本文主要是介绍pytorch中 nn.utils.rnn.pack_padded_sequence和nn.utils.rnn.pad_packed_sequence,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 官方文档:
torch.nn — PyTorch 1.11.0 documentation

2. 应用背景:
在使用pytorch处理数据时,一般是采用batch的形式同时处理多个样本序列,而每个batch中的样本序列是不等长的,导致rnn无法处理。所以,通常的做法是先将每个batch按照最长的序列进行padding处理等长的形式。
但padding操作会带来一个问题,那就是对于多数进行padding过的序列,会导致rnn对它的表示多了很多无用的字符,我们希望的是在最后一个有用的字符后就可以输出该序列的向量表示,而不是在很多padding字符后。
这时候,pack操作就派上场了,可以理解成,它是将一个经过padding后的变长序列压紧,压缩后就不含padding的字符0了。具体操作就是:
- 第一步,padding后的输入序列先经过nn.utils.rnn.pack_padded_sequence,这样会得到一个PackedSequence类型的object,可以直接传给RNN(RNN的源码中的forward函数里上来就是判断输入是否是PackedSequence的实例,进而采取不同的操作,如果是则输出也是该类型。);
- 第二步,得到的PackedSequence类型的object,正常直接传给RNN,得到的同样是该类型的输出;
- 第三步,再经过nn.utils.rnn.pad_packed_sequence,也就是对经过RNN后的输出重新进行padding操作,得到正常的每个batch等长的序列。
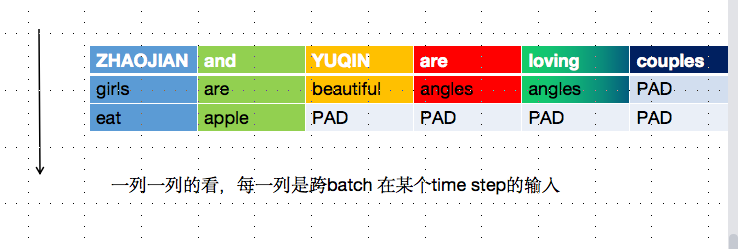

3. 函数详解:
3.1 nn.utils.rnn.pack_padded_sequence
torch.nn.utils.rnn.pack_padded_sequence — PyTorch 1.11.0 documentation

3.2 nn.utils.rnn.pad_packed_sequence
torch.nn.utils.rnn.pad_packed_sequence — PyTorch 1.11.0 documentation


4. 代码实例:
4.1 使用时:
import torch
import torch.nn as nngru = nn.GRU(input_size=1, hidden_size=1, batch_first=True)input = torch.tensor([[1,2,3,4,5],[1,2,3,4,0],[1,2,3,0,0],[1,2,0,0,0]]).unsqueeze(2)
input_lengths = torch.tensor([5,4,3,2])
input = nn.utils.rnn.pack_padded_sequence(input, input_lengths, batch_first=True, enforce_sorted=False)
print(type(input))
print(input)
output, hidden = gru(input.float())
output, _ = torch.nn.utils.rnn.pad_packed_sequence(sequence=output, batch_first=True)print(output)

4.2 不使用时:
import torch
import torch.nn as nngru = nn.GRU(input_size=1, hidden_size=1, batch_first=True)input = torch.tensor([[1,2,3,4,5],[1,2,3,4,0],[1,2,3,0,0],[1,2,0,0,0]]).unsqueeze(2)
input_lengths = torch.tensor([5,4,3,2])
# input = nn.utils.rnn.pack_padded_sequence(input, input_lengths, batch_first=True, enforce_sorted=False)
print(type(input))
print(input)
output, hidden = gru(input.float())
# output, _ = torch.nn.utils.rnn.pad_packed_sequence(sequence=output, batch_first=True)print(output)

5. 注意几个参数:
5.1 batch_first
包括RNN中,参数默认为 False,也就是它鼓励输入的第一维不是batch,这与我们常规输入相悖,我们习惯的输入为(batch_size, seq_len, embedding_dim),所以需要注意,要么该数据输入,要不该参数设置为True。
5.2 enforce_sorted
参数默认为 True,也就是它默认batch中每个序列已经按照长度由大到小进行排列了,所以需要注意,如果没有进行排序,则改为False。
部分参考:https://www.cnblogs.com/yuqinyuqin/p/14100967.html
这篇关于pytorch中 nn.utils.rnn.pack_padded_sequence和nn.utils.rnn.pad_packed_sequence的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








