本文主要是介绍卡夫卡详解_如何宣传卡夫卡,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
卡夫卡详解
Imagine you are a senior engineer working in a company that’s running its tech stack on top of AWS. Your tech organization is probably using a variety of AWS services including some messaging services like SQS, SNS and Kinesis. As someone who reads technical blog posts once in a while you realize Apache Kafka is pretty popular technology for event streaming. You read it is supporting lower latencies, higher throughput, longer retention periods, used in the largest tech organizations and one of most popular Apache projects. You hop into your (now virtual) Architect / CTO / VP seat and tell her you should use Kafka. Following a quick POC you report back that, yes the throughput is great, but you couldn’t support it yourself because of its complexity and the many knobs you need to turn to make it work properly. That’s pretty much where it stays and you let it go.
假设您是一家在AWS上运行其技术堆栈的公司中的高级工程师。 您的技术组织可能正在使用各种AWS服务,包括一些消息服务,例如SQS,SNS和Kinesis。 偶尔阅读技术博客文章的人会意识到Apache Kafka是事件流非常流行的技术。 您会读到它支持更低的延迟,更高的吞吐量 ,更长的保留期, 并在最大的技术组织和最受欢迎的Apache项目之一中使用 。 您跳入(现在是虚拟的)架构师/ CTO / VP座位,并告诉她您应该使用Kafka。 快速POC之后,您会报告说,是的,吞吐量很好,但是由于它的复杂性以及要使其正常工作而需要转动的许多旋钮,您自己无法提供支持。 那几乎就在那里,你放手了。
双方 (Being on Both Sides)
That is pretty much what I went through from the architect side at my previous company as I did not think it was justified to add a few engineers for better technical performance. I simply did not see the ROI. When you focus your argument solely on technical benefits (of any technology) to decision makers at a company, you are not doing any favors to yourself and you will miss out. Ask yourself what is the impact on your organization, what are the challenges your organization faces with data and what people are investing their time on when they should be innovating on data.
这几乎是我从前任公司的架构师那儿经历的,因为我认为增加一些工程师以获得更好的技术性能是不合理的。 我根本没有看到投资回报率。 当您仅将论点仅集中于公司决策者的(任何技术的)技术收益时,您就不会对自己有任何帮助,您会错失良机。 问问自己对组织的影响是什么,组织在数据方面面临什么挑战,以及人们在应该何时进行数据创新方面投入了哪些时间。
Working on Zillow Group’s Data Platform for the past couple of years, looking at the broader challenges of the Data Engineering group, it was time for me to be on the other side, pitching to managers and executives the value of Kafka. I’ve researched it more thoroughly this time and what business value it would bring.
在过去的几年中,在Zillow Group的数据平台上工作时,着眼于Data Engineering团队所面临的广泛挑战,现在是我站在另一侧的时候了,向经理和行政人员介绍Kafka的价值。 这次,我已经对其进行了更彻底的研究,以及它将带来什么商业价值。
云提供商只是魔幻世界 (Cloud Providers are only Half Magic)
See, the democratization of infrastructure by cloud providers made it easy to just spin up the service you need, winning over on-premises solutions not only from a cost point of view but also from a developer experience one. Consider a case where my team needs to generate data about Users’ interactions with their “Saved Homes” and send it to our push notification system. The team decides to provision a Kinesis stream to do that. How would other people in the company know that we did that? Where would they go look for such data (especially when using multiple AWS accounts)? How would they know the meta information about the data (schema, description, interoperability, quality guarantees, availability information, partitioning scheme and much more)?
可见,云提供商的基础设施民主化使得轻松启动所需的服务变得容易,不仅从成本角度而且从开发人员的经验中赢得了本地解决方案。 考虑以下情况:我的团队需要生成有关用户与其“已保存房屋”互动的数据,并将其发送到我们的推送通知系统。 该团队决定提供Kinesis流来实现这一点。 公司中的其他人怎么知道我们做到了? 他们会去哪里寻找此类数据(尤其是在使用多个AWS账户时)? 他们将如何知道有关数据的元信息(模式,描述,互操作性,质量保证,可用性信息,分区方案等等)?

For a vast number of companies, data is the number one asset and source of innovation. Democratizing data infrastructure without a standardized way for defining metadata, common ingestion/consumption patterns and quality guarantees can slow down the innovation from data or make dependencies a nightmare.
