本文主要是介绍C++项目实战——基于多设计模式下的同步异步日志系统-⑩-异步缓冲区类与异步工作器类设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 专栏导读
- 异步缓冲区设计思想
- 异步缓冲区类设计
- 异步工作器类设计
- 异步日志器设计
- 异步缓冲区类整理
- 异步工作器类整理
专栏导读
🌸作者简介:花想云 ,在读本科生一枚,C/C++领域新星创作者,新星计划导师,阿里云专家博主,CSDN内容合伙人…致力于 C/C++、Linux 学习。
🌸专栏简介:本文收录于 C++项目——基于多设计模式下的同步与异步日志系统
🌸相关专栏推荐:C语言初阶系列、C语言进阶系列 、C++系列、数据结构与算法、Linux

为了避免因为写日志的过程阻塞,导致业务线程在写日志的时候影响其效率(例如由于网络原因导致日志写入阻塞,进而导致业务线程阻塞),因此我们需要设计一个异步日志器。
异步的思想就是不让业务线程进行日志的实际落地操作,而是将日志消息放到缓冲区(一块指定内存)当中,接下来有一个专门的异步线程,去针对缓冲区中的数据进行处理(实际落地操作)。
所以,异步日志器的实现思想:
- 设计一个
线程安全的缓冲区; - 创建一个
异步工作线程,专门负责缓冲区中日志消息落地操作。
异步缓冲区设计思想
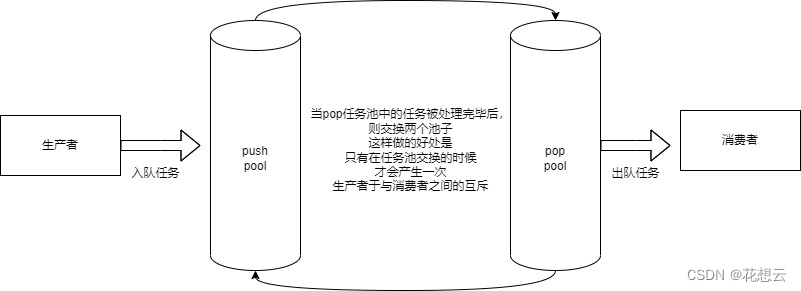
在任务池的设计中,有很多备选方案,比如队列、循环队列等,但是不管哪一种都会涉及到锁冲突的情况,因为在生产者与消费者模型中,任何两个角色之间具有互斥关系,因此每一次任务的添加与取出都有可能涉及锁的冲突。
所以我们采用双缓冲区的的设计思想,优势在于:
避免了空间的频繁申请与释放,且尽可能的减少了生产者与消费则之间锁冲突的概率,提高了任务处理效率。
双缓冲区的设计思想是:采用两个缓冲区,一个用来进行任务写入(push pool),一个进行任务处理(pop pool)。当异步工作线程(消费者)将缓冲区中的数据全部处理完毕之后,然后交换两个缓冲区,重新对新的缓冲区中的任务进行处理,虽然同时多线程写入也会产生冲突,但是冲突并不会像每次只处理一条的时候频繁(减少了消费者与生产者之间的锁冲突),且不涉及到空间的频繁申请释放所带来的的消耗。
异步缓冲区类设计
类中包含的成员:
- 一个存放字符串数据的
缓冲区(使用vector进行空间管理); - 当前
写入数据位置的指针(指向可写区域的起始位置,避免数据的写入覆盖); - 当前
读取数据位置的指针(指向可读区域的起始位置,当读取指针与写入指针指向相同的位置表示数据读取完了);
类中提供的操作:
向缓冲区中写入数据;获取可读数据起始地址的接口;获取可读数据长度的接口;移动读写位置的接口;初始化缓冲区的操作(将读写位置初始化–在一个缓冲区所有数据处理完毕之后);提供交换缓冲区的操作(交换空间地址,并不交换空间数据)。
注意,缓冲区中直接存放格式化后的日志消息字符串,而不是LogMsg对象,这样做有两个好处:
- 减少了
LogMsg对象频繁的构造的消耗; - 可以针对缓冲区中的日志消息,
一次性进行IO操作,减少IO次数,提高效率。
#ifndef __M_BUFFER_H__
#define __M_BUFFER_H__
#include "util.hpp"
#include <vector>
#include <cassert>namespace LOG
{#define DEFAULT_BUFFER_SIZE (1 * 1024 * 1024)#define THRESHOLD_BUFFER_SIZE (8 * 1024 * 1024)#define INCREMENT_BUFFER_SIZE (1 * 1024 * 1024)class Buffer {public:Buffer() : _buffer(DEFAULT_BUFFER_SIZE), _writer_idx(0), _reader_idx(0) {}// 向缓冲区中写入数据void push(const char* data, size_t len){// 1.考虑空间不够则扩容ensureEnoughSize(len);// 2.将数据拷贝到缓冲区std::copy(data, data + len, &_buffer[_writer_idx]);// 3.将当前写入位置向后偏移moveWriter(len);}// 返回可读数据的起始地址const char* begin(){return &_buffer[_reader_idx];}// 返回可写数据的长度size_t writeAbleSize(){// 对于扩容思路并没有用, 仅针对固定大小缓冲区return (_buffer.size() - _writer_idx);}// 返回可读数据的长度size_t readAbleSize(){ return (_writer_idx - _reader_idx);}// 重置读写位置void reset(){_writer_idx = 0;_reader_idx = 0;}// 对buffer实现交换操作void swap(Buffer & buffer){_buffer.swap(buffer._buffer);std::swap(_reader_idx, buffer._reader_idx);std::swap(_writer_idx, buffer._writer_idx);}// 判断缓冲区是否为空bool empty(){return (_reader_idx == _writer_idx);}private:void ensureEnoughSize(size_t len){if(len < writeAbleSize()) return;size_t new_size = 0;if(_buffer.size() < THRESHOLD_BUFFER_SIZE){new_size = _buffer.size() * 2 + len; // 小于阈值则翻倍增长}else{new_size = _buffer.size() + INCREMENT_BUFFER_SIZE + len;}_buffer.resize(new_size);}// 对读指针进行向后偏移操作void moveReader(size_t len){assert(len <= readAbleSize());_reader_idx += len;}// 对写指针进行向后偏移操作void moveWriter(size_t len){assert(len + _writer_idx<= _buffer.size());_writer_idx += len;}private:std::vector<char> _buffer;size_t _reader_idx; // 当前可读数据的指针size_t _writer_idx; // 当前可写数据的指针};
}
#endif
异步工作器类设计
异步工作器的主要任务是,对缓冲区中的数据进行处理,若处理缓冲区中没有数据了则交换缓冲区。
异步工作器类管理的成员有:
双缓冲区(生产,消费);互斥锁:保证线程安全;条件变量-生产&消费:生产缓冲区中没有数据,处理完消费缓冲区数据后就休眠;回调函数:针对缓冲区中数据的处理接口——外界传入一个函数,告诉异步日志器该如何处理。
异步工作器类提供的操作有:
停止异步工作器;添加数据到缓冲区;
私有操作:
创建线程;线程入口函数:在线程入口函数中交换缓冲区,对消费缓冲区数据使用回调函数进行处理,处理完后再次交换;
#ifndef __M_LOOPER_H__
#define __M_LOOPER_H__
#include "buffer.hpp"
#include <iostream>
#include <thread>
#include <mutex>
#include <atomic>
#include <condition_variable>
#include <functional>
#include <memory>namespace LOG
{using Functor = std::function<void(Buffer &)>;enum class AsyncType{ASYNC_SAFE, // 安全状态, 表示缓冲区满了则阻塞,避免资源耗尽的风险ASYNC_UNSAFE // 不考虑资源耗尽的问题};class AsyncLooper{public:using ptr = std::shared_ptr<AsyncLooper>;AsyncLooper(const Functor& cb, AsyncType looper_type = AsyncType::ASYNC_SAFE):_looper_type(looper_type),_stop(false),_call_back(cb),_thread(std::thread(&AsyncLooper::threadEntry, this)){}~AsyncLooper() { stop(); }void stop() {_stop = true; // 将退出标志设置为true_con_cond.notify_all(); // 唤醒所有工作线程_thread.join(); // 等待工作线程退出}void push(const char* data, size_t len){std::unique_lock<std::mutex> lock(_mutex);// 条件变量控制,若缓冲区剩余空间大小等于数据长度,则可以添加数据if(_looper_type == AsyncType::ASYNC_SAFE)_pro_cond.wait(lock, [&](){ return _pro_buf.writeAbleSize() >= len; });// 能够走下来说明条件满足,可以向缓冲区添加数据了_pro_buf.push(data, len);// 唤醒消费者对缓冲区中的数据进行处理_con_cond.notify_one();}private:// 线程入口函数 -- 对消费者缓冲区中的数据进行处理,处理完毕后,初始化缓冲区,交换缓冲区void threadEntry(){// 为互斥锁设置一个声明周期,当缓冲区交换完毕就解锁while(1){{// 1.判断生产缓冲区有没有数据,有则交换,无则阻塞std::unique_lock<std::mutex> lock(_mutex);if(_stop && _pro_buf.empty()) break;// 若当前是退出前被唤醒或者是有数据被唤醒,则返回真,继续向下运行,否则重新进入休眠_con_cond.wait(lock, [&](){ return _stop || !_pro_buf.empty(); });_con_buf.swap(_pro_buf);// 2.唤醒生产者if(_looper_type == AsyncType::ASYNC_SAFE)_pro_cond.notify_all();}// 3.被唤醒后,对消费者缓冲区进行数据处理_call_back(_con_buf);// 4.初始化消费者缓冲区_con_buf.reset();}}private:Functor _call_back;private:AsyncType _looper_type;std::atomic<bool> _stop;Buffer _pro_buf;Buffer _con_buf;std::mutex _mutex;std::condition_variable _pro_cond;std::condition_variable _con_cond;std::thread _thread; // 异步工作器对应的工作线程};
