beats专题
ELK+Kafka+Beats实现海量日志收集平台(三)
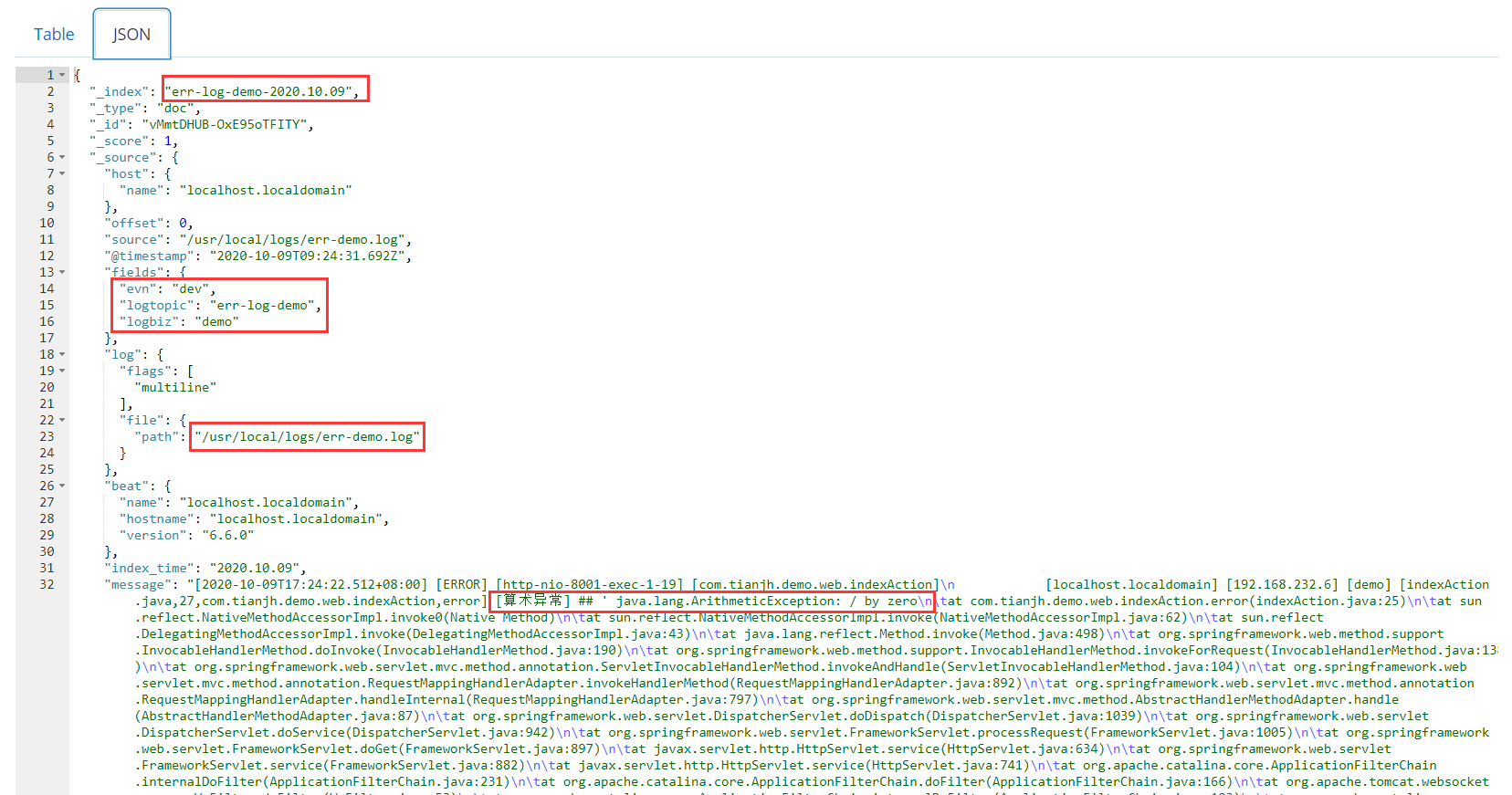
ELK+Kafka+Beats实现海量日志收集平台(三) 目录 六、将日志数据存储到Elasticsearch 七、Kibana展示 六、将日志数据存储到Elasticsearch 通过前面的步骤实现了日志数据的生产、收集和过滤。接下来就将收集之后的日志数据信息持久化到ElasticSearch上,然后在结合Kibana最终显示。 启动Elastic

ELK+Kafka+Beats实现海量日志收集平台(二)
ELK+Kafka+Beats实现海量日志收集平台(二) 目录 三、环境搭建 四、部署demo工程项目 五、测试 三、环境搭建 通过上一小节应用场景和实现原理的介绍,接下来实现所需环境搭建及说明架构图如下所示: 环境说明: 192.168.232.6 : 部署了demo项目(用于产生数据日志) filebe
ELK+Kafka+Beats实现海量日志收集平台(一)
ELK+Kafka+Beats实现海量日志收集平台(一) 目录 一、应用场景 二、实现原理 一、应用场景 利用ELK+Kafka+Beats来实现一个统一日志平台,它是一款针对大规模分布式系统日志的统一采集、存储、分析的APM 工具。在分布式系统中,有大量的服务部署在不通的服务器上,客服端的一个请求查询,就可能会调用后端多个服务,每个服务之间可能会相互调用

LeetCode 23 Merge k Sorted Lists,28ms beats 99% cpp.
