本文主要是介绍谣言检测论文精读——4.WWW2019-Detect Rumors on Twitter by Promoting Information Campaigns with GAN,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.Abstract
分析表明,谣言的广泛传播通常是故意宣传的宣传活动的结果,这些宣传活动旨在形成对相关新闻事件的集体意见。 在本文中,我们尝试与自身对抗这种混乱,以使自动谣言检测更加稳健和有效。 我们的想法受到源自生成对抗网络(GAN)的对抗学习方法的启发。 我们提出了一种 GAN 风格的方法,其中生成器旨在产生不确定或冲突的声音,使原始对话线程复杂化,以迫使鉴别器从增强的、更具挑战性的示例中学习更强的谣言指示表示。
谣言制造者可以利用宣传活动来纠缠公众舆论或影响集体立场,以使其广泛传播和放大。 这对数据驱动的方法提出了重大的技术挑战,因为文本模式和其他显式特征变得难以区分。 共存的各种冲突和不确定的声音会严重干扰有用特征的学习(或提取)。
在本文中,我们提出了一种全新的谣言检测方法,通过利用信息运动机制并以可控的方式推广它,以实现更稳健和有效的检测。 与计算机视觉等旨在学习强大(图像)生成器的典型 GAN 样式模型不同,我们的目标是迫使我们的(谣言)鉴别器更具辨别力。为了保留原始高频模式的判别能力,我们使用生成的类似活动的示例和原始示例在增强的训练数据上训练判别器。
我们论文的主要贡献有四个方面:
- 据我们所知,这是第一个使用基于文本的 GAN 风格框架进行谣言检测的生成方法,我们使文本生成器和判别器相互增强 用于增强谣言指示模式的表示学习。
- 我们将谣言传播建模为生成信息活动,用于生成令人困惑的训练示例,以挑战其检测能力的鉴别器。
- 在 GAN 风格的框架下,我们强化了我们的鉴别器,它在一组由生成器补充的更具挑战性的示例上进行训练,专注于学习低频但有鉴别力的模式。
- 我们通过实验证明,我们的模型比基于两个公共基准数据集的最先进的基线更加稳健和有效,用于 Twitter 上的谣言检测任务。
2.PROBLEM STATEMENT
这一小结给出问题表示
谣言检测任务可以定义为一个二元分类问题,其目的是从训练声明中学习分类器,标记为谣言或非谣言,以预测测试声明的标签。
由于一个声明的文本有限,通常篇幅很短,所以在Twitter谣言检测任务中,一般一个声明由与声明相关的一组帖子祖成。具体表示为:我们将谣言数据集表示为 {X},其中每个X = (y, x1x2 . . . xT ) ,X 由声明的真实标签 y ∈ {N, R} (即,非谣言或谣言)和一系列相关帖子 X1X2 … xT 组成 ,其中每个 xt 可以表示一个帖子或更一般地表示时间间隔内的一批帖子,并以时间步长t为索引。我们将实例(声明)X 写为 Xy,即 XR表示谣言,XN表示非谣言。
3.GENERATIVE ADVERSARIAL LEARNING FOR RUMOR DETECTION
3.1Controversial Example Generation
这一小结介绍如何用生成器生成数据
我们的基本思想是在生成对抗学习机制的启发下,加强谣言指示特征的表示学习。
我们的生成模型旨在针对给定的声明产生不确定或相互冲突的声音,从而使过去依赖于重复模式的谣言和非谣言的区分变得更加困难。一种通用的方法是将我们的生成器转换为可训练的模型,该模型可以涵盖各种表达变化。为此,我们设计了两个生成器,一个用于扭曲非谣言使其看起来像一个谣言,另一个用于“粉饰”谣言使其看起来像一个非谣言。1)GN-R对非谣言主张产生怀疑或反对的声音; 2) GR-N产生支持谣言的声音。 我们定义了一个函数 fg 来制定我们的生成模型:
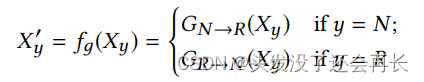
其中 Xy 是来自训练集的原始实例,可以是谣言或非谣言,Xy一撇 是带有生成器的变换实例,而标签保持变。
考虑到每个实例中帖子的时间序列结构,我们使用序列到序列模型进行生成转换,如图所示。我们通过 RNN 编码器,然后通过 RNN 解码器从中生成转换后的序列 X y一撇 。

GRU-RNN 编码器:我们将相关帖子分批成时间间隔,并将每个批次视为时间序列中的单个单元,遵循 [12] 中描述的类似时间分割,使用 RNN,我们将每个输入单元 xt ∈ Xy 映射到 一个隐藏向量 ht,我们使用 GRU来存储隐藏表示:

