本文主要是介绍365天深度学习训练营-第J1周:ResNet-50算法实战与解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、前言
二、论文分析
三、残差网络(ResNet)介绍
1、残差网络解决了什么
2、ResNet-50介绍
四、构造ResNet-50模型
1、Tensorflow代码
2、Pytorch代码
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
● 难度:夯实基础⭐⭐
● 语言:Python3、Pytorch3
● 时间:2月5日-2月10日
🍺要求:1.根据本文的Tensorflow代码,编写Pytorch代码
2.了解残差网络
3.是否可以将残差模块融合到C3中二、论文分析
论文:Deep Residual Learning for Image Recognition
问题的提出:
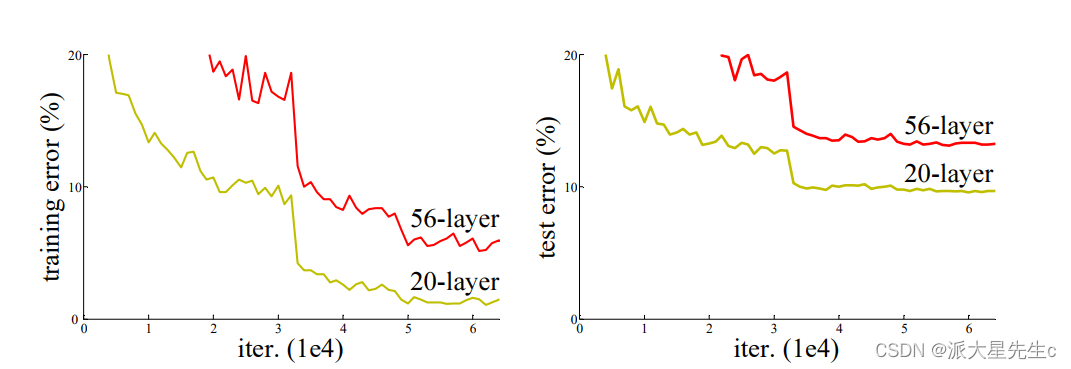
随着网络层数的增加,更深的网络具有更大的训练误差,从而导致测试误差。
所以提出了一个问题:对叠层数越多是不是训练网络效果越好呢?
这种问题的阻碍是梯度消失或者爆炸,而这种我们的解决办法是:初始化归一和中间层归一化
随着网络深度的增加,精度变得饱和,然后迅速退化,但是这种退化不是由于过度拟合引起的,这也就成为了模型训练退化问题。像适当深度的模型添加更多层会导致更高的训练误差。解决这种误差是这篇论文的主要目的。
解决方案一:添加的层是身份映射,其他层是从学习中较浅的模型复制,但是现有的解释器很难做
解决方案二:引入深度残差学习框架来解决这种退化问题。
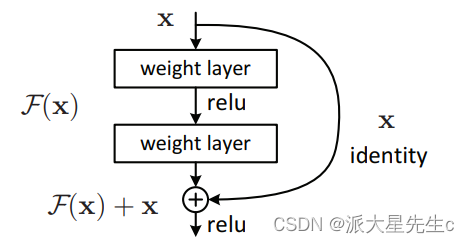
![]()
将所需的基础映射表示为H(x)
让堆叠的非线性层适合F(x):= H(x)- x的另一个映射。
原始映射为F(x)+ x。
通过快捷连接来实现身份验证。
实验证明:
1)极深的残差网络易于优化,但是当深度增加时,对应的“普通”网络(简单地堆叠层)显示出更高的训练误差;
2)深层残差网络可以通过大大增加深度来轻松享受准确性的提高,所产生的结果比以前的网络要好得多。
Deep Residual Learning
残差学习:
将H(x)视为由一些堆叠层(不一定是整个网络)拟合的基础映射,其中x表示这些层中第一层的输入。如果假设多个非线性层可以渐近逼近复杂函数,那么就可以假设它们可以渐近逼近残差函数,即H(x)-x(假设输入和输出为尺寸相同)。因此,没有让堆叠的层近似为H(x),而是明确地让这些层近似为残差函数F(x):= H(x)-x。因此,原始函数变为F(x)+ x。尽管两种形式都应能够渐近地逼近所需的功能(如假设),但学习的难易程度可能有所不同。
简单来讲:
整个模块除了正常的卷积层输出外,还有一个分支把输入直接连在输出上,该分支输出和卷积的输出做算数相加得到了最终的输出,这种残差结构人为的制造了恒等映射,即F(x)分支中所有参数都是0,H(x)就是一个恒等映射,这样就能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。
假设我们现在已经有了一个N层的网络,现在在尾部加上K个残差模块(M层),
如果说这K个残差会造成网络过深,那么这K个残差模块会向恒等映射方向发展(参数为0),进而解决了网络过深问题
网络框架:
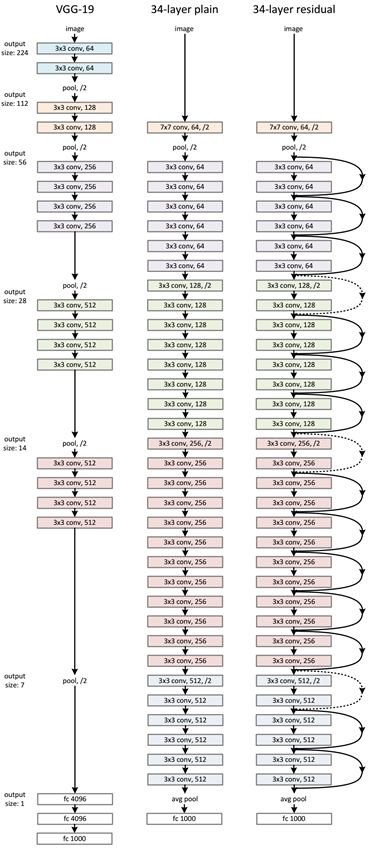
实验结果
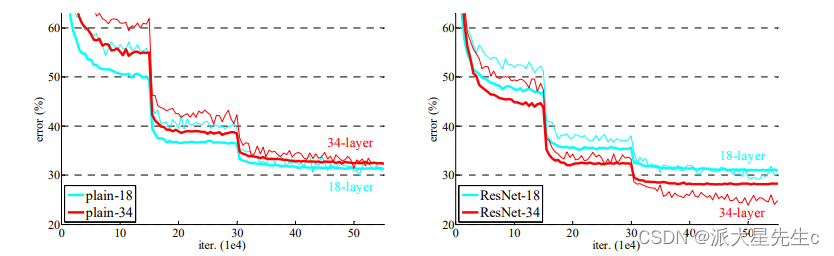
可以明显看到在用ResNet之后,随着网络深度的增加,网络的训练效果更好。
三、残差网络(ResNet)介绍
1、残差网络解决了什么
残差网络是为了解决神经网络隐藏层过多时,而引起的网络退化问题。退化(degradation)问题是指:当网络隐藏层变多时,网络的准确度达到饱和然后急剧退化,而且这个退化不是由于过拟合引起的。
拓展:深度神经网络的"两朵乌云"
- 梯度弥散/爆炸
