本文主要是介绍论文解读:A tree-structure analysis network on handwritten Chinese character error correction,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:现有的手写体汉字研究主要是基于识别网络,旨在解决汉字结构复杂、数量众多的特点。在本文中,我们从纠错的角度来研究汉字,即诊断手写字符的对错,并在错误分析中提供反馈。对于这个手写汉字纠错任务,我们首次通过统一评估指标和数据分割来定义基准。我们设计了一个包括分解、判断和校正阶段的诊断系统。具体而言,基于将汉字建模为树状布局,提出了一种新的树状结构分析网络(TAN),该网络主要由基于CNN的编码器和基于树状结构的解码器组成。使用预测的树形布局进行判断,对错误书写的字符进行错误分析并最终实现校正操作。校正阶段由三个步骤组成:提取理想字符、校正错误和定位错误。此外,我们提出了一种新的bucketing挖掘策略,在字根级别应用三元组损失来缓解特征分散。在手写字符数据集上的实验表明,与其他最先进的识别模型相比,我们提出的TAN在所有三个指标上都显示出极大的优势。通过定量分析,证明TAN比常规的编码器-解码器模型能够捕获更准确的空间位置信息,具有更好的泛化能力。
1、Introduction
由于现有汉字种类繁多,内部结构复杂,学习汉字对孩子来说是一项艰巨的任务。因此,小学生在学习写作时很容易犯错误。针对这种情况,手写体汉字纠错(handwritten Chinese character error correction ,HCCEC)任务应运而生。我们把写错的字定义为拼写错误的字,把写得好的字定义成正确的字。HCCEC的目标有两个:评估手写字符的正确性,并更正拼写错误的字符,简称评估和校正。评估子任务是指确定给定的手写孤立字符是否正确书写。校正子任务是指定位字符中的特定错误并进行校正,这需要模型的复杂分析能力。
拼写错误的字符与正确的字符非常相似,只是在一些细节上有所不同。由于拼写错误的字符可能多种多样,也可能数不胜数,我们将字符错误大致归纳为三类:笔划级错误、部首级错误和结构紊乱。笔划级别错误是指添加、删除或误用一个笔划;部首级错误是指某些部首的添加、删除或误用;结构紊乱是指正确的部首、错误的结构排列顺序。如图1所示,我们列出了三种拼写错误的字符的例子。考虑到错误可能发生在部首或结构中,诊断模型需要具有对汉字内部字根建模的能力,而不是将汉字作为一个整体。

与常用字符不同,拼写错误的字符样本极为罕见,类别也不可预测,数不胜数。我们假设训练集中的样本是正确的字符,并期望模型的迁移学习能力来处理未见过的拼写错误的字符。此外,要诊断的字符可能是正确拼写或错误拼写,因此HCCEC的任务可以归结为广义零样本学习问题(generalized zero-shot learning problem,GZSL)。GZSL是零样本学习的扩展,将测试集标签扩展到见过和未见过的类,这使其更具挑战性和现实性[1]。
与手写体汉字识别(HCCR)任务[2][3]相比,HCCEC的挑战主要体现在以下三个方面:1)1.测试集同时包含可见类和未见类,这对模型的泛化能力提出了更高的要求。2)拼写错误的字符可能与正确的字符非常相似,并且训练集只包含正确的字符。这可能会导致强烈的偏差[4]问题,即拼写错误字符(未见类)的实例更有可能被分类为已知类之一。3)3.除了评估正确性,HCCEC任务还有一个子任务,即纠正错误,这在HCCR中从未讨论过。
本文中,我们提出了一个解决HCCEC任务的诊断系统,该系统由分解、判断和校正三阶段组成。给定一个汉字图像,分解阶段产生它的部首特征表达。根据分解结果,可以判断字符的正确性。对于拼写错误的字符,以下矫正阶段可以提供关于错误位置的详细反馈,并指导如何更正错误。具体来说,我们提出了一种新的树结构分析网络(TAN),将字符分解为部首布局。所提出的TAN主要由一个基于CNN的编码器和一个基于树结构的编码器(TD)组成,它可以减少字符解码器对上下文信息的高度依赖,并在一定程度上缓解了偏差问题,对拼写错误的字符显示出更好的模型泛化能力。对于更具判别性的部首特征表示,我们采用了 bucketing三元组挖掘策略,并成功地将三元组损失函数应用于部首级别的汉字任务。此外,采用了更灵活的基于概率的解码。
考虑到缺乏专门用于HCCEC任务的文献,我们还设计了三个指标来全面衡量模型性能,即F1分数、准确性和校正率。注意到没有可用于HCCEC任务的公开数据集,我们收集了一个大型数据集,其中包含7000个常见字符和570个拼写错误字符的401400个手写汉字样本,并对其字符级别和部首级别标签进行了标注。既然如此,我们希望诊断系统能够生成错误位置和校正的反馈,部首级别的标签可能会有所帮助。
本研究的主要贡献如下:
- 1.我们提出了一个专门针对HCCEC任务的集成诊断系统,该系统主要由分解、判断和校正阶段组成。
- 2.我们为该任务提出了一种新的树结构分析网络,以减轻对上下文信息的高度依赖,并通过定量分析证明TAN能够捕获更好的空间信息。
- 3.我们提出了一种新的bucketing挖掘策略,将三元组损失函数应用于更具判别性的部首特征。此外,还引入了一种新的概率解码方法,将序列解码和度量学习相结合。
- 4.我们成功地将几个基于部首的识别模型应用于该纠错任务中,并设计了后处理。实验结果表明,我们提出的系统在三个指标上都取得了最好的性能,并具有纠错能力。