其中 GRU(·)表示标准 GRU 转移方程,xt 是输入单元,表示为从落入第 t 个时间步的帖子计算的词汇单词的 tf*idf 值的向量,ht−1 指的是先前的隐藏 s状态 和θg代表 GRU 的所有参数。GRU-RNN编码器的最后一个时间步 hT 的输出将是 Xy 的隐藏表示。 请注意,序列长度 T 不是固定的,它可以随不同的实例而变化。
GRU-RNN 解码器:我们现在描述将 hT 转换为生成的序列 X′y = x′1x′2. . . x′T. 的 GRU-RNN 解码器。 具体来说,每个单元是使用 GRU 顺序生成的,然后是一个 softmax 输出函数。 在每个步骤 t 中,softmax 输出层通过计算分布将通过 GRU 获得的隐藏状态 h’t 映射到一批帖子的目标表示 x’t+1.
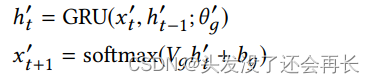
其中 h′t−1 是 GRU 解码器之前的隐藏状态,θ′g表示 GRU2 内部的所有参数,Vg 和 bg 是输出层的可训练参数。
3.2GAN-Style Adversarial Learning Model
这一小结介绍GAN对抗学习模型
前面已经介绍了生成器生成数据的方法,但 一个关键的问题是如何控制生成器产生所需的。 为此,我们使用判别器的性能作为奖励来指导生成器。 在介绍鉴别器之前,让我们介绍一下我们的 GAN 风格模型的架构和控制机制,如图所示,它由一个对抗性学习模块和两个重建模块(一个用于谣言,另一个用于非谣言)组成。
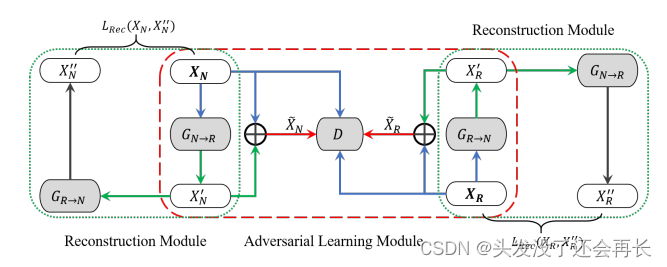
Adversarial learning module:在我们的模型中,鼓励生成器生成类似活动的实例来欺骗鉴别器,以便鉴别器可以专注于学习更多的鉴别特征。 这样的目标提出了一个类似于对抗性学习的训练目标 [7],我们将对抗性损失表述为基于生成器增强训练数据的鉴别器损失的负数:
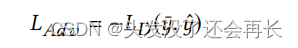
其中 LD (·) 是在给定输入实例的情况下,真实类概率分布 y 和判别器预测的类分布 y帽 之间的损失。
我们将生成的示例和原始示例结合起来,通过它们的并集来增加训练集,即 {{Xy~} U {Xy}},其中 X y ~= X y + Xy’ 是原始示例和生成示例的元素相加 例子
Reconstruction module:生成器可能会通过改变故事的某些基本方面来将原始示例扭曲到意想不到的方向。为了避免这种情况,我们引入了一种重建机制来使生成过程可逆。 这个想法是,固执己见的声音将通过两个相反方向的生成器来逆转,以最大限度地减少信息保真度的损失。 我们定义重构函数如下:
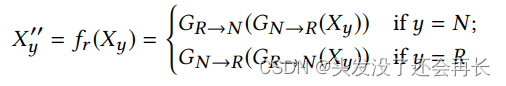
其中 Xy" 是通过两个相反的生成器从原始实例 Xy 重建的实例。我们将 Xy" 和 Xy 之间的差异表示为重建损失:
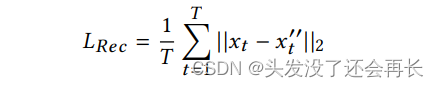
其中 Xt 和 xt" 分别是原始序列和重构序列中的第 t 个单元,T 是序列长度, || · ||2 是向量的 L2 范数。
3.3Rumor Discriminator
我们基于 RNN 谣言检测模型 [12] 构建鉴别器,给定一个实例(原始的或生成的),RNN 模型首先使用 GRU 将第 t 步的相关帖子 Xt 映射到隐藏向量 St:

其中 st-i 是前一个隐藏向量,θd 表示判别器中的所有 GRU 参数。
在 [12] 之后,我们输入隐藏向量 sT 在最后一个时间步,表示为用于对实例进行分类的 2 类 softmax 函数:

其中 y帽 是两个类别的预测概率向量,Vd 是输出层的权重矩阵,bd 是可训练偏差。 判别器的损失定义为预测类和真实类分布之间的平方误差: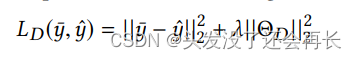
其中 y 和 y帽 分别是真值和预测类概率分布,s, ΘD = {θd,Vd,bd} 是判别器参数,A 是权衡系数。
3.4Generative Adversarial Training Algorithm

