本文主要是介绍【Pytorch Lighting】第 3 章:使用预训练模型进行迁移学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
技术要求
迁移学习入门
使用预训练 ResNet-50 架构的图像分类器
准备数据
提取数据集
预处理数据集
加载数据集
构建模型
训练模型
评估模型的准确性
使用 BERT 转换器进行文本分类
收集数据
准备数据集
设置 DataLoader 实例
构建模型
自定义输入层
设置模型训练和测试
设置模型测试
训练模型
评估模型
概括
深度学习模型拥有的训练数据越多,就越准确。最引人注目的深度学习模型,例如 ImageNet,需要在数百万张图像上进行训练,并且通常需要大量的计算能力。从长远来看,用于训练 OpenAI 的 GPT3 模型的电量可以为整个城市供电。不出所料,从头开始训练这种深度学习模型的成本对于大多数项目来说都是令人望而却步的。
这就引出了一个问题:我们真的需要每次都从头开始训练深度学习模型吗?解决这个问题的一种方法,而不是从头开始训练深度学习模型,是从已经训练过的模型中借用类似主题的表示。例如,如果你想训练一个图像识别模型来检测人脸,你可以训练你的卷积神经网络( CNN ) 来学习每一层的所有表示——或者你可能会想,“世界上所有的人脸都有相似的表示,那么为什么不从其他已经在数百万张脸上训练过的模型中借用表示,并将其直接应用于我的数据集呢?” 这个简单的想法叫做迁移学习。
迁移学习是一种帮助我们利用从先前构建的模型中获得的知识的技术,该模型是为与我们的任务类似的任务而设计的。例如,要学习如何骑山地车,您可以利用以前在学习如何骑自行车时获得的知识。迁移学习不仅适用于将学习到的表示从一组图像转移到另一组图像,还适用于语言模型。
在机器学习社区中,有各种预先构建的模型,其权重由其作者共享。通过重用这些训练过的模型权重,您可以避免更长的训练时间并节省计算成本。
在本章中,我们将尝试利用现有的预训练模型来构建我们的图像分类器和文本分类器。我们将使用一种流行的称为 ResNet-50 的 CNN 架构来构建我们的图像分类器,然后使用另一种称为 BERT 的重磅变压器架构来构建一个文本分类器。本章将向您展示如何使用 PyTorch Lightning 生命周期方法以及如何使用迁移学习技术构建模型。
在本章中,我们将介绍以下主题:
- 迁移学习入门
- 使用预训练 ResNet-50 架构的图像分类器
- 使用 BERT 转换器进行文本分类
技术要求
本章的代码已经在 macOS 上使用 Anaconda 或在 Google Colab 中使用 Python 3.6 开发和测试。如果您使用的是其他环境,请对您的环境变量进行适当的更改。
在本章中,我们将主要使用以下 Python 模块,并在其版本中提及:
- PyTorch Lightning (version: 1.5.2)
- Seaborn (version: 0.11.2)
- NumPy (version: 1.21.5)
- Torch (version: 1.10.0)
- pandas (version: 1.3.5)
请将所有这些模块导入您的 Jupyter 环境。为了确保这些模块一起工作并且不会不同步,我们使用了特定版本的 torch、torchvision、torchtext、torchaudio 和 PyTorch Lightning 1.5.2。您还可以使用相互兼容的最新版 PyTorch Lightning 和torch compatible 。
!pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0 --quiet!pip install pytorch-lightning==1.5.2 --quiet如果您在导入包方面需要任何帮助,可以参考第 1 章PyTorch Lightning Adventure 。
本章的工作示例可以在此 GitHub 链接中找到:https ://github.com/PacktPublishing/Deep-Learning-with-PyTorch-Lightning/tree/main/Chapter03以下是源数据集的链接:
- 对于图像分类,我们将使用我们在第 2 章中使用的相同数据集,第一个深度学习模型起步。您可以从 Kaggle 或直接从 PCam 网站下载数据集:https://www.kaggle.com/c/histopathologic-cancer-detection。
- 对于文本分类案例,我们将使用公共卫生声明数据集。该数据集在 MIT 许可下提供:https://huggingface.co/datasets/health_fact。
该数据集包含来自各种事实核查、新闻评论和新闻网站的 12,288 篇帖子的集合。
迁移学习入门
迁移学习有许多有趣的应用,其中最引人入胜的应用之一是将图像转换为著名画家的风格,例如梵高或毕加索。

图 3.1 – 图片来源:艺术风格的神经算法 (https://arxiv.org/pdf/1508.06576v2.pdf)
前面的示例也称为Style Transfer。有很多专门的算法完成这项任务,VGG-16、ResNet 和 AlexNet一些比较流行的架构。
在本章中,我们将从使用 ResNet-50 架构在 PCam 数据集上创建一个简单的图像分类模型开始,其中包含癌症组织的图像扫描。后来,我们将构建一个文本分类模型,该模型使用来自 Transformers ( BERT )的双向编码器表示。
在这两个例子中在本章中,我们将使用预训练的模型及其权重并微调模型以使其适用于我们的数据集。预训练模型的一大优势是,由于它已经在大量数据集上进行了训练,因此我们可以在更少的时期内获得良好的结果。
任何使用迁移学习的模型通常都遵循以下结构:
- 访问预训练模型。
- 配置预训练模型。
- 构建模型。
- 训练模型。
- 评估模型的性能。
如果您之前使用过 Torch 并使用迁移学习构建了深度学习模型,您将看到与使用 PyTorch Lightning 的相似之处。唯一的区别是我们将使用 PyTorch Lightning 生命周期方法,这使事情变得更加简单和容易。
使用预训练 ResNet-50 架构的图像分类器
ResNet-50代表Residual Network,这是一种 CNN 架构,最早出现在2015 年发表在题为Deep Residual Learning for Image Recognition的计算机视觉研究论文中,作者是 Kaiming He、Xiangyu Zhang、Shaoqing Ren 和 Jian Sun。
ResNet 是目前最流行的图像相关任务架构。虽然它确实有效它非常适合图像分类问题(我们将在下面看到),它作为编码器同样适用于学习更复杂任务(如自我监督学习)的图像表示。ResNet 架构有多种变体,包括 ResNet-18、ResNet-34、ResNet-50 和 ResNet-152,具体取决于其具有的深层数。
ResNet-50 架构有 50 个深层,并在 ImageNet 数据集上进行训练,该数据集有 1400 万张图像,属于 1000 个不同的类别,包括动物、汽车、键盘、鼠标、钢笔和铅笔。以下是 ResNet-50 的架构:
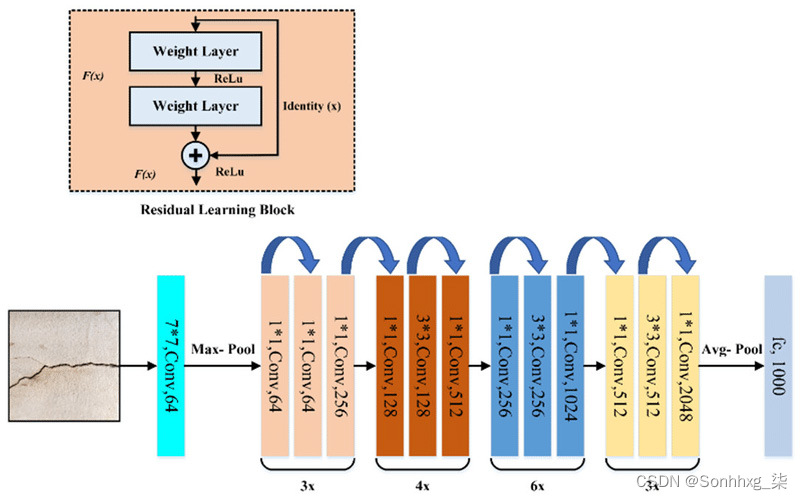
图 3.2 – VGG-16 架构(图片来源:VGG-16 论文)
在 ResNet-50 模型架构中,有 48 个卷积层以及 1 个 AvgPool 层和 1 个 MaxPool 层。
ImageNet 上的 ResNet-50 模型已经在其计算过程中训练了数周。再一次,正如引言中提到的,迁移学习的一个奇妙的好处是,我们不需要从头开始训练模型;相反,我们可以简单地使用模型的权重并引导整个过程。
在本节中,我们将使用 ResNet-50 预训练模型。我们将其配置为处理并训练我们的 PCam 图像数据集。使用预训练的 ResNet-50 模型构建我们的图像分类器基本上需要与之前详述的相同基本步骤:
- 准备数据
- 构建模型
- 训练模型
- 评估模型的准确性
让我们在以下小节中完成这些步骤。在执行任何代码之前,请安装正确版本的 PyTorch Lightning 和 opendatasets (有关说明,请参阅第 2 章,使用第一个深度学习模型起步,在收集数据集部分)。
准备数据