- 5.我们提出的TAN的源代码地址:thttps://github.com/yqingli123/TAN
2、Related works
HCCEC任务的应用需求已经存在很长时间了,但它并没有引起学术界的足够重视,我们还没有找到任何针对性的模型。因此,在本节中,我们描述了密切相关的主题,包括手写汉字识别、汉语语法纠错和广义零样本学习。
A. Handwritten Chinese Character Recognition
考虑到手写体风格的多样性和大量的字符类别,手写体汉字识别自20世纪80年代以来受到了广泛的关注[5]。早期基于传统方法的工作主要涉及三个过程:预处理[6]-[9]、特征提取[10]和分类[11]、[12]。随着深度学习的发展,基于神经网络的研究主要分为基于字符的模型和基于部首的模型。基于字符的模型将识别任务视为一个分类问题。Ciresan[13],[14]提出了多列深度神经网络,这是CNN在离线HCCR上的首次成功应用。后来,[15]提出将传统特征与GoogleNet[16]相结合,实现了超出人类性能的高精度。从那时起,对基于字符的建模的研究转向了其他想法,如writer adaptation[17]和低计算成本[18],[19]。与基于字符的模型不同,基于部首的模型将字符处理为部首的组合。[20] 首先在递归层次方案中分离出部首,并提出了用层次部首匹配来识别特征。[21]利用深度残差网络检测位置依赖的部首。自从提出基于编码器-解码器的模型以来,已经有了许多应用,如机器翻译[22]、数学表达式识别[23][24]、图像加字幕[25][26]等。当时张等人[27]提出了基于编码器-解码器的RAN模型,将汉字分解为一系列部首和结构,在HCCR中也取得了巨大成功。这种基于部署的建模方法具有零样本学习能力,这是HCCEC任务所必需的。FewshotRAN[28]进一步结合了深度原型学习,以实现更健壮的特征提取,但需要测试集的支持样本。RCN[29]将字符视为部首概率和部首数量的向量。最近,Cao等人[3]提出了一种用语义向量表示汉字的层次分解嵌入方法。
B. Chinese Grammatical Error Correction(CGEC )
CGEC是自然语言处理(NLP)中的一项重要任务,旨在检测和纠正中文文本中的语法错误。CGEC任务中讨论的错误是出现在文本或词组中的真实单词错误,而不是手写拆分字符中的“非单词”错误。由于缺乏语料库,传统的研究主要基于统计语言模型和规则[31][32]。自Yu[33]组织汉语语法错误诊断(CGED)共享任务以来,基于机器学习的方法受到了越来越多的关注。他们主要将错误分为四类,即冗余词、漏词、选词不当、乱词。Huang和Wang[34]将CGEC任务视为序列标记问题,提出了一个基于Bi-LSTM的模型。针对不同的错误,他们同时训练三个共享单词嵌入的Bi-LSTM来解决这些错误。Li等人[35]提出了一种two-stage混合系统,不仅可以检测错误,还可以纠正错误。该系统包括一个BiLSTM-CRF检测模型和三个语法纠错生成模型。Ren等人[36]将CGEC视为一个翻译任务,通过提出一个具有注意机制的卷积序列到序列模型,将“坏”中文文本翻译成“好”文本。最近,Lianget al.[37]将BERT-fused融合神经机器翻译模型应用于CGEC,取得了良好的性能。
C. ZSL and GZSL
零样本学习(Zero-shot learning,ZSL)旨在识别训练过程中可能未见过的对象,从而解决具有挑战性的问题:繁琐的人工注释和不可见的类别。由于测试集在实际场景中是无限的,所以测试样本只来自于不可见的类这一强大限制使得ZSL任务受到批评[1][4]。与ZSL相比,GZSL在搜索空间中加入训练类,更具实用性[1]。GZSL旨在识别可见和不可见的类,这与我们的HCCEC任务非常一致。因此,XIan等[l] 提出了一个统一的基准,包括数据集分割和评估协议,为该领域提供了一个科学的标准。GZSL的关键是通过辅助信息建立可见类和未见类之间的关系,如属性[38],单词嵌入[39]。[40]提出学习图像和类的潜在表示,并将稀疏标签转换为连续标签嵌入。[41]提出了一种共表示网络,学习一个更加统一的视觉嵌入空间。另一个研究方向是通过生成未见类的特征来解决训练数据不平衡的问题。[42]提出了f-CLSWGAN算法,以类级语义信息为条件生成未见特征。[43]利用每个类的元表示来获得更真实的合成特征。
考虑到HCCEC和HCCR任务之间的差异,基于字根的识别模型可以通过后处理转移到该纠错任务中,但性能较差(在第六节中讨论)。基于编译码器的RAN模型存在对上下文信息高度依赖的问题,导致训练类的严重偏差。基于度量的模型[3][29]直接将字符图像编码为精细嵌入,模型的中间步骤缺乏可解释性,无法为校正阶段提供详细信息。受手写体数学表达式识别中树形结构译码器[44]的启发,我们将汉字建模为字根树形布局,并结合汉字的特点对树形译码器进行简化。我们提出的TAN还结合了基于编码器-解码器模型和基于度量的模型的优点,具有令人印象深刻的性能和良好的模型解释性。
III、SYSTEM DESCRIPTION
在这一部分中,我们提出了一个新的诊断系统,它包括三个阶段:分解、判断和校正。系统的说明如图2所示。在分解阶段,给定一个汉字的图片(可以是正确的,也可以是拼错的),模型生成一个预测的字根树。经过判断,如果分解后的字根树写错了,则将其发送到纠错模块。然后将产生错误位置和候选修正的反馈。
