本文主要是介绍基于优衣库(Uniqlo)业务场景的数据仓库与数据挖掘课程设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.引言
1.1 编写目的
1.2 背景
2.可行性分析
2.1对现有系统的分析
2.2技术可行性分析
2.3 经济可行性分析
2.4 社会因素可行性分析
3.需求分析
4.总体设计
4.1使用Power BI工具对源数据进行可视化展现
4.2使用kettle-ETL等工具对源数据预处理
4.3数据库-虚拟机-mysql对字段信息的修改,以及简单统计查询
4.4利用python强大的第三方库绘图做数据分析
4.5 使用IBM-SPSS工具,引用相关算法建立模型进行数据分析与挖掘。
5.详细设计
5.1PowerBI可视化
5.2 Kettle、Mysql数据迁移与预处理
5.3Python数据分析
5.4 IBM相关算法建模进行相关分析
6.系统调试
6.1IBM SPSS Modeler贝叶斯关联分析
6.2IBM SPSS Modeler K-Means聚类算法
6.3IBM SPSS Modeler C5.0决策树
参考文献
附录
附录1
附录2
1.引言
商业智能(BI)概念由Gartner Group提出,涉及信息搜索、管理和分析,目的是使企业决策者获得知识,促使他们做出对企业更加有力的决策。商业智能不是一种独立的技术,而是一套完整的解决方案。它将数据仓库,联机分析(OLAP),数据挖掘和可视化等技术结合应用于业务活动,使企业的复杂信息转化为可供辅助的知识,最后将知识呈现给用户,以支持企业决策。随着Internet应用程序规模的不断扩大,需要处理的数据量呈指数级增长,数据结构变得越来越复杂。业务运营压力急剧 增大,从而直接推动了大数据处理技术的发展。随着电子商务、云计算、移动社交媒体、大数据平台技术等新一代IT技术的快速发展,传统的 BI系统逐渐不能满足企业数据分析的需求。个性化、数据化、科学的数据分析技术逐渐使传统的BI系统需要与大数据技术相结合,实现一种满足大数据分析的新商业智能分析挖掘系统。
1.1 编写目的
为了将大数据与传统商业智能相结合,设计相应的商业智能商业智能分析挖掘系统,将着重探讨数据源预处理、模型建立、数据分析、数据挖掘,以优衣库服装企业电商数据为例,用聚类分析中的K-Means算法、分类分析中的贝叶斯、C5.0决策树等算法对商业业务数据进行分析,以此实现商家做出合理决策进行个性化营销的目的。
关键词: 大数据 商业智能 数据分析 数据挖掘。
1.2 背景
优衣库(英文名称:UNIQLO,日文假名发音:ユニクロ),为日本迅销公司的核心品牌,建立于1984年,当年是一家销售西服的小服装店,现在已经是家喻户晓的品牌。价廉物美的休闲装“UNIQLO”是Unique Clothing Warehouse的缩写,意为消费者提供“低价良品、品质保证”的经营理念,在日本经济低迷时期取得了惊人的业绩。迅销公司名称是FAST RETAILING,这其中包含了很多特别的含义。FAST(迅速)+RETAILING(零售)体现了如何将顾客的要求迅速商品化、如何迅速提供商品这一企业根本精神,也表达了他们期望成为拥有快餐文化这一世界通用理念的零售企业界之不可动摇的信念。
