本文主要是介绍《文献阅读》 一种基于局部适应度景观的进化规划的混合策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 标题
- 一、摘要
- 结论
- 五、结论
- 研究背景
- 研究内容、成果
- 三、一种新颖的混合策略
- A.适应当地适应度景观的混合策略
- B.学习本地适应度景观的训练机制
- C. 使用混合策略的进化规划
- 四、实验结果与分析
- 常用基础理论知识
- 二、进化编程的基本操作
- 潜在研究点
- 参考文献
标题
A Mixed Strategy for Evolutionary Programming Based on Local Fitness Landscape
文献链接
一、摘要
进化规划(EP)的性能受到许多因素的影响(如突变操作符和选择策略)。虽然传统的高斯突变算子方法可能是有效的,但整个总体的初始规模可以非常大。这可能会导致传统的EP需要太长的时间才能达到收敛。为了解决这个问题,EP已经以各种方式进行了修改。特别是,对突变算子的修改可以显著提高EP的性能。然而,操作员只有在特定的适应度环境中才有效。因此,为了结合不同运营商的优点,提出了混合策略。混合策略的设计目前是基于应用单个操作人员的性能。与当地适应度景观的信息直接相关。本文提出了一种改进的自动适应局部混合策略,并实现了针对给定典型适应度景观选择最优混合策略的训练程序。该算法在一套23个基准函数上进行了验证。
结论
五、结论
本文提出了一种新的 EP,LMSEP,其特征是使用不同突变策略的混合的局部适应度景观。该方法解决了采用单一突变算子的传统 EP 的缺点。此外,还提供了一个训练程序,通过引入自学习算法,以高效、智能的方式提升 LMSEP。
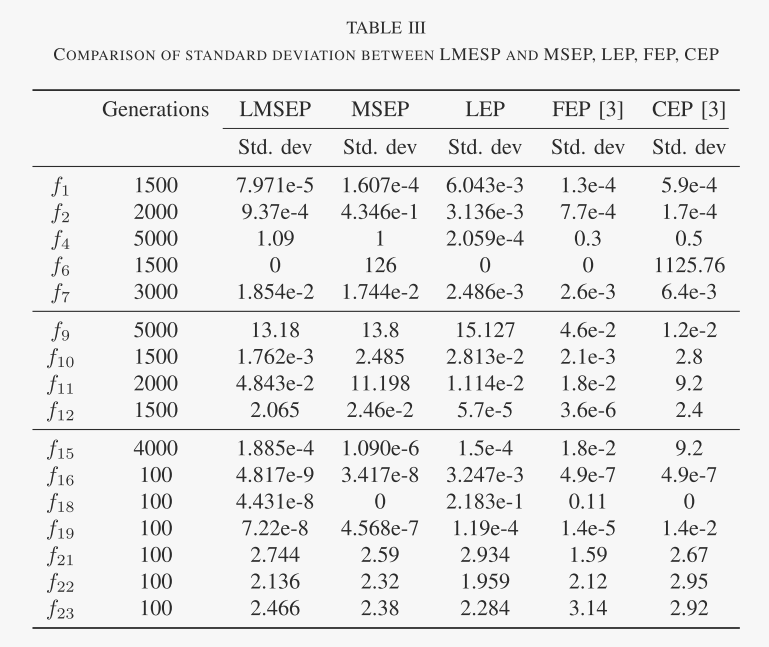
LMSEP 的性能首先在 7 个函数上进行训练,然后在一组 16 个基准函数上进行测试,与之前研究的 EP 进行比较。实验评估表明,新方法能够产生相对更可接受的结果。关于标准差的测试也表明LMSEP具有更稳健的性能。
研究背景
进化规划(EP)是一个分支,与其他著名的研究领域,如遗传算法和进化策略,进化计算起源于自然生物进化[1]。EP以人口为基础进行运作。目标不仅是对当前人口找到适当的调整,从而找到解决方案,而且是有效地执行过程。然而,在EP运行开始时是最优的参数设置在进化过程中可能会变得不合适。因此,希望在EP运行期间自动修改控制参数。控制参数可以有各种形式,从突变率、重组概率、种群大小到选择操作符。因此,我们引入了自适应技术来实现这种参数控制。该方法偏向于搜索空间的适当方向的分布,从而保持个体之间足够的多样性,以实现进一步的进化能力。
突变运算子作为EP的关键因素,在研究中引起了广泛的关注。原始的突变算子通常是高斯分布的,当应用于多模态函数时,通常缺乏鲁棒性。快速进化规划(FEP)中的一个高斯突变的取代基正如在[3]中所报道的,对于许多多变量函数需要更好的性能。然而,它对一些单峰函数的效率较低。通过利用基于L‘evy概率分布的突变进一步推广FEP,可以进一步改进。