在 PyTorch Lightning 中有不同的方法来处理和处理数据集。一种方法是使用 PyTorch Lightning 的DataModule。现在,DataModule是一种很好的处理和结构化数据。您可以通过从 PyTorch Lightning 模块继承DataModule类来创建DataModule 。使用这个模块的一个好处是它带有一些生命周期方法。这些可以帮助我们完成数据准备的不同阶段,例如加载数据、处理数据以及设置训练、验证和测试DataLoader实例。
PyTorch Lightning 的 DataLoader 期望图像位于它们各自的子文件夹中,因此我们需要在将数据输入DataLoader实例之前对其进行预处理。我们将创建一个自定义LoadCancerDataset用于预处理数据集,我们将在后面的部分中看到。
提取数据集
在这里,我们再次使用我们在第 2 章中使用的 PCam 数据集进行组织病理学癌症检测,使用第一个深度学习模型起步。用于组织病理学癌症检测的PatchCamelyon ( PCam ) 数据集包含 327,680 种颜色从淋巴结切片的组织病理学扫描中提取的图像 (96 x 96px)。每个图像都用二进制标签进行注释,表明存在转移组织。有关数据集的更多信息,请参见:https://www.kaggle.com/c/histopathologic-cancer-detection。
以下是来自 PCam 数据集的一些示例图像:
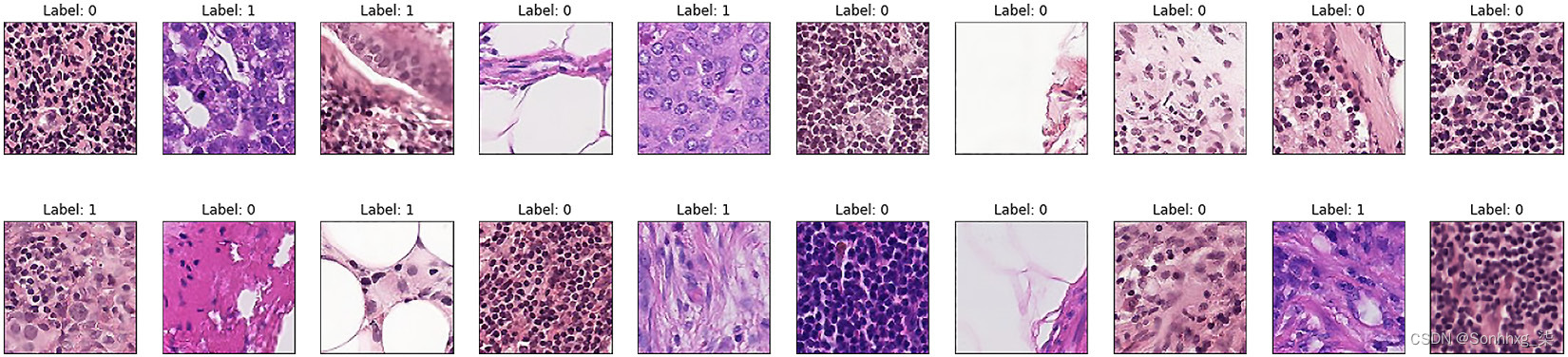
图 3.3 – 来自 PCam 数据集的 20 个带有标签的样本图像
我们将重用第 2 章中的代码,使用第一个深度学习模型起步,来加载数据集。有关如何收集数据集的说明,请参阅收集数据集部分。
收集数据集后,我们可以开始加载数据集的过程。
我们首先需要为在下采样数据中选择的图像提取标签,如下所示:
selected_image_labels = pd.DataFrame()
id_list = []
label_list = []
for img in selected_image_list:label_tuple = cancer_labels.loc[cancer_labels['id'] == img.split('.')[0]]id_list.append(label_tuple['id'].values[0])label_list.append(label_tuple['label'].values[0])在前面的代码中,我们创建了一个名为selected_image_labels的空数据框和两个名为id_list和image_list的空列表来存储图像 ID 和相应的标签。然后我们循环selected_image_list并将图像 ID 添加到id_list以及将标签添加到label_list。最后,我们将id_list和label_list这两个列表作为列添加到selected_image_labels数据框,如下所示:
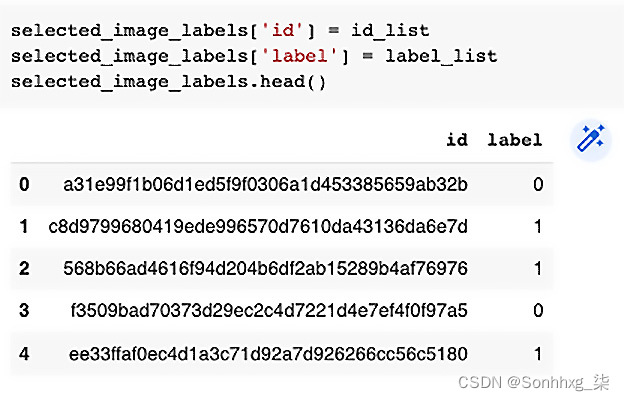
图 3.4 – 图像标签验证
数据集现在已准备好加载到 Dataloader 中。
预处理数据集
现在我们需要创建一个带有标签和 ID 的字典,将在我们的LoadCancerDataset类中使用:
img_class_dict = {k:v for k, v in zip(selected_image_labels.id, selected_image_labels.label)}上述代码从selected_image_labels数据框中提取 ID 和标签,并将它们存储在img_class_dict字典中。
创建自定义LoadCancerDataset类之前的最后一步是定义转换器,如下所示:
data_T_train = T.Compose([T.Resize(224),T.RandomHorizontalFlip(),T.ToTensor()])data_T_test = T.Compose([T.Resize(224),T.ToTensor()])在前面的代码中,我们使用torchvision 变换模块定义了训练和测试变压器。data_T_train转换器将训练图像的大小从 96 像素的原始大小调整为 224 像素,因为 ResNet-50 模型期望图像为 224 像素。我们还通过使用RandomHorizontalFlip函数来扩充训练图像,该函数将附加图像添加到训练数据集中。最后,转换器将图像转换为张量。data_T_test转换器对测试数据集执行类似的转换。