}
#endif
异步日志器设计
异步日志器继承自日志器类,并在同步日志器类上拓展了异步工作器。当我们需要异步输出日志的时候,需要创建异步日志器和消息处理器,调用异步日志器的log、debug、error、info、fatal等函数输出不同级别日志。
log函数为重写Logger类的函数,主要实现将日志日志数据加入异步缓冲区;realLog函数主要由异步线程调用(是为异步工作器设置的回调函数),完成日志的实际落地操作。
class AsyncLogger : public Logger
{
public:AsyncLogger(const std::string &logger_name,LogLevel::value level,LOG::Formatter::ptr &formatter,std::vector<LogSink::ptr> &sinks,AsyncType looper_type): Logger(logger_name, level, formatter, sinks),_looper(std::make_shared<AsyncLooper>(std::bind(&AsyncLogger::realLog, this, std::placeholders::_1), looper_type)){}// 将数据写入缓冲区 void log(const char *data, size_t len){_looper->push(data, len);}// 设计一个实际落地函数void realLog(Buffer &buf){if (_sinks.empty())return;for (auto &sink : _sinks){sink->log(buf.begin(), buf.readAbleSize());}}private:AsyncLooper::ptr _looper; // 异步工作器
};异步缓冲区类整理
#ifndef __M_BUFFER_H__
#define __M_BUFFER_H__
#include "util.hpp"
#include <vector>
#include <cassert>namespace LOG
{#define DEFAULT_BUFFER_SIZE (1 * 1024 * 1024)#define THRESHOLD_BUFFER_SIZE (8 * 1024 * 1024)#define INCREMENT_BUFFER_SIZE (1 * 1024 * 1024)class Buffer {public:Buffer() : _buffer(DEFAULT_BUFFER_SIZE), _writer_idx(0), _reader_idx(0) {}// 向缓冲区中写入数据void push(const char* data, size_t len){// 1.考虑空间不够则扩容ensureEnoughSize(len);// 2.将数据拷贝到缓冲区std::copy(data, data + len, &_buffer[_writer_idx]);// 3.将当前写入位置向后偏移moveWriter(len);}// 返回可读数据的起始地址const char* begin(){return &_buffer[_reader_idx];}// 返回可写数据的长度size_t writeAbleSize(){// 对于扩容思路并没有用, 仅针对固定大小缓冲区return (_buffer.size() - _writer_idx);}// 返回可读数据的长度size_t readAbleSize(){ return (_writer_idx - _reader_idx);}// 重置读写位置void reset(){_writer_idx = 0;_reader_idx = 0;}// 对buffer实现交换操作void swap(Buffer & buffer){_buffer.swap(buffer._buffer);std::swap(_reader_idx, buffer._reader_idx);std::swap(_writer_idx, buffer._writer_idx);}// 判断缓冲区是否为空bool empty(){return (_reader_idx == _writer_idx);}private:void ensureEnoughSize(size_t len){if(len < writeAbleSize()) return;size_t new_size = 0;if(_buffer.size() < THRESHOLD_BUFFER_SIZE){new_size = _buffer.size() * 2 + len; // 