不幸的是,没有一个单一的算法或算子是所有问题[5]的最佳平均水平,无论它们是否自适应。利用单一突变算子增强传统EP的一种方法是同时应用不同的突变算子,并将其优点整合在一起。这种策略被称为混合突变策略(借用博弈论[6]的概念)。混合策略的使用源于需要探索一种统一的方法来最大化各种自适应策略的能力,同时假设人们对手头的问题没有先验知识。
有不同的方法来设计一个混合的策略。例如,早期的实现是高斯分布和柯西分布[7]的线性组合。另一种方法是改进的快速EP(IFEP)[3],[4],它的工作原理是: 1)种群中的每个个体同时实施柯西和高斯突变并产生两个后代;2)选择较好的一个来构建下一代。这两种方法实现起来都很简单。强化学习理论也可以用于学习个体突变算子[8]。最近在努力调整突变策略方面取得了进展。
在以往的研究[9],[11]中,混合策略的设计主要利用每个运算符的奖励(即产生更高适应度的运算符将获得更好的奖励)。现有的工作很少与当地适应度景观的信息直接相关。然而,每个突变操作符的性能与适应度景观密切相关,因此处理种群所在的局部适应度景观是很重要的。本文提出了一种新的混合策略,以适应给定的适应度环境。
本文的其余部分组织如下。第二节概述了使用单一突变算子的常规EP的一般程序。第三节-A节将重点关注LMSEP。它首先介绍了一种关于当地健身景观的测量方法。然后描述了新的混合策略。然后,讨论了学习当地健身景观的训练程序。第四节报告了关于基准问题的实验结果。第五节总结了论文,并指出了进一步的研究。
研究内容、成果
本文提出了一种新的混合策略,以适应给定的适应度环境。
三、一种新颖的混合策略
本节描述了一种新的混合策略,旨在通过两种主要技术来改进传统的EP:
- 1)一种混合突变策略,基于观察到的局部适应度景观是决定EP突变行为的关键因素。
- 2)一种训练过程,其中引入了几个典型的学习函数(作为训练数据集),以确定混合突变算子相对于不同类型的局部适应度景观的最佳概率分布。
下面将处理这两个任务,然后将它们结合起来来处理一组目标函数。
A.适应当地适应度景观的混合策略
在EP中,一个突变算子由Eq(2)中给出的随机变量Xj确定。满足概率分布函数Fs。一个突变算子用s表示。目前,突变算子集由柯西分布、高斯分布、L‘evy等概率分布组成,该集合用S = {s1、···、sL}表示.
考虑到这个概念,可以发展出一种基于概率分布的混合策略。混合策略可以描述为:在每一代中,一个个体根据选择概率分布ρ(s)从其策略集中选择一个突变算子s。混合策略分布由π =(ρ(s1),···,ρ(sL))决定。
混合策略的关键问题是,如果可能的话,为每个个体的个体找出一个良好的最优概率分布(ρ(s1),···,ρ(sL))。这种分布是动态的,它会随着几代人的变化而变化。该问题可以形式化如下:给定第t代种群,决定π =(ρ(s1),···,ρ(sL))的概率分布,从而最大限度地向全局最优方向漂移,即,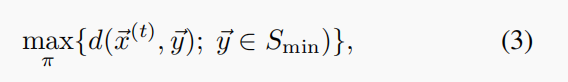
其中,Smin为全局最优集,d(x,y)为欧氏距离。
在理论上,这种最优混合策略π总是存在的,但在实际应用中,由于最优集Smin是未知的,因此不可能找到最优策略π。
相反,混合策略的设计是基于以下假设,即混合策略应该适应当地的适应度景观。本文从之前的实验[6]中得出以下原理: 1)如果局部适应度景观为单模态景观,则应用高斯突变的概率较高;2)如果局部适应度景观为多模态适应度景观,则应用柯西突变的概率较高。