对于众多公司而言,数据是创新的头号资产和来源。 如果没有标准化的元数据定义方法,通用的摄取/消费模式和质量保证,使数据基础架构民主化,可能会减慢数据创新的速度或使依赖成为噩梦。
Think about the poor team trying to find the data in the sea of Kinesis streams (oh hello AWS Console UI :-( ) and AWS accounts used in the company. Once they do find it, how would they know the format of the data? How would they know what field “is_tyrd” means? What would their production service do once the schema changes? Many RCAs have been born simply because of that. In reality, as the company grows, so do the complexities of its data pipelines. It’s no longer a producer consumer relationship, but rather many producers, many middle steps, intermediary consumers who are also producers, joins, transformations and aggregations, which may end up in a failing customer report (at best) or bad data impacting the company revenue.
想想这个糟糕的团队试图在Kinesis流的海洋中查找数据(哦,您好,AWS Console UI :-()和公司中使用的AWS帐户。一旦找到它们,他们将如何知道数据的格式?他们将如何知道“ is_tyrd”字段的含义;一旦架构发生更改,他们的生产服务将执行什么工作;许多RCA正是由于这一原因而诞生的;实际上,随着公司的发展,其数据管道的复杂性也随之而来。不再是生产者与消费者的关系,而是许多生产者,许多中间步骤,同时也是生产者的中间消费者,联接,转换和聚合,最终可能导致失败的客户报告(充其量)或不良的数据影响公司的收入。
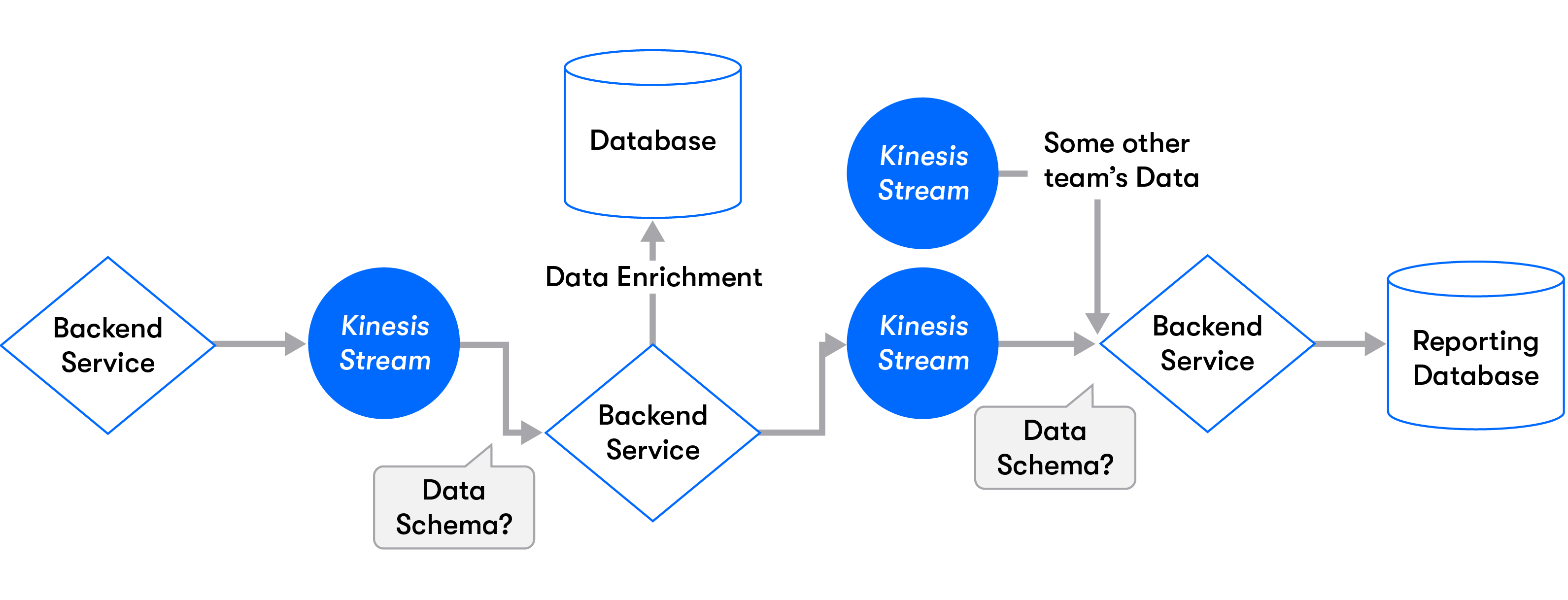
All of that doesn’t really have a lot to do with either Kinesis or Kafka, but mostly about understanding that the cloud providers’ level of abstraction and “platform” ecosystem is simply not enough as it is to help mid-size/large companies innovate on data.
