调优篇专题

二、Spark性能优化:资源调优篇
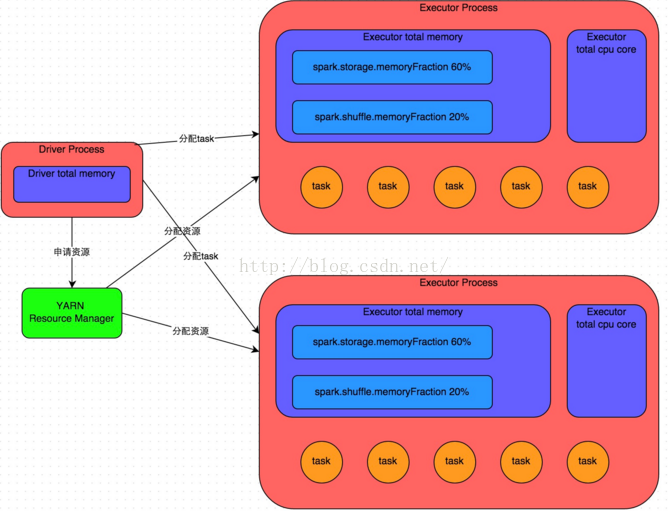
转自:https://blog.csdn.net/u012102306/article/details/51637366 在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参数,最后就只能胡乱设置,甚至压根儿不设置。资源参数设置的不
一、Spark性能优化:开发调优篇
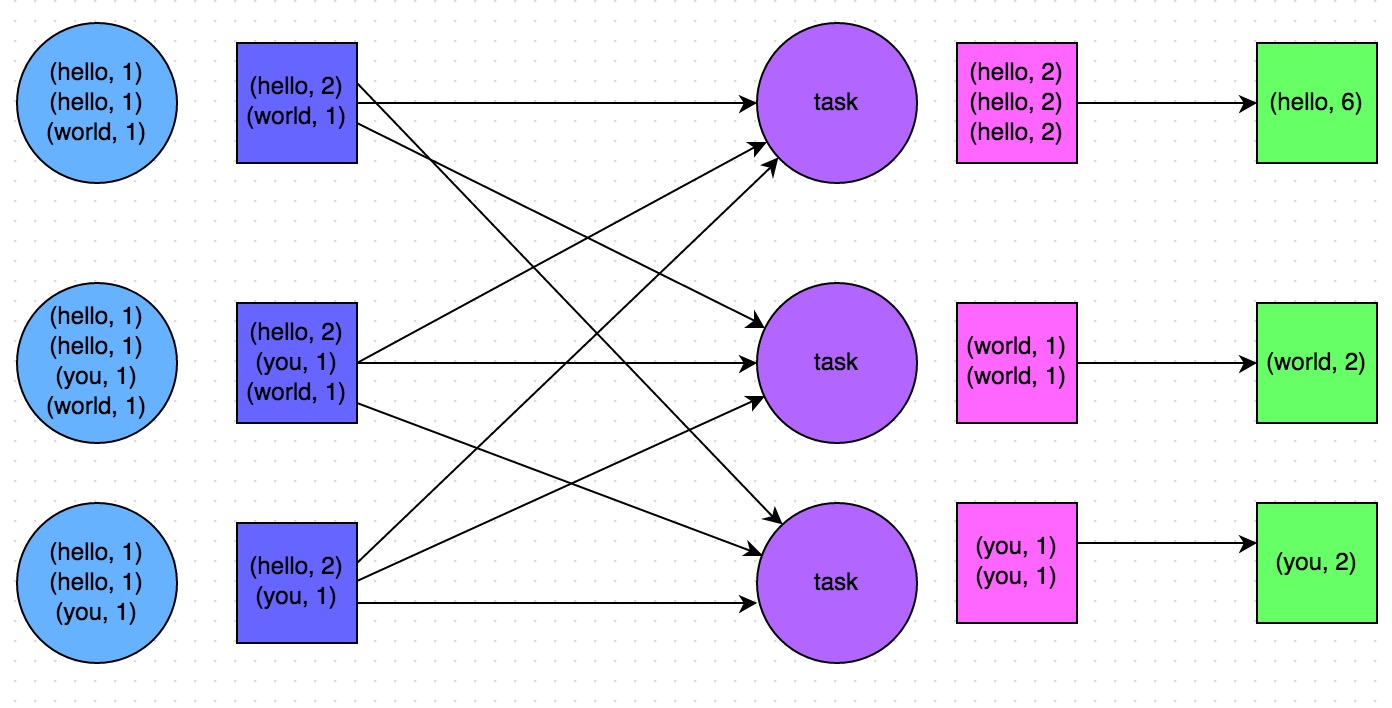
转自:https://blog.csdn.net/u012102306/article/details/51322209 1、前言 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。在美团•大众点评,已经有很多同学