设计上述混合策略有两个任务: (1)在真实空间Rn中给定一个个体x,确定它是什么类型的局部适应度景观;(2)基于局部适应度景观的特征,为混合策略分配一个概率分布。
考虑第一个任务。给定单个x,很难给出局部适应度景观的精确特征,计算成本也会非常重。相反,最好是寻求一种简化的方法。由于每个个体都在一个种群中,因此种群形成了对当地适应度景观的观察。然后从观察中得出了当地适应度景观的一个简单特征。根据种群中其他个体的距离对种群中最好的个体进行分类,然后检查每个个体的适应度如何随距离而变化。
如果适应度随着距离的增加,那么当地的适应度景观就像一个单峰景观;否则,它属于多模式景观。下面给出了一个实现这一点的一个简单过程。对于种群(x1、·、xµ),
- 1)找出人群中最好的个体,用xbest标记它。然后计算每个个体xi(i = 1,···,µ)与xbest之间的距离如下:
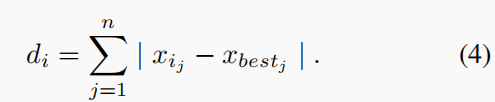
- 2)根据距离值对个体进行排序,结果升序为: k1、···、kµ。
- 3)计算个体对当地适应度景观的测量值。用χ表示度量值。假设初始值为0,如果f(ki+1)≤f(ki),则该值将增加1。将该值规范化为:
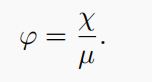
第二个任务是基于学习的。给定几个典型的适应度景观,计算不同混合策略在这些适应度景观上的表现,并找到每个景观特征φ的最佳混合策略。由于局部适应度景观实际上是一个模糊的概念,因此特征φ可以看作是观察到的适应度景观的粗糙度。
本文只使用了两个突变算子,即高斯突变和柯西突变,这两个突变算子的性能是众所周知的。他们的行为方式恰恰相反。因此,要确定混合策略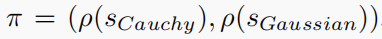
使用了一种简单的方法:使用柯西突变的概率可以被处理为在数值上等于特征φ。同样,高斯突变的概率等于(1−φ)。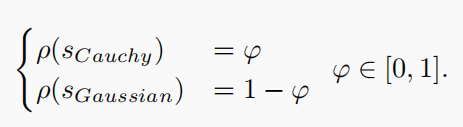
因此,对于仅包含柯西突变和高斯突变的混合策略,其概率分布为
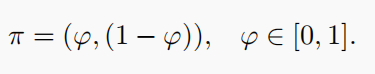
这是合理的,因为:如果φ = 0的值,则局部适应度景观更像是单峰景观,因此最好只使用高斯突变;如果φ = 1的值,则局部适应度景观非常粗糙,可能只应用柯西突变。随着φ值的增加,应用柯西突变的概率也应该增加。
B.学习本地适应度景观的训练机制
上述研究表明,设计了一种基于局部适应度景观的新型混合突变策略。它的实现涉及每一代应用的每个突变算子比例的波动。由于柯西突变和高斯突变的性能是众所周知的(它们的行为只是以相反的方式进行),因此混合策略π可以由等式来确定 (6).然而,这意味着一个现有的混合策略对应于特定的当地适应度景观已经通过人类干预确定。它也使算法抵抗使用任何新的突变算子,没有足够的先验知识的问题。鉴于此,如果针对给定的局部适应度景观φx的混合策略Sx可以自确定并推广到类似的情况下,这是可取的。