所有这些都与Kinesis或Kafka并没有多大关系,但主要是要了解云提供商的抽象水平和“平台”生态系统根本不足以帮助中型/大型公司在数据上创新。
这是生态系统的愚蠢 (It is the Ecosystem Stupid)
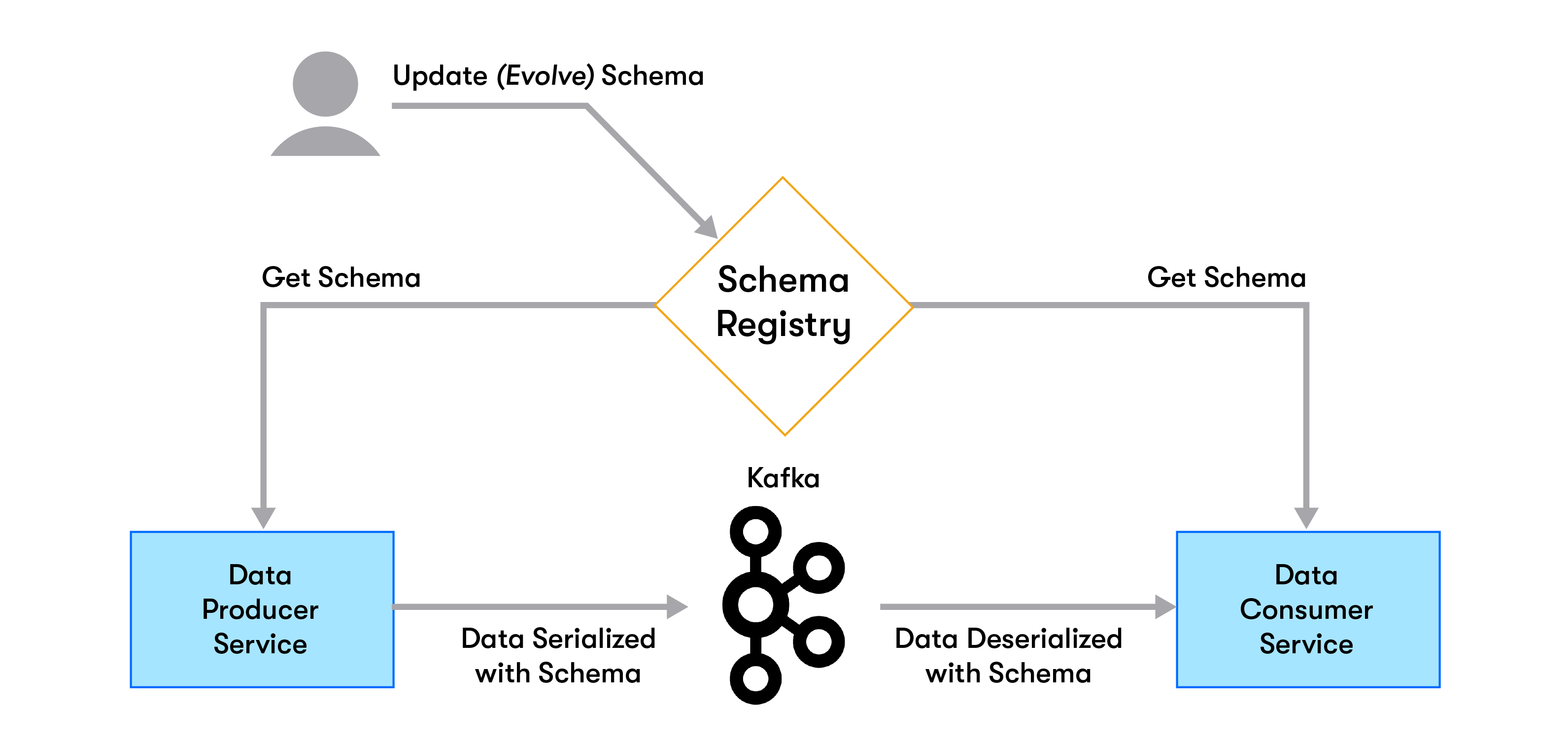
With Kafka, first and foremost, you have an ecosystem led by the Confluent Schema Registry. The combination of validation-on-write and schema evolution has a huge impact on data consumers. Using the Schema Registry (assuming compatibility mode) guarantees your consumers that they will not crash due to de-serialization errors. Producers can feel comfortable evolving their schemas without that risk of impacting downstream, and the registry itself provides a way for all interested parties to understand the data. At least at the schema level.