1. 首先写出两个排序链表的函数 2. 然后两两进行调用上述函数即可 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/class Solution {p

Beats:在单个服务器上配置多个 Beats 实例
本文档作为如何在同一服务器上配置和运行 Filebeat/Metricbeat/Auditbeat 的多个实例的指南。 当你需要为同一台计算机上的不同应用程序或环境分离数据收集和处理时,此设置特别有用。 在今天的展示中,我们将以 Filebeat 为例来进行展示。此方法也适用于其他的 Beats。 复制 Filebeat 配置目录 要创建 Filebeat 的新实例,我们首先需要复制现有

Logstash 与 Beats 入门
公号:码农充电站pro 主页:https://codeshellme.github.io 目录 1,Logstash 处理流程2,Logstash 插件3,Logstash Queue4,Logstash 使用示例4.1,-e 参数4.2,-f 参数 5,Beats 介绍 Logstash 是一款免费开放的服务器端数据处理管道,能够从多个来源采集并转换数据,然后将数据发
Logstash 与 Beats 入门
公号:码农充电站pro 主页:https://codeshellme.github.io 目录 1,Logstash 处理流程2,Logstash 插件3,Logstash Queue4,Logstash 使用示例4.1,-e 参数4.2,-f 参数 5,Beats 介绍 Logstash 是一款免费开放的服务器端数据处理管道,能够从多个来源采集并转换数据,然后将数据发

Beats轻量级日志采集工具
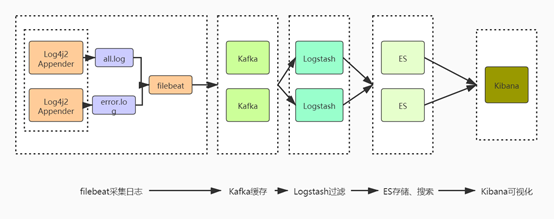
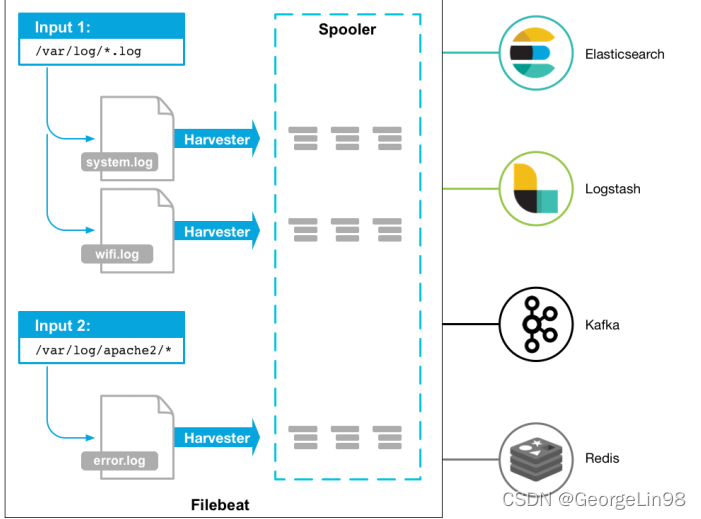
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。常用的Beats有Filebeat(收集文件)、Metricbeat(收集服务、系统的指标数据)、Packetbeat(收集网络包)等。这里主要介绍Filebeat插件。 一、架构图 二、安装Filebeat 官网地址:
