本文主要是介绍卡夫卡 启动生产者_如何使卡夫卡生产者消费品生产做好准备,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
卡夫卡 启动生产者
Kafka is an open-source stream processing platform. It is developed to provide high throughput and low latency to handle real-time data.
Kafka是一个开源流处理平台。 开发它是为了提供高吞吐量和低延迟来处理实时数据。
Before we read about how to make our Kafka producer/consumer production-ready, Let’s first understand the basic terminologies of Kafka.
在我们了解如何使我们的Kafka生产者/消费者生产就绪之前,让我们首先了解Kafka的基本术语。
Kafka topic: It refers to a family or name to store a specific kind of message or a particular stream of data. A topic contains messages of a similar kind.
Kafka主题:它是指用于存储特定类型的消息或特定数据流的族或名称。 主题包含类似的消息。
Kafka partition: A topic can be partitioned into one or more partitions. It is again to segregate the messages from one topic into multiple buckets. Each partition may reside on the same/different Kafka brokers.
Kafka分区:一个主题可以分为一个或多个分区。 再次将消息从一个主题隔离到多个存储桶中。 每个分区可以驻留在相同/不同的Kafka代理上。
Kafka producer: It is a component of the Kafka ecosystem which is used to publish messages onto a Kafka topic.
Kafka生产者:它是Kafka生态系统的组成部分,用于将消息发布到Kafka主题上。
Kafka consumer: It is another component of the Kafka ecosystem which consumes messages produced by a Kafka producer on a topic.
卡夫卡消费者:这是卡夫卡生态系统的另一个组成部分,使用卡夫卡生产者产生的有关主题的消息。
Kafka生产者配置 (Kafka producer configurations)
Having knowledge of these producer configurations becomes critical for us in order to get optimal performance and to leverage the capabilities of Kafka in your streaming application in the best possible way. There are multiple configurations. Let's look at each of them in detail below:
了解这些生产者配置对于我们至关重要,以便获得最佳性能并以最佳方式在您的流式应用程序中利用Kafka的功能。 有多种配置。 让我们在下面详细查看它们:
Retries: This configuration is used to set the maximum number of retry attempts to be done by the producer in case of any message publish failure. If your application can not afford to miss any data publish, we increase this count to guarantee to publish our data.
重试:此配置用于设置在任何消息发布失败的情况下,生产方要进行的最大重试次数。 如果您的应用程序不能错过任何发布的数据,我们将增加此计数以保证发布我们的数据。
Batch size: It is set to have high throughput in our producer application by combining multiple network calls into one.
batch.sizemeasures batch size in total bytes, how many bytes to be collected before sending to Kafka broker. It makes sense to increase its value when your producer is publishing data all the time to have the best throughput otherwise, it will have to wait till the given size is collected. The default value is 16384.批处理大小:通过将多个网络调用组合为一个,可以在我们的生产者应用程序中实现高吞吐量。
batch.size以总字节batch.size衡量批量大小,即在发送到Kafka经纪人之前要收集多少字节。 当您的生产者一直在发布数据以具有最佳吞吐量时,增加其价值是有意义的,否则,它将不得不等到收集给定的大小。 默认值为16384 。Linger time: This configuration collaborates with batch size to have high throughput.
linger.mssets the maximum time to buffer data in asynchronous mode. Suppose we set 300kb inbatch.sizeand 10 ms inlinger.ms, then the producer waits till at least one of them is breached. By default, the producer does not wait. It sends the buffer any time data is available. This would reduce the number of requests sent, but would add up to n milliseconds of latency to records sent.延迟时间:此配置与批处理大小协作以实现高吞吐量。
linger.ms设置在异步模式下缓冲数据的最长时间。 假设在我们设定的300KBbatch.size和10毫秒linger.ms,则生产者等待,直到它们中的至少一个被破坏。 默认情况下,生产者不等待。 只要有数据,它就会发送缓冲区。 这将减少发送的请求数,但会给发送的记录增加最多n毫秒的延迟。Send() method: There are 3 ways to publish messages onto a Kafka topic.
Send()方法:有3种方法可以将消息发布到Kafka主题上。
Send() method: There are 3 ways to publish messages onto a Kafka topic.A. Fire and forget — It is the fastest way to publish messages, but messages could be lost here.