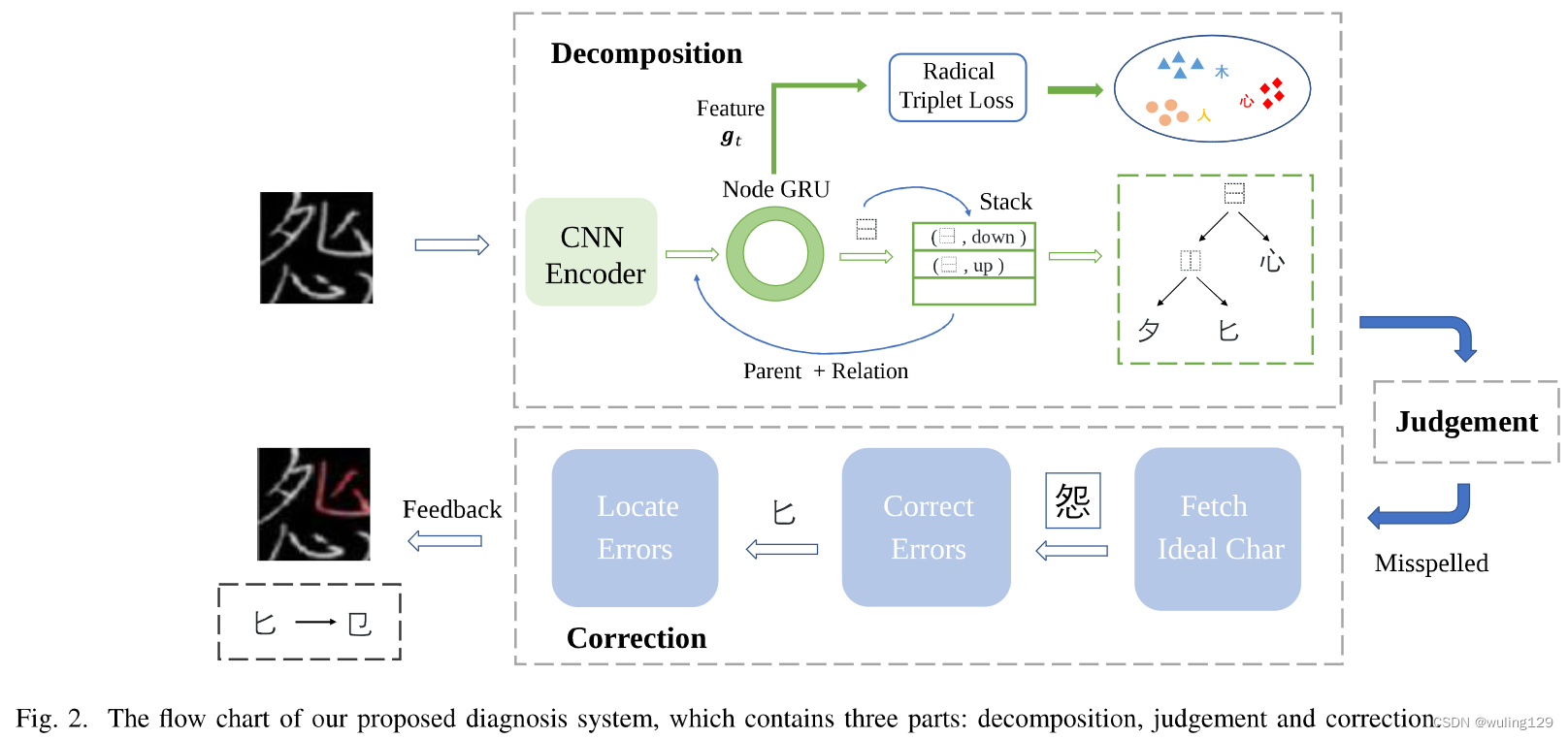
A. Motivation
众所周知,汉字的基本体包括笔划、字根和结构。一个或几个笔划可以组成一个部首。按一定顺序列出的一个或几个部首和结构可以组成一个字符。如第一节所述,汉字错误可分为三种类型,笔划的增减可转化为相似字根之间的差异。因此,我们在字根层次上建立汉字模型,利用共享字根将学习从正确的汉字(seen类)转移到拼错的汉字(unseen类)。
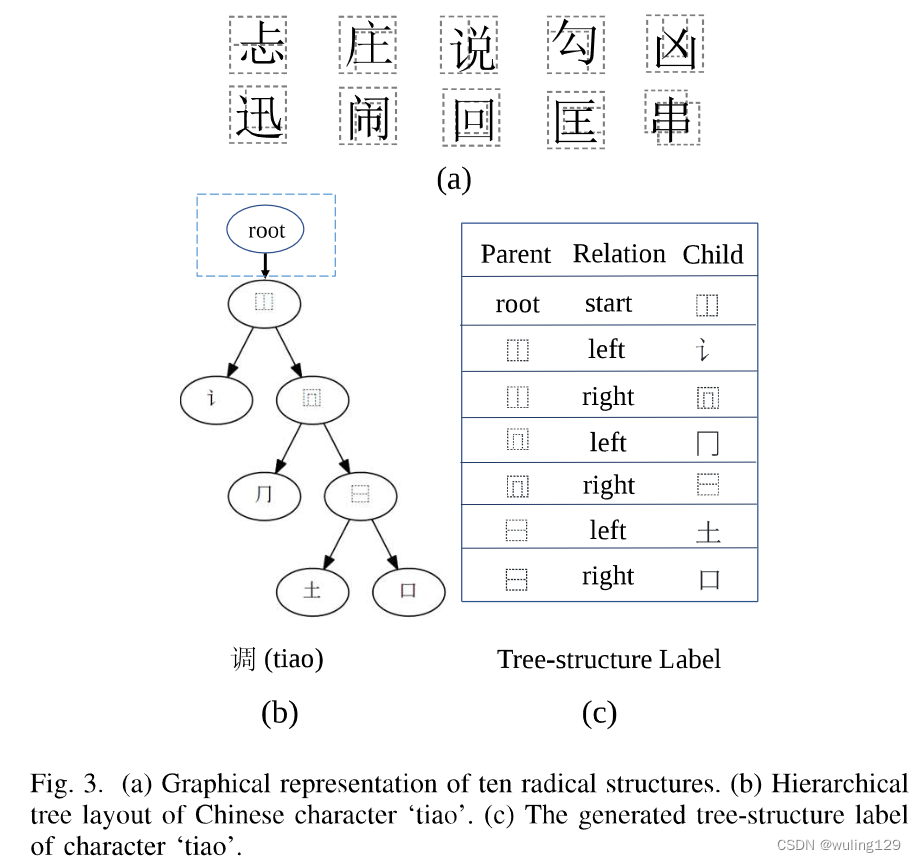
与英语或阿拉伯语不同,汉字有内部结构。有十种分解字符的方法,导致10种结构[45]。在图3(a)中,列出了10种结构:(1)上下,(2)左上环绕(3)左右,(4)右上环绕,(5)下环绕,(6)左下环绕,(7)上环绕,(8)全环绕,(9)左环绕,(10)覆盖。由于这些结构,所有的汉字都可以分层分解为相应的树形布局,由部首和结构组成[3][45]。如图3(b)所示,按照从整体到局部分解的原则,“调”字首先属于左右结构。我们将结构设置为父节点,将左右部分设置为两个子节点。然后对这两个子字根进行递归分解,直到子节点是不可分解。因此,每个汉字可以分解成由部首和字根组成的层次树状布局。
通过观察,我们总结出三条树型规律:
1) 所有树布局都是二叉树,因此每个父-子对之间的关系仅为左和右。这可以大大简化解码过程,因为无需特殊建模即可确定关系。
2) 所有父节点都是结构,所有叶节点都是根。这个规则使得在解码过程中很容易确定当前分支何时结束。若当前节点属于结构,则包含子节点,此树分支需要后续解码。如果当前节点属于部首,则为树的叶节点,表示当前分支的结束。
3) 父节点可以表示其子节点之间的空间关系。例如,如果父节点是上下结构,则其两个子节点在空间上位于字符的上方和下方。这给我们的启示,有必要给每一个亲子对增加空间位置指导注意。
受上述三个规律的启发,我们创新性地提出将每个汉字直接建模为一个独立的树布局。与[27]不同,后者将树结构序列化为一维序列。我们充分利用了结构所能提供的位置信息,并从二维结构的角度对汉字进行建模,这在以往的研究中是被忽略的[27][28][29]。
B. Decomposition Model
给定一幅手写体汉字图像,我们提出的TAN算法将汉字分解为一个树形布局。TAN主要由基于CNN的特征提取编码器和用于汉字建模的树结构解码器组成。提出了一种基于父节点和子节点空间关系的指导思想,以提高注意力。此外,我们还提出了bucketing三元挖掘策略,将三元损失应用到字根上,以获得更显著的特征。还提出了一种比匹配解码器更灵活的概率解码器方法。
I) Tree-structure Label
每个字符都可以表示为字根树布局,如图3(b)所示。按照深度优先遍历顺序,树结构可以分解为一个有序的父子节点对序列,由两个节点及其边组成。如图3(c)所示,我们列出了‘调’字的转换树结构标签调。为了统一表达式增加了辅助符号root和关系start。关系是父子对在树中的相对位置。左子节点对应关系“left”,右子节点对应关系"right"。字根树布局中的每个 字根/结构 被视为子节点一次,并且可以一步解码。从图3(c)中的树结构标签表中,我们可以看到除辅助符号“root”外的所有父节点都是结构—符合规律2。
因此,树结构解码器的目标被转换为产生有序的父子对序列。在每一对中,需要产生三个元素:父、子、关系。利用前两个规律,我们可以将树型结构的解码器灵活地建模为节点预测模块和堆栈。在每一步的堆栈操作的帮助下,利用堆栈存储解码后的节点并弹出准确的父节点。在父子对中,一旦给定了父节点,就可以通过第1定律很容易地推测出关系。因此,不需要对关系进行专门建模。在每个时间步中,给定父节点及其对应关系,设计一个节点预测模块,用于子节点解码。
2) CNN Encoder
给定一个字符图像I(正确或拼写错误),我们首先使用DenseNet[46]中由密集连接的卷积层组成的基于CNN的编码器来提取高级视觉特征。我们将从编码器获得的三维特征作为B,其大小为Hx Wx D,其中H表示高度,W表示宽度,D表示通道(为什么不用C,更好理解)。特征图B包含视觉信息,这有助于后面的解码。此外,三维特征B可以展平为L x D的变长网格,其中L=HxW。
3) Node Prediction Module
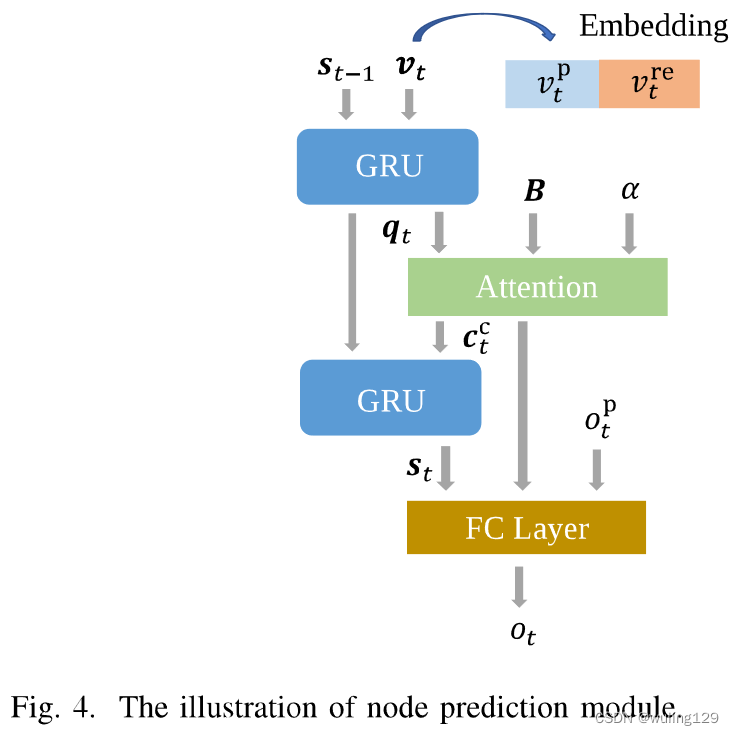
如第III-B1节所述,假设当前父节点和关系为
,则其子节点由节点预测模块解码。如图4所示,该模块主要由两层门递归单元(GRU)[47]、注意模块和分类器组成。通过两个嵌入层,将父节点
和关系
的高维向量表示为
和
。concat
和
后的
作为上下文信息,
表示嵌入的维度。
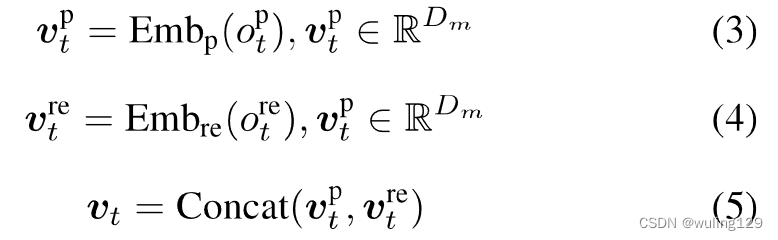
通过第一层GRU,我们从先前的隐藏状态St-1和当前上下文信息计算当前查询向量
。
然后采用基于覆盖率的注意机制[27],其中视觉特征B为key和vaue,
为查询,定位当前步骤的相关区域。
具体来说,除了视觉特征B和查询向量外,还考虑了先前注意概率的总和。覆盖向量F用于避免过度解析(某些字根被多次解码)和欠解析(某些字根从未被解码)的问题[27]。
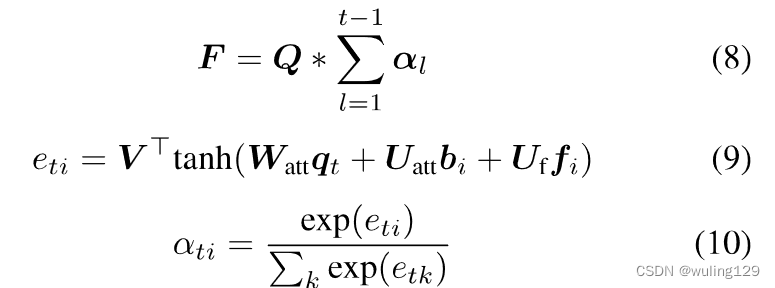

公式8-10没看懂什么意思,和上下什么关系。难道不应该是:
+公式11吗?