数据集现在已准备好加载到 Dataloader 中。
加载数据集
后完成所有数据预处理步骤后,我们准备创建自定义LoadCancerDataset类,以使用 DataLoader 实例准备要加载的数据:
class LoadCancerDataset(Dataset):def __init__(self, datafolder,transform = T.Compose([T.CenterCrop(32),T.ToTensor()]), labels_dict={}):self.datafolder = datafolderself.image_files_list = [s for s in os.listdir(datafolder)]self.transform = transformself.labels_dict = labels_dictself.labels = [labels_dict[i.split('.')[0]] for i in self.image_files_list]def __len__(self):return len(self.image_files_list)def __getitem__(self, idx):img_name = os.path.join(self.datafolder, self.image_files_list[idx])image = Image.open(img_name)image = self.transform(image)img_name_short = self.image_files_list[idx].split('.')[0]label = self.labels_dict[img_name_short]return image, label在前面的代码中,我们有以下内容:
- 此处定义的自定义类继承自torch.utils.data.Dataset模块。自定义LoadCancerDataset类在__init__方法中初始化,并接受三个参数:数据文件夹的路径,带有默认值的转换器将图像裁剪为 32 大小,并将其转换为张量和带有数据集标签和 ID 的字典的值。
- LoadCancerDataset读取文件夹中的所有图像,并从文件名中提取图像名称,这也是图像的 ID。
- 然后将此图像名称与带有标签和 ID 的字典中的标签进行匹配。LoadCancerDataset返回图像及其标签,然后可以在torch.utils.data的DataLoader模块中使用,因为它现在可以读取带有相应标签的图像。
我们现在将调用LoadCancerDataset的实例来加载训练和测试数据集,如下所示:
cancer_train_set = LoadCancerDataset(datafolder='/content/gdrive/My Drive/Colab Notebooks/histopathologic-cancer-detection/train_dataset/',transform=data_T_train, labels_dict=img_class_dict)cancer_test_set = LoadCancerDataset(datafolder='/content/gdrive/My Drive/Colab Notebooks/histopathologic-cancer-detection/test_dataset/',transform=data_T_test, labels_dict=img_class_dict)我们将三个必需的参数传递给我们的LoadCancerDataset类以创建cancer_train_set和cancer_test_set。第一个参数是我们之前创建的用于存储的 Google Drive 持久存储路径训练和测试图像。第二个参数是我们在上一步中创建的转换器,最后是带有图像标签和 ID 的字典。
在这个预处理之后,我们现在准备调用DataLoader模块的实例,我们在大部分章节中都广泛使用了该模块:
batch_size = 128cancer_train_dataloader = DataLoader(cancer_train_set, batch_size, num_workers=2, pin_memory=True, shuffle=True)
cancer_test_dataloader = DataLoader(cancer_test_set, batch_size, num_workers=2, pin_memory=True)如前面的代码所示,我们将批量大小设置为 128,然后使用DataLoader模块分别创建名为cancer_train_dataloader和cancer_test_dataloader的训练和测试数据加载器,该模块将自定义LoadCancerDataset类的输出作为此处的输入批量大小 (128)、worker 数量 (2) 以及自动内存固定 ( pin_memory ) 设置为True,这可以将数据快速传输到支持 CUDA 的 GPU。
至此,我们准备好了cancer_train_dataloader加载器,大约有 8,000 张图像,我们的cancer_test_dataloader加载器,大约有 2,000 张图像。所有图像的大小均为 224 x 224,转换为张量形式,并提供批量 128 张图像。我们将使用cancer_train_dataloader来训练我们的模型,并使用cancer_test_dataloader来衡量我们模型的准确性。
总而言之,我们首先执行数据工程步骤来下载、下采样和存储数据。然后,我们对数据进行预处理,为DataLoader模块做好准备,然后使用DataLoader模块为 PCam 数据集创建训练和测试数据加载器。
构建模型
如上一章所述,我们在 PyTorch Lightning 中构建的任何模型都必须继承来自闪电模块类。让我们从创建一个名为CancerImageClassifier的类开始:
class CancerImageClassifier(pl.LightningModule):ResNet-50 模型在不同的数据集上进行训练。为了使模型在 PCam 数据集上工作,我们需要对 ResNet-50 模型进行一些配置和调整,这是在模型初始化方法中完成的。
如前所述,在 ResNet-50 模型架构中,有 48 个卷积层,在卷积层之后,还有一个 MaxPool 层和一个 AvgPool 层。在上一章中,我们只使用了 2 或 3 个卷积层,所以这种架构有 50 个卷积层,它会变得更加密集。
您可以在名为ResNet50.txt的书的 GitHub 页面以及 PyTorch 上阅读 ResNet-50 架构的完整实现。
在前面的 ResNet-50 架构中,有几个卷积层,然后是 MaxPool 层和 AvgPool 层。最终分类器层的输出为1000,因为该模型是为分类 1,000 个类而构建的,但对于我们使用 PCam 数据集训练模型的用例,我们只需要 2 个类。
可以在初始化方法中对 ResNet-50 模型进行更改,使其可以处理数据集。
init方法将学习率作为输入,默认值为0.001,我们正在使用CrossEntropyloss函数来计算输入和目标之间的交叉熵损失,如下所示:
def __init__(self, learning_rate = 0.001):super().__init__()self.learning_rate = learning_rateself.loss = nn.CrossEntropyLoss()在进行迁移学习时,重要的是冻结现有层的权重以避免反向传播和重新训练,因为我们将利用现有的训练模型。ResNet-50 模型已经在数百万张图像上进行了训练,我们可以利用数据集的现有权重,因此我们冻结了权重,如下所示:
self.pretrain_model = resnet50(pretrained=True)self.pretrain_model.eval()for param in self.pretrain_model.parameters():param.requires_grad = False在前面的代码中,我们首先将 ResNet-50 模型加载为pretrain_model,该模型是从torchvision.models库中导入的。然后我们将模式更改为评估模式,使用 eval 方法将 dropout 和批量归一化层设置为评估模式。然后,我们遍历每个模型的参数并将required_grad值设置为False,以确保不会更改 ResNet-50 模型的当前权重。