首先,使用Kafka,您将拥有一个由Confluent Schema Registry领导的生态系统。 写入时验证和模式演变的结合对数据使用者具有巨大影响。 使用Schema Registry(假定兼容模式)可以确保您的使用者不会因反序列化错误而崩溃。 生产者可以轻松地发展自己的模式,而又不会影响下游,而注册表本身为所有感兴趣的各方提供了一种理解数据的方式。 至少在架构级别。
Kafka Connect is another important piece of the ecosystem. While AWS services are great at integrating between themselves, they are less than great with integrating with everything else. The closed garden simply doesn’t allow the community to come together and build those integrations. While Kinesis has integration capabilities using DMS it is well shy of the Kafka Connect ecosystem of integrations, and connecting your data streams to other systems in an easy and common way is another key to getting more from your data.
Kafka Connect是生态系统的另一个重要组成部分。 尽管AWS服务擅长在它们之间进行集成,但与整合其他所有功能相比却不够出色。 封闭的花园根本不允许社区聚集在一起进行整合。 虽然Kinesis具有使用DMS的集成功能 ,但与Kafka Connect集成生态系统相去甚远 ,而以简单而通用的方式将数据流连接到其他系统是从数据中获取更多收益的另一关键。
A more technical piece of the ecosystem I’ll discuss is the client library. The Kinesis Producer Library is a daemon C++ process that is somewhat of a black box which is harder to debug and maintain of going rogue. The Kinesis Consumer Library is coupled with DynamoDB for offset management — which is another component to worry about (getting throughput exceptions for example). In my last two companies we have actually implemented our own, thinner (simpler) version of the Kinesis Producer Library. In that sense it is again the open source community and the popularity of Kafka that helps in having more mature clients (with the bonus of offsets being stored within Kafka).
我将讨论的生态系统中更具技术性的部分是客户端库。 Kinesis Producer库是一个守护程序C ++进程,它有点像一个黑匣子,很难调试和维护恶意程序。 Kinesis Consumer Library与DynamoDB结合用于偏移量管理—这是另一个值得担心的组件(例如,获取吞吐量异常)。 在我的前两家公司中,我们实际上实现了我们自己的Kinesis Producer库的更薄(更简单)的版本。 从这个意义上讲,开源社区和Kafka的流行再次帮助拥有了更多成熟的客户(抵消额度的奖励存储在Kafka中)。
And then you get to a somewhat infamous point around AWS Kinesis — its read limits. A Kinesis shard allows you to make up to 5 read transactions per second. On top of the inherent latency that limit introduces, it is the coupling of different consumers that is most bothersome. The entire premise of streaming talks about decoupling business areas in a way to reduce coordination and just have data as an API. Sharing throughput across consumers mandates one to be aware of the other to make sure consumers are not eating away each other’s throughput. You can mitigate that challenge through Kinesis Enhanced Fan-Out but it does cost a fair bit more. Kafka on the other hand is bound by resources rather than explicit limits. If your network, memory, CPU and disk can handle additional consumers, no such coordination is needed. Worth noting that Kinesis being a managed service has to tune to fit the majority of the customer workload requirements (one size fits all), while with your own Kafka you can tailor fit it.