从而得到注意力系数,表示特征向量
在步骤 t 的注意得分;(公式11)
使用上下文向量 和查询向量
,就可以计算当前隐藏状态
:

图4应该是画错了 应该为
—>
两步;
应该为
;这样才和公式13、14符合。
Let Dr and M denotes the dimension of radical representation and the size of radical dictionary. Then ![]()
表示第t节点
的特征向量,包含当前字根最具代表性的信息(父节点信息
,隐藏状态
(上下文向量信息
和查询向量
),上下文向量
。可见上下文信息
被多次利用和传递(隐藏跳连结构),那这样这个图就画的不好。)。
表示步骤t的预测概率分布。
假设第t步的独热标签为,其子节点分类损失计算为:
![]()
4) Spatial Relation Guidance:
如第三定律Ⅲ-A所述,父节点都是结构,表示父节点和子节点之间的空间关系。例如,父节点是“上下”结构,这意味着其左子节点在空间中位于其上方,而右子节点在其下方。在此基础上,提出了一种基于父子节点对的空间关系引导方法。由于上下文向量Ct包含上下文信息和空间信息,因此我们利用它们来预测父节点和子节点之间的空间关系。
最后得出一个空间关系指导损失Lg。

5) Radical Triplet Loss:
在解码期间,在式(13)中计算字根r的特征向量gt。理想情况下,相同字根特征之间的距离应小于不同字根特征之间的距离。然而,受写作风格和字根位置的影响(详见第VI-A节),特征空间相对混乱。因此,本节首次从字根层面介绍了汉字的三元损失。我们对特征向量施加约束,使类内距离比类间距离更接近。目标如下:
![]()
(x,p,n)组成三元组。Ex是一个字根的锚定特征。Ep是同一字根的正特征,En是其他字根的负特征。m表示增加类内距离的边距。
我们应用在线挖掘方法[48]在每个小批量N中生成三元组。考虑到每个汉字c由几个部首组成,确保每个部首样本
(i in [ 1,N])至少有一个正样本和一个负样本是一个问题。此外,类间的距离是由字根位置和写作风格造成的。因此,我们提出了一种新的bucketing挖掘策略。我们首先将所有包含某个部首r的汉字打包到一个bucket桶中,就会有M个部首桶(M表示部首字典的size)。请注意,一个汉字可以同时出现在多个bucket中。在每个小批量中,我们在随机bucket中随机选择P个汉字,然后每个汉字随机选择K个样本。这样,我们就可以确保来自不同汉字和不同写作风格(同一汉字)的同一部首可以同时考虑。每个batch中将会有
个字根样本。
表示字根编号为i的汉字。因此,对于每个字根,总是至少有P*K个正样本,最多有
个负样本。我们使用batch-hard[49]方法,选择hardest的正样本和hardest的负样本,为每个字根样本组成一个三元组。三元组损失计算为:
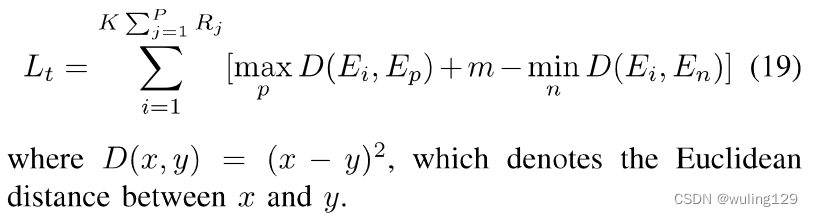
6) Probability-based Decoding
我们提出了一种基于概率的解码方法,而不是将输出 序列/树 与字符根词典进行匹配,因为匹配解码需要预测和GT之间的严格一致性。基于概率的解码方法是基于度量学习的,并放宽了要求。
通过节点预测模块,我们可以得到预测的子节点序列和相应的概率
。由于
表示当前第i个步骤中所有字根的概率分布 并 连同当前节点的深度信息,我们对T个概率向量进行加权求和,得到预测特征的概率嵌入W。
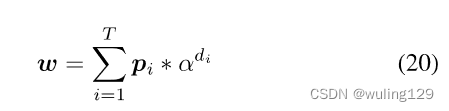
其中表示权重随深度的增加而衰减。我们限制
<1.0,因为深度越大,对整个汉字的影响就越小。
表示第i个节点的深度。
类似地,一旦给定了部首级别的标签,我们就可以将所有字符的标签预处理到嵌入编码中。我们可以对每个部首采用一个独热编码嵌入
。因此,字符c的标签嵌入可以如下计算:
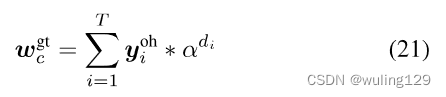

其中C表示所有可能的字符(包括所有正确的字符和拼写错误的字符)的集合。
C. Correction
HCCEC的任务不仅是评估字符是否正确书写,还包括纠正错误。接下来介绍了系统的纠错过程,主要包括三个步骤。
Step I. Fetch the ideal char
在字符分解之后,我们需要首先找出候选的理想字符,即用户打算写哪个字符。考虑到字符是在没有上下文的情况下写的,我们选择前5个字符作为理想候选集。给定输出概率嵌入 w 和所有正确字符集 的嵌入,我们可以使用等式Eq.(22)计算它们之间的欧式距离d,然后将理想字符指定为前5个最短距离的汉字。
