一种pache Kafka is in its core a distributed, scalable and fault tolerant log system exposed as a Topic abstraction and implemented with a high-performance and language agnostic TCP protocol, which enables it to be used in different ways:
- 流处理系统讯息系统储存系统
Apache Kafka documentation is really concise and to the point, I really recommend you to read it as your initial reference to working with Kafka.
It offers core APIs for Producing and Consuming messages, Streaming messages and connecting to external systems with it's Connector AP一世.
It has its primary client in Java but there are also clients built for many other languages like Node.js, .NET, Scala, and others.
Basic Concepts
Kafka对其分布式日志记录有一个抽象,一个Topic,还提供了与之交互的客户端API。 让我们更多地了解主题在后台如何工作以提供高可用性和可伸缩性,以及使我们能够产生,使用和操作现有数据的客户端API,但首先,我们将看一下 卡夫卡及其经纪人和客户的高级概述。
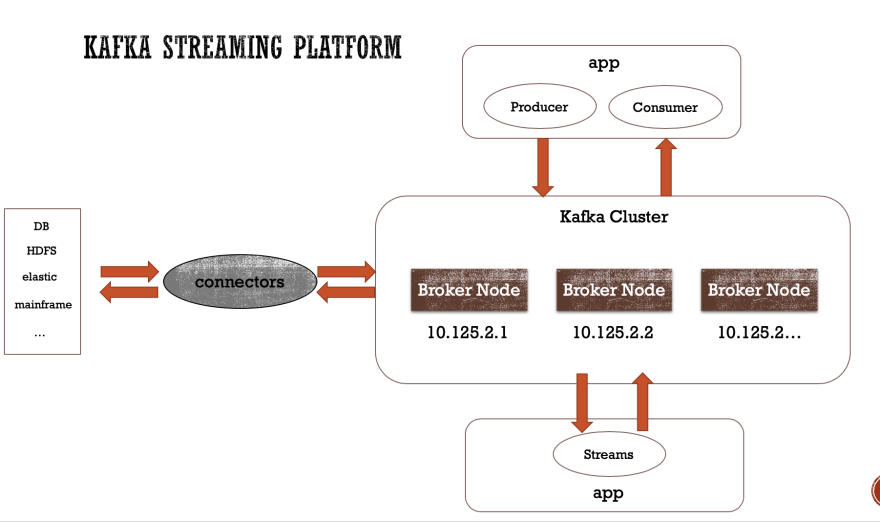
Brokers
Kafka经纪人是管理主题的核心,它们还提供一些基本的支持来协调Kafka客户,这将在另一篇文章中进行详细说明。
将更多服务器添加到Kafka集群有点琐碎,所需要做的只是启动一个新实例,为其分配唯一的代理ID,一旦启动,便将一些分区分配给该新代理。 从那里,Kafka会小心地将数据复制到适当的代理,并将代理集成到自动管理现有分区和副本的群集中。
Topics
Kafka在其分布式日志系统上提供了一个主题抽象,可以将其分区1到N次,其分区也可以复制1到N次,以实现高可用性和持久性。
一个主题可以有零个到许多订阅者来订阅,以接收其中包含的数据,并且每个主题可以被多次分区,当一个主题被分区时,消息将被存储并路由到每个分区,前提是您提供或不提供密钥。 向主题发送消息。
Kafka Producers
生产者使我们能够发布主题消息。 如果我们提供密钥,则生产者还负责将我们的消息路由到适当的分区;如果我们不随消息一起提供密钥,则默认情况下以循环方式进行。
Kafka Producer的Java实现是线程安全的,因此可以重用于将消息发送到不同的分区甚至主题,并且根据某些基准,实际上建议重用该主题,并且在许多情况下可以实现更好的性能。
