本文主要是介绍知更鸟语音训练和so-vist训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现在哪还有人读小说、看视频,谁还用真人朗读呢?
现在给大家介绍,假人朗读是怎么来的,提供一些音频,进行训练,然后就能合成属于自己的音频了。这里只讲训练部分,使用请自己看github知更鸟,是来自于实时音频的分支。
GitHub - babysor/MockingBird: 🚀AI拟声: 5秒内克隆您的声音并生成任意语音内容 Clone a voice in 5 seconds to generate arbitrary speech in real-time🚀AI拟声: 5秒内克隆您的声音并生成任意语音内容 Clone a voice in 5 seconds to generate arbitrary speech in real-time - GitHub - babysor/MockingBird: 🚀AI拟声: 5秒内克隆您的声音并生成任意语音内容 Clone a voice in 5 seconds to generate arbitrary speech in real-time![]() https://github.com/babysor/MockingBird
https://github.com/babysor/MockingBird
电脑要求:内存32G(16G跑不起来的),显卡3060(显存8G)
1.环境就直接看github搭建
2.素材,首先准备好,样本素材(声音.wav,声音对应的文字)
b站有好人,不用你去下他对应的数据集格式16G,吓死了。人家直接给的1kb的数据集格式。
https://pan.baidu.com/s/1y9mIvi-Utv8sGt-NaNV_9Q?pwd=8888
MockingBird训练自己的声音 文字转 语音 2023 ai 保姆教程_哔哩哔哩_bilibili
拿了之后直接解压
然后就有这个目录,进入transcript目录
打开,把你音频对应的文本放上去,这是我自己一行一行读的。我想训练自己,话是gpt生成的。