Step Il. Correct the errors
以候选的理想汉字为参考,我们可以通过编辑距离计算将拼写错误的字符更正为正确的字符。具体来说,可以通过按深度优先顺序遍历,首先将部首树布局序列化为部首序列,如图5所示。然后采用编辑距离算法[50]将预测序列转换为编辑时间最短的理想序列。计算的编辑操作可以指导我们纠正错误。例如,如图5所示,通过删除两个选定的部首,可以将预测序列校正为正确的部首。
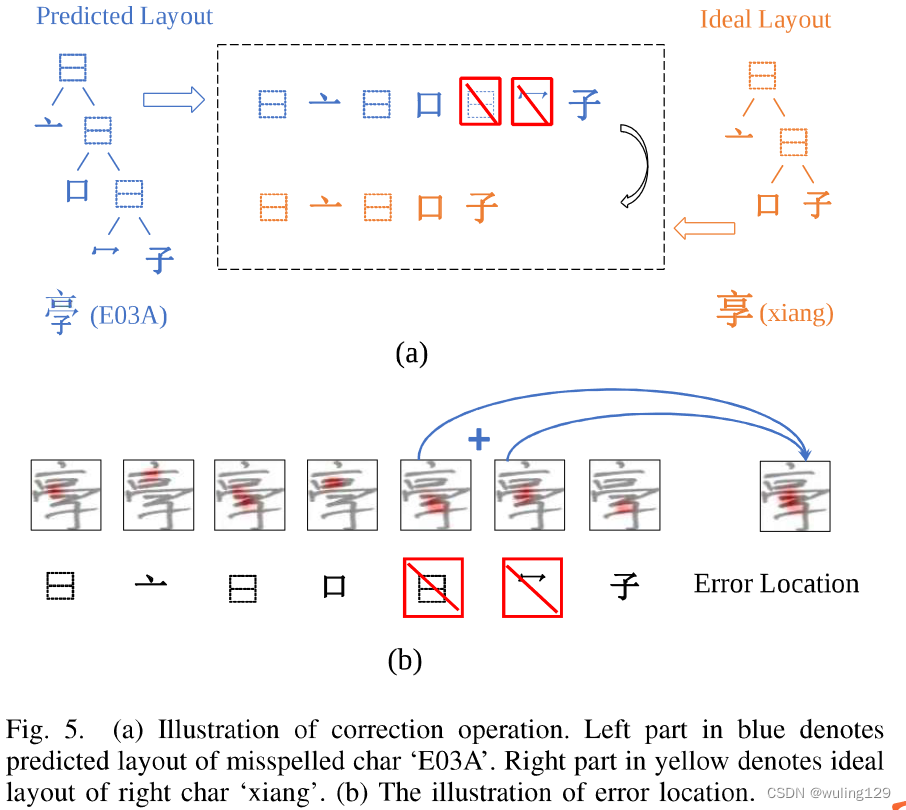
Step IIl. Locate the errors
对于书写者来说,错误可能很难发现,因为他们写错了。因此,误差的大致位置将是有帮助的。由于有注意力机制,我们提出的TAN可以在解码过程中大致定位每个部首。结合步骤 Il 中生成的误差字根,我们可以通过注意力可视化来定位误差。例如如图5所示,通过删除步骤 Il 中的两个部首的校正操作,我们将这两个步骤的注意力图合并为错误位置。
IV. TASK SETTING
有两组字符类:正确汉字和拼写错误的汉字。设,…,
为N个样本。
表示第i个图像。
表示第i个评估标签,为0或1,0表示拼写错误的字符,1表示正确的字符。
表示其准确类别的第i个字符级标签,
对应于其部首级标签(是一个还是一串图结构字根图序列?)。
表示第i个字符级校正标签。
A. Dataset
我们的数据集由5500个常见字符和570个拼写错误的字符组成,这些字符由小学书写。注释都是手动标记的,包括正确性、字符级标签和部首级标签。对于拼写错误的字符,我们也对其相应的理想字符进行了标注。根据第一节所述的划分方法,在570个拼写错误的字符中,有234个笔划级错误、320个部首级错误和16个结构紊乱错误。
零样本学习假设训练和测试集不相交。为了在不破坏假设的情况下获得更好的模型性能,准备了一个单独的验证集来调整参数。按照[1]中的数据集拆分方法,我们将字符划分为两个不相交的部分:训练集和验证集。训练集中的每个汉字由50名writer编写,构成250000个训练样本(对应5k个汉字)。验证集中的每个字符由200名writer编写,构成100000个验证样本(对应500个汉字)。
由于这是一个GZSL问题,所以测试集由正确的字符和拼写错误的字符组成。测试集2000个正确字符是从训练集中随机抽取。这边应该少了一句话:测试集中的570个错误字符从哪来,应该是单独写的,不合训练集还有验证集相交。测试集中的每个字符由20位writer编写,这样行了包括40000个正确的样本和11400个拼写错误的样本。具体划分见表一。总之,共有401.4k个样本,由6070(5000+500+570)个字符组成。
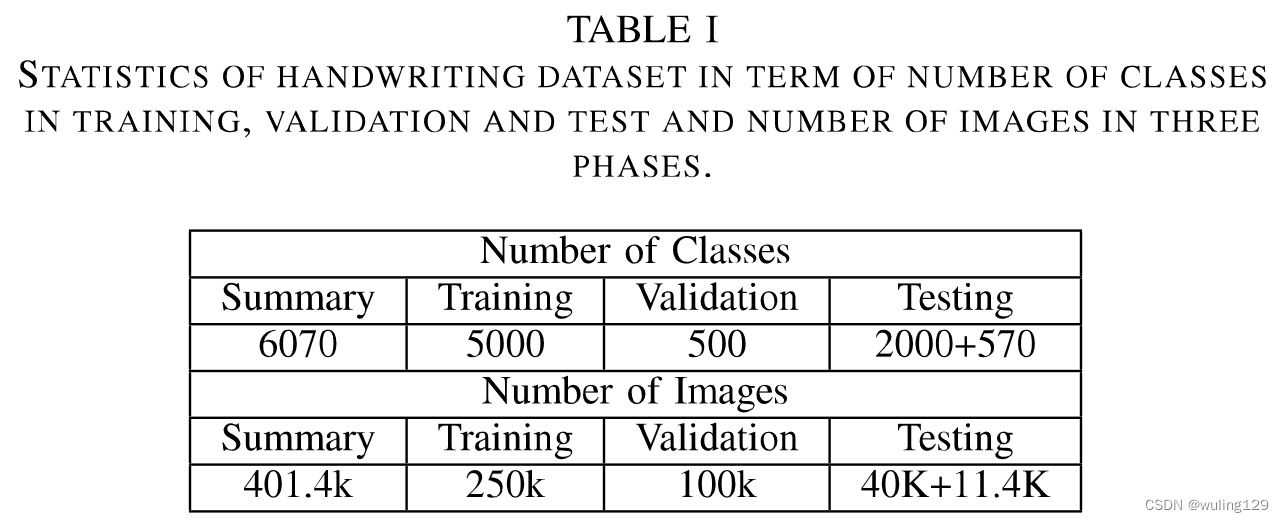
有个疑问,重复的那40k也算到summary里了,合适吗?
B.Evaluation Metrics
适当的评估指标可以全面、公平地反映模型的性能。接下来,我们介绍了三个指标来评估HCCEC的两个子任务的模型表现。第一个是F1-score,一种衡量预判断能力的指标。第二个是准确性,这是衡量分类能力的一个很好的指标。最后一个是修正率,旨在衡量模型的纠错能力。
F1-score
在评估子任务中,给定的字符需要预先判断正确性、正确字符或拼写错误的字符。预断结果可能会影响以下操作:拼写错误的字符需要校正,但正确的字符不需要。为了衡量预判断的性能,我们计算了两个类别的准确度和召回率,分别得到F1分数。
Correction rate
经过评估阶段,拼写错误的字符需要进行校正操作。校正率的度量可以直观地反映模型的校正能力。为了纠正错误,模型需要正确预测字符类别,并推断出理想的字符(用户打算写哪个字符)。
假设N个样本的测试集中拼写错误字符总共有,Nc表示正确分类的样本,Ni表示正确预测理想字符的样本。然后校正率CR可以计算为:
校正率的度量对模型提出了更高的要求:不仅需要对给定的汉字进行分类,还需要根据模型输出推断出理想的汉字(用户真正想写的汉字)。(这一块加上句子上下文信息可以进行优化,不过意义不大)
V. EXPERIMENT SETTING
A. Training
在训练方面,我们提出的模型通过三个损失进行优化:子节点分类损失Lc、关系引导损失Lg和字根三元损失Lt。总损失函数如下:
实验中,设=1,
=0.5,
=0.1。(why 为什么这么设置,依据和原因?)
