本文主要是介绍深入理解强化学习——学习(Learning)、规划(Planning)、探索(Exploration)和利用(Exploitation),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
分类目录:《深入理解强化学习》总目录
学习
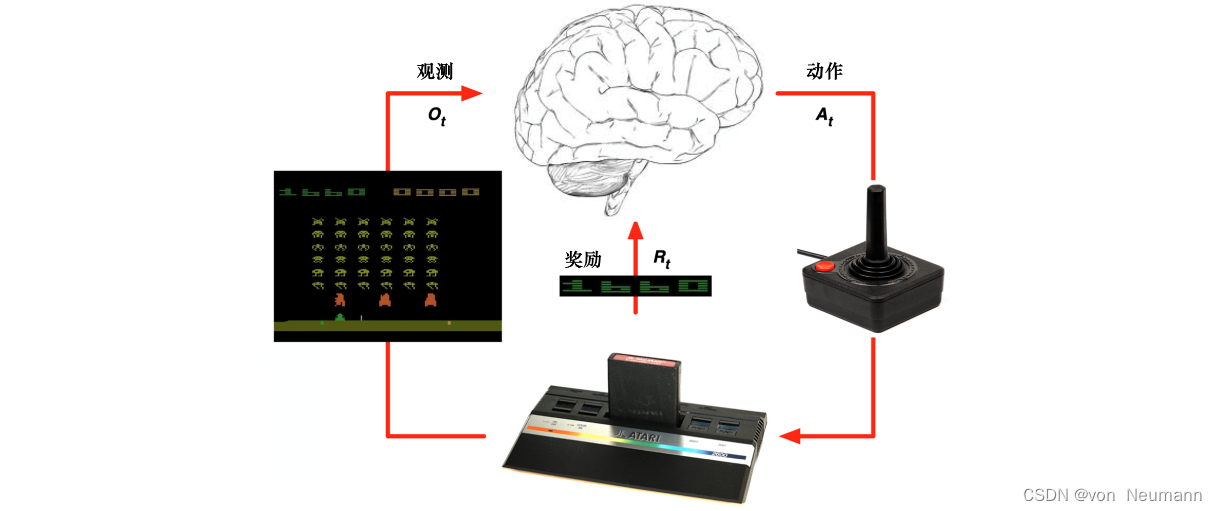
学习(Learning)和规划(Planning)是序列决策的两个基本问题。 如下图所示,在强化学习中,环境初始时是未知的,智能体不知道环境如何工作,它通过不断地与环境交互,逐渐改进策略。
规划
如下图图所示,在规划中,环境是已知的,智能体被告知了整个环境的运作规则的详细信息。智能体能够计算出一个完美的模型,并且在不需要与环境进行任何交互的时候进行计算。智能体不需要实时地与环境交互就能知道未来环境,只需要知道当前的状态,就能够开始思考,来寻找最优解。
在下图所示的游戏中,规则是确定的,我们知道选择左之后环境将会产生什么变化。我们完全可以通过已知的规则,来在内部模拟整个决策过程,无需与环境交互。 一个常用的强化学习问题解决思路是,先学习环境如何工作,也就是了解环境工作的方式,即学习得到一个模型,然后利用这个模型进行规划。

探索和利用
在强化学习里面,探索和利用是两个很核心的问题。 探索即我们去探索环境,通过尝试不同的动作来得到最佳的策略(带来最大奖励的策略)。 利用即我们不去尝试新的动作,而是采取已知的可以带来很大奖励的动作。 在刚开始的时候,强化学习智能体不知道它采取了某个动作后会发生什么,所以它只能通过试错去探索,所以探索就是通过试错来理解采取的动作到底可不可以带来好的奖励。利用是指我们直接采取已知的可以带来很好奖励的动作。所以这里就面临一个权衡问题,即怎么通过牺牲一些短期的奖励来理解动作,从而学习到更好的策略。
下面举一些探索和利用的例子。 以选择餐馆为例,利用是指我们直接去我们最喜欢的餐馆,因为我们去过这个餐馆很多次了,所以我们知道这里面的菜都非常可口。 探索是指我们用手机搜索一个新的餐馆,然后去尝试它的菜到底好不好吃。我们有可能对这个新的餐馆感到非常不满意,这样钱就浪费了。 以做广告为例,利用是指我们直接采取最优的广告策略。探索是指我们换一种广告策略,看看这个新的广告策略可不可以得到更好的效果。 以挖油为例,利用是指我们直接在已知的地方挖油,这样可以确保挖到油。 探索是指我们在一个新的地方挖油,这样就有很大的概率可能不能发现油田,但也可能有比较小的概率可以发现一个非常大的油田。 以玩游戏为例,利用是指我们总是采取某一种策略。比如,我们玩《街头霸王》游戏的时候,采取的策略可能是蹲在角落,然后一直出脚。这个策略很可能可以奏效,但可能遇到特定的对手就会失效。 探索是指我们可能尝试一些新的招式,有可能我们会放出“大招”来,这样就可能“一招毙命”。