打开qh目录,将音频放进去
3.进行训练
梅尔频谱图预处理
python pre.py 文件根目录 -d 文件夹名称 -n 核数
我创建了一个morckingData,然后把数据文件夹放进去了
执行命令(其实训练就这一句,主要是样本一定要搞好,环境我就不多说了)
除了基本的安装外,他还需要这个包pip install webrtcvad-wheels
python pre.py D:\morckingData -d aidatatang_200zh -n 6
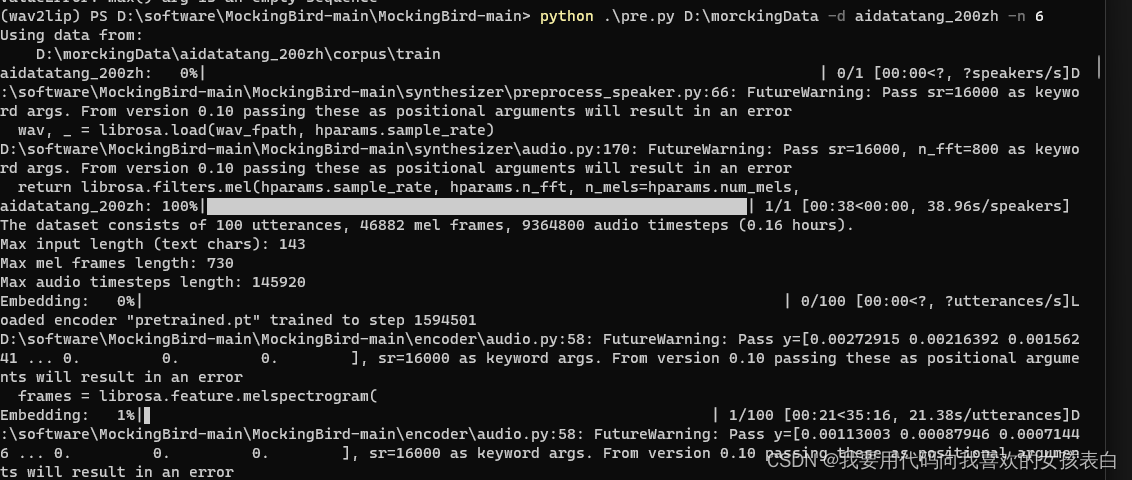
如果遇到了no words,那就是你qh里的音频名字和你transcripts里的。
100句话训练完了,我就录了100句。
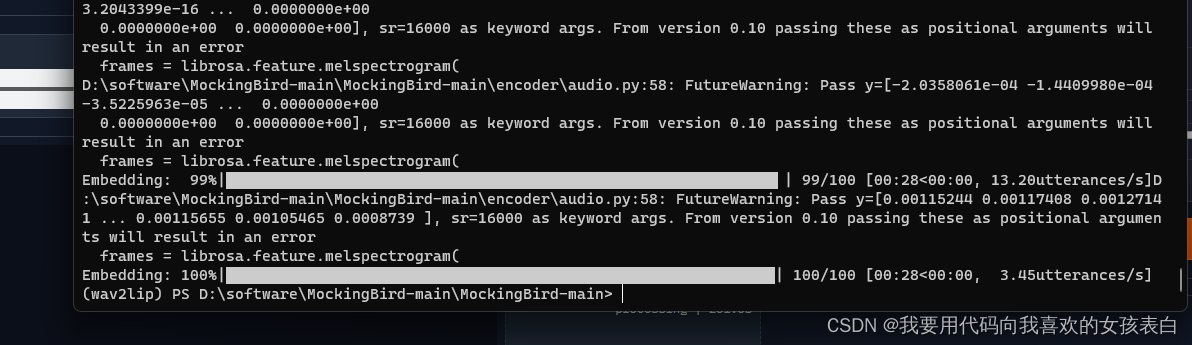
然后会生成一个这个/SV2TTS/synthesizer
训练合成器
python synthesizer_train.py 训练集模型名称 根目录/SV2TTS/synthesizer
执行命令(我是windows,所以是分隔符是\)
python synthesizer_train.py shiao d:\morckingData\SV2TTS\synthesizer

然后他会一直训练,你按ctrl+c退出就行。
我大概训练了5分钟。
模型
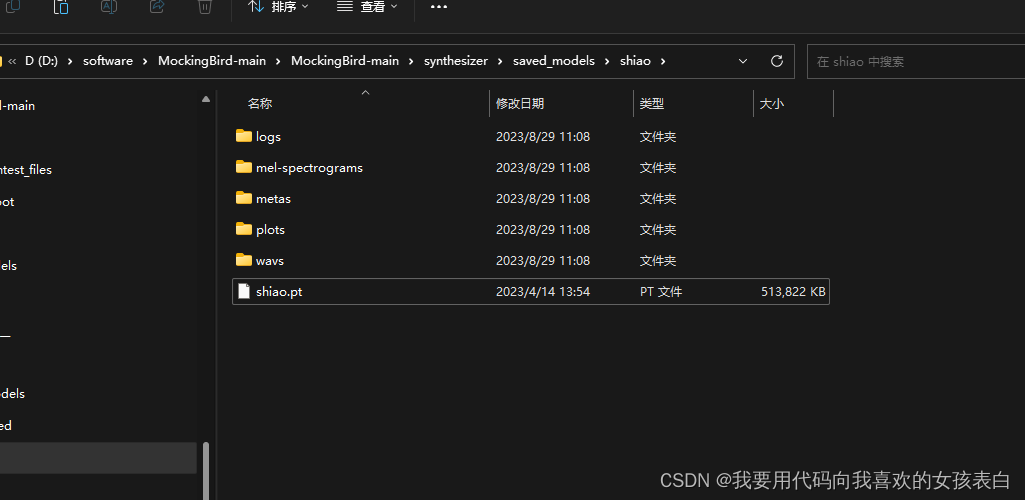
刚刚合成的模型就在mockingBird-main的synthesizer/saved_models
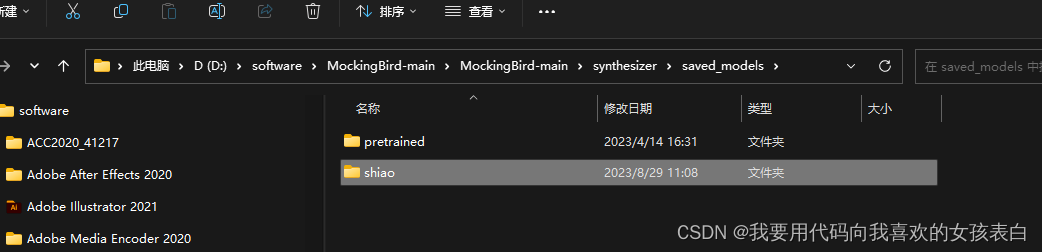
当然这点数据集连声音都训练不出来,但是你的音色会被记录。所以现在还需要用之前他们利用很多音频训练好的模型,进行整合训练。为的是把声音训练出来,并且加入你的音色。
添加之前的模型文件

这个是之前安装的时候,下载的自带的模型。你也可以去官网下一个。
复制一下别人的pretrained.pt,复制到我们自己训练的目录下。因为之前已经执行过训练了,所以我们自己的xx.pt可以删除。并且将这个复制过来的改名为我们自己的xx.pt