这可以通过在目标函数上运行算法之前引入一个训练程序来实现。在数值函数优化中寻找全局最小值的任务是通过学习基于先前性能[13]的经验来实现的。特别地,我们将一组函数作为训练示例。选择训练函数集{f1、···、fγ}为不同局部适应度景观的代表,如单模态函数、具有多个局部极小值的多模态函数和只有几个局部极小值的多模态函数。
为了构建实际的训练数据,需要局部适应度景观φ的特征以及相应的混合策略。它们可以利用第三节-A节中提出的算法得到。请注意,由于该算法用于测试函数优化的整个过程,所以它可以一直执行,直到满足一定的性能标准或达到最大的执行时间。在正常情况下,该算法将在一个平台状态下终止,这表明它无法找出任何更好的结果。此外,在达到这个状态之前,它通常会经历一个涉及大量中间状态的整个操作区域。这些中间状态可能会表现出各种各样的适应度景观,这些景观可能会随着时间的推移而变化。因此,如果算法运行在多模态函数上,经过大量代后,种群中的个体可能会缩小到全局最优附近的极限区域,从而得到类似的结果。由于它们之间的差异将相当小,潜在的当地适应度景观将看起来像一个单峰的。为了保证所有个体在整个训练函数的域中均匀随机地定位,对算法进行了轻微的修改。这是通过运行相对较小的代tT来实现的,每个训练函数的结果被平均。
根据方程 (5),基于一组训练函数{f1,····,fn},可以将特征φ设置为不同的值{φ1,····,φn}。因此,需要变异算子的概率分布。对于仅涉及柯西和高斯变异的混合策略,可以使用等式(6)计算 。为了与 φ 保持一致,概率分布也按 tT 进行平均,如下所示:
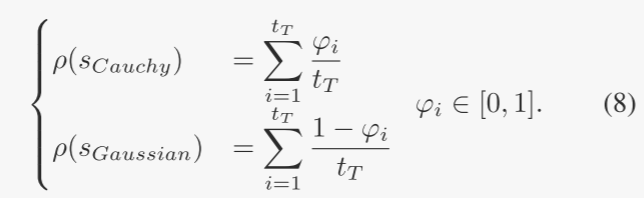
当选择 γ 个单独函数来形成训练示例时,计算 γ 个特征对和概率分布。特征集{φ1,···,φγ}和概率分布(ρ(s1),···,ρ(sL))具有一一对应的关系。可以合理地假设,给定一个特征,可以通过利用现有的概率分布 {φ1, · · ·, φγ} 从底层对应关系中学习到目标概率分布。
为了实现特征 φx 和目标 πx 之间对应关系的学习,采用基于距离的方法来近似最佳 πx。根据特征 φ 的值,所有训练数据以及 πx 都被视为一条线上的点。距离相对较小的两个点被视为邻居。给定一个目标特征φx,其值在[0, 1]区间内,训练数据{φ1,···,φγ}中的一个实例φa可以被找到作为其最近邻。因此,这种方法具有直观的吸引力,将与 φa 相关的 πa 视为所需的近似值。每个变异算子在所需 πx 中的概率为:

当目标特征πx附近只有一个点时,采用式(9)是合理的。然而,目标特征可能是在距离所在的位置给出的。
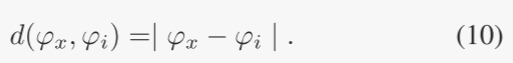
来自它的两个邻居的几乎相同。注意到这一点后,对上面的近似进行了修改,以便将目标特征的两个最近邻居(每侧一个)都考虑在内。每个邻居的贡献根据其到查询点 φx 的距离进行加权,以便将更大的权重放在较近的邻居上。将具有较小值的邻居表示为 φa,另一个表示为 φb,相对放置因子定义为
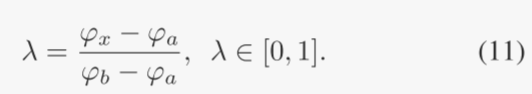
然后,目标 πx 的每个变异算子的概率被视为其两个邻居的线性组合:
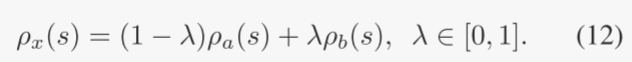
