本文主要是介绍一种新型元启发式算法-长鼻浣熊优化算法(COA),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、COA算法理论基础
二、COA算法数学模型
2.1 种群初始化
2.2 对鬣蜥狩猎和攻击策略(勘探阶段)
2.3 逃离捕食者的过程(开发阶段)
三、COA算法流程图
四、COA算法运行结果
长鼻浣熊优化算法(Coati Optimization Algorithm,COA)算法是Mohammad Dehghani 等人于2022年提出的一种模拟长鼻浣熊的两种自然行为:攻击和狩猎鬣鳞蜥时的行为和逃离捕食者的行为的元启发式算法。该算法在勘探和开发的两个阶段中进行描述和数学建模。
一、COA算法理论基础
长鼻浣熊是一种日间活动的哺乳动物,活动于美国西南部、墨西哥、中美洲和南美洲。长鼻浣熊的体积大约和一只大家猫相同,体重在2到8公斤之间,站在肩膀上大约有30厘米高。雄性可以长到几乎是雌性的两倍大,有锋利的大犬齿。长鼻浣熊是杂食动物,比如吃无脊椎动物(狼蛛),小型脊椎动物的猎物(小鸟、蜥蜴、啮齿动物、鳄鱼蛋和鸟卵),最喜欢吃的食物之一是绿色鬣鳞蜥。它们也被大型猛禽猎杀(鹰)。因此COA算法是通过模拟长鼻浣熊攻击鬣鳞蜥的策略和面对与躲避捕食者的行为提出的一种元启发式算法。

图1 长鼻浣熊
二、COA算法数学模型
2.1 种群初始化


2.2 对鬣蜥狩猎和攻击策略(勘探阶段)
当长鼻浣熊攻击鬣鳞蜥时,一群浣熊爬上树,到达一只鬣鳞蜥附近时恐吓它。其他几个长鼻浣熊在树下等待,直到鬣鳞蜥掉落到地上,长鼻浣熊开始攻击和猎捕它。该策略的模式图如图2所示:
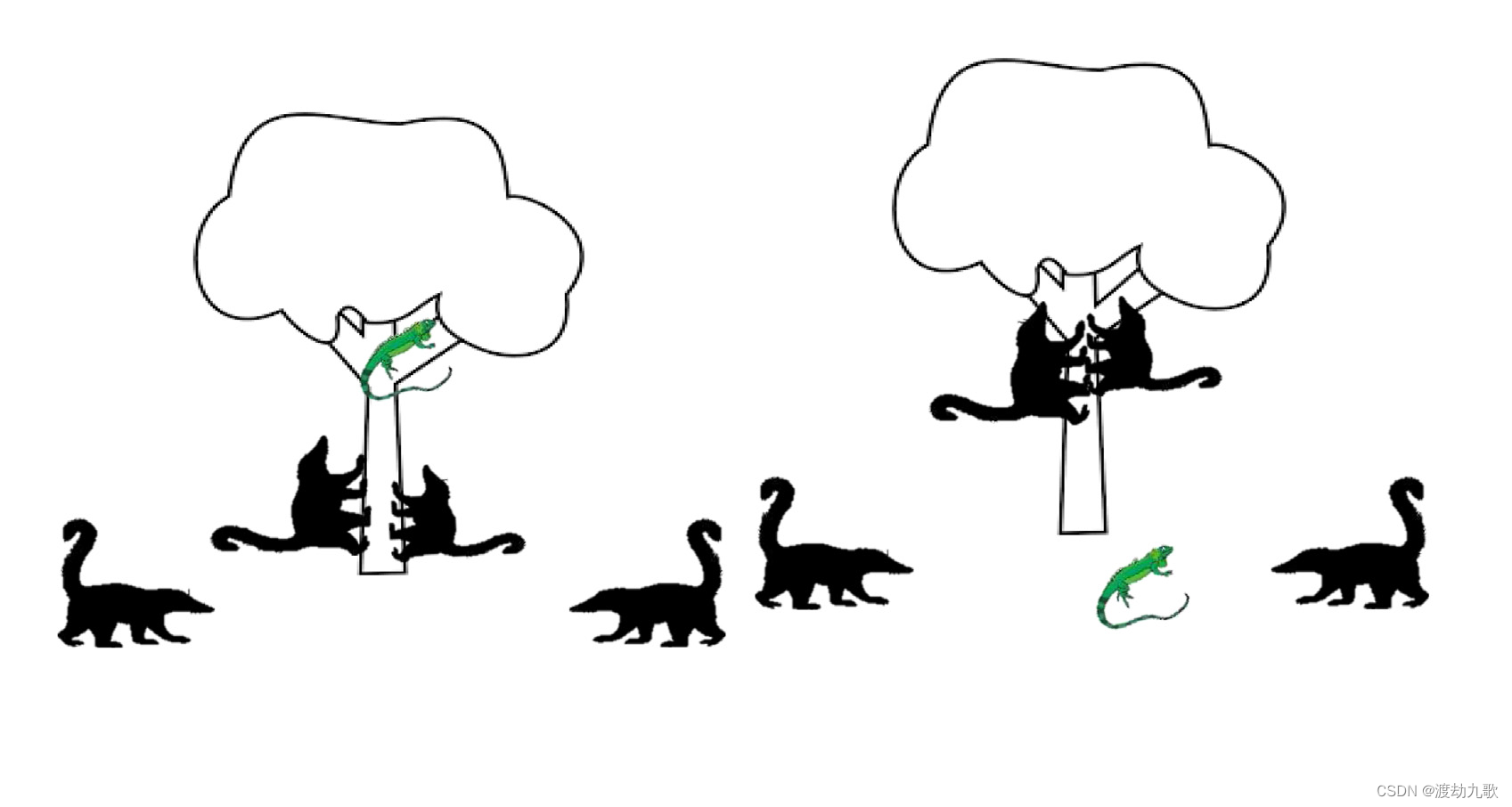
图2 COA 第一阶段的模式图