现在我们需要更改 ResNet-50 模型的最后一层,以便我们可以对 PCam 数据集中的两个类别进行分类,而 ResNet-50 模型的构建是为了将其分类为 1000 个不同的类别:
self.pretrain_model.fc = nn.Linear(2048, 2)在这里,我们正在改变最后一个线性的输出,它将采用 2,048 个输入特征和返回 PCam 数据集的 2 个不同类别的 2 个概率。
重要的提示
ResNet-50 模型在所有卷积层之后,输出 2,048 个特征。最后一个线性层的输出为2,因为我们的 PCam 数据集仅包含 2 个类。
由于模型现在已准备好接受 PCam 数据集,我们将使用forward方法将数据传递给模型,如下所示:
def forward(self, input):output=self.pretrain_model(input)return outputforward方法是一个简单的函数,它将数据作为输入,将其传递给预训练模型(本例中为 ResNet-50),然后返回输出。
我们需要为CancerImageClassifier配置优化器,我们将为此覆盖configure_optimizer生命周期方法,如下所示:
def configure_optimizers(self):params = self.parameters()optimizer = optim.Adam(params=params, lr = self.learning_rate)return optimizerconfigure_optimizer方法将Adam 设置为具有__init__方法中定义的学习率的优化器。此优化器随后由configure_optimizers方法作为输出返回。
下一步是通过覆盖生命周期方法来定义训练步骤,如下所示:
def training_step(self, batch, batch_idx):inputs, targets = batchoutputs = self(inputs)preds = torch.argmax(outputs, dim=1)train_accuracy = accuracy(preds, targets)loss = self.loss(outputs, targets)self.log('train_accuracy', train_accuracy, prog_bar=True) self.log('train_loss', loss)return {"loss":loss, "train_accuracy": train_accuracy}training_step方法将批次和批次索引作为输入。然后它存储使用torch.argmax方法对这些输入进行预测,该方法返回输入张量中所有元素的最大值的索引。使用来自torchmetrics.functional模块的准确度方法通过将预测和实际目标作为输入来计算训练准确度。还使用输出和实际目标计算损失,然后记录损失和准确性。最后,training_step方法返回训练损失和训练准确率,这有助于在训练步骤中观察模型的性能。
对测试数据集重复此方法,如下所示:
def test_step(self, batch, batch_idx):inputs, targets = batchoutputs = self.forward(inputs)preds = torch.argmax(outputs, dim=1)test_accuracy = accuracy(preds, targets)loss = self.loss(outputs, targets)return {"test_loss":loss, "test_accuracy":test_accuracy}前面的代码块重复了这里为测试数据集解释的所有过程。PyTorch Lightning 框架负责在DataModule中定义的DataLoader实例之间传递正确的数据;即数据从train_DataLoader分批传到training_step,测试数据从test_DataLoader传到test_step。在training_step方法中,我们正在将输入数据传递给模型以计算并返回损失值。PyTorch Lightning 框架负责反向传播。在测试步骤中,我们使用来自torchmetrics.functional模块的预构建准确度方法计算损失和准确度值。