请注意,如果目标特征 φ 恰好取接近 0 或 1 的值,则可以使用式(9)了。在这种情况下,很明显,eq. (12) 不适用,因为只有一个现有邻居。
综上所述,所需π的计算如下:
距离规则:
- 1)给定目标特征 φx,在 γ 训练特征中识别其最近的两个点 φa 和 φb。
- 2)检查 φa 的值和 φb 相对于 φx 的值。如果它们都大于或小于 φx,则生成目标分布 π,如式(9)所示。 否则,采用eq.(12)。
C. 使用混合策略的进化规划
借助上述训练过程,可以相对于先前未知的局部适应度景观近似自动生成混合策略。这种新的基于混合策略的进化规划算法的细节如下:
训练:在应用混合策略之前,使用γ函数作为训练样例,生成混合策略特征φ与概率分布π之间的一组对应关系。
T1:初始化:随机生成由 µ 个个体组成的初始种群,每个个体由两个实数向量 ⃗x(0) i 和 ⃗σ(0) i (i ∈ 1, 2, · · · , µ) 表示。每个 x(0) i 是搜索空间中的随机点,每个 σ(0) i 是坐标偏差的向量。两个向量都有 n 个实值分量:对于 i = 1,····,μ。
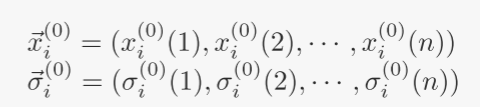
对于所有个体,其混合策略取相同的,即 π = (ρ(0)(1), ρ(0)(2), ),其中 ρ(0)(1), ρ(0) (2) 分别表示选择高斯变异算子和柯西变异算子的概率。

T2: 特征计算:对于种群中的每个个体i,局部适应度景观的特征可以确定为:给定一个种群(x1,···,xμ),在不失一般性的情况下,假设x1是种群中最好的个体。计算式(5)中给出的局部适应度景观的特征值 φ。
T3:混合策略调整:根据特征值φ根据式(6)调整概率分布πm。将 φ 指定为使用柯西变异的概率,将 (1 − φ) 指定为高斯变异。
T4:突变:将 t 表示为生成计数器。每个个体i根据其混合策略(ρ(t)(1),ρ(t)(2))从其策略集中选择一个变异算子,并使用该策略生成新的后代。算子集包括以下两个变异算子。在每个描述中,个体父 i 都以 (⃗x(t) i , ⃗σ(t) i ) 的形式编写。相应的后代 i′ 写成 (⃗x(t) i′ , ⃗σ(t) i′ ) 形式。
高斯变异:每个父代 i 产生一个子代 i′,如下所示: for j = 1, 2, · · · , n
表1 用于实验的 23 个函数分为 3 组。 7 个函数选择作为训练功能的功能以灰色背景突出显示。 n 代表函数的维度,S 代表函数的范围。


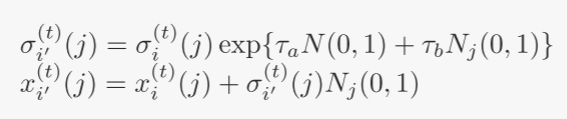
其中 N(0, 1) 代表标准高斯随机变量(对于给定 i 固定),Nj(0, 1) 代表为每个分量 j 生成的独立高斯随机变量。控制参数值 τa 和 τb 选择如下:

柯西变异:每个父代 i 生成一个子代 i′,如下所示: for j = 1, 2, · · · , n
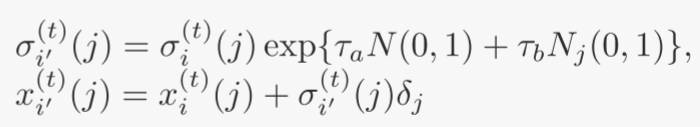
其中 δj 是标准柯西随机变量,为每个分量 j 生成。参数 τa 和 τb 设置为高斯突变中使用的值。变异后,总共产生μ个新个体。后代种群用 I′(t) 表示。
T5:适应度评估:计算父代群体和子代群体中个体的适应度。
