本文主要是介绍【视觉大模型SAM系列】PerSAM:Personalize Segment Anything Model with One Shot,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【版权声明】
本文为博主原创文章,未经博主允许严禁转载,我们会定期进行侵权检索。
更多算法总结请关注我的博客:https://blog.csdn.net/suiyingy,或”乐乐感知学堂“公众号。
本文章来自于专栏《大模型》的系列文章,专栏地址为:https://blog.csdn.net/suiyingy/category_12473256.html。
PerSAM是基于SAM(Segment Anything Model)进行改进的模型,并且实现OneShot功能。SAM一般需要人工选择先验的提示词,包括点、矩形框box和分割mask,并根据提示词分割出目标。PerSAM采用一张参考图片的目标(OneShot)来自动选择前景点和背景点,并作为SAM的提示词,而不需要手动选择。针对目标可能存在歧义的部分,PerSAM-F通过训练两个权重参数来对SAM输出的3组mask进行加权求和,进而使得分割更加准确。另一方面,PerSAM将第一次预测结果再次经过两次SAM来进行后处理微调。以上3点即为PerSAM模型的核心思想。其论文地址为“https://arxiv.org/abs/2305.03048”。
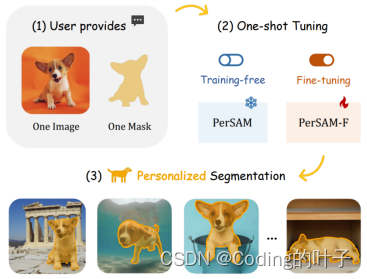
图1 PerSAM模型总体结构
下面将结合PerSAM的程序来分析具体的模型结构。
1 环境安装
PerSAM模型程序的下载地址为“https://github.com/ZrrSkywalker/Personalize-SAM”。Python环境搭建过程如下所示。由于大模型大多比较新,因而考虑到环境的兼容性,我们最好安装比较高版本的Python、CUDA、Pytorch。当前Pytorch安装的是1.13.1版本,很多大模型在2.0版本以上运行速度更快,但是至少需要安装CUDA 11.7。一般情况下CUDA套件的版本不能高于显卡驱动版本,否则可能会带来兼容性问题。
conda create -n persam python=3.10 -y
conda activate persam
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116 #安装pytorch CUDA 11.6
git clone https://ghproxy.com/https://github.com/ZrrSkywalker/Personalize-SAM.git #github代理:https://ghproxy.com/,如果GitHub无法直接连接下载,可采用该方式。
cd Personalize-SAM
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple2 数据下载
2.1 PerSeg.zip
测试数据PerSeg.zip下载地址为“下载地址1:https://drive.google.com/file/d/18TbrwhZtAPY5dlaoEqkPa5h08G9Rjcio/view?usp=sharing”或“下载地址2:https://pan.baidu.com/s/1X-czD-FYW0ELlk2x90eTLg(提取码:222k)”。
解压后包括Annotations和Images两个文件夹,共41组目标语义分割类别。Images存储输入图片,同一类别图片在一个文件夹下,文件夹名称表示类别。Annotations存储图片分割标注,采用图片mask,目标区域像素值为[128, 0, 0],背景为全黑[0, 0, 0]。解压后如下图所示,将data3重命名为data,并放到模型工程目录下即可。
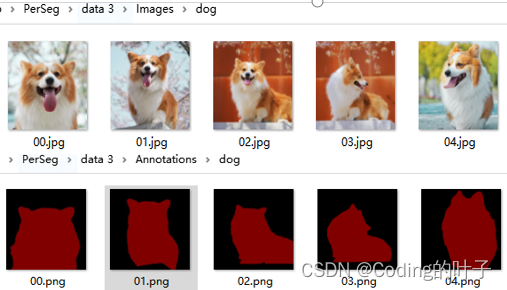
图2 PerSeg示例图片
2.2 训练评估数据DAVIS
数据集下载地址为“https://data.vision.ee.ethz.ch/csergi/share/davis/DAVIS-2017-trainval-480p.zip”。目录结构如下图所示。
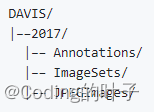
图3 DAVIS目录结构
2.3 SAM预训练模型
SAM预训练模型名称为sam_vit_h_4b8939.pth,下载地址为“https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth”。
3 SAM输入
SAM论文地址为“https://arxiv.org/abs/2304.02643”,模型的整体结构如下图所示。
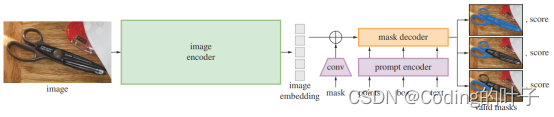
图4 SAM模型结构
SAM的输入包括图像、分割mask、提示词(点points、矩形框box、文本text)。PerSAM不涉及文本提示词。图像输入尺寸为1024x1024。因此,图像将按照长边缩放到1024,短边则填充至1024像素,另外图像还将根据均值和标准差进行归一化。