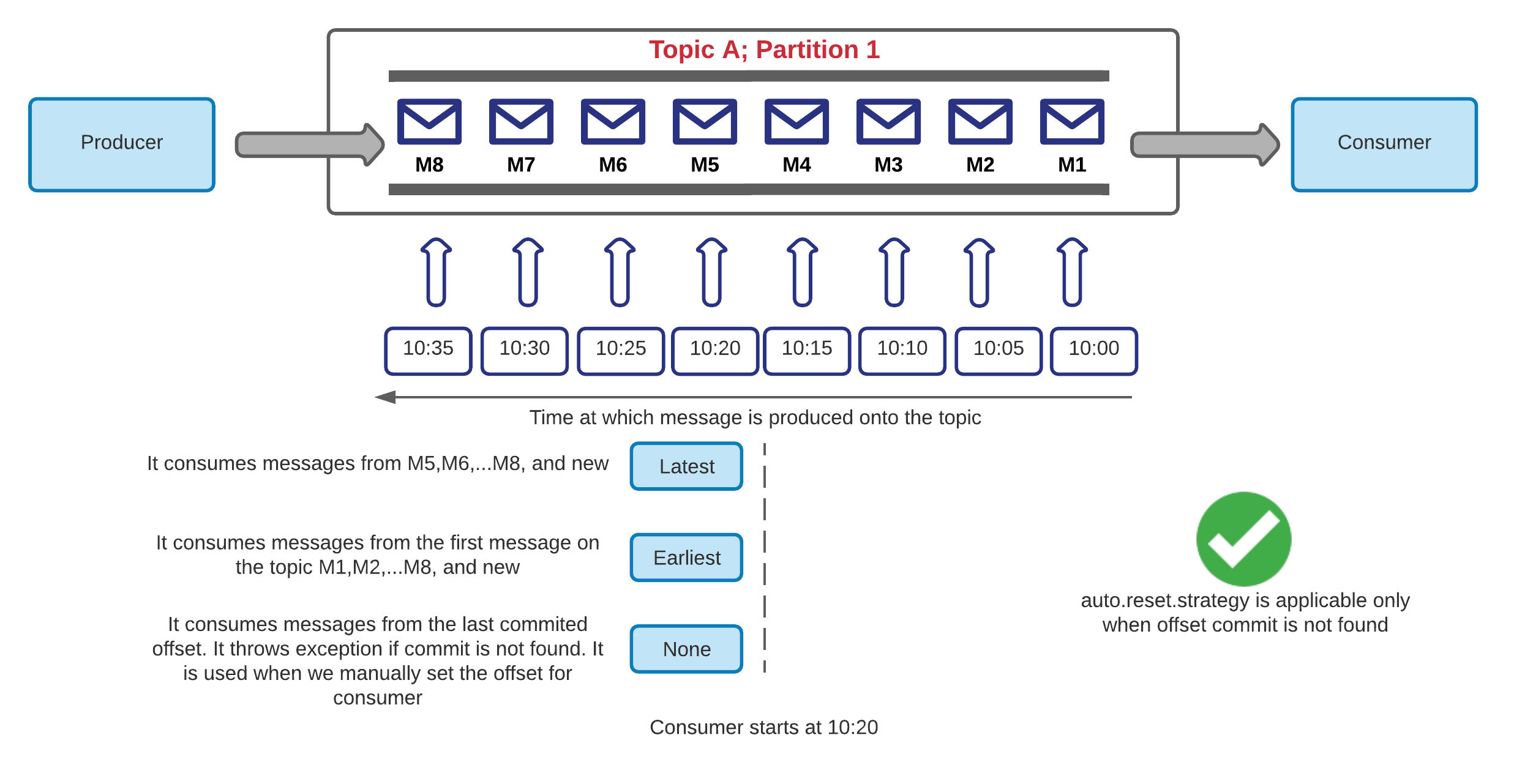
消息总是按照生产者发送消息的顺序添加到日志中,并且每条消息都会自动获得一个“偏移”号。 使用者以与存储在日志中相同的顺序读取消息。
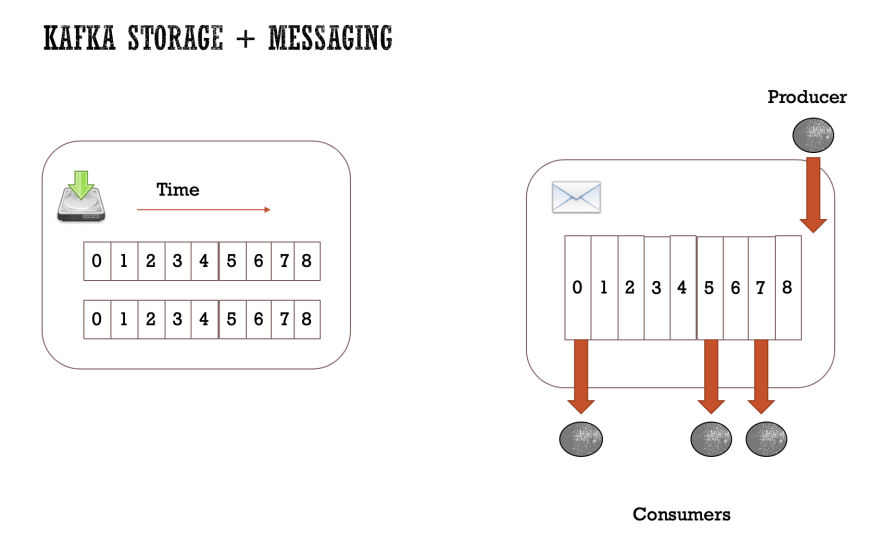
当您使用Kafka生产者向特定主题发送消息而没有提供密钥时,生产者将使用循环机制,并在所有分区之间均匀地分配消息。
如果为每个消息提供密钥,则生产者将对密钥进行哈希处理以选择分区,结果哈希值必须在0-NP的范围内(零至分区数),这将为您提供对指定密钥的订购保证,如 它们都将位于同一有序分区中。
Kafka Consumers
消费者阅读从1到N个主题及其分区的消息。
使用者可以控制这些消息的处理方式,可以根据其配置并行化和分配负载,这可以通过配置消费群体 if you give the same 消费群体 to multiple instances consuming from the same topic they will share the load, dividing the available partitions on that specific topic between the existent group members which will then work as a point to point mechanism where each instance will read from a specific partition.
另一方面,如果您给每个客户端实例都是它自己的群组编号每个实例将处理来自该特定主题的所有现有分区的消息。
多个使用者可以读取特定主题中的数据,每个使用者将控制自己的偏移量。
Kafka Streams
It's a library that abstracts a consumer/producer client where the data is read and published back to a Kafka topic. In this process, you can do data transformation, joins, and many other interesting operations. The most notable and interesting difference between Kafka streams and other streaming platforms like Apache Flink, Apache Spark and other streaming platforms is that Kafka streams being a library it runs directly, co-located with your application, in the same JVM, which gives you a lot of flexibility and control as a developer and enables some nice possibilities.