继续训练
python synthesizer_train.py shiao d:\morckingData\SV2TTS\synthesizer
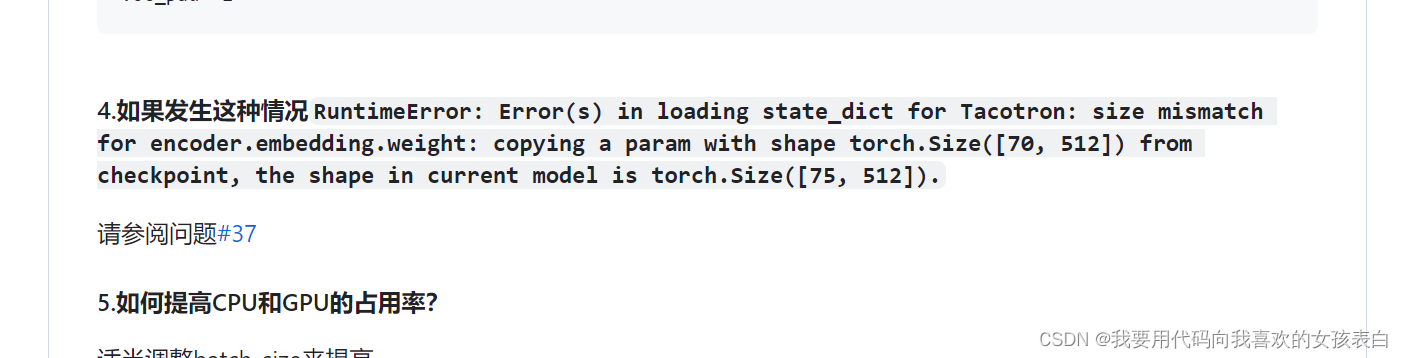
遇到个超参数的问题,网上说是机器问题,别人训练的机器和我机器不一样。所以没法把自己声音覆盖上去。
Traceback (most recent call last):
File "D:\software\MockingBird-main\MockingBird-main\synthesizer_train.py", line 37, in <module>
train(**vars(args))
File "D:\software\MockingBird-main\MockingBird-main\synthesizer\train.py", line 114, in train
model.load(weights_fpath, optimizer)
File "D:\software\MockingBird-main\MockingBird-main\synthesizer\models\tacotron.py", line 525, in load
self.load_state_dict(checkpoint["model_state"], strict=False)
File "C:\Users\a3139\anaconda3\envs\wav2lip\lib\site-packages\torch\nn\modules\module.py", line 2041, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for Tacotron:
size mismatch for gst.stl.attention.W_query.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([512, 256]).