Send()方法:有3种方法可以将消息发布到Kafka主题上。 A.忘却了-这是发布消息的最快方法,但是消息可能会在此处丢失。
Send() method: There are 3 ways to publish messages onto a Kafka topic.A. Fire and forget — It is the fastest way to publish messages, but messages could be lost here.
RecordMetadata rm = producer.send(record);B. Synchronous — It is the slowest method, we use it when we can not afford to lose any message. It blocks the thread to produce a new message until an acknowledgment is received for the last published message.RecordMetadata rm = producer.send(record).get();C. Asynchronous — It gives us better throughput comparing to synchronous since we don’t wait for acknowledgments.producer.send(record, new Callback(){
@Override
onComplete(RecordMetadata rm, Exception ex){...}
})Send()方法:有3种方法可以将消息发布到Kafka主题上。 A.忘却了-这是发布消息的最快方法,但是消息可能会在此处丢失。
RecordMetadata rm = producer.send(record);B.同步-这是最慢的方法,当我们无法承受丢失任何消息时,我们会使用它。 它阻塞线程以产生新消息,直到收到最后发布的消息的确认为止。RecordMetadata rm = producer.send(record).get();C.异步-与同步相比,它为我们提供了更好的吞吐量,因为我们不等待确认。producer.send(record, new Callback(){
@Override
onComplete(RecordMetadata rm, Exception ex){...}
})Acks: It is used to set the number of replicas for which the coordinator node will wait before sending a successful acknowledgment to the producer application. There are 3 values possible for this configuration —
0,1 and -1(all). 0 means no acknowledgment is required. It is set when low latency is required. -1 (or all) means response from all the replicas for the given partition is inevitable and it is set when data consistency is most crucial.Acks:用于设置协调器节点向生产者应用程序发送成功确认之前等待的副本数。 此配置可能有3个值
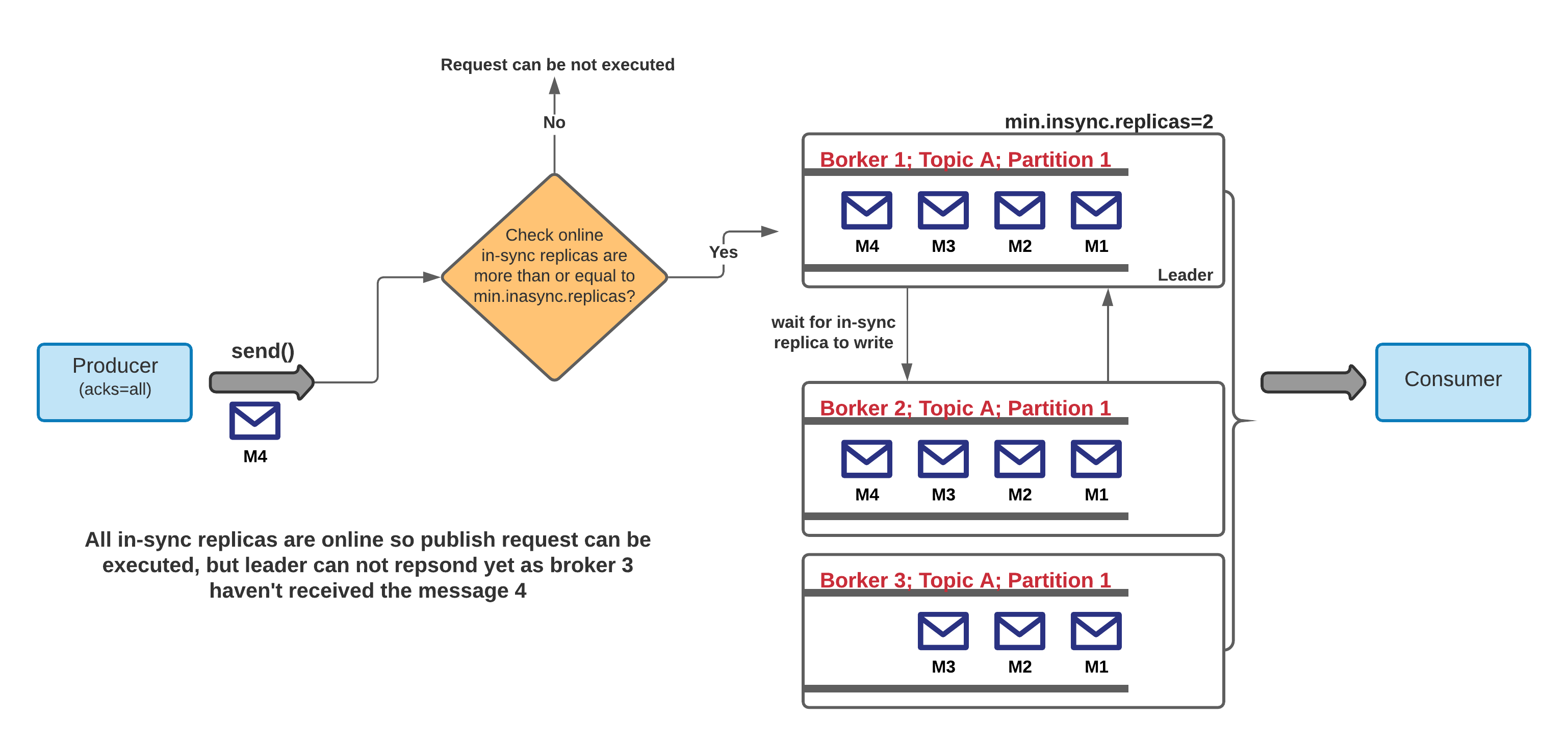
0,1 and -1(all)。 0表示不需要确认。 需要低延迟时设置。 -1(或全部)表示来自给定分区的所有副本的响应是不可避免的,并且在数据一致性最为关键时进行设置。There is one more important property
还有一个重要的属性
min.insync.replicasthat works withacks=allproperty. For any publish request withacks=allto execute, there should be at least these many in-sync replicas online, otherwise the producer will get exceptions.与
acks=all属性一起使用的min.insync.replicas。 对于要执行的acks=all带有acks=all发布请求,至少应在线上有这么多个同步副本,否则生产者将获得异常。
卡夫卡消费者配置 (Kafka consumer configuration)