There's a very nice article comparing Kafka Streams and Flink published at the Confluent Blog if you want to know more details about the differences I recommend you to read it.
The Kafka streams API is divided into two, a high-level Streams DSL which provides you stateless and stateful operations over the stream created from a topic and is, in most cases enough, the Streams API also provides a low-level Processor APIs which gives you more control with the tradeoff of extra complexity. The recommendation is to use it only in very specific cases where you need more control over your streams and can't get it done with the Streams DSL.
我们将在以后的文章中更详细地介绍Kafka Streams。
Kafka Connectors
Kafka连接器使您能够以可靠和高性能的方式在Kafka和外部资源之间“同步”数据,从而使您能够在系统之间移动大量数据,同时利用Kafka的弹性和可扩展性并利用其对偏移量和通用值的自动控制 集成组织中不同数据源的框架。
对于大型组织而言,拥有标准,自动化和可靠的集成非常重要,这使团队能够对来自许多不同系统的变化数据进行实时处理和做出反应。
我们将在以后的文章中更详细地介绍Kafka连接器。
Wrapping up
我们刚刚完成了有关Kafka的快速速成课程。 我希望本文对您对Kafka的简要概述有一个有益的了解,了解它的工作原理及其API。
For a more detailed explanation of some of the concepts covered here, I strongly suggest that you take a look at this article from my friend Tim: Head First Kafka where those concepts are covered in a very friendly way.
References
一种pache Kafka Official Documentation
Confluent Platform Documentation
小号pring Kafka
Ťhe Log: What every software engineer should know about real-time data's unifying abstraction.