功夫不负有心人有心人,在2小时后,我找到了
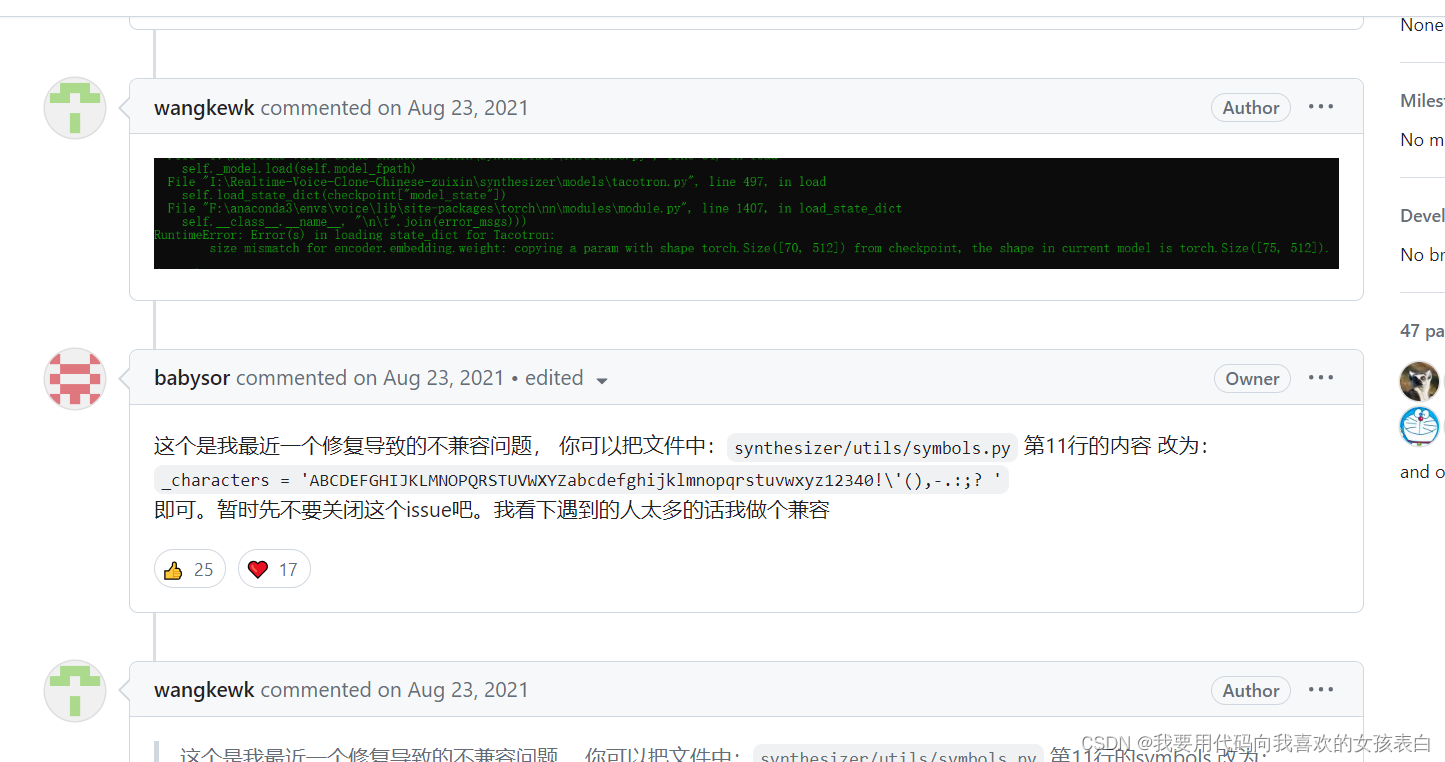
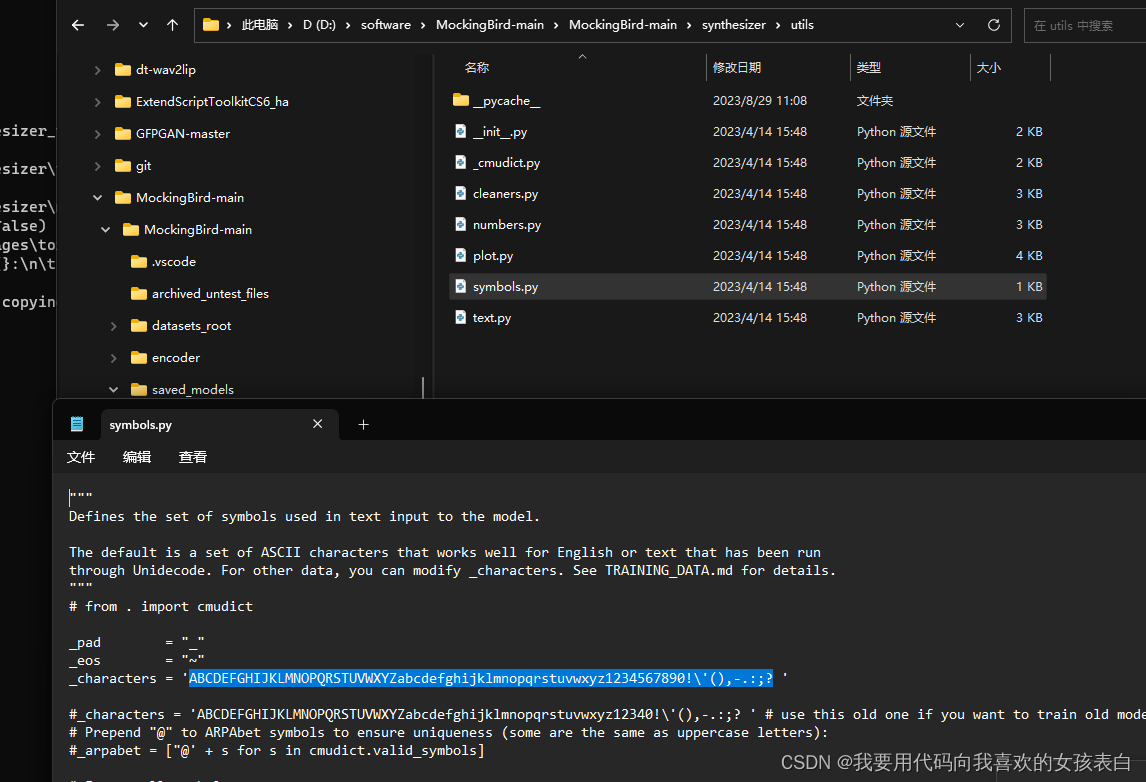
将下面选中的部分改成
_characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz12340!\'(),-.:;? '
然后还是不行。于是又去社区是issue里面找,发现了一个
https://github.com/babysor/MockingBird/issues/245
用他的新模型替换测试,这个也不行。
经过1天的努力,我解决了这个问题,原因就是训练模型的版本和你训练的模型版本不一致。
首先我去网上下了5开头的mocking,这个是网友给的,我拿来pre预处理数据的时候发现和官网的不一样,他是直接合成100句,而不是官网一条一条打印100句。
接下来,我进入了我的模型的目录,然后将他的模型复制过来,删除掉我的,居然成功了。

核心:
在他的模型上训练自己的数据,发现的兼容的版本是
开源知更鸟的源代码版本为 5-MockingBird-main
