本文主要是介绍论文解读---Frozone: Freezing-Free, Pedestrian-Friendly Navigation in Human Crowds,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文题目:Frozone: Freezing-Free, Pedestrian-Friendly Navigation in Human Crowds (Frozone:在人群中的无停留、行人友好导航)
原文作者:Adarsh Jagan Sathyamoorthy, Utsav Patel, Tianrui Guan, and Dinesh Manocha
论文地址:https://arxiv.org/abs/2003.05395
发表/提交时间:11 Mar 2020
Abstract— We present Frozone, a novel algorithm to deal with the Freezing Robot Problem (FRP) that arises when a robot navigates through dense scenarios and crowds. Our method senses and explicitly predicts the trajectories of pedestrians and constructs a Potential Freezing Zone (PFZ); a spatial zone where the robot could freeze or be obtrusive to humans. Our formulation computes a deviation velocity to avoid the PFZ, which also accounts for social constraints. Furthermore, Frozone is designed for robots equipped with sensors with a limited sensing range and field of view. We ensure that the robot’s deviation is bounded, thus avoiding sudden angular motion which could lead to the loss of perception data of the surrounding obstacles. We have combined Frozone with a Deep Reinforcement Learning-based (DRL) collision avoidance method and use our hybrid approach to handle crowds of varying densities. Our overall approach results in smooth and collision-free navigation in dense environments. We have evaluated our method’s performance in simulation and on real differential drive robots in challenging indoor scenarios. We highlight the benefits of our approach over prior methods in terms of success rates (up to 50% increase), pedestrian-friendliness (100% increase) and the rate of freezing (>80% decrease) in challenging scenarios.
本文提出了一种新的Frozone算法,用于解决机器人在密集场景和人群中导航时出现的机器人冻结问题(FRP)。该方法可感知并明确预测行人的轨迹,构建一个潜在的冻结区(PFZ)—在此区域内,机器人可能冻结或其出现对人类来说很突兀。本文的方法计算了一个偏离速度以避免PFZ,同时考虑了社会约束。此外,Frozone是为装备感应范围和视野有限的传感器的机器人设计的。本文保证了机器人的偏移是有界的,从而避免了突然的转向运动导致周围障碍物感知数据的丢失。本文将Frozone与基于深度强化学习(DRL)的避碰方法结合在一起,并使用混合方法来处理不同密度的人群。本文方法在稠密环境中实现了平滑和无碰撞的导航。在仿真和具有挑战性的真实室内环境中分别评估了本方法的性能。结果表明,在具有挑战性的场景中,本文的方法在成功率(增加50%)、行人友好度(增加100%)和冻结率(减少80%)方面比以往方法更具优势。
1. 论文动机(Motivation)
- 移动机器人除了避免与周围静态或动态障碍物的碰撞外,还应该以行人友好的方式导航,例如与行人保持足够的距离,以及其他从后面避开行人的相应规则(见图1底部).

- 当机器人遇到避障模块声明所有可能的速度都可能导致碰撞的情况时,就会发生机器人冻结问题(FRP)。机器人要么停止,要么开始无限期地摆动,这可能会导致碰撞,或者无法朝着目标前进.
- 一些方法也尝试解决人群中同时出现的冻结和定位丢失问题,但我们需要更一般的解决方案,减少对全局信息的依赖,并对最终性能提供一些保证.
2. 贡献(Contribution)
- 本文提出了Frozone,一种通过明确预测行人轨迹,将其划分为可能冻结或不冻结行人,并构建潜在冻结区(PFZ),以显著减少FRP发生的实时算法.
- 基于个人社交与心理空间约束,该方法保证了机器人可以避免PFZ,并且不会影响到附近的行人.
- 将Frozone与最先进的基于深度强化学习(DRL)的避碰方法相结合,提出了一种混合导航算法.
- 在不同密度人群的几个具有挑战性的室内场景中,基于Clearpath Jackal和一个Turtlebot评估了本文的方法.
3. 方法(Methods)
3.1 系统总体框架,
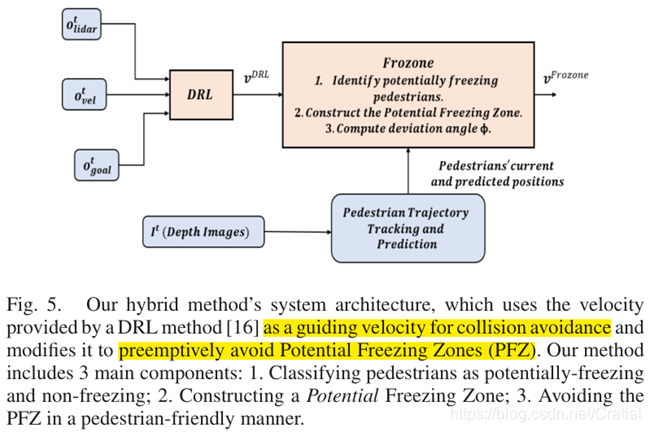
由二维激光雷达,机器人当前速度,目标位置,通过深度强化学习DRL获得下一步可以避开障碍物的速度,之后由Frozone模块对此速度进行调整,以避免陷入机器人冻结问题(避开潜在的冻结区域)。
3.2 机器人冻结问题(FRP)建模,
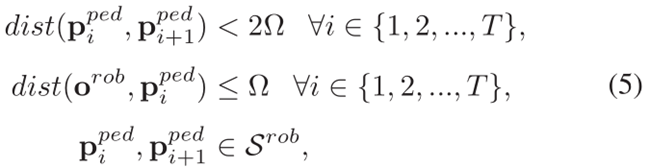
Ω表示机器人的避障模块应保持与所有障碍的最小距离阈值。此条件满足时,控制器认为所有的前进速度都是不安全的。
3.3 识别可能冻结的行人,