目前零售行业竞争异常激烈,在商场上占有一席之地越来越困难。针对企业销售数据结构混杂、数据利用率低、客户流失 严重、潜力市场寻找困难。
自从我国加入 WTO 世贸组织之后,国外零售集团也加入中国零售行业的竞争,为我国零售行业特别是与国外竞争激烈的个别企业提供一个系统的商业智能解决方案,让企业管理者不仅了解企业销售现状,并且能预测每做出一个决策对销售收入的影响。特此研究与设计一款基于商业智能的新销售商业智能分析挖掘系统。
2.可行性分析
各种信息技术的发展以及普遍运用,给我国各行各业的企业管理带来了全新的转变。尤其是电商业务场景的决策,其由传统的数据统计处理转变为数字型信息化系统处理模式, 而传统的数据挖掘处理方式显得“捉襟见肘”,如何帮助企业在短时间内从大量的数据库中做出最为快速以及科学合理的反应,全面优化企业在决策上的质量水平显得越来越重要。
现有BI数据分析与挖掘软件已经愈加成熟与稳定,并且大多数是开源、免费。正因为如此,对我们的研究提供将会提供一定的协助作用。将BI分析技术有效运用在商业决策上,能够帮助企业的管理层对数据展开更加深入的分析和处理, 使得整体的决策机制变得更加智能化和信息化, 帮助企业实现智能化的管理模式, 给商家提供强有力的数据基础, 帮助各领域的数字型企业及时做出有效决策,有效提高商品变现转化率,进而获得更大的利润空间。
2.1对现有系统的分析
伴随着我国BI产品研发的不断升级 和进步,数据分析与挖掘系统也得到了创新性的发展和突破, 使得系统的可持续性有了更加强大的技术保障。 现阶段在国外具备代表性的产品有 IBM(Internet Business Machine, 互 联 网 商 业 机 器 )、MicroSoft(微软)等。国内的主要产品有Smartbi(思迈特)、浪潮 BA、金蝶KBI等。国外一些BI产品其主要的价值和优势在于数据仓库行业模型和解决方案上,相比国内的BI产品更加优化。 但是由于国外BI 产品在国内的本地化应用程度不足,培训周期相对来说较长,同时费用比较高,给我国 BI 产品提供了更加充足和广泛的发展空间,尤其是在BI产品本地化操作习惯、 使用复杂程度和使用便捷程度等方向上,国内的BI产品更是实了创新性的突破。 同时在 BI分析技术发展的过程中呈现出了逐渐壮大的趋势。
2.1.1市场调研