为了进行公平比较,我们在以下模型中统一使用DenseNet作为编码器。DenseNet主要由三个dense blocks 和两个dense blocks 组成。Each dense block contains 22 bottlenecks. bottlenecks有1×1卷积层和3×3卷积层,依次为BatchNorm层和Relu激活层。
为了避免过拟合,我们在每个bottleneck 中添加了rate为0.2的dropout layer。每个bottleneck 的增长率设置为24。然后在每两个块之间设置一个 transition module,以减少一半(0.5)的特征映射的通道数。对于 transition module,我们使用1 x 1卷积,然后使用2x2平均池化。在第一个dense blocks之前,执行步长为2的7 x 7卷积层。在解码器中,节点预测模块由两层单向GRU和注意模块组成,每个GRU层有256个单元(如图4)。父节点和关系的嵌入维度都设置为256。注意力向量dim为512。所有图像的大小都调整为64 x 64。我们使用的字根字典和空间关系字典的M和大小分别为413和22。
在训练过程中,我们使用Adadelta优化器来训练所提出的模型。学习率设置为1.5,权重衰减为1e-4。实验均在两个Nvidia Telsa V100 GPU上进行。
B. Inference
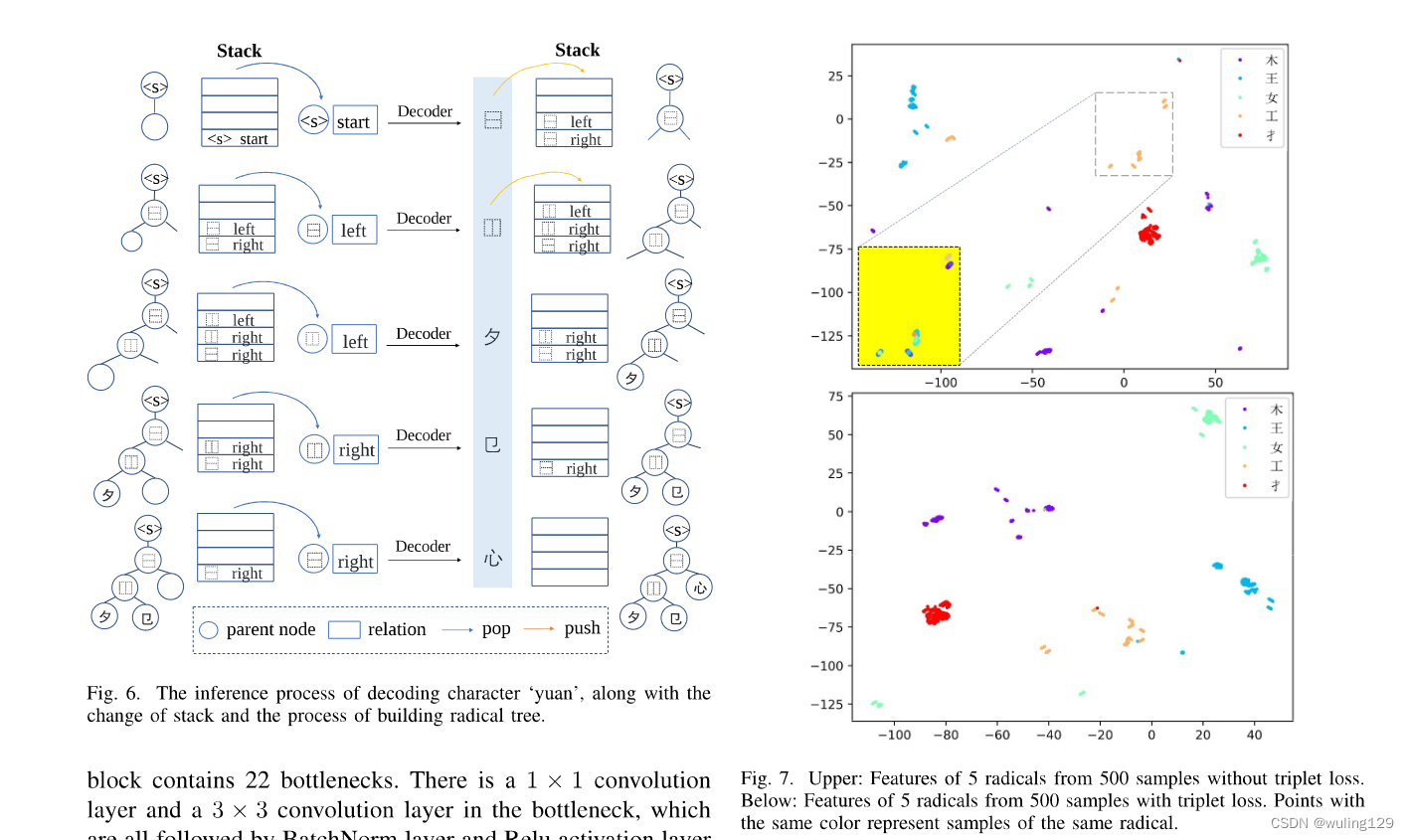
在推理过程中,为了简化解码过程,我们使用了一个堆栈来记录解码后的元组(,
),并在适当的时间将其弹出。在一个步骤中,解码节点指导入栈操作。在下一步中,将弹出准确的父节点和关系信息以进行子节点解码。如图6所示,我们展示了示例字符‘怨’的详细解码过程。在第一步中,给定父节点“<s>”和关系“start”,TAN解码器解出当前节点“up-down”—— 属于10个预定义结构之一。因此,需要使用两个元组,其中“up-down”作为父节点来入堆。在第二步中,我们弹出堆栈顶部的元组来解码当前节点的“左-右”。以同样的方式,将两个以“left-right”作为父节点的元组推送到堆栈中。我们可以重复这个操作直到堆栈为空。在解码过程中,还可以建立字根树。给定输入图像x和候选标签Y,通过树布局解码,生成每一步的概率向量。根据等式(22)和(23),我们可以计算预测概率嵌入和所有可能标签嵌入之间的距离,将输入分类为距离最近的输入。
VI.EXPERIMENTS
按照第四节介绍的数据集分割方法,我们在收集的手写数据集上进行了手写体汉字纠错实验。
A. Ablation Study
高维字根可以通过大Vis算法[51]简化为2D。我们选择5个部首,每个部首至少有500个汉字样本(至少来自5个不同汉字)。2500个样本的二维特征可以可视化。从图7的上图中,我们有两个观察结果:
1、同一字根样本之间的距离有时大于不同字根样本之间的距离。
2、意外的大类间距离主要由两个因素引起:字根位置和书写方式。
具体来说,我们可以看到橙色的点分散在不同的位置,其距离甚至大于一些蓝色点与它们之间的距离,这导致了第一个观察结果。我们聚焦于字根‘工’的样本,放大虚线框中的橙色点。在黄色背景的缩放图形中,一个颜色的点代表一个字符的字根“工”的特征。可以看出,一般情况下,同一颜色的点往往会聚集在一起,这意味着来自同一字符的字根特征具有较高的相似性。此外,一些紫色点远离紫色点簇的中心,这意味着来自不同writer的相同字根也会产生不同的特征表示。这证实了第二个观察结果。考虑到这一点,我们提出了字根三元损失来约束字根特征,以达到聚类同一类和增加类间距离的效果。
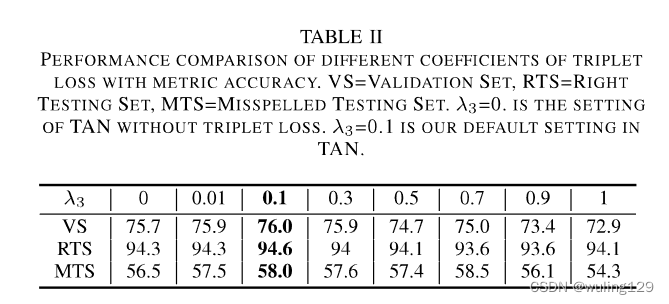
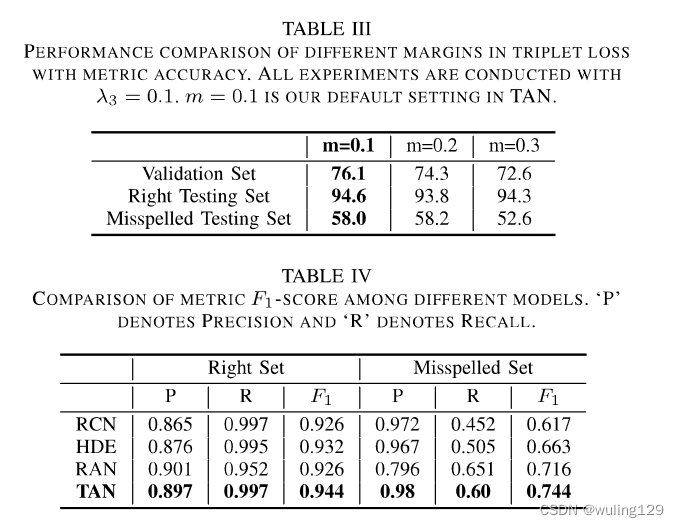
为了验证字根三元损失的有效性,我们在验证集上进行了烧蚀实验,并在测试集上验证了烧蚀效果。如表Il所示,TAN在未加入三元损失与加入三元损失相比,验证集上正确汉字测试相差0.3%,错误拼写测试集上相差1.5%。此外,超参数的选取对TAN的性能有很大的影响。起初,编辑行逐步增加,三组上的准确度都增加。当编辑