简单来讲就是网络太深了,会导致模型训练难以收敛。这个问题可以被标准初始化和中间层正规化的方法有效控制。
- 网络退化
随着网络深度增加,网络的表现先是逐渐增加至饱和,然后迅速下降,这个退化不是由过拟合引起的。
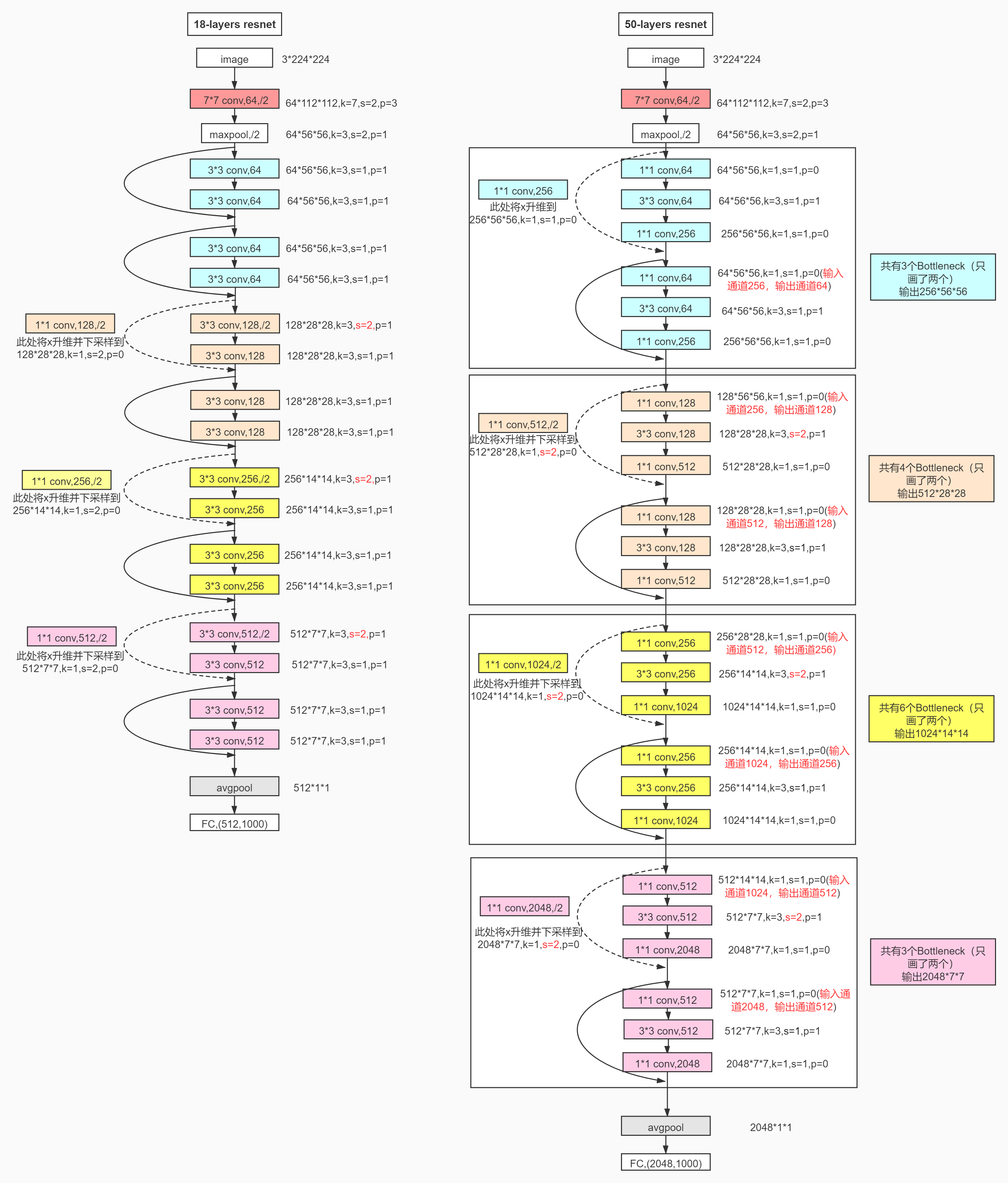
2、ResNet-50介绍
ResNet-50有两个基本的块,分别名为Conv Block和Identity Block
Conv Block结构:
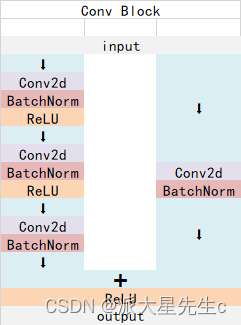
Identity Block结构:

ResNet-50总体结构:

四、构造ResNet-50模型
1、Tensorflow代码
def identity_block(input_ten,kernel_size,filters):filters1,filters2,filters3 = filtersx = Conv2D(filters1,(1,1))(input_ten)x = BatchNormalization()(x)x = Activation('relu')(x)x = Conv2D(filters2,kernel_size,padding='same')(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = Conv2D(filters3,(1,1))(x)x = BatchNormalization()(x)x = layers.add([x,input_ten])x = Activation('relu')(x)return x
def conv_block(input_ten,kernel_size,filters,strides=(2,2)):filters1,filters2,filters3 = filtersx = Conv2D(filters1,(1,1),strides=strides)(input_ten)x = BatchNormalization()(x)x = Activation('relu')(x)x = Conv2D(filters2,kernel_size,padding='same')(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = Conv2D(filters3,(1,1))(x)x = BatchNormalization()(x)shortcut = Conv2D(filters3,(1,1),strides=strides)(input_ten)shortcut = BatchNormalization()(shortcut)x = layers.add([x,shortcut])x = Activation('relu')(x)return x
def ResNet50(nb_class,input_shape):input_ten = Input(shape=input_shape)x = ZeroPadding2D((3,3))(input_ten)x = Conv2D(64,(7,7),strides=(2,2))(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = MaxPooling2D((3,3),strides=(2,2))(x)x = conv_block(x,3,[64,64,256],strides=(1,1))x = identity_block(x,3,[64,64,256])x = identity_block(x,3,[64,64,256])x = conv_block(x,3,[128,128,512])x = identity_block(x,3,[128,128,512])x = identity_block(x,3,[128,128,512])x = identity_block(x,3,[128,128,512])x = conv_block(x,3,[256,256,1024])x = identity_block(x,3,[256,256,1024])x = identity_block(x,3,[256,256,1024])x = identity_block(x,3,[256,256,1024])x = identity_block(x,3,[256,256,1024])x = identity_block(x,3,[256,256,1024])x = conv_block(x,3,[512,512,2048])x = identity_block(x,3,[512,512,2048])x = identity_block(x,3,[512,512,2048])x = AveragePooling2D((7,7))(x)x = tf.keras.layers.Flatten()(x)output_ten = Dense(nb_class,activation='softmax')(x)model = Model(input_ten,output_ten)model.load_weights("resnet50_weights_tf_dim_ordering_tf_kernels.h5")return model
model_ResNet50 = ResNet50(24,(img_height,img_width,3))
model_ResNet50.summary()
2、Pytorch代码
from torch import nnclass ConvBlock(nn.Module):def __init__(self, in_channel, kernel_size, filters, stride):super(ConvBlock, self).__init__()filter1, filter2, filter3 = filtersself.stage = nn.Sequential(nn.Conv2d(in_channel, filter1, 1, stride=stride, padding=0, bias=False),nn.BatchNorm2d(filter1),nn.RuLU(True),nn.Conv2d(filter1, filter2, kernel_size, stride=1, padding=True, bias=False),nn.BatchNorm2d(filter2),nn.RuLU(True),nn.Conv2d(filter2, filter3, 1, stride=1, padding=0, bias=False),nn.BatchNorm2d(filter3),)self.shortcut_1 = nn.Conv2d(in_channel, filter3, 1, stride=stride, padding=0, bias=False)self.batch_1 = nn.BatchNorm2d(filter3)self.relu_1 = nn.ReLU(True)def forward(self, x):x_shortcut = self.shortcut_1(x)x_shortcut = self.batch_1(x_shortcut)x = self.stage(x)x = x + x_shortcutx = self.relu_1(x)return xclass IndentityBlock(nn.Module):def __init__(self, in_channel, kernel_size, filters):super(IndentityBlock, self).