我国的一些 BI 产品经过多年的发展和进步,现阶段已经逐渐发展到了产品化和商业化的阶段,个别的BI产品已经发展得较为成熟。在国内已经得到了 相关客户的普遍使用,并在使用之后获得了使用验证, 在与国际 BI 产品的竞争过程中也频频获得优势。我国的 IT(Internet Technology,互联网技术)技术发展程度基本上已经保持在国际水平,现阶段国内的BI 产品 也一直紧跟国际的标准技术要求,甚至在整个互联网领域中,我国的 IT技术处于较为领先的发展地位。包括国外的数据分析相关软件的发展愈加成熟稳定。
2.1.2技术难度
本次实验使用到的比如IBMSPSS、Python、kettle、mysql、PowerBI等一系列工具都是平时学习并掌握或者了解过的,所以从技术难度分析来看,难度大小适中,符合当下的学习掌握要求。
2.2技术可行性分析
现阶段国内外有很多开源、开放、稳定的数据预处理、数据存储、数据分析与挖掘等相关软件与使用文档说明供我们选择。比如:IBMSPSS软件为我们提供了大量的数据分析算法,例如:IBMSPSS modelerclient中的贝叶斯关联算法、K-Means聚类算法、C5.0决策树等;Python强大的第三方库等等为我们的研究与挖掘提供了不可计量的帮助。而且随着短视频、相关网站和论坛的发展,网上不难就可以找到相关参考内容。这都为我们的技术支持提供了一定帮助,所以此实验具备一定的技术可行性。
2.3 经济可行性分析
基于本次实验用到的各种分析挖掘相关软件或者实验中遇到的各种技术难点基本都可以到网上或者咨询老师免费的寻找到相关的解决的方案。此次实验对经济的要求比较低,具备有一定的经济可行性。
2.4 社会因素可行性分析
随着社会经济、互联网技术的发展,我国消费者对于休闲时尚越来越强烈追求,使休闲服装在国内服装市场备受推装的款式更趋国际化,种类更趋多样化,消费更趋品牌化、个性化。顾客对消费体验的要求也变得越来越高。对于商家基于电商业务场景的业务决策也变得愈加重要,所以此次实验内容大概会受到社会的认可与支持。对于社会因素来说具备有一定可行性。
3.需求分析
3.1、源数据可视化展现(PowerBi-BI工具)
3.2、数据预处理(Kettle-ETL工具)
3.3模型结构的建立与分析(Python、IBM SPSS Modeler)
3.4.1销售额时间序列变化、购买渠道(Python第三方库及相关函数)
3.4.2不同城市、产品、时间,顾客偏爱的购买方式(贝叶斯关联分析)
3.4.3产品、城市、消费等级、订单数的聚类分析(K-Means算法)
3.4.4顾客年收入、消费等级、产品、接受价格等级之间的树形结构分析与决策
(C5.0决策树分析算法)
4.总体设计
4.1使用Power BI工具对源数据进行可视化展现
将源数据导入PowerBI做可视化分析,了解掌握元数据,并大概挖掘出一定的规律性。
Power-BI绿色开发平台是一个平台性产品,通过数据视图管理、数据转换管理、OLAP数据库管理、多维报表设计、即席报表设计等一系列功能,可快速帮助企业IT人员在现有ERP/CRM等信息系统基础之上,构建多维分析模型,制作即席报表、制作分析报告,发布管理驾驶舱等BI的应用。
