本文主要是介绍Word2Vec-------skip-gram跳字模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.什么是Skip-gram算法
Skip-gram算法就是在给出目标单词(中心单词)的情况下,预测它的上下文单词(除中心单词外窗口内的其他单词,这里的窗口大小是2,也就是左右各两个单词)
如下图

图中love是目标单词,其他事上下文单词,分别对其上下文中出现的概率进行预测,p(you|love),p(do|love),p(),等等
2.定义
在这里设定一些定义
d : 为词向量的维度,如[0.3,0.4,0.5,0.6] 用这一词向量来表示单词
v: 词汇表中的单词数,即词汇表维度
vc: 该目标单词 的词向量
vx: 目标单词外的第x个单词的词向量
W: dv 表示目标单词的矩阵
wc:one-hot向量
W’: vd表示其他单词的矩阵,是W的转置矩阵
vx*vc: 目标单词与第x单词的相似度,注意vx要转置,最终结果为一个数
vc= W*wc 首先从目标词矩阵中用onehot向量将目标词的词向量提取出来
之后通过vc与其他单词的词向量转置组成的其他单词举证相乘,得到目标单词与其他单词的相关性向量,即点积,值越大,目标词与该单词的相关性越高

之后得到的相似度向量传入softmax公式,就得到了一个满足概率分布的矩阵。
需要注意的是随着词典规模的扩大,这一部分的分母计算量非常的大
由于此时是有关于单词的上下文信息的,为了训练单词之间的相关性,我们的目标变为极大化概率P ( w o ∣ w c ) ,在不影响单调性的情况下,采用对数似然来计算(取对数),并对目标函数进行单调性转换,即-logP ( w o ∣ w c ),即可用梯度下降法,来不断更新词嵌入表示的向量值,随着不断训练,单词之间的关联性将会不断地增强
3.模型特点:
相比于之前用onehot这一稀疏向量来表示单词,这一模型趋向于通过编码,来使用一个稠密的向量去表示一个单词,并且这个单词是可以在空间中表征准确含义的。比如,“man”和“woman”在空间中就应该是距离比较近的,这一映射过程被称作嵌入,因为是单词的映射,所以被叫做词嵌入(word embedding),稠密向量中的值也是需要通过不断训练,来不断更新的
这里存在几个问题:
一个是在词典中所有的词都有机会被当做是“中心词”和“背景词”,那么在更新的时候,都会被更新一遍,这种时候该怎么确定一个词的向量到底该怎么选择呢?在自然语言处理应用中,一般使用跳字模型的中心词向量作为词的表征向量。
另一个问题就比较验证了,从刚刚最终的梯度公式中,存在着一个参数V,我们知道这个参数代表的含义是词典中单词的个数,通常这个个数会非常大,这时候我们在进行迭代的时候对系统消耗也是巨大的,因为每走一步就要对所有的单词进行一次矩阵运算。这种时候该如何进行优化呢?
负采样:每次只采少量的负label,即label为0的一些其他单词,而不是在窗口中的单词,只要挑选k个,不需要计算单词表中全部的V,考虑到频数比较少的单词出现概率,以及削弱高频词的影响,采样时对数据去0.75次方
层级softmax:
接下来重点来说明下hierachical softmax的原理以及怎么训练hierachical softmax网络模型
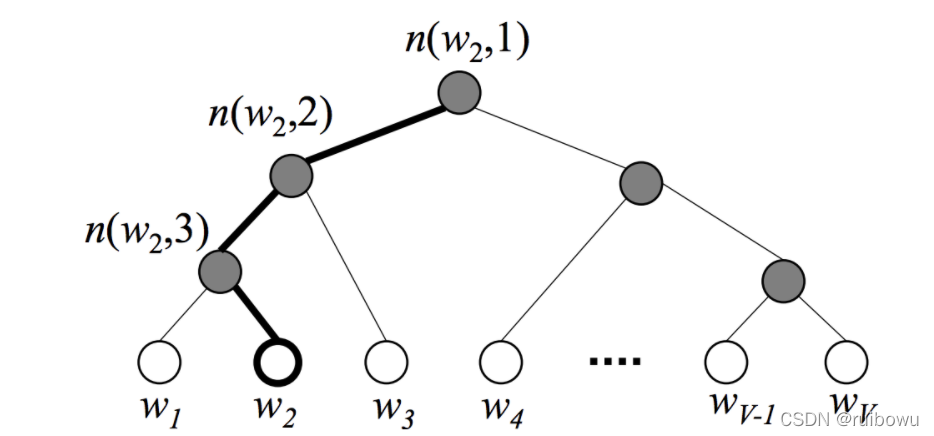
首先对所有在V 词表的词,根据词频来构建二叉树,词频越大,路径越短,编码信息更少。tree中的所有的叶子节点构成了词V ,中间节点则共有V-1个,上面的每个叶子节点存在唯一的从根到该节点的path,如上图所示, 词w 2 的path n ( w 2 , 1 ) , n ( w 2 , 2 ) , n ( w 3 , 3 )其中n ( w , j ) 表示词w 的path的第j 个节点。经过左节点时为正,经过右节点时为负
每个词的概率公式可以表示为
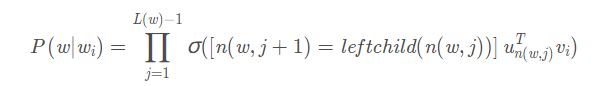
如此看来,这种方法的复杂度就是二叉树的高度,也就是O(logV)。相比于原来的逐个计算O(V),在词表量较大的情况下,确实有很大改进
模型也存在一定的缺点:
由于词和向量是一对一的关系,所以多义词的问题无法解决。
而且是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化
词的前后关系无法确认,比如 the dog is strong这句中,p(the|dog)与 p(dog|the)的概率是几乎相同的,但是并不能表示词在句中的位置。
参考:
https://zhuanlan.zhihu.com/p/27234078
https://zhuanlan.zhihu.com/p/29305464
这篇关于Word2Vec-------skip-gram跳字模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








