本文主要是介绍python批量将多年降水的nc数据处理为季节性平均降水量或年降水量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本代码目的:
1.批量读取nc降水数据集。
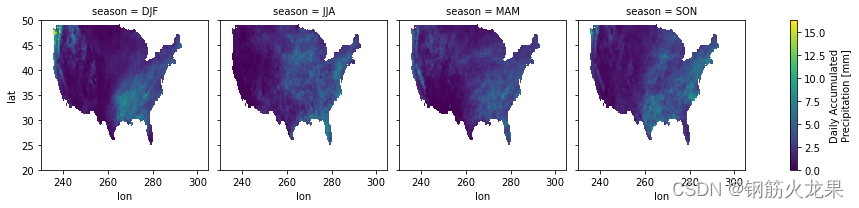
2.按照季节平均来粗略绘制降水量图。
3.保存所有处理后的数据集,以备下次精细化绘图。
原始数据请见美国2013-2021年每日降水的nc数据集资源-CSDN文库
##1.导入需要的库和函数
import xarray as xr
import os
from netCDF4 import Dataset##2.指定文件路径,实现批量读取满足条件的文件.(批量读取多个nc文件)
path = r"D:/baseCode/raw/"
#file = os.listdir(path)
#print(file) #输出nc文件列表##3.创建一个空的数据集来存储结果
result = xr.DataArray()##4.遍历文件夹下的nc文件
for root_dir, sub_dir, files in os.walk(path):for file in files:if file.endswith('.nc'): file_name=os.path.join(root_dir, 这篇关于python批量将多年降水的nc数据处理为季节性平均降水量或年降水量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