4.2使用kettle-ETL等工具对源数据预处理
将源数据进行筛选、过滤、清除异常值,转换文件类型并将表数据迁移到数据库。
4.3数据库-虚拟机-mysql对字段信息的修改,以及简单统计查询
进入虚拟机中数据库,进行相关的增删查改操作。
4.4利用python强大的第三方库绘图做数据分析
导入数据,利用Python的相关函数以及第三方强大的库绘制图标并做相关分析。
4.5 使用IBM-SPSS工具,引用相关算法建立模型进行数据分析与挖掘。
利用贝叶斯关联算法、K-Means聚类算法、C5.0决策树等算法建立模型并进一步做数据分析。
5.详细设计
5.1PowerBI可视化
使用PowerBI可视化工具导入uniqlo表格信息进行可视化,如图5-1,5-2所示:
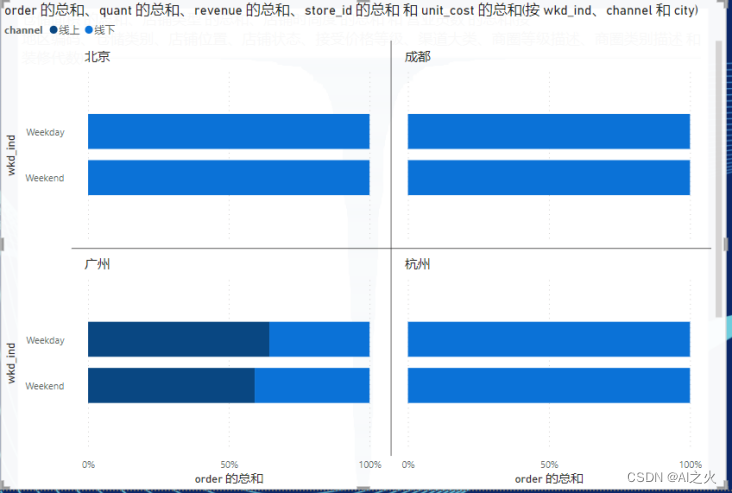
顾客行为柱状图可视化:图5-1
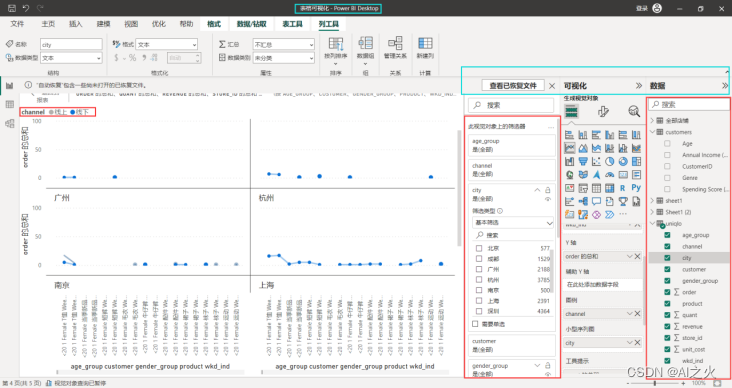
顾客行为散点图可视化:图5-2
5.2 Kettle、Mysql数据迁移与预处理
将csv文件内容转换、迁移到mysql数据库表中,如图5-3所示: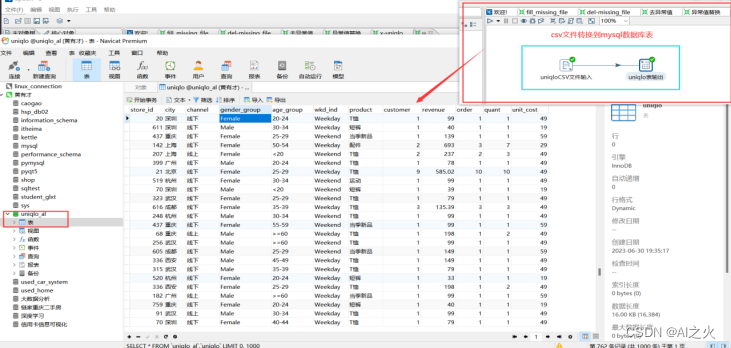
 数据转换、迁移结果图:图5-3
数据转换、迁移结果图:图5-3
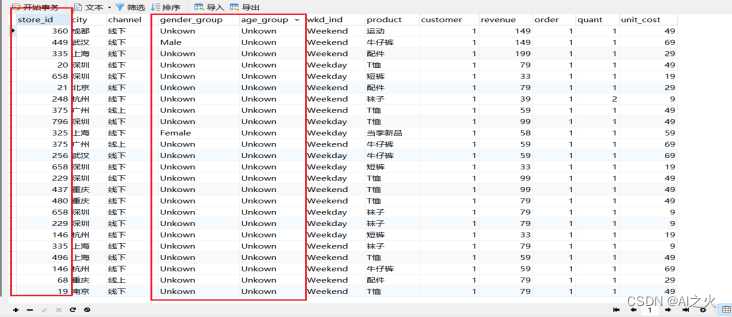
数据处理——筛选、过滤年龄、产品等字段如图5-5

图5-5
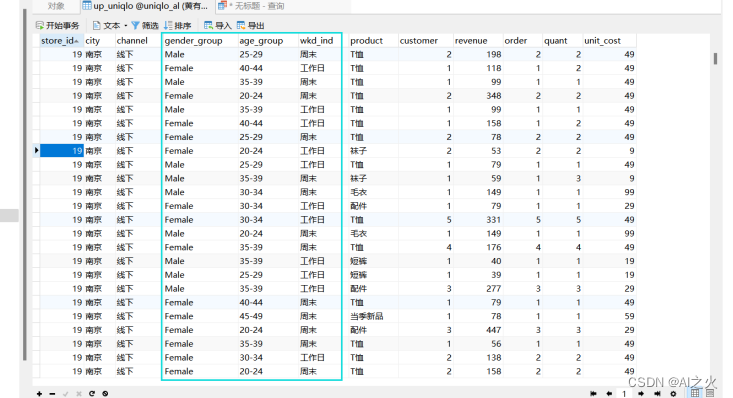
图5-6
order为关键字字段,无法正常使用order字段查询,所以另行修改字段名为order_1,
如图5-7所示:
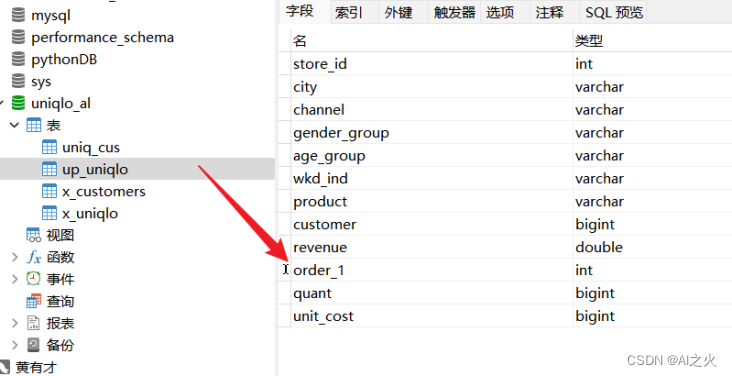 图5-7
图5-7
Uniqlo表信息统计与简单查询:如图5-8所示:

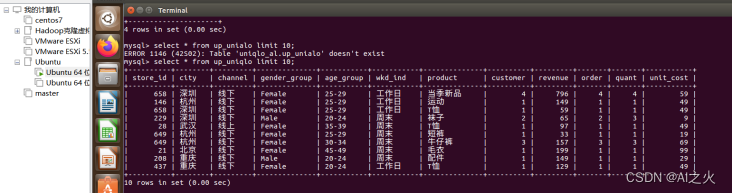

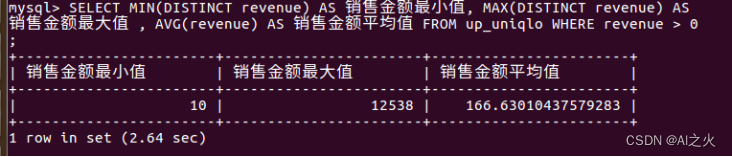
查询结果图5-8
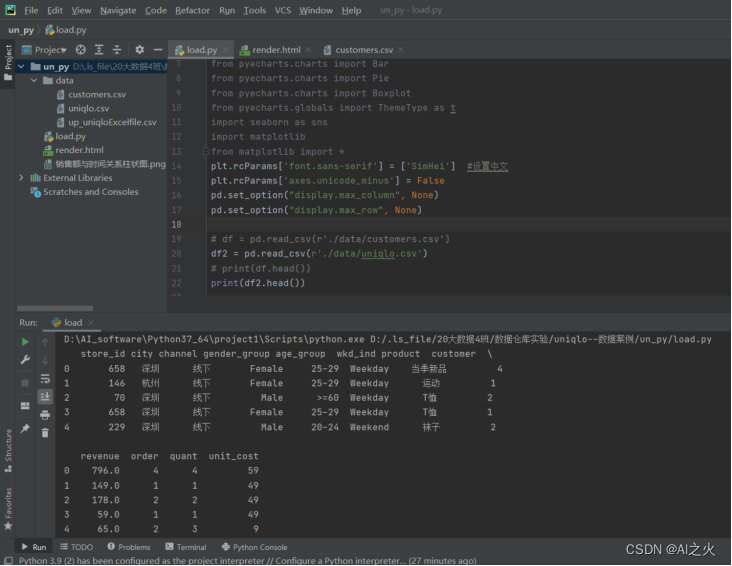
5.3Python数据分析:
Python导入文件数据,并显示前五行数据如图5-9所示:
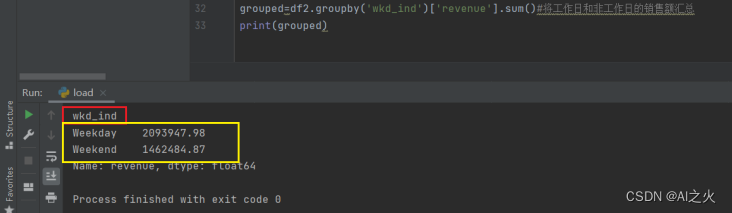 工作日与非工作日购买量统计图5-10
工作日与非工作日购买量统计图5-10

可视化销售额随时间序列的变化情况图5-11
基于现有数据的统计结果不难预测出:未来一段时间工作日整体的销售额会比非正常日高。
统计检查不同城市顾客不同渠道的购买情况是否有异常并进行分析:如图5-12所示:
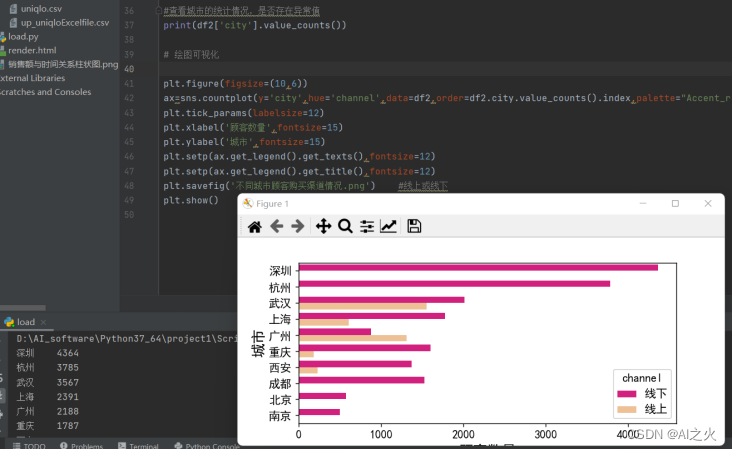
图5-12