生成器和判别器交替使用随机梯度下降和小批量 [2] 进行训练,在每个 epoch 中,生成有争议的示例并将其扩充到原始训练数据中。 我们使用等式针对增强的训练示例优化生成器和判别器。 8 通过算法 1 中的步骤 8-11 执行最小-最大游戏。
EXPERIMENTS AND RESULTS
数据集:
我们使用两个公共数据集 TWITTER [12] 和 PHEME [22] 进行实验评估,此外,我们过滤掉了少于 10 条推文的声明,并平衡了这两个类别的实例数量。 结果数据集的统计数据见表

实验结果:
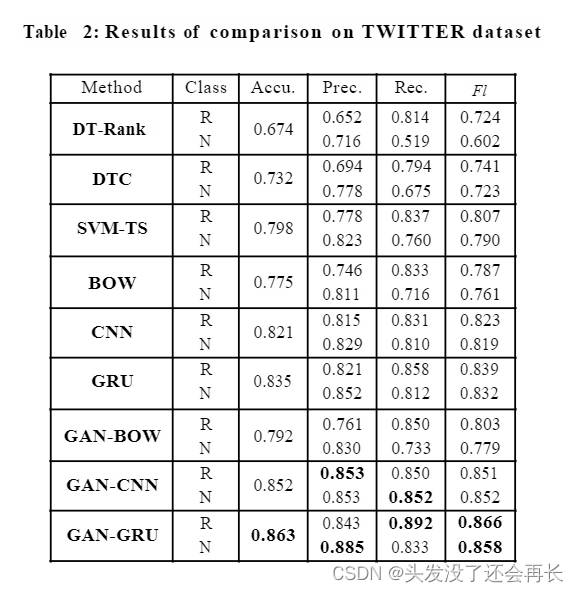
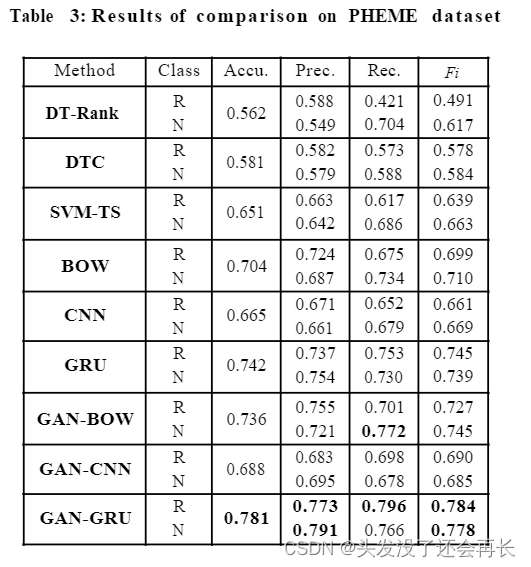
- 可以观察到,基于手工特征的 3 个基线的性能明显低于所有 6 个纯数据驱动模型。 SVM-TS 相对更好,因为它在传统模型中加入了额外的时间信息。 GRU 在所有基线中表现最好,这并不奇怪,因为它利用深度神经网络来捕获复杂的隐藏特征,这些特征表明谣言超出了显式和浅层模式。
- 在 PHEME 上被证明 CNN 的表现要差得多。 原因是 RNN 本质上可以处理可变长度序列,而 CNN 本质上不是序列模型。PHEME 中的声明明显少于 TWITTER,将大量零值输入单元呈现给 CNN,这会恶化卷积运算,但 RNN 可以通过缩短序列长度轻松摆脱零输入单元。 这也解释了所有模型在 TWITTER 上的整体表现更好。
- 我们的三种生成性对抗模型在非生成性对抗的基线上优于它们的对手。在这两个数据集上,我们的模型在这些基线上的改进范围从2.6%到5.3%,表明使用生成性辨别过程的对抗性学习通常是有益和有效的。
- 此外,谣言检测任务强调对谣言类别的识别性能。 GAN-GRU 在谣言类别上的召回率最高,表明可以找到更多的谣言。 从准确率和召回率的平衡来看,我们还观察到 GAN-GRU 实现的谣言类别的 Fl 分数高于非谣言类别。
总
我们提出了一种新颖的 GAN 风格模型,可以生成和利用信息活动的效果来更好地检测谣言。 我们基于神经网络的生成器创建训练示例来混淆谣言鉴别器,从而迫使鉴别器从增强的训练数据中学习更强大的特征。 实验结果证实,我们的方法基于两个公共基准数据集用于 Twitter 上的谣言检测是有效且稳健的。
这篇关于谣言检测论文精读——4.WWW2019-Detect Rumors on Twitter by Promoting Information Campaigns with GAN的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!