与监督学习任务不同,强化学习任务的最终奖励在多步动作之后才能观察到,这里我们不妨先考虑比较简单的情形:最大化单步奖励,即仅考虑一步动作。需注意的是,即便在这样的简单情形下,强化学习仍与监督学习有显著不同,因为智能体需通过试错来发现各个动作产生的结果,而没有训练数据告诉智能体应当采取哪个动作。
想要最大化单步奖励需考虑两个方面:一是需知道每个动作带来的奖励,二是要执行奖励最大的动作。若每个动作对应的奖励是一个确定值,那么尝试遍所有的动作便能找出奖励最大的动作。然而,更一般的情形是,一个动作的奖励值是来自一个概率分布,仅通过一次尝试并不能确切地获得平均奖励值。
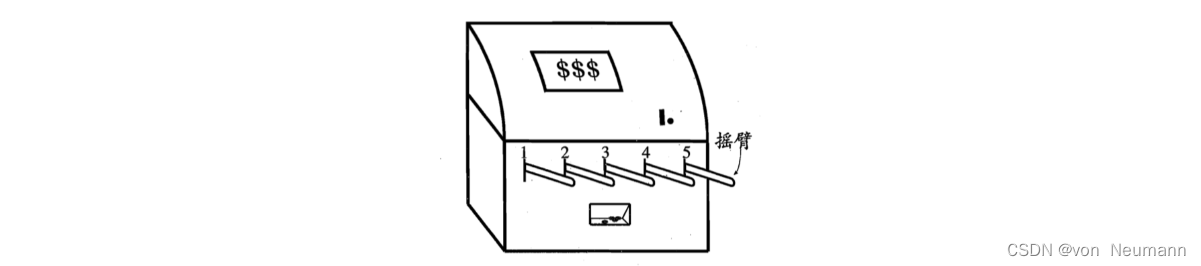
实际上,单步强化学习任务对应于一个理论模型,即K-臂赌博机(K-armed Bandit)。 K-臂赌博机也被称为多臂赌博机(Multi-armed Bandit,MAB) 。如下图所示,K-臂赌博机有K个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币,但这个概率赌徒并不知道。赌徒的目标是通过一定的策略最大化自己的奖励,即获得最多的硬币。 若仅为获知每个摇臂的期望奖励,则可采用仅探索(Exploration-only)法:将所有的尝试机会平均分配给每个摇臂(即轮流按下每个摇臂),最后以每个摇臂各自的平均吐币概率作为其奖励期望的近似估计。若仅为执行奖励最大的动作,则可采用仅利用(Exploitation-only)法:按下目前最优的(即到目前为止平均奖励最大的)摇臂,若有多个摇臂同为最优,则从中随机选取一个。
显然,仅探索法能很好地估计每个摇臂的奖励,却会失去很多选择最优摇臂的机会;仅利用法则相反,它没有很好地估计摇臂期望奖励,很可能经常选不到最优摇臂。因此,这两种方法都难以使最终的累积奖励最大化。
事实上,探索(估计摇臂的优劣)和利用(选择当前最优摇臂)这两者是矛盾的,因为尝试次数(总投币数)有限,加强了一方则自然会削弱另一方,这就是强化学习所面临的探索-利用窘境(Exploration-Exploitation Dilemma)。显然,想要累积奖励最大,则必须在探索与利用之间达成较好的折中。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022
这篇关于深入理解强化学习——学习(Learning)、规划(Planning)、探索(Exploration)和利用(Exploitation)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