从可视化出来的结果图可以看出顾客更倾向于线下购买,尤其是深圳、杭州等城市。企业预想借助互联网+的趋势,可以试着加大对武汉、上海、广州的投入、研究。
5.4 IBM相关算法建模进行相关分析
5.4.1贝叶斯关联分析算法
朴素贝叶斯分类算法作为机器学习最经典的算法之一,该算法是一种有监督学习算法。其理论基础是“贝叶斯定理”,该原理是由英国著名数学家托马斯·贝叶斯提出,贝叶斯定理是基于统计学和概率论相关知识实现的。贝叶斯分类算法有着极其广泛的用途,例如广泛应用于情感分类,文本分类等分类任务。
贝叶斯模型的建立如图5.4.1-1:
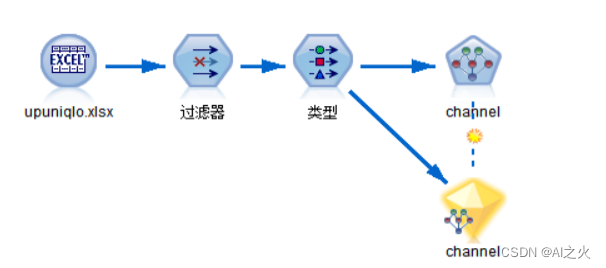
图5.4.1-1
导入数据并进行预览如图5.4.1-2所示:

图5.4.1-2
注意:文件命名不能出现下划线_格式,或者无法正常读取。
字段选取如图5.4.1-3:
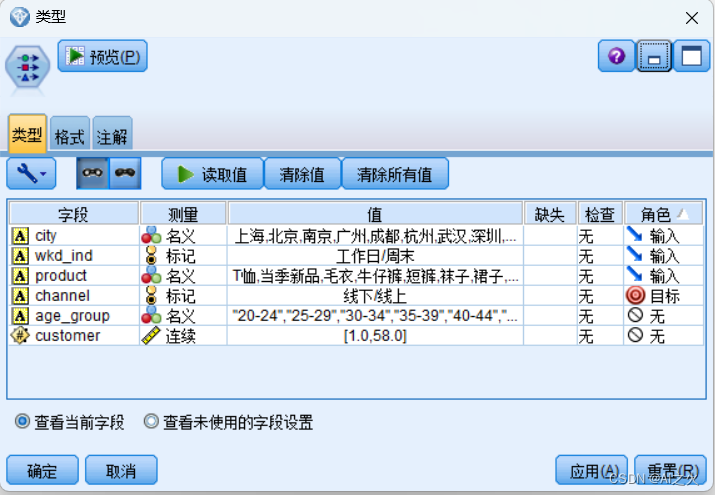
图5.4.1-3
5.4.2K-Means聚类算法
- Means聚类算法是一种常用的无监督学习算法,可以将数据集分成k个不同的簇。该算法通过迭代的方式不断调整簇的中心点,直到达到最优的聚类效果。
建立模型之前将多个表数据进行过滤、等级划分并合并;过滤uniqlo字段信息并将商家收入进行等级划分如图5.4.2-1:
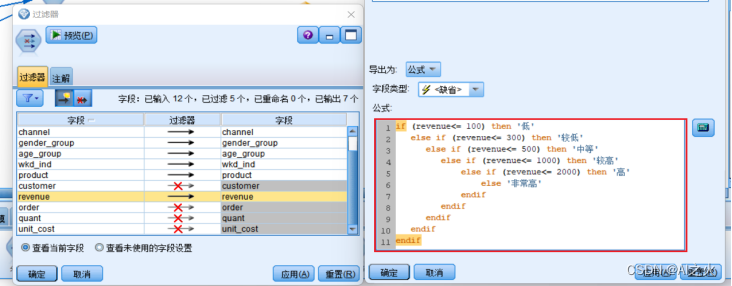
图5.4.2-1
修改字段格式:如图5.4.2-2
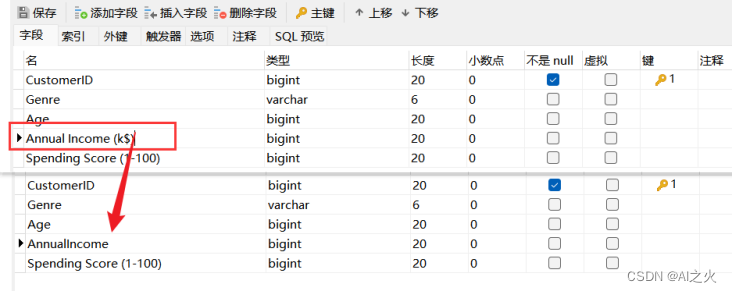 图5.4.2-2
图5.4.2-2
将顾客年收入等级划分如图5.4.2-3
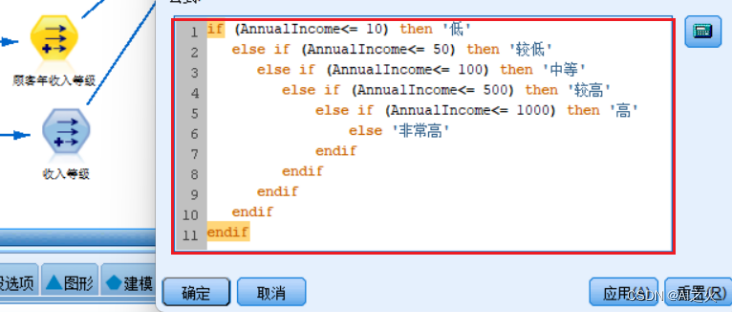
图5.4.2-3
利用画板选择相关字段进行可视化如图5.4.2-4:
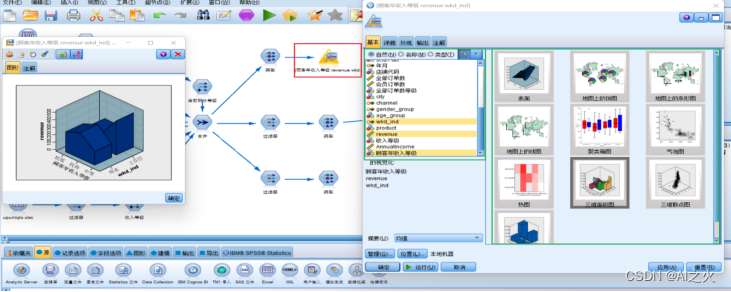
图5.4.2-4
K-Means聚类算法结构模型建立:
 K-Means模型5.4.2-5
K-Means模型5.4.2-5
分析字段选取如图5.4.2-6所示:
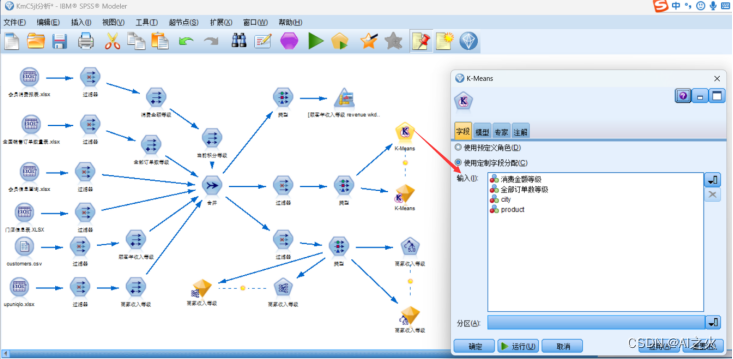
图5.4.2-6
注意这里选择字段做关联分析算法不能选择连续性字段数据。
5.4.3.C5.0决策树
SPSS Modeler决策树 C5.0是一种基于数据挖掘技术的分类算法,它可以通过对数据集进行分析和学习,自动构建出一棵决策树模型,用于预测未知数据的分类结果。C5.0算法具有高效、准确、可解释性强等特点,被广泛应用于商业、金融、医疗等领域的数据分析和决策支持。
C5.0决策树模型建立如图5.4.3-1所示:
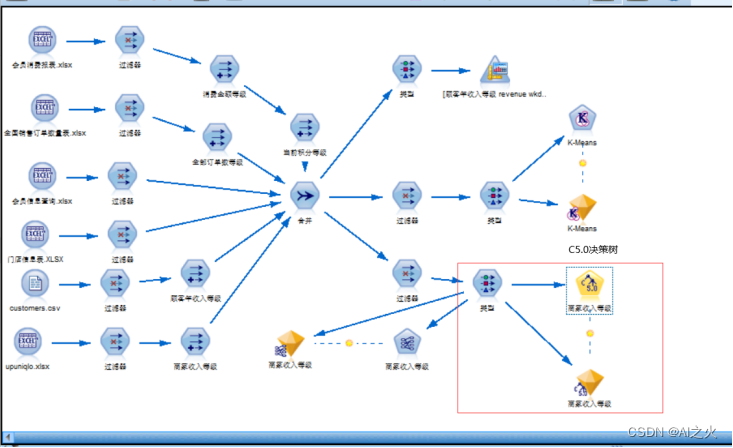
图5.4.3-1
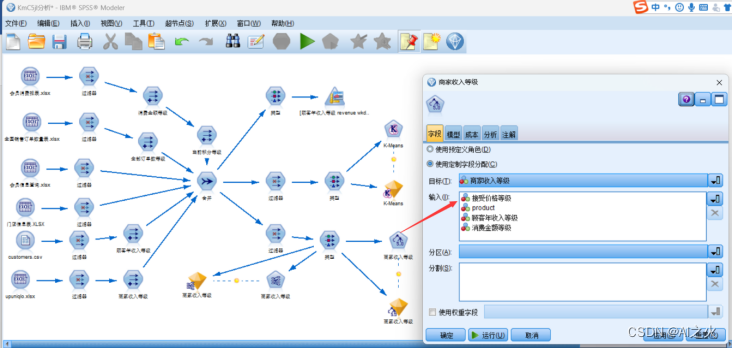