小于阈值则翻倍增长}else{new_size = _buffer.size() + INCREMENT_BUFFER_SIZE + len;}_buffer.resize(new_size);}// 对读指针进行向后偏移操作void moveReader(size_t len){assert(len <= readAbleSize());_reader_idx += len;}// 对写指针进行向后偏移操作void moveWriter(size_t len){assert(len + _writer_idx<= _buffer.size());_writer_idx += len;}private:std::vector<char> _buffer;size_t _reader_idx; // 当前可读数据的指针size_t _writer_idx; // 当前可写数据的指针};
}
#endif
异步工作器类整理
#ifndef __M_LOOPER_H__
#define __M_LOOPER_H__
#include "buffer.hpp"
#include <iostream>
#include <thread>
#include <mutex>
#include <atomic>
#include <condition_variable>
#include <functional>
#include <memory>namespace LOG
{using Functor = std::function<void(Buffer &)>;enum class AsyncType{ASYNC_SAFE, // 安全状态, 表示缓冲区满了则阻塞,避免资源耗尽的风险ASYNC_UNSAFE // 不考虑资源耗尽的问题};class AsyncLooper{public:using ptr = std::shared_ptr<AsyncLooper>;AsyncLooper(const Functor& cb, AsyncType looper_type = AsyncType::ASYNC_SAFE):_looper_type(looper_type),_stop(false),_call_back(cb),_thread(std::thread(&AsyncLooper::threadEntry, this)){}~AsyncLooper() { stop(); }void stop() {_stop = true; // 将退出标志设置为true_con_cond.notify_all(); // 唤醒所有工作线程_thread.join(); // 等待工作线程退出}void push(const char* data, size_t len){std::unique_lock<std::mutex> lock(_mutex);// 条件变量控制,若缓冲区剩余空间大小等于数据长度,则可以添加数据if(_looper_type == AsyncType::ASYNC_SAFE)_pro_cond.wait(lock, [&](){ return _pro_buf.writeAbleSize() >= len; });// 能够走下来说明条件满足,可以向缓冲区添加数据了_pro_buf.push(data, len);// 唤醒消费者对缓冲区中的数据进行处理_con_cond.notify_one();}private:// 线程入口函数 -- 对消费者缓冲区中的数据进行处理,处理完毕后,初始化缓冲区,交换缓冲区void threadEntry(){// 为互斥锁设置一个生命周期,当缓冲区交换完毕就解锁while(1){{// 1.判断生产缓冲区有没有数据,有则交换,无则阻塞std::unique_lock<std::mutex> lock(_mutex);if(_stop && _pro_buf.empty()) break;// 若当前是退出前被唤醒或者是有数据被唤醒,则返回真,继续向下运行,否则重新进入休眠_con_cond.wait(lock, [&](){ return _stop || !_pro_buf.empty(); });_con_buf.swap(_pro_buf);// 2.唤醒生产者if(_looper_type == AsyncType::ASYNC_SAFE)_pro_cond.notify_all();}// 3.被唤醒后,对消费者缓冲区进行数据处理_call_back(_con_buf);// 4.初始化消费者缓冲区_con_buf.reset();}}private:Functor _call_back;private:AsyncType _looper_type; // 选择异步工作器工作模式(安全与非安全模式)std::atomic<bool> _stop; // 工作器退出标志Buffer _pro_buf; Buffer _con_buf; std::mutex _mutex;std::condition_variable _pro_cond;std::condition_variable _con_cond;std::thread _thread; // 异步工作器对应的工作线程};
}
#endif

这篇关于C++项目实战——基于多设计模式下的同步异步日志系统-⑩-异步缓冲区类与异步工作器类设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







