本文主要是介绍卡夫卡详解_外行卡夫卡指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
卡夫卡详解
首先,为什么要用卡夫卡? (Firstly why Kafka?)
Kafka’s growth is exploding, more than 1⁄3 of all Fortune 500 companies use Kafka. These companies include the top ten travel companies,7 of the top ten banks, 8 of the top ten insurance companies, 9 of the top ten telecom companies, and much more. LinkedIn, Microsoft, and Netflix process four comma messages a day with Kafka (1,000,000,000,000).
卡夫卡的增长迅猛 ,在世界500强企业中,有超过1⁄3的企业使用卡夫卡。 这些公司包括排名前十的旅行社,排名前十的银行中的七,排名前十的保险公司中的八,排名前十的电信公司中的九,等等。 LinkedIn,Microsoft和Netflix 每天使用Kafka(1,000,000,000,000)处理四条逗号消息。
Kafka is used for real-time streams of data, used to collect big data or to do real-time analysis or both).
Kafka用于实时数据流,用于收集大数据或进行实时分析,或两者兼而有之 。
Kafka is used with in-memory microservices to provide durability and it can be used to feed events to CEP (complex event streaming systems), and IOT/IFTTT style automation systems.If you want to know which companies use Kafka take a look here https://kafka.apache.org/powered-by
Kafka与内存微服务一起使用以提供持久性,并且可以用于将事件馈送到CEP (复杂事件流系统)和IOT / IFTTT风格的自动化系统。如果您想知道哪些公司在使用Kafka,请查看此处https ://kafka.apache.org/powered-by
但是卡夫卡到底是什么? (But what the Heck is Kafka?)

So Kafka is a distributed system consisting of servers and clients that communicate via a high-performance TCP network protocol. It can be deployed on bare-metal hardware, virtual machines, and containers in on-premise as well as cloud environments.
因此,Kafka是一个分布式系统,由通过高性能TCP网络协议进行通信的服务器和客户端组成。 它可以部署在内部以及云环境中的裸机硬件,虚拟机和容器上。
让我们简化一下 (Let’s simplify it a bit)
Think of Kafka as your house mailbox, in Kafka, we refer to that mailbox as a Kafka Topic, other people can send you mail’s on this mailbox address, those senders we refer as Kafka Producers, and yes the people who read those mail are known as Kafka Consumers and well yeah your family living in the same house belonging to a Consumer group all grouped by a Group id.
将卡夫卡视为您的家庭邮箱,在卡夫卡中,我们将该邮箱称为“卡夫卡主题” ,其他人可以在该邮箱地址上向您发送邮件,那些发件人我们称为“卡夫卡生产者” ,是的,阅读这些邮件的人是已知的作为卡夫卡消费者 是的,您的家人住在属于“ 消费者”组的同一个房屋中,所有住房均按“ 组ID”分组。

现在,让我们看看有关我们发现的事物的一些关键功能 (Now Let’s see some of the key features about the things we have discovered)
大事记 (Events)
An Event is the most basic entity in Kafka, it corresponds to a single message/event published or consumed from any topic, When you read or write data to Kafka, you do this in the form of Events.
事件是Kafka中最基本的实体,它对应于从任何主题发布或使用的单个消息/事件,当您向Kafka读取或写入数据时,您将以事件的形式进行操作。
话题 (Topic)
All Kafka Events are organized into topics.
所有Kafka活动均按主题进行组织。

- A topic in Kafka can have zero to many producers writing events to it as well as zero to many consumers that are subscribed to these events. Kafka中的主题可以有零个生产者向其编写事件,也可以零个订阅这些事件的消费者。
- Unlike a traditional messaging system events are not deleted after consumption, you can define how long an event should remain thorough a per-topic configuration setting and read from them as often as needed. 与传统的消息传递系统不同,使用后事件不会被删除,您可以定义事件在每个主题的配置设置中应保留的时间,并根据需要从中读取事件。
经纪人 (Brokers)
Kafka, as a distributed system, runs in a cluster. Each node in the cluster is called a Kafka broker.
Kafka作为分布式系统,在集群中运行。 群集中的每个节点都称为Kafka 代理 。
现在让我们深入探讨这些主题 (Now let us dive a little more into these topics)
Topics in Kafka are Partitioned this is just a fancy way of saying that your events are distributed into several buckets located onto different Kafka brokers. Every Broker has exactly one partition leader which handles all the read/write requests of that broker. If the replication factor is greater than 1, the additional partition replications act as partition followers.
卡夫卡中的主题是分区的,这只是一种奇特的说法,您的事件被分配到了不同的卡夫卡经纪人的多个桶中。 每个经纪人只有一个分区负责人 ,负责处理该经纪人的所有读/写请求。 如果复制因子大于1,则其他分区复制将充当分区跟随器 。
A partition, in theory, can be described as an immutable collection (or sequence) of messages.