字段选取图5.4.3-2
6.系统调试
6.1IBM SPSS Modeler贝叶斯关联分析:
预测变量重要性图6.1-1:
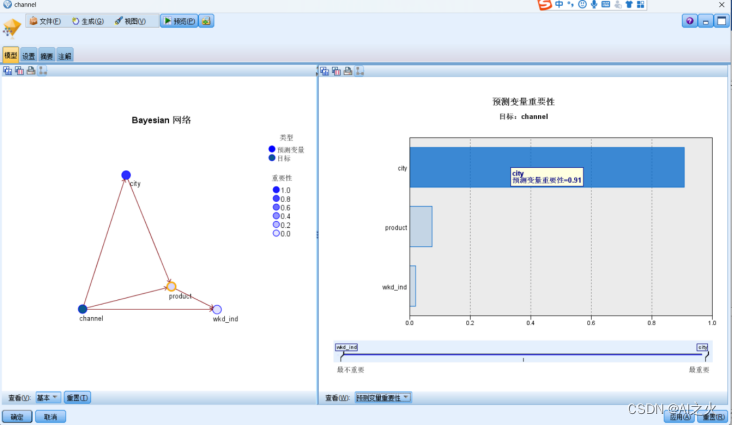
从分析结果图来看:预测变量对购买渠道影响最大的字段为城市。
对城市做相关条件概率分析如图6.1-2:
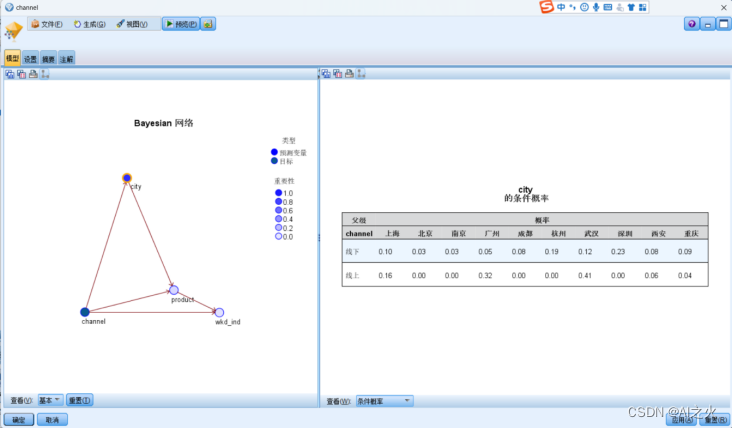
经研究发现:广州、武汉等城市更偏向于线上改名;
上海、杭州、深圳等城市购买方式偏向于线下。
产品关联分析图6.1-3:
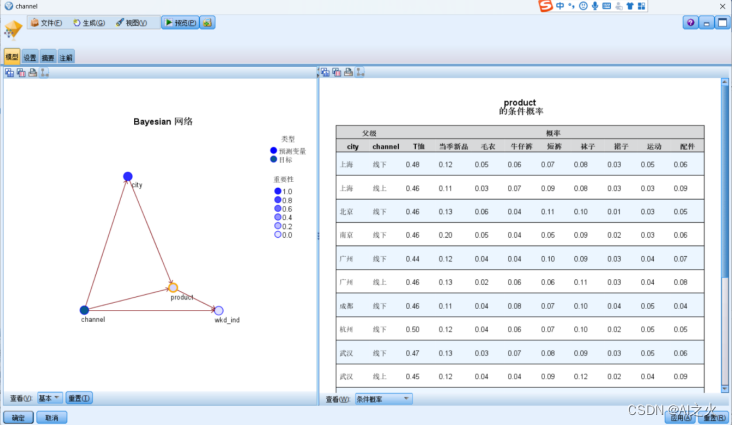
无论那个城市不管是线上还是线下顾客更偏向于购买T恤。
购买时间关联分析图6.1-4:

线下购买牛仔裤的顾客更偏向于选择在工作日购买。
6.2IBM SPSS Modeler K-Means聚类算法:
聚类大小如图6.2-1所示:
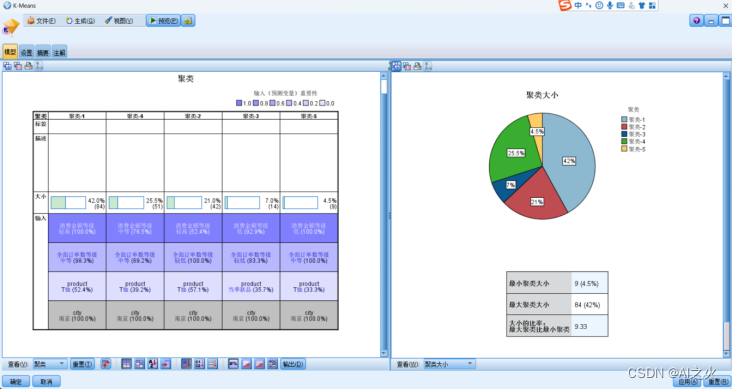
图6.2-1
从分析结果来看聚类一的占比更大。
聚类单元格分布图:6.2-2:
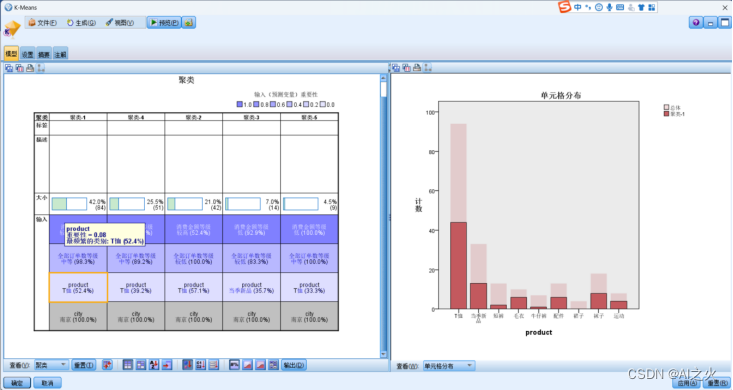
从分析结果来看:在南京顾客消费金额以及全部订单数为中等的情况下,购买T恤的顾客相比于其他会更高。因此可以选择加到T恤的投入。
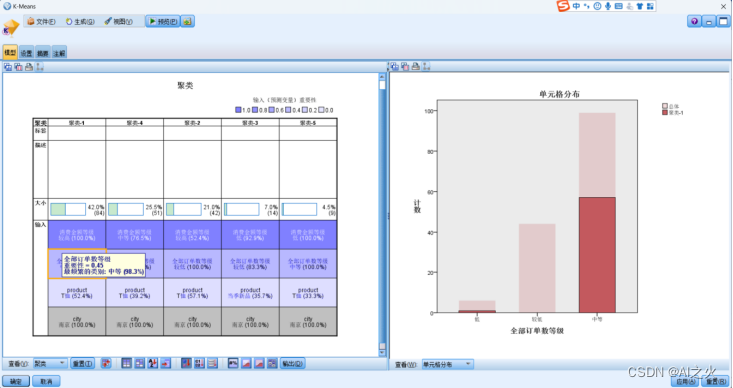
在南京消费金额为中等并且有一半选择T恤的人他们一般会订比较多的单。
6.3IBM SPSS Modeler C5.0决策树:
决策树模型与查看器结果图如下6.3-1:
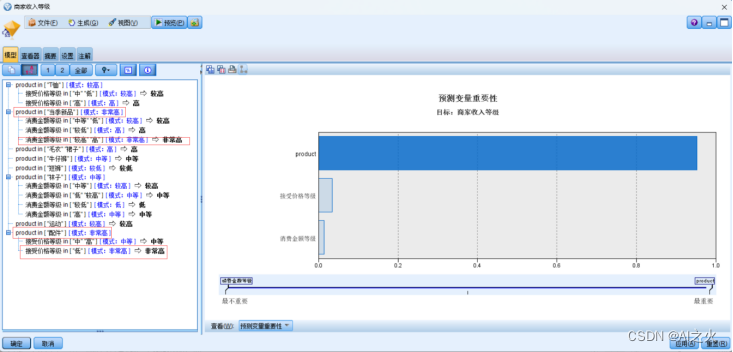
图6.3-1
从分析结果来看:
产品为当季产品的模式非常高,顾客消费金额中等偏上;可以看出大多数顾客更中意于当季产品。因此针对于进货我们应该与时俱进、跟进季节的变化随时进货,对于过季产品,我们可以采取的营销模式进行售卖;
产品为配件的模式也非常高,顾客的销售等级为中下,可以看出顾客更看重价格以及性价比,因此针对于此类产品我们可以考虑选取薄利多销的模型,实现长期合作共赢。
在大数据的背景下,充分利用数据挖掘信息可以抓住市场机遇。众多企业除了线下实体销售外也开展了具有独特优势的线上交易,从电商大数据中挖掘隐藏的信息,根据这些信息,针对不同的客户群体进行个性化营销,从而提高企业的客户满意度和经济效益。本文主要研究了大数据与传统商业智能在电商企业(优衣库电商网站)数据分析中的应用,重点描述关联分析的贝叶斯算法、聚类分析的K- Means算法等并应用于uniqlo电子商务网站中客户消费数据的挖掘。通过关联、聚类决策分析将数据进行分析与挖掘,根据不同客户群体的特征有助于企业识别客户,并及时做出合理决策布局,从而实现差异化的营销目标。
参考文献