图形prompt包括点points和矩形框box两种类型。点由坐标及其标签组成。矩形框由左上和右下两个点组成。点和矩形框相对于语义分割任务来说属于一种稀疏表示方法,这是因为分割需要对每个点进行区分,若干个点相对于全部点来说是稀疏的。换句话说,点和矩形框是分割结果的近似表示形式。程序中点和矩形框进行特征变换,成为256维特征embedding。程序中定义为稀疏特征sparse_embedding。该特征维度为bxkx256,b表示batch size,以下将设置为1,k与点数和矩形框数量相关,256为特征维度)。由于矩形框由左上和右下两个点组成,每个点有一个embedding,因此一个矩形框有两个embedding,即1x2x256。算法会设置一个空白的无效sparse_embedding(1x256)用于表示没有输入矩形框prompt的情况。
相比而言,mask是对区域进行分割标记,维度与图像特征相同,因而是稠密的。程序中定义为稠密特征dense_embedding(1x256x64x64,64为特征图尺寸)。在后续transformer变换过程中,该特征会与图像特征进行叠加。在没有mask输入时,程序也会设置一个无mask输入时的dense_embedding(1x256x64x64,no_mask_embedding)。
图像经过特征提取模块image encoder之后的图像特征image_embedding维度为1x256x64x64,即1x4096x256,并且与mask的特征dense_embedding进行叠加。与此同时,模型会也会对各个像素位置进行特征编码,image_pe,1x256x64x64。位置编码属于transformer的常规操作。
4 transformer
SAM的核心结构为transformer,而transformer的关键参数为Q(query)、K(key)、V(value)。Q可认为是我们要查询的结果或问题表述或提示信息,例如语义分割mask、mask的质量分 数、提示词embedding等。我们需要通过注意力计算出其对应的特征属性,一般是V的叠加。特征属性本质上来源于图像。因此,SAM第一个transformer的Q(tokens)由mask质量分数(1x1x256)、mask(1x4x256)、sparse_encoding(1x2x256,包含1个点和1个padding)组成,维度为1x7x256。
Transformer根据K对Q的贡献程度来,得到Q各个元素的注意力特征V。通常Q和K会将位置进行关联,包含位置特征,而V则不包含位置特征。可以理解为,位置特征是不变的,不会随着特征变换发生改变,并不需要进行注意力叠加。例如,目标的矩形框位置坐标在特征图的位置实际上是固定的。
QKV注意力的公式如下:
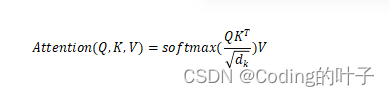
由于每个Q元素会跟所有K计算softmax注意力权重,并将加权求和的结果作为注意力特征,因而其长度与A保持一致。假设Q的维度为BxLQxC,K的维度为BxLKxC,那么输出注意力的特征的维度也为BxLQxC。在多层注意力叠加时,模型会将Q与注意力结果进行一次叠加融合(二者维度完全一致,可直接进行叠加求和),并进行归一化操作。需要特别注意,叠加一般是对特征进行操作,不需要引入位置特征。
5 PerSAM-F模型结构
程序中PerSAM-F的模型结构保持与SAM基本一致,只是对输出的mask做了加权参数优化。结果相比PerSAM更加简洁,因而这里先对其进行介绍。PerSAM-F模型总体过程主要包括相似度计算、SAM注意力特征提取层、解码层和mask权重微调训练三个部分,下面将分别进行详细介绍。
5.1 相似度计算
模型首先根据参考图像mask区域特征采用均值与最大值相结合的方法计算出One-Shot的目标特征,维度为1x256,然后计算该特征与整图每个点特征的余弦相似度,并将相似度最高的作为prompt的输入点,即目标前景点。
因此,SAM的prompt输入为参考图像及其相似度最高的输入点。具体选择过程如下所示。
# Image features encodingref_mask = predictor.set_image(ref_image, ref_mask) # 1x3x1024x1024ref_feat = predictor.features.squeeze().permute(1, 2, 0) # 64x64x256ref_mask = F.interpolate(ref_mask, size=ref_feat.shape[0: 2], mode="bilinear") # 1x3x64x64ref_mask = ref_mask.squeeze()[0] # 64x64# Target feature extractiontarget_feat = ref_feat[ref_mask > 0] # K x 256target_feat_mean = target_feat.mean(0) # 256
target_feat_max = torch.max(target_feat, dim=0)[0] # 256