=0.1时,三元损失在validation set上的效果最好,因此我们选择0.1作为最佳选择。综合来看,
=0.1还可以最大化两个测试集的性能增益。随着
的不断增加,模型的性能下降,这是可以理解的,因为我们的主要目的是分类,而三元损失只是起到辅助作用的聚类特征。在m=0.1时,模型在验证集上的性能最好,这与测试集的性能一致。
此外,我们可视化的字根特征与字根三元损失失。如图7的底图所示,来自不同字符的相同字根样本明显更多,类间距离也更大。分类是任务的主要目的,而字根三元损失只是辅助分类。因此,从最大化分类精度的角度来看,三元损失系数不能太大(如表I所述),这会导致聚集效果不理想。
B. Experiment Results of Assessment Subtask
1) 使用度量F1分数进行评估:
在本节中,我们使用第四节中介绍的数据集进行实验,并使用度量F1分数评估模型。为了比较,我们还实现了一些识别模型在这个子任务。
基于度量学习的模型,如RCN[29]和HDE[3],将字符表示为基于字根的嵌入。在适应HCCEC任务时,可以通过计算输出嵌入与所有候选字符嵌入之间的距离来生成预测字符。如果预测的字符属于正确的字符集,则判断其为正确字符。否则,它将被预测为拼写错误的字符。
基于编码器-解码器的模型(这里指RAN)将字符解码成字根序列,并在识别任务中查找字根词典以确定预测字符。在适应HCCEC任务时,如果预测的字根序列属于候选正确字符集,则判断其为正确字符。否则。它将被预测为拼写错误的字符。
按照各自的评估方法,我们比较了以下四种模型:RCN、HDE、RAN和我们提出的TAN。请注意,所有模型都有相同的编码器,图像大小调整为相同大小,以便公平比较。如表四所示,TAN在正确测试集和拼写错误测试集上的F1成绩都是最好的。RAN的正确测试集的查准率和拼错测试集的查全率略高于TAN。这是因为RAN解码一个不受限制的字根序列,并在固定字根词典中查找该序列来判断其正确性。它倾向于预测成拼错的字符。因此,RAN模型对拼写错误测试集的查准率和对正确测试集的查全率均显著低于其他模型。总的来说,F1在两个测试集上的得分仍然低于TAN。
2) Assessment with Metric Accuracy.
除了判断正确性外,分类准确度更能反映模型的能力,因为它要求对字符类别进行准确的判断。由于测试集由两部分组成:正确集和拼写错误集,我们分别计算这两部分的准确度。如表V所示,在正确集中,其他三种模型的性能相当,而TAN则显著超过它们约2%。在拼写错误集上,TAN的泛化能力优于其他模型,提高了10%~16%。
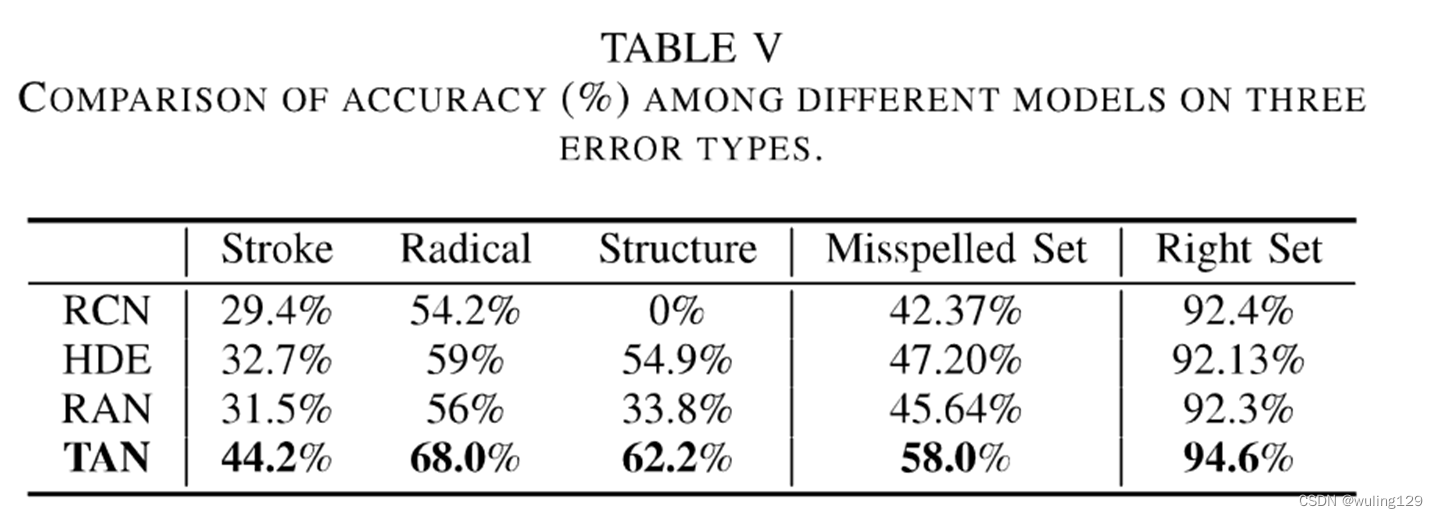
外,我们还进一步分析了模型在三种误差下的性能。如表5所示,与性能最好的识别模型HDE相比,我们提出的TAN取得了更好的性能,并有显著的改进:笔划级错误11.5%,字根级错误9%,结构紊乱7.3%。在这三种误差中,stroke-level误差的精度最低,因为stroke-level是最小的单位,也是最难检测的单位。TAN在字根级误差上的性能达到了68%的高性能,接近于普通的未见字(模型性能)。

为了探索TAN的最佳表现,我们在图8中展示了拼错字符的一些示例以及四个模型的相应预测结果。HDE直接将输入图像编码为包含字根信息的特征嵌入,其细节建模能力相对较弱。我们列出了它的前2个预测特征和相应的概率。在第一个示例中,HDE错误地将其分类为相似字符'式’ 高概率为0.79。在第二个示例中,HDE错误地发现另一个拼写错误的字符 ‘E10D_1” 作为最可能的预测。在第三个示例中,字符“hu”和字符“E16E 2”对于HDE是混淆的,尽管它们的结构略有不同。
RAN的字符串解码器严重依赖于上下文信息,因此前几个步骤的解码结果容易误导后续解码。我们列出了RAN in Fig8 的解码序列。RAN错误地将第一个图像识别为一个相似的可见字符'贰’. 在第二个示例中,受前面解码的影响,第七个字根被错误地解码为字根“子”,如所见的字符“熟”。
TAN将输入解码为字根树布局,每个字根的输出概率显示在树的旁边。TAN模型具有更精细的字根建模和更少的上下文信息依赖性,对未见但相似的字符具有更好的模型泛化能力。