[1]旭辉,电子商务环境下顾客价值的提升[J],商场现代化,2007(7):117-118。
[2]王丹梅,侯清涵基于大数据技术的 BI 分析系统在财务管理方面的应用[J],国际商务财会,2020(07):3-6。
[3]李玉华,侯彦波,商业智能技术在企业财务管理的应用探讨[J],商业时代,2021。
[4]国才,杨金民K-Means算法在电信CRM客户分类中的应用[J],计算机系统应用,2010。
[5]张存芬,杨路明,陈媛电子商务下顾客价值提升途径研究[J],商场现代化,2006。
附录
附录1
Python可视化分析:#导入包import pandas as pdimport numpy as npimport randomfrom matplotlib import pyplot as pltfrom pyecharts import options as optsfrom pyecharts.charts import Barfrom pyecharts.charts import Piefrom pyecharts.charts import Boxplotfrom pyecharts.globals import ThemeType as timport seaborn as snsimport matplotlibfrom matplotlib import *plt.rcParams['font.sans-serif'] = ['SimHei'] #设置中文plt.rcParams['axes.unicode_minus'] = Falsepd.set_option("display.max_column", None)pd.set_option("display.max_row", None)# df = pd.read_csv(r'./data/customers.csv')df2 = pd.read_csv(r'./data/uniqlo.csv')# print(df.head())# print(df2.head())#画图# sns.barplot(x='wkd_ind',y='revenue',data=df2,palette="ocean")#调色板# plt.tick_params(labelsize=10)# plt.xlabel("wkd_ind",fontsize=15)# plt.ylabel("revenue",fontsize=15)# plt.savefig('销售额与时间关系柱状图.png')# plt.show()# grouped=df2.groupby('wkd_ind')['revenue'].sum()#将工作日和非工作日的销售额汇总# print(grouped)#查看城市的统计情况,是否存在异常值print(df2['city'].value_counts())# 