MySQL性能调优篇(8)-NoSQL与MySQL的比较
MySQL数据库是一种关系型数据库,而NoSQL是一种非关系型数据库。它们在数据存储和处理方式、数据模型和可扩展性等方面存在一些明显的差异。本文将对MySQL数据库和NoSQL进行比较,并介绍它们的优势和劣势。 首先,MySQL使用表格的形式来存储数据,采用一对多的关系,并且要求在插入数据之前定义表结构。这种结构化的数据存储方式可以确保数据的一致性和完整性,同时也提供了强大的查询功能。下面是一个
MySQL性能调优篇(10)-数据库备份与恢复策略
MySQL数据库备份与恢复策略 数据库备份与恢复是数据库管理中非常重要的一环,对于保障数据的安全性和可靠性起着至关重要的作用。本文将介绍MySQL数据库备份与恢复的策略,包括备份类型、备份方法以及恢复策略。 1. 备份类型 1.1 完整备份 完整备份是备份数据库中所有数据和对象的一种方式。它可以创建数据库的一个镜像副本,包括表、索引、存储过程等。完整备份需要较长的时间和磁盘空间,但是恢复时
MySQL性能调优篇(7)-MySQL的集群部署和优化
MySQL的集群部署和优化 MySQL是一种常用的关系型数据库管理系统,可以用于存储和管理大量的结构化数据。为了满足高并发和大规模数据存储需求,MySQL的集群部署和优化变得非常重要。本篇博客将介绍MySQL的集群部署方法和一些优化技巧。 一、MySQL集群部署 主从复制 主从复制是一种非常常见的MySQL集群部署方法,它通过将一个MySQL实例作为主服务器,其他实例作为从服务器来实现数据的
MySQL性能调优篇(6)-主从复制的配置与管理
MySQL数据库主从复制是一种常用的数据复制和高可用性解决方案。它允许将一个MySQL主服务器上的数据自动复制到多个从服务器上,从而提供了数据冗余备份、读写分离等优势。本文将详细介绍MySQL数据库主从复制的配置与管理。 1. 原理概述 MySQL主从复制是基于二进制日志(Binary Log)实现的。主服务器将写操作记录在二进制日志中,并将这些日志传输给从服务器进行重放,从而使从服务器上的数

MySQL性能调优篇(3)-缓存的优化与清理
MySQL数据库缓存的优化与清理 数据库缓存在MySQL中扮演着非常重要的角色,它可以显著提高数据库的性能和响应速度。在本篇博客中,我们将介绍如何优化和清理MySQL数据库的缓存,以进一步提高数据库的效率。 优化缓存 1. 适当调整缓存大小 MySQL数据库的缓存大小对性能有着直接的影响。通过修改以下两个参数,可以调整缓存的大小: innodb_buffer_pool_size:适用于I
MySQL性能调优篇(2)-数据库统计信息的收集
MySQL是一个开源的关系型数据库管理系统,被广泛应用于各种规模的企业和网站。而数据库统计信息的收集对于数据库性能调优和监控非常重要。本文将介绍MySQL数据库中的统计信息的收集方式及其用途,以及如何使用相关命令和工具进行统计信息收集。 一、什么是数据库统计信息 数据库统计信息主要指数据库中包含关于表、索引、列以及其他数据库对象的元数据,通过收集这些统计信息,可以了解数据库中数据的分布情况、索
MySQL性能调优篇(1)-分析执行计划的方法
MySQL是一种常用的关系型数据库管理系统,它的性能优化对于数据处理的效率和性能至关重要。在优化MySQL数据库的过程中,分析执行计划是一个重要的步骤。执行计划是查询优化器在执行SQL语句时生成的一种解析树或操作流程图,用于描述MySQL数据库系统按照哪种方式执行查询操作。本文将介绍如何使用MySQL的语法来分析执行计划,并提供详细的示例。 在MySQL中,我们可以使用EXPLAIN关键字来分析
04:JVM调优篇(6)
目录 一、说一说JVM的内存模型 二、JAVA类加载的全过程是怎样的?什么是双亲委派机制?有什么作用? 三、怎么确定一个对象到底是不是垃圾? 什么是GC Root? 四、JVM有哪些垃圾回收算法? 五、JVM有哪些垃圾回收器?他们都是怎么工作的?什么是STW?他都发生在哪些阶段?什么是三色标记?如何解决错标记和漏标记的问题?为什么要设计这么多的垃圾回收器? 六、如何进行JVM调优?JV