然后您会发现关于AWS Kinesis的一个臭名昭著的观点-它的读取限制。 Kinesis分片允许您每秒最多进行5次读取事务 。 除了限制引入的固有延迟之外,最麻烦的是不同使用者的耦合。 流式传输的整个前提是讨论如何将业务区域分离,以减少协调并仅将数据作为API。 在消费者之间共享吞吐量要求一个人知道另一方,以确保消费者不会蚕食彼此的吞吐量。 您可以通过Kinesis增强型扇出来缓解这种挑战,但确实要花费更多 。 另一方面,Kafka受资源的约束,而不是明确的限制。 如果您的网络,内存,CPU和磁盘可以处理其他使用者,则无需进行此类协调。 值得注意的是,作为托管服务的Kinesis必须进行调整以适应大多数客户工作负载要求(一种尺寸适合所有需求),而对于您自己的Kafka,您可以对其进行定制。
太好了,卡夫卡。 怎么办? (Great, Kafka. Now What?)
But know (and let your executives know) that all this good stuff is not enough to reach a nirvana of data innovation, which is why our investment in Kafka included a Streaming Platform team.
但是要知道(并让您的高管知道)所有这些好东西还不足以达到数据创新的必杀技,这就是为什么我们对Kafka的投资包括一个Streaming Platform团队。
The goal for the team is to make Kafka the central nervous system of events across Zillow Group. We got inspiration from companies like PayPal and Expedia and set these decisions:
该团队的目标是使卡夫卡成为整个Zillow集团事件的中枢神经系统。 我们从PayPal和Expedia等公司那里获得了灵感,并制定了以下决定:
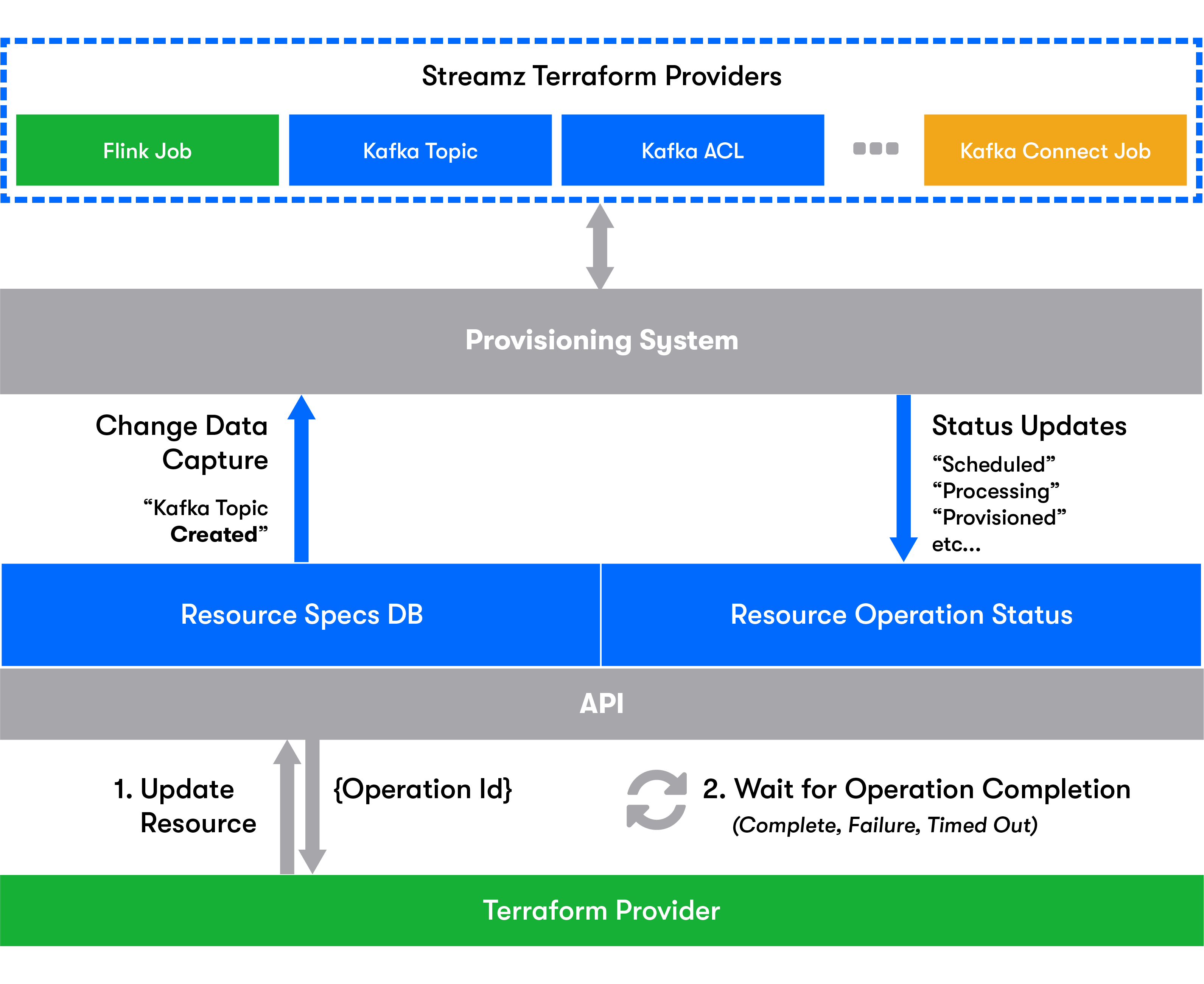
We’ll delight our customers by meeting them where they are-Most of Zillow Group is using Terraform for its Infrastructure as Code solution. We have decided to build a Terraform provider for our platform. This also helps us to balance out between decentralization (not having a central team that needs to approve every production topic) and control (think how you prevent someone from creating a 10000 partitions topic).
我们将通过与客户见面的方式来满足客户的要求-Zillow Group的大多数公司都将Terraform用于其基础设施即代码解决方案。 我们已决定为我们的平台构建Terraform提供程序。 这也有助于我们在分散化(没有需要批准每个生产主题的中央团队)和控制(考虑如何防止某人创建10000个分区主题)之间取得平衡。
We will invest heavily in metadata for discoverability The provisioning experience will include all necessary metadata to discover ownership, description, data privacy info, data lineage and schema information (Kafka only allows linking schemas by naming conventions). We will connect the metadata with our company’s Data Portal which helps people navigate through the entire catalog of data and removes tribal knowledge dependency.