绘图可视化plt.figure(figsize=(10,6))ax=sns.countplot(y='city',hue='channel',data=df2,order=df2.city.value_counts().index,palette="Accent_r")plt.tick_params(labelsize=12)plt.xlabel('顾客数量',fontsize=15)plt.ylabel('城市',fontsize=15)plt.setp(ax.get_legend().get_texts(),fontsize=12)plt.setp(ax.get_legend().get_title(),fontsize=12)plt.savefig('不同城市顾客购买渠道情况.png') #线上或线下plt.show()附录2
IBM-SPSS:消费等级划分:if (消费金额<= 100) then '低'else if (消费金额<= 500) then '较低'else if (消费金额<= 1000) then '中等'else if (消费金额<= 2000) then '较高'else if (消费金额<= 5000) then '高'else '非常高'endifendifendifendifendif全部订单数等级划分:if (全部订单数<= 50) then '低'else if (全部订单数<= 100) then '较低'else if (全部订单数<= 200) then '中等'else if (全部订单数<= 300) then '较高'else if (全部订单数<= 500) then '高'else '非常高'endifendifendifendifendif顾客年收入等级划分:if (AnnualIncome<= 10) then '低'else if (AnnualIncome<= 50) then '较低'else if (AnnualIncome<= 100) then '中等'else if (AnnualIncome<= 500) then '较高'else if (AnnualIncome<= 1000) then '高'else '非常高'endifendifendifendifendif商家收入等级划分:if (revenue<= 30) then '低'else if (revenue<= 50) then '较低'else if (revenue<= 70) then '中等'else if (revenue<= 100) then '较高'else if (revenue<= 200) then '高'else '非常高'endifendifendifendifendif这篇关于基于优衣库(Uniqlo)业务场景的数据仓库与数据挖掘课程设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