从理论上讲,分区可以描述为消息的不可变集合(或序列)。
T
Ť
Each event in a partition has an identifier called offset. This offset is responsible for maintaining the order of your events in a partition for you.
分区中的每个事件都有一个名为offset的标识符。 此偏移量负责为您维护分区中事件的顺序。
Hence to summarise each event in a Kafka topic can be uniquely identified by a tuple of partition, and offset within the partition.
因此,总结一下,Kafka主题中的每个事件都可以由一个分区的元组唯一地标识,并在该分区内偏移。
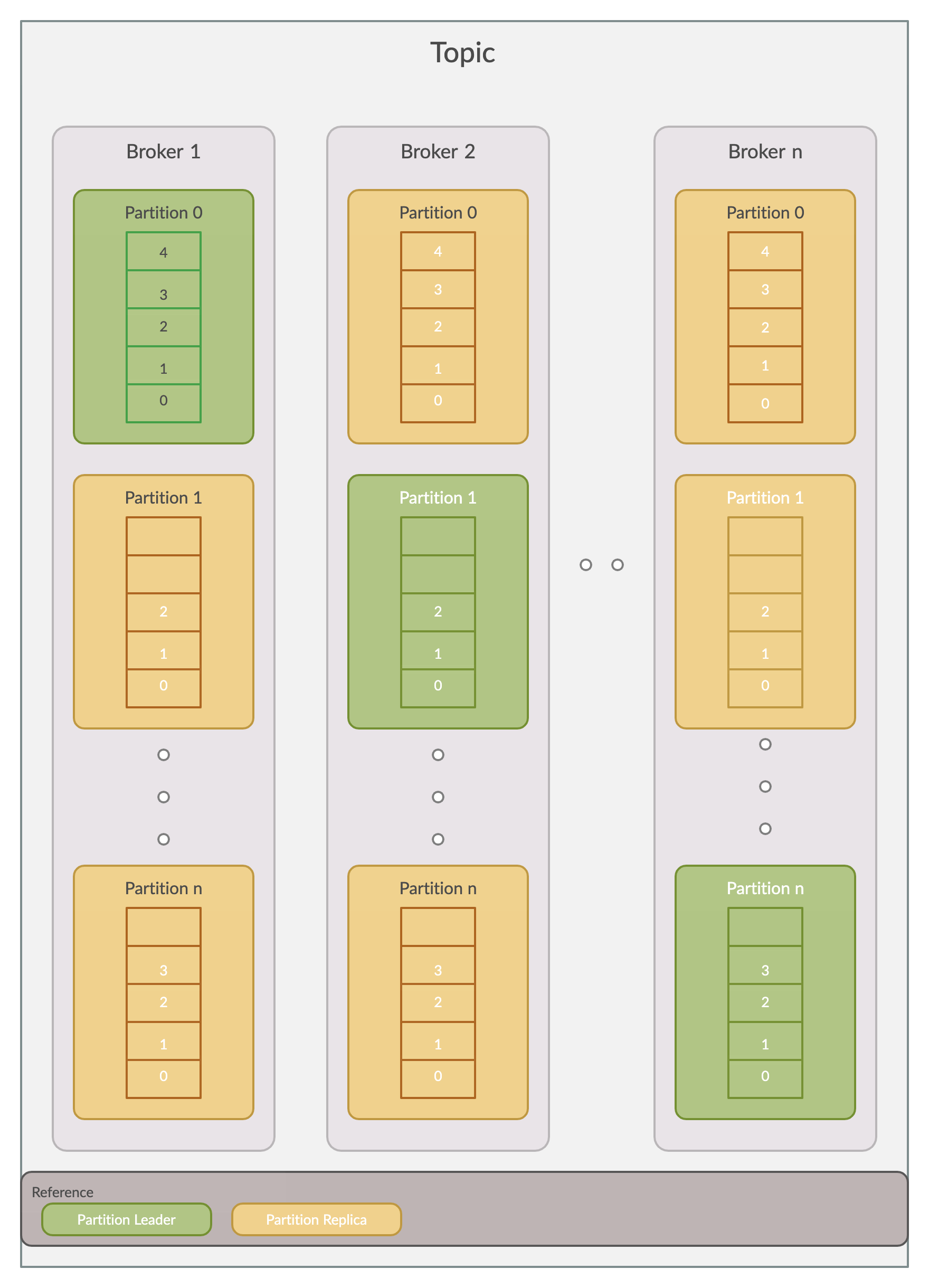
生产者 (Producers)
So far you must have known that a producer is responsible for writing / committing your events to any Kafka topic, so let’s be a little more specific now.
到目前为止,您必须已经知道制作人负责将您的事件编写/提交给任何Kafka主题,所以现在让我们更具体一些。
A Producer writes to a single partition leader for a Kafka topic, this provides a means of load balancing production so that each write can be serviced by a separate broker and machine.
生产者向Kafka主题的单个分区负责人写信,这提供了一种负载均衡生产的方法,以便每个写操作都可以由单独的代理和机器提供服务。
消费者 (Consumers)
Each consumer reads from a single partition, also consumers can be organized into consumer groups for a given topic, the group as a whole consumes all messages from the entire topic.