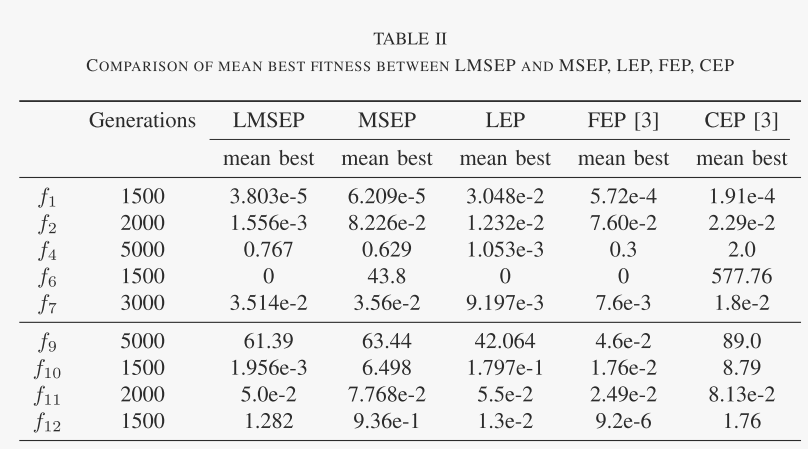
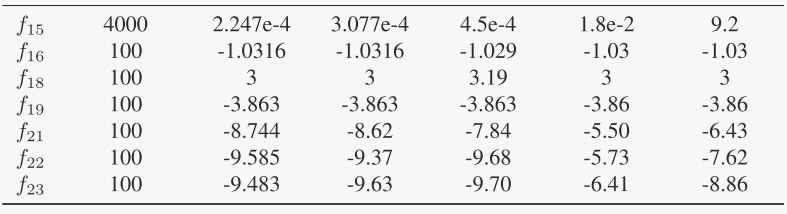
表2 LMSEP 与 MSEP、LEP、FEP、CEP 之间的平均最佳适应度比较
T6:q-锦标赛选择:对于父代和子代群体中的每个个体 i ∈ 1, 2, · · · , 2μ,获胜函数 wi 初始化为零。对应每个个体i,随机选择另一个个体 j 并将适应度 f(i) 与 f(j) 进行比较。如果 fi < fj,则个体 i 的获胜函数加一 (wi = wi + 1)。这个过程对每个个体执行 q 次。根据获胜函数,从亲本和后代群体中选择具有最高获胜值的 µ 个个体作为下一代。
T7:训练数据集的建立:步骤T2-T6重复γ次,这是训练过程的停止标准。然后,通过以下等式(8)对 φ 和 πm 进行平均 。一旦建立了这个训练数据集,在测试中就不需要重复这样的学习过程。这是因为测试过程仅需要使用该训练过程产生的混合策略。因此,在评估测试目标功能的总成本时,不包括训练过程的运行成本。
混合策略测试:训练完成后,具有所提出的混合策略的 EP 可以在各种目标函数上运行,并将其应用于已建立的数据集:
- P1:测试过程涉及EP的一般过程与特征计算相结合,为混合策略的使用做准备。几个步骤的执行方式与培训程序期间的执行方式相同。特别是,前两个步骤与T1 和 T2 相同。
- P2: 学习混合策略:有了特征 φx 的知识,与之相关的混合策略确定如下:使用式(11)中定义的距离在训练数据集中找到两个相似的特征。 考虑它们与 φx 的相对位置,然后根据距离规则得到混合策略的概率分布。
- P3:此后的步骤也与训练过程中相应的步骤(T4-T6)相同。
- P4:重复步骤P1-P2,直到满足停止标准。
四、实验结果与分析
为了验证所提出的基于局部适应度景观的混合策略的有效性,采用[3]中用于测试FEP的23个函数作为训练示例。表 I 中提供了这些函数的描述。它们分为 3 类:函数 f1 −f7 是单峰函数,函数 f8 − f13 是具有许多局部最小值的多峰函数,函数 f14 − f23 是仅具有少数局部最小值的多峰函数。混合EP中的参数设置与[3]中的参数设置相同。人口规模 µ = 100,锦标赛规模 q = 10,初始标准差取 σ = 3.0。对于除 f8 和 f11 之外的所有函数,它们使用的下界是 σmin = 10−5。 由于 f8 和 f11 比其余的具有更大的定义域,因此 σmin 被取为更大的值 10−4。
为了进行训练过程,选择一些函数作为训练样本,训练样本应包含所有三类函数。本文选择函数f3、f5、f8、f13、f14、f17和f20作为三类的代表。训练函数的生成 tT 限制为 5。这 7 个训练函数在表 I 中以灰色背景着色。
所有其他功能均用作实际测试功能。
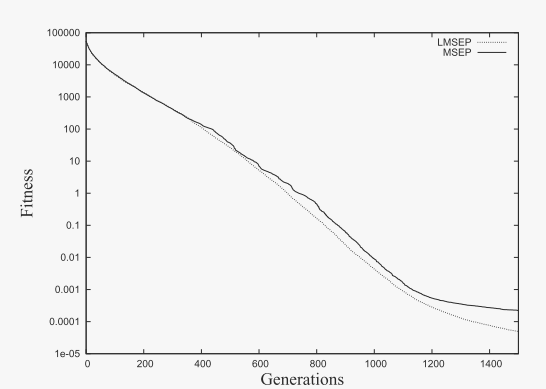
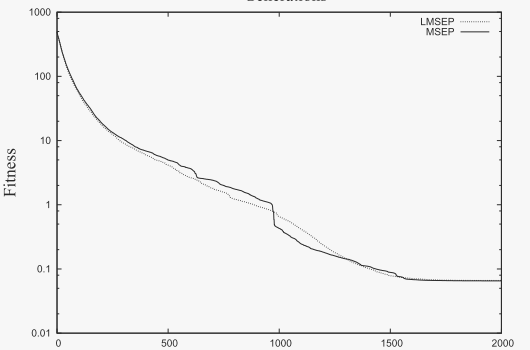
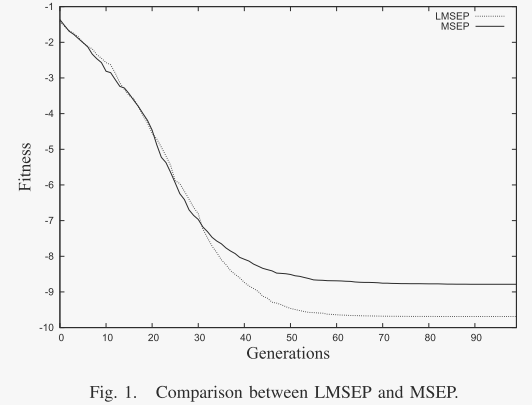
图 1. LMSEP 和 MSEP 之间的比较。
