解释:
-
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。 -
--name kibana:设置容器的名称为 “kibana”。 -
-e ELASTICSEARCH_HOSTS=http://es:9200:设置环境变量ELASTICSEARCH_HOSTS,这是 Kibana 的参数,用于指定 Elasticsearch 服务的地址。这里设置的是http://es:9200,表示 Kibana 将连接到同一 Docker 网络中名为 “es” 的容器的 9200 端口。 -
--network=es-net:将容器连接到es-net网络。 -
-p 5601:5601:端口映射。这个参数将容器的 5601 端口映射到主机的 5601 端口。 -
kibana:7.12.1:要运行的 Docker 镜像的名称和标签。这里使用的是版本为 7.12.1 的 Kibana 镜像。
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:

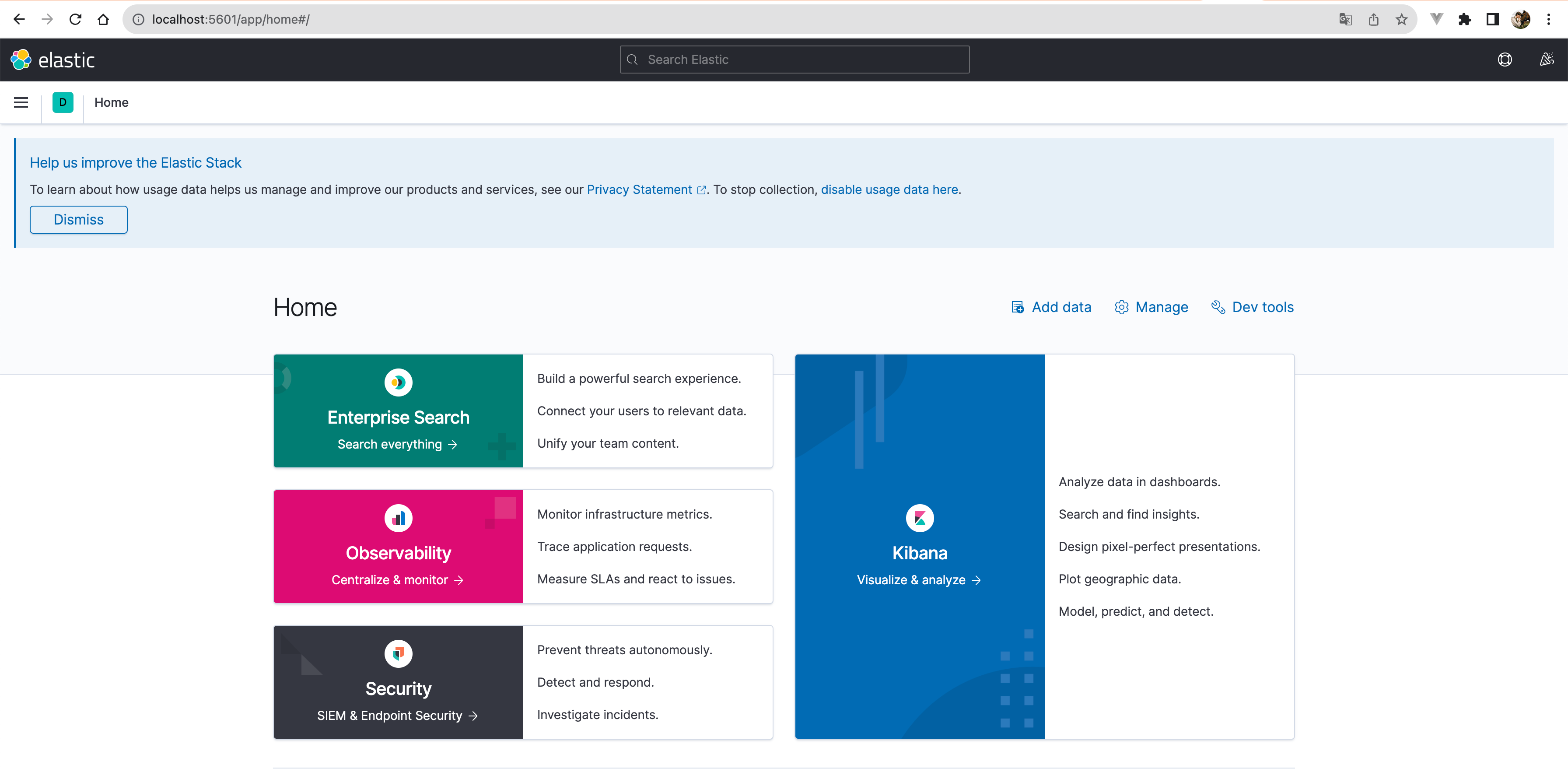
运行结果验证:随后便可以去访问 IP:9200,结果如图:
也可以浏览器访问:
2.5、基于Docker的Zookeeper部署
加载镜像:
docker pull zookeeper:latest
运行容器:
以下是一个基本的 Docker 命令,用于运行一个 Zookeeper 容器:
docker run -d \--name zookeeper \--network=es-net \-p 2181:2181 \
zookeeper:latest
这个命令的参数解释如下:
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。--name zookeeper:设置容器的名称为 “zookeeper”。--network=es-net:将容器连接到es-net网络。-p 2181:2181:端口映射。这个参数将容器的 2181 端口映射到主机的 2181 端口。zookeeper:latest:要运行的 Docker 镜像的名称和标签。这里使用的是最新版本的 Zookeeper 镜像。
2.6、基于Docker的Kafka部署
加载镜像:
docker pull confluentinc/cp-kafka:latest
运行容器:
以下是一个基本的 Docker 命令,用于运行一个 Kafka 容器:
docker run -d \--name kafka \--network=es-net \-p 9092:9092 \-e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092 \
confluentinc/cp-kafka:latest
这个命令的参数解释如下:
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。--name kafka:设置容器的名称为 “kafka”。--network=es-net:将容器连接到es-net网络。-p 9092:9092:端口映射。这个参数将容器的 9092 端口映射到主机的 9092 端口。-e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181:设置环境变量KAFKA_ZOOKEEPER_CONNECT,这是 Kafka 的参数,用于指定 Zookeeper 服务的地址。这里设置的是zookeeper:2181,表示 Kafka 将连接到同一 Docker 网络中名为 “zookeeper” 的容器的 2181 端口。-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092:设置环境变量KAFKA_ADVERTISED_LISTENERS,这是 Kafka 的参数,用于指定 Kafka 服务对外公布的地址和端口。这里设置的是PLAINTEXT://localhost:9092。confluentinc/cp-kafka:latest:要运行的 Docker 镜像的名称和标签。这里使用的是最新版本的 Confluent 平台的 Kafka 镜像。
2.7、基于Docker的Logstash部署
加载镜像:
docker pull docker.elastic.co/logstash/logstash:7.12.1
创建配置文件:
首先,你需要创建一个 Logstash 配置文件,例如 logstash.conf,内容如下:
input {kafka {bootstrap_servers => "kafka:9092"topics => ["logs_topic"]}
}output {elasticsearch {hosts => ["es:9200"]index => "logs_index"}