Hadoop3教程(三十五):(生产调优篇)HDFS小文件优化与MR集群简单压测
文章目录 (168)HDFS小文件优化方法(169)MapReduce集群压测参考文献 (168)HDFS小文件优化方法 小文件的弊端,之前也讲过,一是大量占用NameNode的空间,二是会使得寻址速度变慢。 另外,过多的小文件,在进行MR的时候,会生成过多切片,从而启动过多的MapTask,很容易造成,启动MapTask的时间比MapTask计算的时间还长,浪费资源。 那怎
Hadoop3教程(三十六):(生产调优篇)企业开发场景中的参数调优案例概述
文章目录 (170)企业开发场景案例HDFS参数调优MapReduce参数调优YARN参数调优执行程序 参考文献 (170)企业开发场景案例 这章仅做兴趣了解即可。 需求:从1G数据中,统计每个单词出现次数。服务器3台,每台配置4G内存,4核CPU,4线程。 需求分析: 1G / 128m = 8个MapTask;1个ReduceTask;1个mrAppMaster 平均
Hadoop3教程(三十六):(生产调优篇)企业开发场景中的参数调优案例概述
文章目录 (170)企业开发场景案例HDFS参数调优MapReduce参数调优YARN参数调优执行程序 参考文献 (170)企业开发场景案例 这章仅做兴趣了解即可。 需求:从1G数据中,统计每个单词出现次数。服务器3台,每台配置4G内存,4核CPU,4线程。 需求分析: 1G / 128m = 8个MapTask;1个ReduceTask;1个mrAppMaster 平均
Hadoop3教程(三十五):(生产调优篇)HDFS小文件优化与MR集群简单压测
文章目录 (168)HDFS小文件优化方法(169)MapReduce集群压测参考文献 (168)HDFS小文件优化方法 小文件的弊端,之前也讲过,一是大量占用NameNode的空间,二是会使得寻址速度变慢。 另外,过多的小文件,在进行MR的时候,会生成过多切片,从而启动过多的MapTask,很容易造成,启动MapTask的时间比MapTask计算的时间还长,浪费资源。 那怎

Hadoop3教程(三十二):(生产调优篇)NameNode故障恢复与集群的安全模式
文章目录 (159)NameNode故障处理(160)集群安全模式&磁盘修复集群安全模式磁盘修复等待安全模式 参考文献 (159)NameNode故障处理 如果NameNode进程挂了并且存储的数据也丢失了,如何恢复NameNode? 首先,我们可以通过以下代码来模拟故障: (1)kill -9 NameNode进程 [atguigu@hadoop102 current]$
Hadoop3教程(三十二):(生产调优篇)NameNode故障恢复与集群的安全模式
文章目录 (159)NameNode故障处理(160)集群安全模式&磁盘修复集群安全模式磁盘修复等待安全模式 参考文献 (159)NameNode故障处理 如果NameNode进程挂了并且存储的数据也丢失了,如何恢复NameNode? 首先,我们可以通过以下代码来模拟故障: (1)kill -9 NameNode进程 [atguigu@hadoop102 current]$

Hadoop3教程(三十一):(生产调优篇)异构存储
文章目录 (157)异构存储概述概述异构存储的shell操作 (158)异构存储案例实操参考文献 (157)异构存储概述 概述 异构存储,也叫做冷热数据分离。其中,经常使用的数据被叫做是热数据,不经常使用的数据被叫做冷数据。 把冷热数据,分别存储在不同的存储介质里,从而达到对每个介质的利用率最高,从而实现整体最佳性能,或者说性价比更高(比如说高性能硬盘放经常使用的数据)。

Hadoop3教程(二十九):(生产调优篇)集群扩容及缩容(白名单与黑名单)
文章目录 (150)添加白名单(151)服役新服务器(152)服务器间数据均衡(153)黑名单退役服务器参考文献 这一章还算是比较重要的。 (150)添加白名单 白名单:在白名单里的主机IP地址,就可以用来存储数据以及互相之间的通信等。一般企业都会配置集群白名单,防止黑客攻击。 相应的,集群里也有黑名单,下几节会讲。 配置白名单步骤如下,仅做了解,所以直接复制的教程内
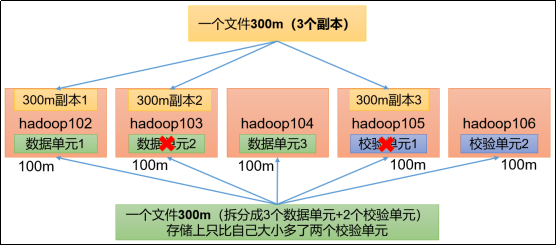
Hadoop3教程(三十):(生产调优篇)纠删码
文章目录 (155)纠删码原理纠删码原理纠删码相关命令纠删码策略解释 (156)纠删码案例实操参考文献 (155)纠删码原理 纠删码原理 默认情况下,一个文件在HDFS里会保留3个副本,以此提高数据的可靠性(容灾),但也带来了2倍的存储上的冗余开销。 于是Hadoop3.x引入了纠删码,采用计算的方式来提高数据的可靠性,可以节省50%左右的存储空间。 如上图(黄色部分)
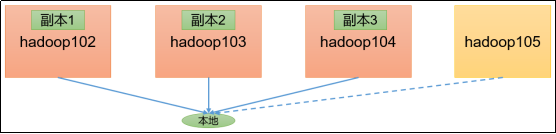
Hadoop3教程(二十七):(生产调优篇)HDFS读写压测
文章目录 (146)HDFS压测环境准备(147)HDFS读写压测写压测读压测 参考文献 (146)HDFS压测环境准备 对开发人员来讲,压测这个技能很重要。 假设你刚搭建好一个集群,就可以直接投入生产了吗? 那当然不行,还需要对集群进行压测,一方面是测试集群的读写性能,多大的数据耗时多久才能读写完成,另一方面也是测试集群是否会崩溃。 HDFS的读写性能主要受网络和磁盘的影