target_feat = (target_feat_max / 2 + target_feat_mean / 2).unsqueeze(0) # 均值与最大值合并,1x256
# Cosine similarity
h, w, C = ref_feat.shape # 64x64x256
target_feat = target_feat / target_feat.norm(dim=-1, keepdim=True) # 归一化,1x256
ref_feat = ref_feat / ref_feat.norm(dim=-1, keepdim=True)# 归一化,64x64x256
ref_feat = ref_feat.permute(2, 0, 1).reshape(C, h * w) # 256x4096
sim = target_feat @ ref_feat # 1x4096
sim = sim.reshape(1, 1, h, w) # 1x1x64x64
sim = F.interpolate(sim, scale_factor=4, mode="bilinear") # 1x1x256x256
sim = predictor.model.postprocess_masks(sim,input_size=predictor.input_size,original_size=predictor.original_size).squeeze() # 插值回原图尺寸,hxw
# Positive location prior
topk_xy, topk_label = point_selection(sim, topk=1) # 选择相似度最高的像素点坐标,1x2,[1]5.2 SAM注意力特征提取层
SAM注意力特征提取层主要由transformer结构组成,其结构如下图所示。

图5 SAM注意力特征提取层
其结构由两个transformer 结构堆叠组成,可通过深度depth参数来设置堆叠的数量。每一个transformer 结构包含一个自注意力模块和两个交叉注意力模块。最终输出融合后的tokens预测结果hs和图像特征src,二者维度分别为1x7x256和1x4096x256。
5.2.1 第1个transformer
第1组transformer的输入如下:
Q:tokens,1x7x256,包括预测目标和prompt特征。
K:image_embedding,下文用IE表示,1x4096x256,包括图像和mask(dense-embedding)特征。
Q_PE:Prompt位置编码,tokens,1x7x256。
K_PE:图像特征位置编码,image_pe,下文用IE_P表示,1x4096x256。
(1)自注意力
q=k=v=Q,学习tokens特征之间的关联性,输出注意力结果作为新的Q(1x7x256)。注意力的head数量为8,特征为32,QKV全连接为Linear(256, 256),输出全连接为Linear(256, 256),norm层为LayerNorm(256)。
(2)交叉注意力 tokens attending to image embedding
tokens特征中融入图像特征。q= Q + Q_PE,k = K + K_PE,V=K。根据tokens对各个图像像素特征的关注程度,得到新的注意力特征attn_out(1x7x256),该特征进一步与Q进行叠加作为新的Q(1x7x256),从而使得原始tokens中融入图像特征。注意力的head数量为8,特征为16,QKV全连接为Linear(256, 128),输出全连接为Linear(128, 256),norm层为LayerNorm(256)。
(3)MLP
对Q的特征使用全连接层进行融合,全连接层为Linear(256, 2048)和Linear(2048, 256)。
mlp_out = self.mlp(queries) # 1x7x256
queries = queries + mlp_out # 1x7x256
queries = self.norm3(queries) # 1x7x256(4)交叉注意力 image embedding attending to tokens
图像特征中融入tokens特征。q = K + K_PE,k= Q + Q_PE,V=Q。根据各个图像像素特征对tokens的关注程度,得到新的注意力特征attn_out(1x4096x256),该特征进一步与K进行叠加作为新的K(1x4096x256),从而使得图像特征中融入tokens特征。注意力的head数量为8,特征为16,QKV全连接为Linear(256, 128),输出全连接为Linear(128, 256),norm层为LayerNorm(256)。
经过第1个ransformer后,tokens特征融入了图像特征,得到新的Q(1x7x256),图像特征也融入了tokens特征,得到了新的K(1x4096x256)。但是,位置编码是不变的,仍然分别保持为Q_PE和K_PE。
5.2.2 第二个transformer