2.3 逃离捕食者的过程(开发阶段)
当一个捕食者攻击一只长鼻浣熊同伴时,这只浣熊就会逃离它原来的位置。在这个过程中使长鼻浣熊处于接近原先位置的一个安全区域,以躲避捕食者。开发阶段模型图如下所示:

图3 COA 第二阶段逃离捕食者的模式图

三、COA算法流程图
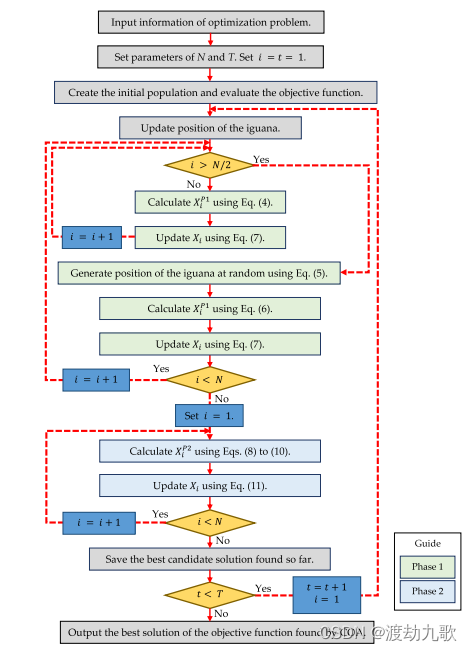
图4 COA流程图
四、COA算法运行结果
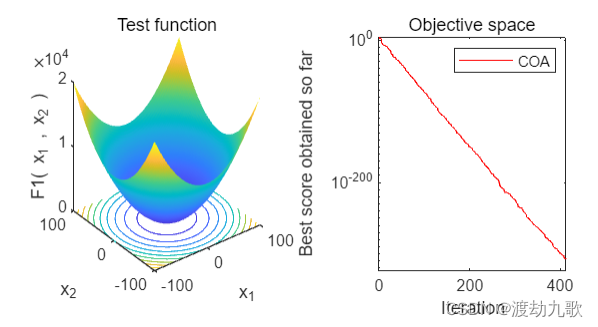
F1:
The best optimal value of the objective funciton found by COA for F1 is : 0
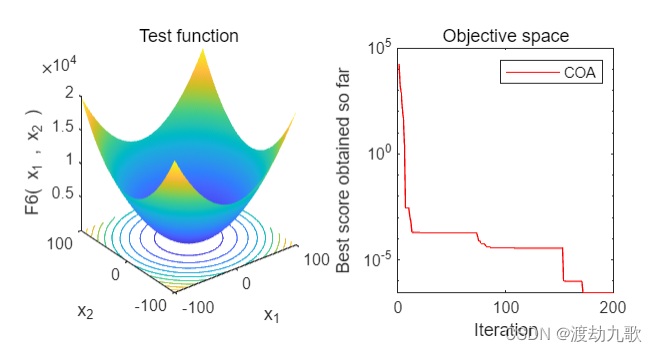
F6:
The best optimal value of the objective funciton found by COA for F6 is : 0
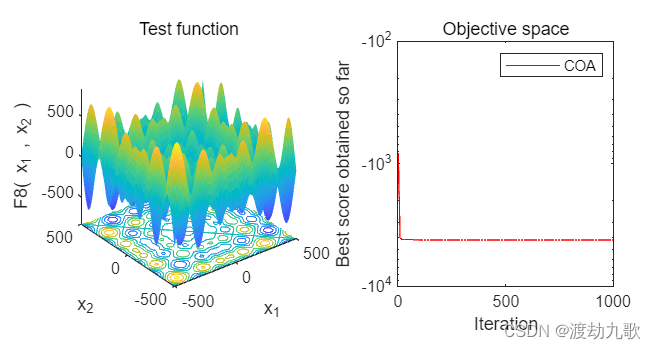
F8:
The best optimal value of the objective funciton found by COA for F8 is : -4189.828
这篇关于一种新型元启发式算法-长鼻浣熊优化算法(COA)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