__init__()filter1, filter2, filter3 = filtersself.stage = nn.Sequential(nn.Conv2d(in_channel, filter1, 1, stride=1, padding=0, bias=False),nn.BatchNorm2d(filter1),nn.RuLU(True),nn.Conv2d(filter1, filter2, kernel_size, padding=True, bias=False),nn.BatchNorm2d(filter1),nn.RuLU(True),nn.Conv2d(filter2, filter3, 1, stride=1, padding=0, bias=False),nn.BatchNorm2d(filter3),)self.relu_1=nn.ReLU(True)def forward(self, x):x_shortcut = xx = self.stage(x)x = x + x_shortcutx = self.relu_1(x)return xclass ResModel(nn.Module):def __init__(self, n_class):super(ResModel, self).__init__()self.stage1 = nn.Sequential(nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False),nn.BatchNorm2d(64),nn.ReLU(True),nn.MaxPool2d(3, 2, padding=1),)self.stage2 = nn.Sequential(ConvBlock(64, f=3, filters=[64, 64, 256], s=2),IndentityBlock(256, 3, [64, 64, 256]),IndentityBlock(256, 3, [64, 64, 256]),)self.stage3 = nn.Sequential(ConvBlock(256, f=3, filters=[128, 128, 512], s=3),IndentityBlock(512, 3, [128, 128, 512]),IndentityBlock(512, 3, [128, 128, 512]),IndentityBlock(512, 3, [128, 128, 512]),)self.stage4 = nn.Sequential(ConvBlock(512, f=3, filters=[256, 256, 1024], s=4),IndentityBlock(1024, 3, [256, 256, 1024]),IndentityBlock(1024, 3, [256, 256, 1024]),IndentityBlock(1024, 3, [256, 256, 1024]),IndentityBlock(1024, 3, [256, 256, 1024]),IndentityBlock(1024, 3, [256, 256, 1024]),)self.stage5 = nn.Sequential(ConvBlock(1024, f=3, filters=[512, 512, 2048], s=5),IndentityBlock(2048, 3, [512, 512, 2048]),IndentityBlock(2048, 3, [512, 512, 2048]),)self.pool = nn.AvgPool2d(7, 7, padding=1)self.fc = nn.Sequential(nn.Linear(8192, n_class))def forward(self, X):out = self.stage1(X)out = self.stage2(out)out = self.stage3(out)out = self.stage4(out)out = self.stage5(out)out = self.pool(out)out = out.view(out.size(0), 8192)out = self.fc(out)return out
这篇关于365天深度学习训练营-第J1周:ResNet-50算法实战与解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







