本文主要是介绍Hadoop3教程(二十七):(生产调优篇)HDFS读写压测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- (146)HDFS压测环境准备
- (147)HDFS读写压测
- 写压测
- 读压测
- 参考文献
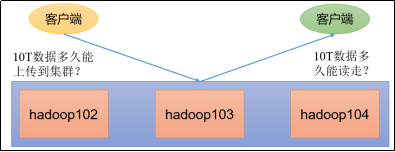
(146)HDFS压测环境准备
对开发人员来讲,压测这个技能很重要。
假设你刚搭建好一个集群,就可以直接投入生产了吗?
那当然不行,还需要对集群进行压测,一方面是测试集群的读写性能,多大的数据耗时多久才能读写完成,另一方面也是测试集群是否会崩溃。
HDFS的读写性能主要受网络和磁盘的影响比较大。教程里为了方便测试,将三台节点的虚拟机网络都设置为100mbps,先人为抹掉网络的影响。
注意,100mbps单位是bite,1字节等于8bite,所以实际设置的网速是12.5M/s.
(147)HDFS读写压测
hadoop自带的tests.jar包就是专门用来做压测的。
位置是/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar
这个包下有多个模块,比如说TestDFSIO模块,就是用来做HDFS读写压测的。
写压测
原理是什么呢?
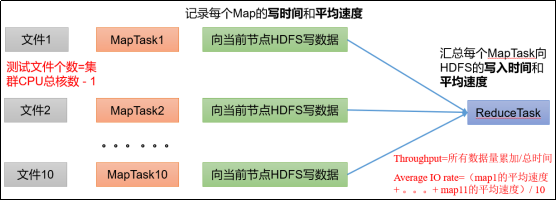
提交10个文件,开启10个MapTask,每个MapTask开始向当前节点HDFS写数据,每个Map会记录下写的时间和平均速度,而ReduceTask会汇总每个MapTask的写入时间和平均速度。
会计算3个指标:
- 所有数据量累加 / 所有数据写时间累加,即集群整体吞吐量Throughput;
- 所有平均速度累加 / 10,即平均MapTask的吞吐量Average IO rate;
- 方差,反应各个MapTask处理的差值,越小越均衡,IO rate std deviation。
使用方法以及对应的指标输出:
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB2021-02-09 10:43:16,853 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Date & time: Tue Feb 09 10:43:16 CST 2021
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Throughput mb/sec: 1.61
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Average IO rate mb/sec: 1.9
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: IO rate std deviation: 0.76
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Test exec time sec: 133.05
2021-02-09 10:43:16,854 INFO fs.TestDFSIO:
上面代码中,TestDFSIO指启用HDFS读写测试
-write表示启动写测试,
-nfFiles 10表示提交10个文件,对应生成MapTask的数量,而提交的文件数,一般是集群CPU总核数 - 1。
-fileSize 128MB表示每个文件大小是128MB。
注意,如果测试过程中出现异常,可以取消掉虚拟内存,具体方式为修改yarn-site.xml文件:
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
然后xsync yarn-site.xml分发配置,并顺便重启yarn。
测试结果怎么分析呢?
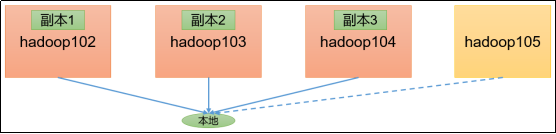
以上面的输出为例,我们的压测后速度是1.61,每个文件默认3个副本,但由于副本1,即文件本身都在节点1上,所以我们在写数据的时候,每个文件相当于只写了2个副本,即节点2和节点3上。

所以参与测试的文件就是20个。(如果客户端不在集群节点上,那么就三个副本都参与计算。就是30个文件了)
实测速度:1.61*20=32M/s
三台服务器的总带宽:12.5*3=37M/s
基本相当于所有网络资源都已经用满。
如果实测速度远远小于网络速度,且不能满足工作需求,那么可以采用固态硬盘或者增加磁盘个数等。
读压测
原理差不多,命令就换成了:
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB2021-02-09 11:34:15,847 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Date & time: Tue Feb 09 11:34:15 CST 2021
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Throughput mb/sec: 200.28
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Average IO rate mb/sec: 266.74
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: IO rate std deviation: 143.12
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Test exec time sec: 20.83
注意,模块用的都是TestDFSIO,但是后面的参数改成了-read
读的速度是很快的,且读取文件速度大于网络带宽。这是由于目前只有三台服务器,且有三个副本,数据读取就近原则,相当于都是读取的本地磁盘数据,没有走网络。
最后记得删除一下测试生成的数据:
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
因为是官方提供的包,所以我们在实现整个压测的时候,还是比较轻松的。
如果感情也能这么轻松就好了。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
这篇关于Hadoop3教程(二十七):(生产调优篇)HDFS读写压测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