Let’s understand how to tune our Kafka consumer to consume messages from Kafka efficiently. Like a Kafka producer, a consumer also has a number of configurations.
让我们了解如何调整我们的Kafka用户以有效地使用来自Kafka的消息。 像卡夫卡生产者一样,消费者也有许多配置。
Consumer group: It plays a significant role for the consumer as you can have multiple instances of the consumer application within the same consumer group to consume messages from a Kafka topic. The number of consumers should be less than or equal to the number of partitions in the Kafka topic as a partition can be assigned to only one consumer in a consumer group.
使用者组:它对使用者起着重要的作用,因为您可以在同一使用者组中拥有多个使用者应用程序实例,以使用来自Kafka主题的消息。 使用者数量应小于或等于Kafka主题中的分区数量,因为一个分区只能分配给一个使用者组中的一个使用者。
Best performance is achieved when
当达到最佳性能时
#consumers = #partitions#consumers = #partitionsAuto vs Manual commit: A consumer has to commit the offset after consuming a message from a topic. This commit can be made automatically or manually.
自动提交与手动提交:使用者在消费了主题消息后必须提交偏移量。 可以自动或手动进行此提交。
Auto vs Manual commit: A consumer has to commit the offset after consuming a message from a topic. This commit can be made automatically or manually.
enable.auto.commitis the property which needs to be true to enable auto-commit. It is enabled by default.自动提交与手动提交:使用者在消费了主题消息后必须提交偏移量。 可以自动或手动进行此提交。
enable.auto.commit是必须为true的属性,以启用自动提交。 默认情况下启用。Auto vs Manual commit: A consumer has to commit the offset after consuming a message from a topic. This commit can be made automatically or manually.
enable.auto.commitis the property which needs to be true to enable auto-commit. It is enabled by default.auto.commit.interval.msis the dependent property which is taken into account when auto-commit is enabled. It is used to set the max time in ms to wait to make a commit for the consumed messages.自动提交与手动提交:使用者在消费了主题消息后必须提交偏移量。 可以自动或手动进行此提交。
enable.auto.commit是必须为true的属性,以启用自动提交。 默认情况下启用。auto.commit.interval.ms是从属属性,启用自动提交时会考虑该属性。 它用于设置等待提交消耗消息的最长时间(以毫秒为单位)。Auto vs Manual commit: A consumer has to commit the offset after consuming a message from a topic. This commit can be made automatically or manually.