停止标准为:函数f1、f6、f10和f12运行到1500代时停止运行,f2和f11运行到2000代时停止运行,f4和f9运行到5000代时停止运行,f15运行到4000代时停止运行。其余的将运行 100 次迭代。对于除 f4 之外的所有函数,它们使用的下界是 σmin = 10−5。 f1 −f15 的结果是 50 次独立试验的平均值,f16 − f23 的结果是 1000 次独立试验的平均值。
使用混合策略突变的 EP 的性能与 MSEP、SPMEP、LEP、FEP 和 CEP 的性能进行了比较,其结果如表 II 和表 III 所示。为了简单起见,本工作中提出的算法(与局部适应度景观相关)被命名为 LMSEP。MSEP [9]是一种具有混合变异策略的EP,其中根据动态概率分布考虑并自适应地使用不同的变异算子。CEP 是使用高斯变异的 EP,FEP 代表使用柯西变异的 EP,然后扩展到 LEP。表 II 列出了基准函数中生成的平均最佳适应度的结果,从中可以看出,LMSEP 在类似的精度水平下产生了合理的结果,这表明混合策略的性能至少与纯策略一样好。然而,可以看出,通过使用LEP或FEP,可以获得f4、f7、f9和f12的显着改善的结果。通过探究LEP和FEP的突变机制,可以认为主要原因是LEP和FEP比LMSEP具有相对更高的灵活性。由于LMSEP中特征和混合策略是一一对应的,一旦局部适应度景观特征没有改善,混合策略的更新将在某一代停止。结果,在搜索后期产生大步跳的能力降低了[3]。分配一个以百分比表示的参数可能是有利的,以使过程具有不符合一对一对应关系的有限灵活性。
图 1 提供了两种混合策略 LMSEP 和 MSEP 在 50 次运行中发现的总体平均值的图形比较,其中两种算法都采用两种类型的变异算子,即高斯变异和柯西变异。这里测试了两个基准函数 f1、f11 和 f22。很明显,LMSEP 可以在 f1 和 f22 上进一步搜索,而 MSEP 无法找到相对改进的结果。对于 f11,LMSEP 显示出比 MSEP 更快的收敛速度。 LMSEP 很快达到约 1000 代中有 1 代。此后,MSEP 表现出大幅下降并超过了 LMSEP。然而最终,两种算法在 1700 代左右达到了大致相同的结果。考虑到所有情况,过程曲线表明 LMSEP 引入了更有效的进展。
表 III 中给出的 LMSEP 评估标准差也与使用其他方法获得的标准差进行了比较。根据结果,LMSEP 在除 f4、f7、f9 和 f12 之外的大多数函数上表现出相似的性能。这一事实表明,LMSEP 至少具有与单一纯策略相同的稳定性。然而,LMSEP 在 LEP 和 FEP 很好应用的某些功能上并没有表现出更好的性能。这表明混合策略的搜索有时无法关注全局最小值所在的位置。这意味着本文中的局部适应度景观特征的调整,即φ的实现,还有待在今后的研究中仔细修改,以期得到更好的结果。
常用基础理论知识
二、进化编程的基本操作
本文利用EP求出一个连续函数f (x)的最小xmin,即,
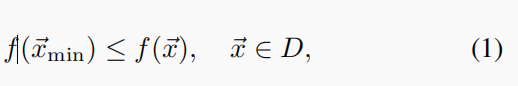
其中D是Rn中的一个超立方体,n是维数。使用单一突变操作子的传统EP可以描述如下:
1)Initialization:
- 随机生成一个由µ个个体组成的初始种群。每个个体都由一组真实的向量(xi,σi)表示,对于,i = 1,···,µ.