我们将在元数据上进行大量投资以提高可发现性供应体验将包括所有必要的元数据,以发现所有权,描述,数据隐私信息,数据沿袭和架构信息(Kafka仅允许通过命名约定链接架构)。 我们将把元数据与我们公司的数据门户相连接,该门户将帮助人们浏览整个数据目录并消除部落知识的依赖性。
We will help our customers adopt Kafka by removing the need to get into the complex details whenever possible — A configuration service that injects whatever producer/consumer configs you may require is helping achieve that, along with a set of client libraries for the most common use cases.
我们将通过消除在任何可能的情况下进入复杂细节的需求来帮助我们的客户采用Kafka-注入您可能需要的任何生产者/消费者配置的配置服务正在帮助实现这一点,以及一组最常用的客户端库案件。
We will build company wide data ingestion patterns — mostly using Kafka Connect, but also by integrating with our Data Streaming Platform service which proxies Kafka.
我们将建立公司范围内的数据摄取模式 -主要使用Kafka Connect,也将与我们的代理Kafka的Data Streaming Platform服务集成。
We will connect with our Data Governance team as they build Data Contracts and Anomaly detection services — to be able to provide guarantees about the data within Kafka, and prevent the scenario of data engineers chasing upstream teams to understand what went wrong with the data.
在建立数据合同和异常检测服务时,我们将与数据治理团队保持联系 -以便为Kafka中的数据提供保证,并防止数据工程师追赶上游团队以了解数据出了问题的情况。
Lastly, before your pitch, get to know the numbers. How much does your organization spend on those AWS services? how much (time/effort/$$) it spends on the pain points I mentioned? Go ahead and research your different deployment options, from vanilla Kafka, Confluent (on-premise and cloud) and the newer AWS MSK.
最后,在推销之前,先了解一下数字。 您的组织在这些AWS服务上花费了多少? 我提到的痛点花费了多少(时间/精力/ $$)? 继续研究各种不同的部署选项,包括香草Kafka, Confluent (本地和云)和较新的AWS MSK 。
Good luck with your pitch!
祝你好运!
翻译自: https://medium.com/zillow-tech-hub/how-to-pitch-kafka-1da73ae050ca
卡夫卡详解
相关文章:
这篇关于卡夫卡详解_如何宣传卡夫卡的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