Beats轻量级日志采集工具
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。常用的Beats有Filebeat(收集文件)、Metricbeat(收集服务、系统的指标数据)、Packetbeat(收集网络包)等。这里主要介绍Filebeat插件。 一、架构图 二、安装Filebeat 官网地址:
Beats与Logstash与Kibana知识概括
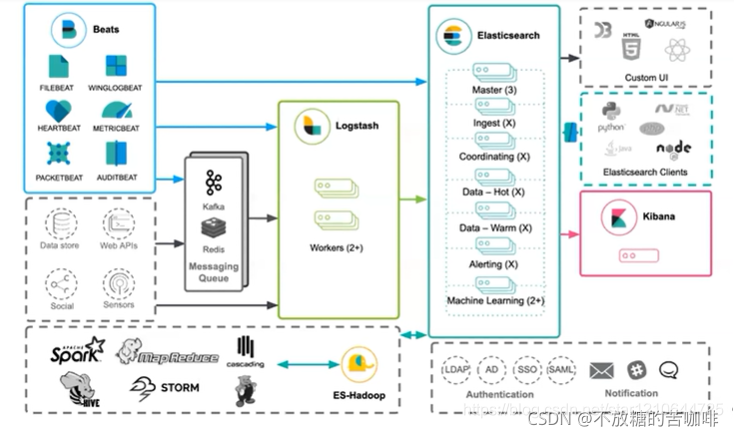
Beats与Logstash与Kibana知识概括 BeatsFilebeatMetricbeat KibanaLogstash Beats Beats简介: 轻量型数据采集器:Beats平台集合了多种单一用途数据采集器。它们从成百上千或成千上万台机 器和系统向Logstash 或 Elasticsearch发送数据。Beats 系列:全品类采集器,搞定所有数据类型。 ①Fil
Beats与Logstash与Kibana知识概括
Beats与Logstash与Kibana知识概括 BeatsFilebeatMetricbeat KibanaLogstash Beats Beats简介: 轻量型数据采集器:Beats平台集合了多种单一用途数据采集器。它们从成百上千或成千上万台机 器和系统向Logstash 或 Elasticsearch发送数据。Beats 系列:全品类采集器,搞定所有数据类型。 ①Fil
beats 与 logstash 的关系
Beats 是一个轻量型数据采集器,能够方便的与 Logstash 和 ElasticSearch 配合使用。 beats 并不是替换logstash的,beats 是用来优化logstash 的,logstash 的消耗性能比较多,如果只是单纯为了收集日志,使用logstash 就有点大材小用了,另外也有点浪费资源,而beats 是轻量级的用来收集日志的。 logstash 更加关注一件事,