每个使用者都从单个分区读取,也可以将使用者组织为给定主题的使用者组,该组作为一个整体使用整个主题中的所有消息。
If the number of consumers in a consumer group is more than the number of partitions then some of these consumers will be idle as they have no partition to read from. Similarly, if the number of partitions is more than the number of consumers then consumers will receive messages from multiple partitions
如果使用者组中的使用者数大于分区数,则这些使用者中的一些将处于空闲状态,因为它们没有要读取的分区。 同样,如果分区数大于使用方数,那么使用方将从多个分区接收消息
If you have equal numbers of consumers and partitions, each consumer reads messages in order from exactly one partition.
如果您具有相同数量的使用者和分区,则每个使用者都从一个分区中按顺序读取消息。
卡夫卡担保 (Kafka Guarantees)
There are some claims which Kafka makes but like always there are terms and conditions applied so let’s discuss those first.
Kafka提出了一些主张,但像往常一样,有一些适用的条款和条件,所以让我们先讨论一下。
So Kafka guarantees hold as long as we are producing to one partition and consuming from one partition, it voids as soon as we either read from the same partition using multiple consumers or write to a single partition using multiple producers.
因此, 只要我们 生产一个分区并从一个分区消费, Kafka保证就成立,一旦我们使用多个使用者从同一个分区读取或使用多个生产者写入单个分区,Kafka保证便会失效。
Q. But what will I get if I pay this cost?A. Data consistency and availability 🚀
问:但是如果我支付这笔费用,我会得到什么? A.数据一致性和可用性🚀
How?
怎么样?
- Messages sent to a topic partition will be appended to the commit log in the order they are sent. 发送到主题分区的消息将按照发送顺序追加到提交日志中。
- A single consumer instance will see messages in the order they appear in the log. 单个使用者实例将按照消息在日志中出现的顺序查看消息。
- A message is ‘committed’ when all in-sync replicas have applied it to their log. 所有同步副本都将消息“提交”时,会将其应用于日志。
- Any committed message will not be lost, as long as at least one in sync replica is alive. 只要至少有一个同步副本处于活动状态,任何提交的消息都不会丢失。

使用Kafka我们可以实现什么? (What can we achieve using Kafka?)
Using Kafka in our architecture provides a high level of parallelism and decoupling between data producers and their consumers. In a Microservice pattern, this comes very handy when we want to trigger some other flow with an event happening somewhere else.
在我们的体系结构中使用Kafka可以在数据生产者及其使用者之间提供高度的并行性和去耦性。 在微服务模式中,当我们想触发其他事件发生在其他地方的流程时,这非常方便。
Wait! but this can also be achieved using some rest APIs and async calls 😕. So why do I bother to learn something new? I had the same question so I thought of researching a little more about this and these are my findings.
等待! 但这也可以使用一些其他API和异步调用来实现。 那么,为什么我要去学习新的东西呢? 我有同样的问题,所以我想对此进行更多研究,这是我的发现。
Also committing to a Kafka topic is much faster than executing an API call which writes to a database, hence is we have a pipeline to process the data which is being produced choosing Kafka over REST is better, but if we have a user waiting for the response after the data is being consumed REST is best.
与执行写入数据库的API调用相比,提交Kafka主题的速度要快得多,因此,我们是否拥有一条管道来处理正在生成的数据,因此选择REST上的Kafka会更好,但是如果我们有一个用户在等待数据被消耗后的响应最好是REST。
Hope this article was able to develop a better understanding of Kafka and also its use case, will be soon writing the next blog about how to set up a Kafka system in some of the frequently used programming languages 😀. Feel free to put your thoughts or corrections about this article it will surely help me to write better next time.
希望本文能够对Kafka及其用例有更好的理解,并将很快撰写下一个博客,介绍如何使用某些常用的编程语言来设置Kafka系统blog。 请随意发表您对本文的想法或更正,这肯定会帮助我下次写得更好。
一些不错的读物帮助我撰写了此博客 (Some good reads which helped me write this blog)
https://kafka.apache.org/intro
https://kafka.apache.org/intro
https://sookocheff.com/post/kafka/kafka-in-a-nutshell/
https://sookocheff.com/post/kafka/kafka-in-a-nutshell/
https://medium.com/@durgaswaroop/a-practical-introduction-to-kafka-storage-internals-d5b544f6925f
https://medium.com/@durgaswaroop/a-practical-introduction-to-kafka-storage-internals-d5b544f6925f
https://stackoverflow.com/questions/57852689/kafka-msg-vs-rest-calls
https://stackoverflow.com/questions/57852689/kafka-msg-vs-rest-calls
翻译自: https://medium.com/@jenishjain6/laymans-guide-to-kafka-203089f1dbd0
卡夫卡详解
相关文章:
这篇关于卡夫卡详解_外行卡夫卡指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