在他基础上训练的模型版本为 pretrained-11-7-21_75k.pt
这边我已经将兼容的打包好了,方便我下次训练使用
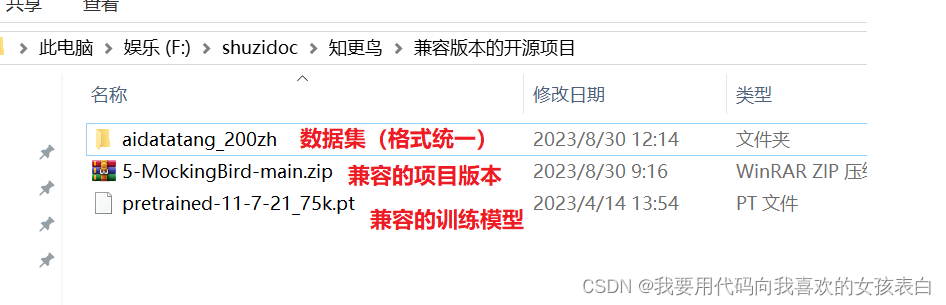
想克隆新声音,添加数据集,使用兼容的模型在训练就行
参考:
https://github.com/babysor/MockingBird/blob/main/README-CN.md
Docs
so-vist
效果非常好,在我尝试了3-4天,换了不同的数据集后,得到的结果。
首先用ffmpeg降噪,如果有噪声。
然后用里面自带的分片。我用的是50分钟的音频,训练了1800步。也就是30分钟。
然后开启f0,然后使用harvest或dio。选择tts-云溪,还原了真人音色。
保存模型只用一个g开头的模型就行(如果以后不训练的话)。在log/44k里
祝贺自己
更牛逼的,中文
SambertHifigan个性化语音合成-中文-预训练-16k
bark是最屌的,但是中文不行。目前我用的最屌的就是kan-tts
这篇关于知更鸟语音训练和so-vist训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