当行人速度与机器人速度相当,在机器人右、左半视场的行人,其速度分别满足条件(7)、(8)时,这些行人就是可能冻结的行人。这些行人与机器人之间的距离函数(dist())是一个随时间递减的函数。
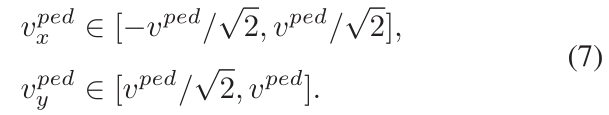
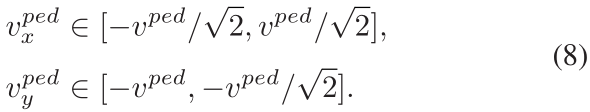
如果行人的速度小于机器人移动速度,则不管行人的方向如何,行人被认为是存在潜在冻结的。因为机器人和行人之间的距离随着时间的推移而减小。
沿x轴运动的行人,不论方向如何都被认为是存在冻结风险的。
3.4 潜在冻结区域(PFZ)建模,
PFZ定义为在经过一个时间间隔Δt后,发生机器人冻结问题(FRP)比较高的区域。
经过Δt时间后,行人的预测位置,

PFZ就是以下凸包函数确定的封闭区域,
![]()
当k=1时,PFZ是一个点,在这种情况下,为了与行人保持足够的距离,将PFZ构造为一个以行人为中心且半径固定的圆。
3.5 计算偏转角度(修正DRL生成的机器人速度),
如果距离机器人最近的潜在冻结行人与机器人之间的距离满足以下条件,或者![]() 时,
时,
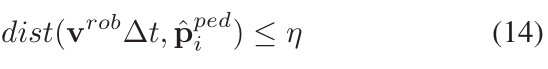
η是行人的舒适距离.
机器人需要调整由DRL生成的速度(旋转一个角度),
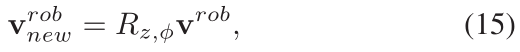
这个旋转是基于机器人的目标位置,以及避免在行人前面导航。

Theta1确保新的速度方向可以避开PFZ区域。此处,Theta2应该为一个集合,图4也说明了Theta2取最大值的情况,但是从公式(18)的表示不能看出是集合。此外,既然需要同时满足绕开PFZ区域,以及保留距离机器人最近的潜在冻结行人的舒适距离,那么改变的转角应该取较大值,即公式(16)应该取max函数。(笔者个人分析)


4. 实验结果与分析(Experiments & Discussion)
以ROS Kinetic和Gazebo创建仿真环境,论文设置了8组仿真实验,从到达目标的准确率、机器人在避开障碍物的过程中被卡住或开始振荡超过10秒的次数、行人友好度(Pedestrian friendliness, PF)、平均用时、平均速度等指标评价本方法的优劣。
行人友好度建模,
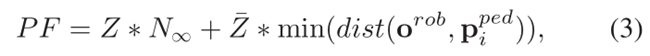
实验结果,



本文的方法避免了预先在行人周围构建的圆形PFZ,防止了冻结机器人问题,而另外三种方法不能处理这种场景。
5. 启示(Conclusion)
本文提出了一种可以显著减少机器人在中等密集人群中导航时出现机器人冻结问题的新方法。本文建模的潜在冻结区域是保守的,仅使用了局部最优技术来计算速度偏差。方法的优劣由底层的行人跟踪算法以及用于行人友好度建模的技术控制。未来,可以进一步考虑机器人的动力学约束。
这篇关于论文解读---Frozone: Freezing-Free, Pedestrian-Friendly Navigation in Human Crowds的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