C.Experiment Results of Correction Subtask
在这一部分中,我们展示了我们系统的纠错性能,并从纠错和错误定位的角度列举了一些详细的例子。
1) 修正率:
按照ⅲ-C节中介绍的三个步骤,我们将详细介绍每个模型的具体校正操作,并比较它们在三种错误类型上的校正率。
基于度量学习的模型,这里参考RCN和HDE,输出一个嵌入向量来表示字符。对于判断为拼错字符的样本,可以计算输出嵌入与所有候选正确字符嵌入之间的距离,并选择距离最近的前5个候选正确字符作为候选正确字符。由于标签嵌入是在复杂的规则中设计的,所以不能通过输出的嵌入向量推断出具体的错误,更不用说定位了。RAN基于编解码框架,将字符解码为表意字符描述序列(IDS)。对于拼写错误的字符,可以计算预测IDS和正确字符的所有候选IDS之间的编辑距离。但是,最接近编辑距离的正确字符数可以超过5个,因此与其他方法进行比较是不公平的。因此,RAN结果未列在表VI中。
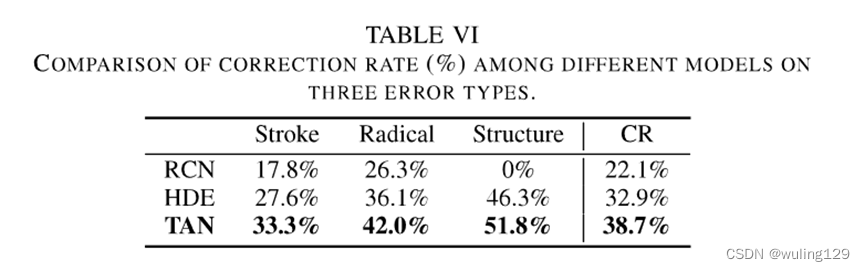
由于校正子任务是评估的后续任务,因此校正率与评估结果高度相关。根据相应的校正方法,我们比较了我们提出的TAN与其他模型的校正率。如表Vl所示,与表V中的精度相比,所有模型的校正率都有所降低,因为校正操作还需要正确地找到理想的字符。但就整体修正率而言。三种错误类型中,结构紊乱最容易纠正,笔划水平错误最难纠正,纠正率为33.3%。
2) 修正结果

D. Quantitative Analysis
为了深入研究树型解码器在拼错字符中表现出更强的模型泛化能力,我们进行了定量分析计算。在解码过程中,字符串解码器和树型解码器都首先将前一个隐藏状态和前一个输出作为输入,生成查询向量:
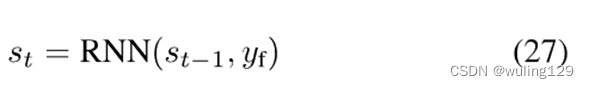
中Yf可以是对应于字符串解码器和树解码器的Yt-1或(Yp;Yre)。然后利用查询向量计算注意图。由于RNN的记忆机制,St显然包含上下文信息。我们进一步发现,它包含了二维位置信息来辅助当前的注意图计算。
根据文献[52],我们首先通过对相同树布局和不同树布局的字符分别拟合t=Wrst+br(80%用于训练,20%用于测试),对模型RAN的查询(st)与其位置(t)进行线性回归。我们设定指标R2来反映因变量的方差中可预测的比例。对于具有相同树布局的字符,我们得到R2=0.95。但对于相同长度的不同树布局的字符,我们得到R2=0.70。这表明字根的位置信息与其在树布局中的位置有关。尽管RAN在建模过程中将汉字识别为线性序列,但RAN捕获的位置信息不再是一维位置。为了进一步验证查询向量所包含的位置信息与树布局的一致性,我们计算布局为A和B的字符的第i个和第j个时间步长的查询特征向量之间的平均余弦相似度S:

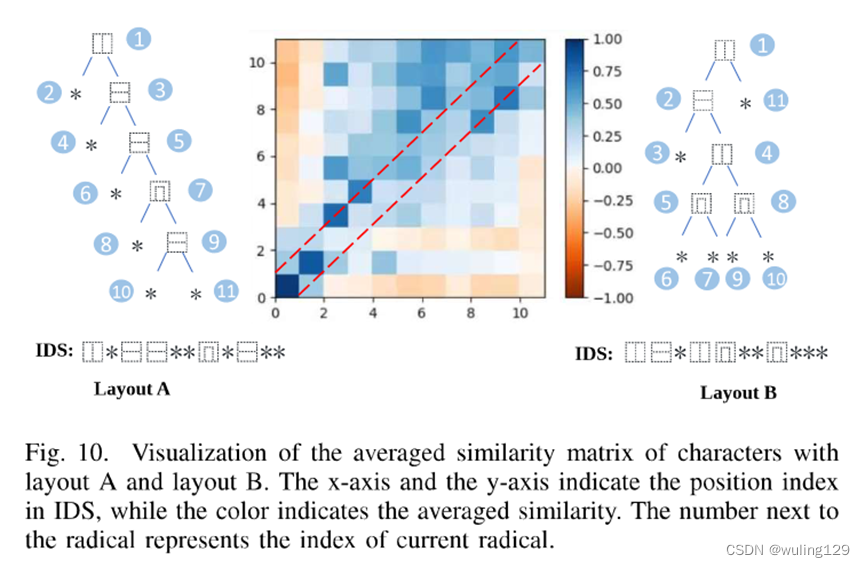
如图10所示,聚焦于对角线,前两步的根位于布局A和B的相同位置,因此余弦相似性较高。从第三步到第五步,相似性仍然很低,因为这些根与两个布局位于不同的位置。由此可以看出,由于结构和部首具有不同的物理意义,RAN捕捉到了部首树上的空间信息。但在后一步(>5),即使在不同的位置,余弦相似度仍然保持在0.3到0.5的水平,这并不低。这反映了RAN捕捉空间位置的能力随着长度的增加而降低。
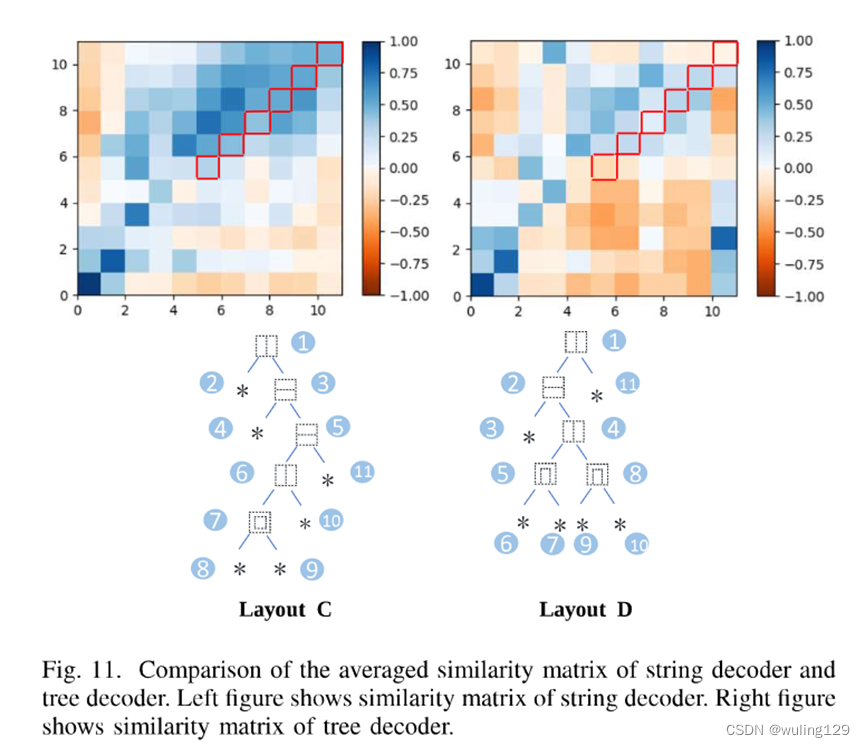
为了具体比较字符串解码器和树解码器学习到的位置信息,我们计算布局为C和D的字符的余弦相似度。如图11所示,在前几个步骤(<5)中,树解码器和字符串解码器都捕获与字根位置匹配的位置信息。但在后续步骤(>5),字符串解码器的余弦相似度开始表现混乱,而树解码器仍然捕获相对准确的空间位置信息。更准确的视觉信息和更少的上下文依赖性使得树解码器在拼写错误的字符上具有更好的性能。
这篇关于论文解读:A tree-structure analysis network on handwritten Chinese character error correction的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