自注意力过程中由于Q已经融合了新的特征,而不再是由token的位置特征组成,因此q=Q + Q_pe,K=Q + Q_pe,V=Q。
交叉注意力机制和MLP与第一个transformer一致,相当于特征的再次融合。融合后的Q和K的维度仍然分别为1x7x256和1x4096x256。
5.2.3 final attention layer
上面我们分别得到了融合后的Q和K,但是最后两者还未进行关联融合人。因此,这里需要再次计算Q对K注意力结果,并与Q叠加得到新的Q。最终,经过注意力融合后的Q和K的维度仍然分别为1x7x256和1x4096x256,分别对应下面程序的hs和src。
# Run the transformer
hs, src = self.transformer(src, pos_src, tokens, attn_sim, target_embedding) # 1x7x256,1x4096x2565.3 解码层
PerSAM-F的解码层结构如下图所示。
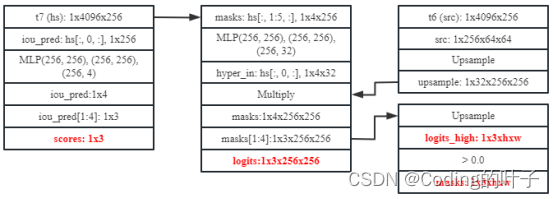
图6 PerSAM-F解码层
hs[:, 0, :]经过3层全连接Linear(256, 256)、Linear(256, 256)和Linear(256, 4)得到mask的质量得分iou_pred(1x4)。
hs[:, 1:5, :]分别经过3层全连接Linear(256, 256)、Linear(256, 256)和Linear(256, 32)得到4组图像特征权重hyper_in(4x32)。
src(1x256x64x64)经过逆卷积上采样操作后得到最终图像特征32x256x256,权重hyper_in(4x32)分别对图像特征进行加权求和得到4组分割masks(1x4x256x256)。
在多mask输出时选择后3个mask为预测结果,那么mask和iou_pred的维度分别为1x3x256x256和1x3。
# Select the correct mask or masks for output
if multimask_output:mask_slice = slice(1, None)
else:mask_slice = slice(0, 1)
masks = masks[:, mask_slice, :, :]
iou_pred = iou_pred[:, mask_slice]
# Prepare output
return masks, iou_pred此时mask的分辨率是256x256,相当于原图的下采样,因而用low_res_masks表示。低分辨率mask经过上采样插值后的高分辨mask(high_res_masks),维度为1x3xhxw。最终有效目标masks是high_res_masks中大于0处的点。
high_res_masks = self.model.postprocess_masks(low_res_masks, self.input_size, self.original_size)#将mask插值到原始图像分辨率,1x3xhxw
masks = high_res_masks > self.model.mask_threshold # 0.0
return masks, iou_predictions, low_res_masks, high_res_masks5.4 mask权重微调训练
mask权重微调训练过程如下图所示。

图7 mask权重微调训练过程
PerSAM-F对high_res_masks中的3组mask进行加权求和得到最终mask,且权重组成为(w1, w2, 1-w1-w2)。可以看到,微调只需学习w1和w2这两个参数。加权得到的mask与真实mask进行损失计算,包括Dice Loss和Foca Loss,这也是两种比较常规的语义分割损失。
6 PerSAM-F推理过程
训练完成之后得到经过优化的后的mask权重参数w1和w2。推理过程包括初步预测和两次后处理过程。
6.1 初步预测
与训练过程一致,采用相似度最高的点与SAM Decoder获取masks、 scores、 logits、 logits_high。masks维度为3xhxw,是high_res_masks大于0的布尔运算结果;scores维度为3,是3组mask的质量得分,即iou_pred;logits维度为3x256x256,即low_res_masks;logits_high维度为3xhxw,即high_res_masks。
logits_high经过加权求和得到预测的mask,并计算mask大于0区域的外接矩形,将该矩形作为初步预测的矩形框box。
6.2 使用SAM后处理微调
模型仍然使用SAM来进行预测,此时prompt不仅包含相似度最大的点,还包括第一步预测的mask的外接矩形框,并且将第一步预测的logits作为mask prompt。因此输入tokens的维度为1x8x256,包括mask质量分数(1x1x256)、mask(1x4x256)、sparse_encoding(1x3x256,包含1个点和1个矩形框)。Decoder再次输出masks、scores、 logits、 logits_high。这次不再使用加权求和的方法来预测结果,而是根据最优的质量得分选择从masks中选择对应的维度的mask,属于常规的SAM预测操作。这里没有使用加权求和的原因在于后处理是独立的,即后处理方法为SAM模型。最优mask仍然对应一个外接矩形。