beats 与 logstash 的关系
Beats 是一个轻量型数据采集器,能够方便的与 Logstash 和 ElasticSearch 配合使用。 beats 并不是替换logstash的,beats 是用来优化logstash 的,logstash 的消耗性能比较多,如果只是单纯为了收集日志,使用logstash 就有点大材小用了,另外也有点浪费资源,而beats 是轻量级的用来收集日志的。 logstash 更加关注一件事,
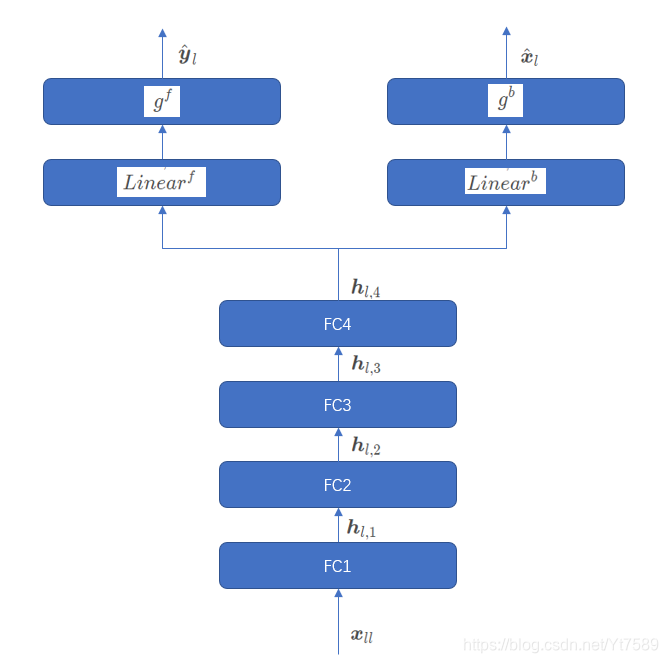
时间序列预测的Meta N-BEATS方法1
在时间序列预测中,目前占统治地位的方法仍然是传统的时间序列分析统计方法,虽然有个别方法中融入了深度学习模型,也基本上仅限于利用深度学习来学习这些时间序列统计模型的超参数。Bengio团队最新的Paper,将纯深度学习技术应用于时间序列预测,并在测试数据集上取得了比传统时间充列分析还要好的效果,他们分别发表了两篇文章,第一篇发表于19年5月,讲述了N-BEATS算法,第二篇发表于20年2月,将N-B
Elasticsearch实践:ELK+Kafka+Beats对日志收集平台的实现
可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个全文搜索引擎,它还提供了分布式的多用户能力,实时的分析,以及对复杂搜索语句的处理能力,使其在众多场景下,如企业搜索,日志和事件数据分析等,都有广泛的应用。 本文将介绍 ELK+Kafka+Beats 对日志收集平台的实现。 文章目录 1、关于ELK与BKELK1.1、ELK架构及其影响1.2、基于BKLE
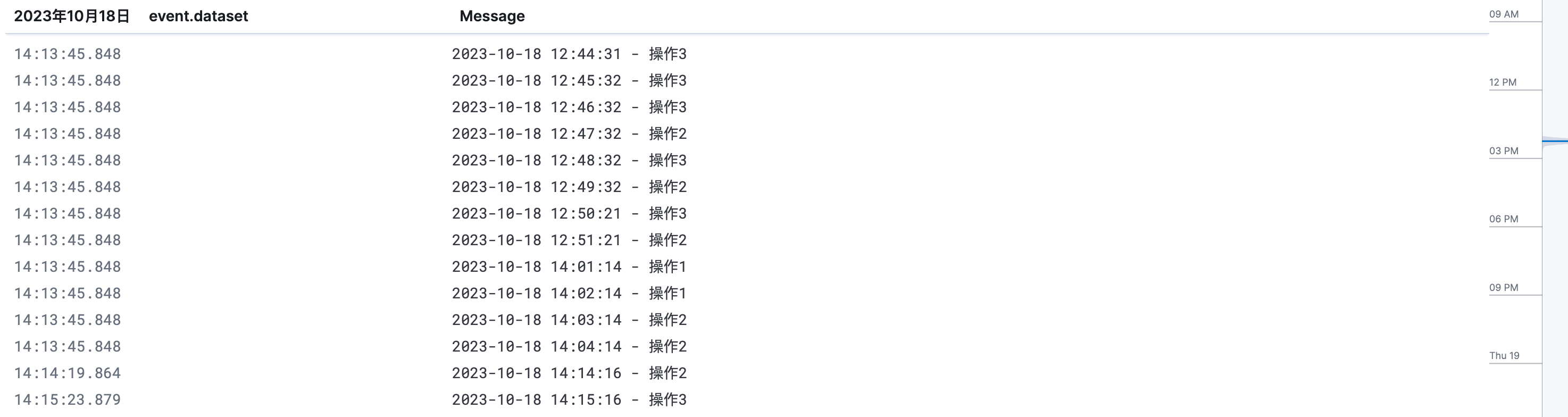
Elasticsearch系列组件:Beats高效的日志收集和传输解决方案
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个全文搜索引擎,它还提供了分布式的多用户能力,实时的分析,以及对复杂搜索语句的处理能力,使其在众多场景下,如企业搜索,日志和事件数据分析