enable.auto.commitis the property which needs to be true to enable auto-commit. It is enabled by default.auto.commit.interval.msis the dependent property which is taken into account when auto-commit is enabled. It is used to set the max time in ms to wait to make a commit for the consumed messages. There could be a situation where messages are read, but not processed yet and the application crashes for a reason, then the last read messages will be lost when we restore the application. Manual commit comes into the picture to prevent this situation where the consumer makes commit once it processes the messages completely.自动提交与手动提交:使用者在消费了主题消息后必须提交偏移量。 可以自动或手动进行此提交。
enable.auto.commit是必须为true的属性,以启用自动提交。 默认情况下启用。auto.commit.interval.ms是从属属性,启用自动提交时会考虑该属性。 它用于设置等待提交消费消息的最长时间(以毫秒为单位)。 可能存在读取消息但尚未处理消息并且应用程序由于某种原因崩溃的情况,那么当我们还原应用程序时,最后读取的消息将丢失。 手动提交会出现在图片中,以防止这种情况,即消费者在完全处理完消息后即进行提交。Heartbeat interval: This property is used by the consumers to send their heartbeat to the Kafka broker. It tells Kafka that the given consumer is still alive and consuming messages from it.
心跳间隔:消费者使用此属性将心跳发送到Kafka代理。 它告诉Kafka,给定的使用者仍在运行,并且正在使用该使用者的消息。
Heartbeat interval: This property is used by the consumers to send their heartbeat to the Kafka broker. It tells Kafka that the given consumer is still alive and consuming messages from it.
heartbeat.interval.ms = 10msthe consumer sends its heartbeat to the Kafka broker at every 10 milliseconds.心跳间隔:消费者使用此属性将心跳发送到Kafka代理。 它告诉Kafka,给定的使用者仍在运行,并且正在使用该使用者的消息。
heartbeat.interval.ms = 10ms,消费者每10毫秒将其心跳发送到Kafka代理。Session timeout: It is the time when the broker decides that the consumer is died and no longer available to consume.
会话超时:这是经纪人确定消费者死亡并且不再可以消费的时间。
Session timeout: It is the time when the broker decides that the consumer is died and no longer available to consume.
session.timeout.ms = 50 msSuppose the consumer is down and it is not sending heartbeat to Kafka broker, then the broker waits until 50 ms time is over, to decide the consumer is dead.会话超时:这是经纪人确定消费者死亡并且不再可以消费的时间。