}
这个配置文件定义了 Logstash 的输入和输出。输入是 Kafka,连接到 kafka:9092,订阅的主题是 your_topic。输出是 Elasticsearch,地址是 es:9200,索引名是 logs_index。
运行容器:
然后,我们使用以下命令运行 Logstash 容器:
docker run -d \--name logstash \--network=es-net \-v /Users/lizhengi/test/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
docker.elastic.co/logstash/logstash:7.12.1
这个命令的参数解释如下:
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。--name logstash:设置容器的名称为 “logstash”。--network=es-net:将容器连接到es-net网络。-v /path/to/your/logstash.conf:/usr/share/logstash/pipeline/logstash.conf:挂载卷(volume)。这个参数将主机上的logstash.conf文件挂载到容器的/usr/share/logstash/pipeline/logstash.conf。docker.elastic.co/logstash/logstash:latest:要运行的 Docker 镜像的名称和标签。这里使用的是最新版本的 Logstash 镜像。
请注意,你需要将 /path/to/your/logstash.conf 替换为你的 logstash.conf 文件所在的实际路径。
2.8、基于Docker的Filebeat部署
加载镜像:
docker pull docker.elastic.co/beats/filebeat:7.12.1
运行容器:
首先,你需要创建一个 Filebeat 配置文件,例如 filebeat.yml,内容如下:
filebeat.inputs:
- type: logenabled: truepaths:- /usr/share/filebeat/logs/*.logoutput.kafka:enabled: truehosts: ["kafka:9092"]topic: "logs_topic"
这个配置文件定义了 Filebeat 的输入和输出。输入是文件 /usr/share/filebeat/Javalog.log,输出是 Kafka,连接到 kafka:9092,主题是 logs_topic。
然后,你可以使用以下命令运行 Filebeat 容器:
docker run -d \--name filebeat \--network=es-net \-v /Users/lizhengi/test/logs:/usr/share/filebeat/logs \-v /Users/lizhengi/test/filebeat.yml:/usr/share/filebeat/filebeat.yml \
docker.elastic.co/beats/filebeat:7.12.1
这个命令的参数解释如下:
-
docker run -d:使用 Docker 运行一个新的容器,并且在后台模式(detached mode)下运行。 -
--name filebeat:设置容器的名称为 “filebeat”。 -
--network=es-net:将容器连接到es-net网络。 -
-v /Users/lizhengi/test/Javalog.log:/usr/share/filebeat/Javalog.log:挂载卷(volume)。这个参数将主机上的/Users/lizhengi/test/Javalog.log文件挂载到容器的/usr/share/filebeat/Javalog.log。 -
-v /path/to/your/filebeat.yml:/usr/share/filebeat/filebeat.yml:挂载卷(volume)。这个参数将主机上的filebeat.yml文件挂载到容器的/usr/share/filebeat/filebeat.yml。 -
docker.elastic.co/beats/filebeat:latest:要运行的 Docker 镜像的名称和标签。这里使用的是最新版本的 Filebeat 镜像。
请注意,你需要将 /path/to/your/filebeat.yml 替换为你的 filebeat.yml 文件所在的实际路径。
这篇关于Elasticsearch实践:ELK+Kafka+Beats对日志收集平台的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