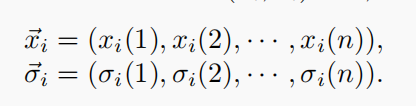
2)Mutation:
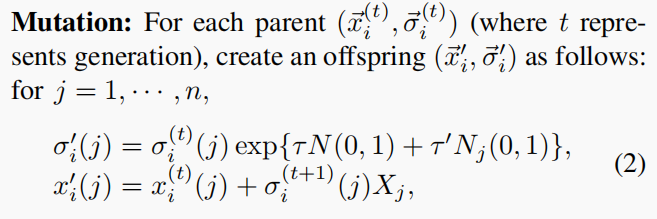
- 其中N(0,1)表示为给定的i生成的高斯随机变量,Nj(0,1)是为每个j生成的高斯随机变量,Xj是为每个j生成的随机变量。控制参数τ和τ‘的选择与[3]中的相同。
3)Fitness Evaluation:
- 对于µ及其µ后代,计算其适应度值f1、f2、···、f2µ。
4)Selection:
- 为父代和后代群体中的每个个体定义并初始化一个获胜函数,分别为wi = 0,i =
1、2、···、2µ。对于每个个体i,选择一个适应度函数,比如fj,并比较这两个适应度函数。如果fi小于fj,那么让wi = wi +
1。对每个人执行这个程序q次。选择拥有最大获胜价值的µ个体,作为下一代的父母。
5).
- 重复步骤2-4,直到满足停止标准为止。为了避免步长σ降得太低,应该在σ [12]上设置一个下限σmin。因此,更新σ的修正方案如下:
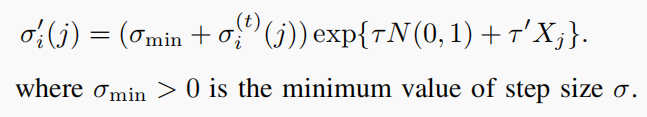
潜在研究点
尽管训练过程可以带来快速的性能,但它偶尔可能会错过某些应该检查的区域。为了解决这个问题,训练程序的微调仍然是一个活跃的研究。例如,可以潜在地采用向后跳转过程。由于使用 FEP 和 LEP 可以获得兼容的满意结果,因此更好地实现 φ 参数可能会很有用。此外,可以考虑更多的变异算子(例如 L´evy 变异)。最后,向其他类型的算子引入混合策略(如交叉和选择)也构成了未来工作的一个有趣的部分。
参考文献
[1] L. J. Fogel, A. J. Owens, and M. J. Walsh, Artificial Intelligence
Through Simulated Evolution. New York, NY, USA: John Wiley
& Sons, Inc., 1966.
[2] D. B. Fogel, Evolutionary computation: toward a new philosophy of
machine intelligence. Piscataway, NJ, USA: IEEE Press, 1995.
[3] X. Yao, Y. Liu, , and G. Lin, “Evolutionary programming made faster,”
IEEE Transactions on Evolutionary Computation, vol. 3, pp. 82–102,
1999.
[4] C.-Y. Lee and X. Yao, “Evolutionary programming using mutations
based on the l´evy probability distribution,” IEEE Transactions on
Evolutionary Computation, vol. 8, no. 1, pp. 1–13, 2004.
[5] D. H. Wolpert and W. G. Macready, “No free lunch theorems for op-
timization,” IEEE Transactions on Evolutionary Computation, vol. 1,
no. 1, pp. 67–82, 1997.
[6] J. He and X. Yao, “A game-theoretic approach for designing mixed
mutation strategies,” in ICNC’05 (LNCS 3612). Springer-Verlag,
2005, pp. 279–288.
[7] K. Chellapilla, “Combining mutation operators in evolutionary pro-
gramming,” IEEE Transaction on Evolutionary Computation, vol. 2,
no. 3, pp. 91–96, 1998.
[8] H. Zhang and J. Lu, “Adaptive evolutionary programming based on
reinforcement learning,” Information Science, vol. 178, no. 4, pp. 971–
984, 2008.
[9] H. Dong, J. He, H. Huang, and W. Hou, “Evolutionary programming
using a mixed mutation strategy,” Information Sciences, vol. 177, no. 1,
pp. 312–327, 2007.
[10] L. Shen and J. He, “Evolutionary programming using a mixed strategy
adapting to local fitness landscape,” in Proceedings of the 2009 UK
Workshop on Computational Intelligence. University of Nottingham,
2009, pp. 92–97.
[11] Y. Liu, “Operator adaptation in evolutionary programming,” in ISICA,
2007, pp. 90–99.
[12] G. B. Fogel, G. B. Fogel, and K. Ohkura, “Multiple-vector self-
adaptation in evolutionary algorithms,” BioSystems, vol. 61, pp. 155–
162, 2001.
[13] T. M. Mitchell, Machine Learning. New York, NY, USA: McGraw-
Hill Science/Engineering/Math, March 1997.
这篇关于《文献阅读》 一种基于局部适应度景观的进化规划的混合策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