session.timeout.ms = 50 ms假设使用者关闭并且没有向Kafka经纪人发送心跳,然后该经纪人等待直到50毫秒时间结束,以决定使用者死亡。Auto offset reset strategy: It is used to define the behavior of the consumer when there is no committed offset. This would be the case when the consumer is started for the first time or when an offset is out of range. There are 3 possible values for the property
auto.offset.reset = earliest, latest, none. The default value is latest.自动偏移量重置策略:用于定义没有提交偏移量时使用者的行为。 当使用者第一次启动或偏移量超出范围时,就会出现这种情况。 属性
auto.offset.reset = earliest, latest, none3种可能的值。 默认值为最新。Auto offset reset strategy: It is used to define the behavior of the consumer when there is no committed offset. This would be the case when the consumer is started for the first time or when an offset is out of range. There are 3 possible values for the property
auto.offset.reset = earliest, latest, none. The default value is latest.Note: This configuration is applicable only when no offset commit is found.自动偏移量重置策略:用于定义没有提交偏移量时使用者的行为。 当使用者第一次启动或偏移量超出范围时,就会出现这种情况。 属性
auto.offset.reset = earliest, latest, none3种可能的值。 默认值为最新。 注意:仅当未找到偏移提交时,此配置才适用。
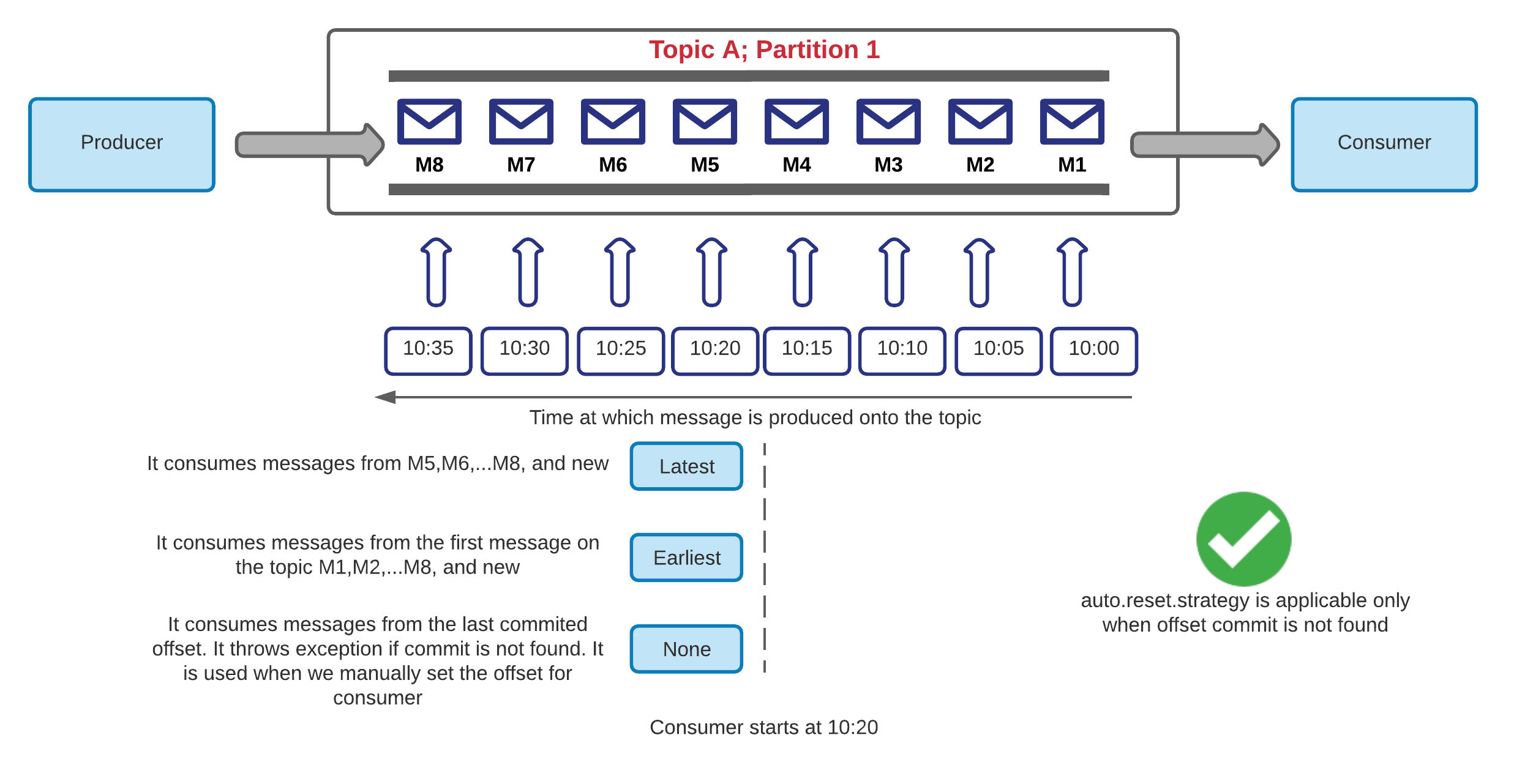
One more important thing that affects what offset value will correspond to the earliest and latest configs is log retention policy. Imagine we have a topic with retention configured to 1 hour. We produce 10 messages, and then an hour later we publish 5 more messages. The latest offset will still remain the same as explained above, but the earliest one won’t be able to be 0 because Kafka will have already removed these messages and thus the earliest available offset will be 10.
更重要的一点是,日志保留策略会影响什么偏移值将对应最早和最新的配置。 想象一下,我们有一个保留时间配置为1小时的主题。 我们产生10条消息,然后一个小时后,我们又发布5条消息。 最新的偏移量仍将保持与上面说明的相同,但是最早的偏移量将不能为0,因为Kafka将已经删除了这些消息,因此最早的可用偏移量将为10。
Thanks for reading!
谢谢阅读!
翻译自: https://medium.com/swlh/how-to-make-kafka-producer-consumer-production-ready-d40915b78c9
卡夫卡 启动生产者
相关文章:
这篇关于卡夫卡 启动生产者_如何使卡夫卡生产者消费品生产做好准备的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