重要的提示
在较新版本(1.5+)中,计算精度的方法与之前版本的 PyTorch Lightning 发生了显着变化。pl.metrics.Accuracy ()函数已被弃用,因此我们现在将使用torchmetrics.functional模块中的准确度方法来计算准确度。由于这个方法需要两个参数——预测和目标,它不能再在__init__方法中定义。现在在train_step和test_step方法中调用此准确度方法。
训练和测试生命周期方法的数据均以 128 批次传递。因此,模型在 train_step 中每 128 批次数据进行一次训练,并且在train_step和train_step中也每 128 批次数据计算准确度和损失测试步骤。
因此,为了计算整个数据集的整体准确度,我们将利用一种名为test_epoch_end的生命周期方法。test_epoch_end生命周期方法在测试时期结束时调用,并输出所有测试步骤的输出,如下所示:
def test_epoch_end(self, outputs):test_outs = []for test_out in outputs:out = test_out['test_accuracy']test_outs.append(out)total_test_accuracy = torch.stack(test_outs).mean()self.log('total_test_accuracy', total_test_accuracy, on_step=False, on_epoch=True)return total_test_accuracy在test_epoch_end方法中,我们首先循环所有批次的输出并将它们存储在test_outs列表中。然后,我们使用torch.stack()函数连接各个批次的准确度的所有张量输出,并使用均值方法计算总准确度。这是计算整个测试数据集的测试准确度的推荐方法。如果需要,此方法还可用于计算完整训练和验证数据集的准确性。
训练模型
训练模型的过程与我们在上一章中看到的相同。以下是使用trainer类训练模型的代码。
请注意,以下代码使用 GPU。请确保您的环境中启用了 GPU 来执行它。如果需要,您还可以将 GPU 替换为 CPU:
model = CancerImageClassifier()
trainer = pl.Trainer(max_epochs=10, gpus=-1)
trainer.fit(model, train_dataloaders=cancer_train_dataloader)在前面的代码中,我们调用了CancerImageClassifier的实例并将其保存为模型。接下来,我们用最多 10 个 epoch 初始化训练器类并将GPU设置为-1,相当于使用了所有可用的GPU。最后,将 PCam 数据集的模型和训练数据加载器传递给fit方法。Pytorch Lightning 利用我们在DataModule类中定义的生命周期方法来访问和设置数据,并访问DataLoader实例以获取训练和测试数据。

图 3.5 – 10 个时期的训练图像分类器
此时,我们的模型正在针对 PCam 数据集进行总共 10 个 epoch 的训练。
在训练阶段,仅调用training_step生命周期方法。
评估模型的准确性
评估模型的准确性涉及测量模型的分类能力图像分为两个不同的类别。可以在测试数据集上测量准确性,如以下代码所示:
trainer.test(test_dataloaders=cancer_test_dataloader)这将产生以下输出:

图 3.6 – 测试数据集上的模型精度
在这里,我们的模型被训练了 10 个 epoch,并且在大约 2000 个测试图像上达到了 85% 的准确度得分。