6.3 再次使用SAM后处理微调
微调过程与上一次完全一致,并且最终输出最优的mask作为预测结果。
best_idx = np.argmax(scores)
final_mask = masks[best_idx] # hxw7 PerSAM
PerSAM与PerSAM-F的区别在于:
- 没有训练微调。
- 增加背景点输入。
- 引入相似度注意力机制。
- 推理阶段输出单mask。
根据图像特征与参考目标的平均特征分别选择相似度最高的点作为前景点(label为1),选择相似度最低的点作为背景点(label为0)。另一方面,模型将图像与参考目标特征的相似度作为注意力的一部分,在Token-to-Image中进行注意力叠加,如下图所示。
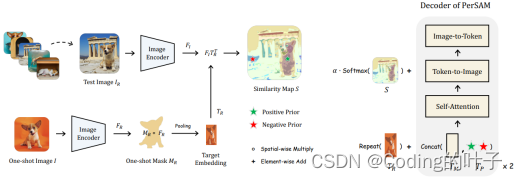
图8 PerSAM模型结构
# Obtain the target guidance for cross-attention layers
sim = (sim - sim.mean()) / torch.std(sim) # 归一化,hxw
sim = F.interpolate(sim.unsqueeze(0).unsqueeze(0), size=(64, 64), mode="bilinear") # 1x1x64x64
attn_sim = sim.sigmoid_().unsqueeze(0).flatten(3) # 转换为0~1概率,相当于每个像素的受关注程度,1x1x1x4096
attn = q @ k.permute(0, 1, 3, 2) # B x N_heads x N_tokens x N_tokens
attn = attn / math.sqrt(c_per_head)
attn = torch.softmax(attn, dim=-1)
if attn_sim is not None:attn = attn + attn_simattn = torch.softmax(attn, dim=-1)在Token-to-Image过程中,每个token会计算与4096个像素之间的注意力权重,而4096个像素特征之间根据相似度注意力也可以得到一个自身的注意权重,二者进行叠加实现了注意力融合。在计算tokens对每个像素点的注意力时,模型会通过Q、K和Softmax得到注意力矩阵,该注意力与相似度注意力attn_sim进行叠加再经过softmax得到新的注意力系数。
PerSAM输入增加负样本点Prompt,因此tokens维度为1x8x256,包括mask质量分数(1x1x256)、mask(1x4x256)、sparse_encoding(1x3x256,包含2个点和1个padding)。
每次进行transformer时Q中增加参考图像特征1x1x256,这相当于查找测试图像中与参考图像特征的相似关系。
输出单个mask(1x1x256x256)预测结果masks[0]及其质量得分iou_pred[0],这说明假设第1个mask是最优的。最终返回masks、 scores、 logits、 logits_high。masks维度为1xhxw,是high_res_masks大于0的布尔运算结果;scores维度为1,是1组mask的质量得分,即iou_pred;logits维度为1x256x256,即low_res_masks;logits_high维度为1xhxw,即high_res_masks。
两次后处理操作与PerSAM-F一样,仅使用原始SAM结构,不再使用相似度注意力。其中第一次微调不输入box矩形框。第一步预测的结果可以认为是mask的初步预测,并作为后处理的mask prompt特征。
8 多目标分割
多目标分割的主要过程如下:
- 使用PerSAM或PerSAM-F预测mask;
- 将原图中mask区域置为黑色;
- 重复以上两步,直到mask数量达到最大数量的限制,或者mask与已有结果IOU重叠较大,达到重叠阈值。
PerSAM和PerSAM-F的具体效果可前往论文查看,也可按照工程进行验证测试。
【版权声明】
本文为博主原创文章,未经博主允许严禁转载,我们会定期进行侵权检索。
更多算法总结请关注我的博客:https://blog.csdn.net/suiyingy,或”乐乐感知学堂“公众号。
本文章来自于专栏《大模型》的系列文章,专栏地址为:https://blog.csdn.net/suiyingy/category_12473256.html。
这篇关于【视觉大模型SAM系列】PerSAM:Personalize Segment Anything Model with One Shot的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