总而言之,首先,我们开始使用所有必需的生命周期方法构建DataModule实例,以与第 2 章“第一个深度学习模型起步”中完全相同的方式处理和服务DataLoader实例。后来,我们通过配置和调整 ResNet-50 预训练模型来构建模型,以在 PCam 数据集上进行训练。我们在训练数据集上仅对模型进行了 10 个 epoch 的训练,并在测试数据集上测量了模型的性能。达到了 85% 的准确度分数,远高于我们在第 2 章中运行的 500 个 epoch ,使用第一个深度学习模型起步,但准确度仍然较低。这不仅仅是因为我们有了更好的模型;它也便宜得多,花费的时间和计算更少。这应该证明迁移学习对你的价值。
即使只有 10 个 epoch,我们也可以获得更好的结果,因为迁移学习使用从 ImageNet 学习的图像表示。如果没有这些表示,则需要更多的时期和超参数调整才能达到我们所做的准确度得分。
使用 BERT 转换器进行文本分类
文本分类using BERT transformers 是Google 开发的一种用于自然语言处理( NLP ) 的基于转换器的机器学习技术。BERT 已创建并由 Jacob Devlin 于 2018 年出版。前BERT,对于语言任务,通常使用半监督模型,例如递归神经网络( RNN ) 或序列模型。BERT 是第一个无监督的语言模型方法,在 NLP 任务上取得了最先进的性能。大型 BERT 模型由 24 个编码器和 16 个双向注意力头组成。它接受了约 3,000,000,000 个单词的 Book Corpora 单词和英语 Wikipedia 条目的训练。它后来扩展到 100 多种语言。使用预训练的 BERT 模型,我们可以对文本执行多项任务,例如分类、信息提取、问答、摘要、翻译和文本生成。
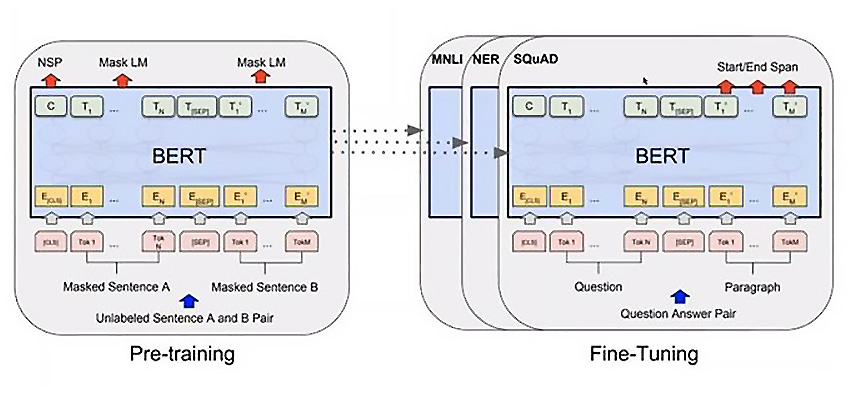
图 3.7 – BERT 架构图(图片来源:纸质用户生成数据:BERT 的致命弱点)
在本节中,我们将使用预训练的 BERT 模型构建我们的文本分类模型。在 PyTorch Lightning 中构建模型有不同的方式,我们将在本书中介绍一些不同的方式和风格来编写模型。在本节中,我们将仅使用 PyTorch Lightning 方法来构建模型。
在我们进入模型构建之前,让我们谈谈我们将用于文本分类器模型的文本数据。在本练习中,我们将使用公共卫生声明数据集。这个数据集包括来自各种事实核查、新闻评论和新闻网站的 12,288 个公共卫生声明的集合。以下是收集这些公共卫生声明的来源的完整列表:
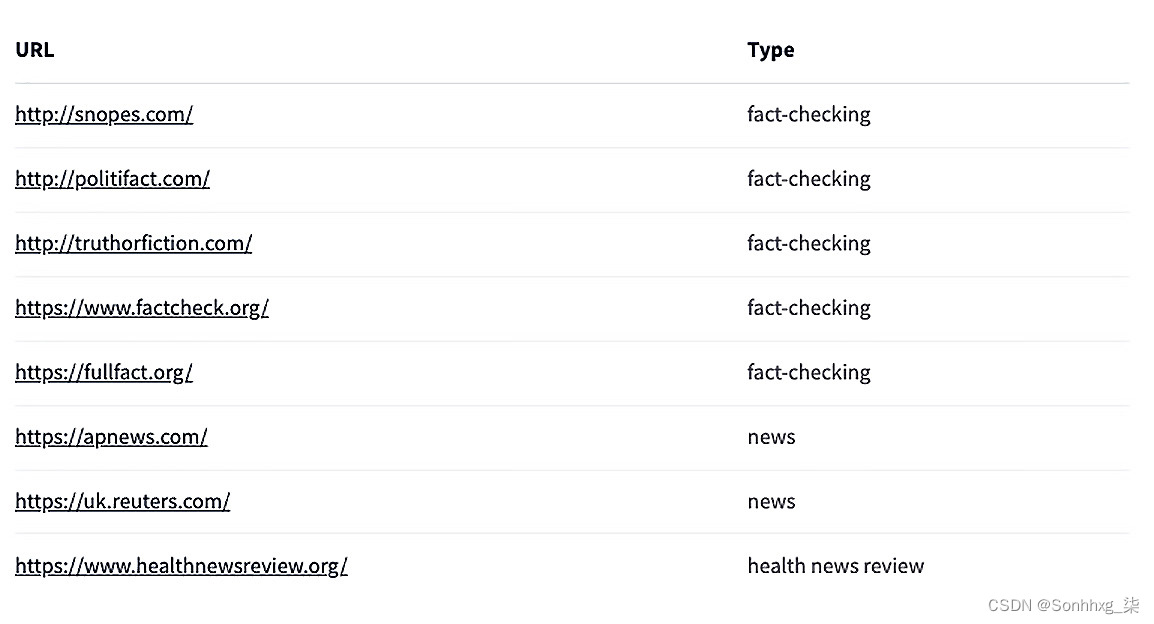
图 3.8 – 数据集中公共卫生声明的来源列表
以下是来自公共卫生声明数据集的有关抗体的一些示例文本数据检测冠状病毒及其相关标签 - 2(正确):
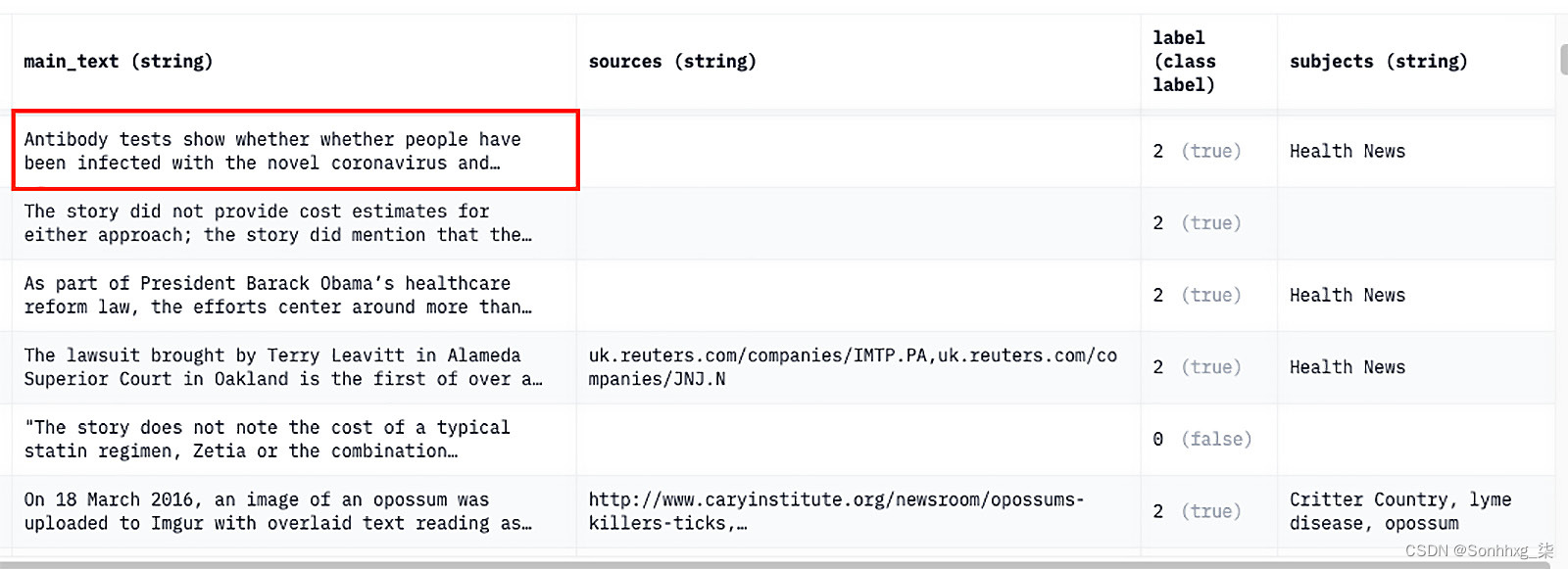
图 3.9 – 来自公共卫生声明数据集的样本文本数据
我们的目标是使用迁移学习技术和 BERT 模型将文本分为四种不同的类别——真、假、未经证实和混合。以下是步骤参与构建我们的文本分类模型:
- 收集数据
- 构建模型
- 训练模型
- 评估模型
然而,在我们开始之前,像往常一样;让我们准备好我们的环境。
我们将安装以下软件包:
!pip install pytorch-lightning==1.5.2 --quiet!pip install transformers==3.1.0 --quiet并导入它们:
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
import matplotlib.pyplot as plt
%matplotlib inline
import pytorch_lightning as pl
from torchmetrics.functional import accuracy
import transformers
from transformers import BertModel, BertConfig
from transformers import AutoModel, BertTokenizerFast
import pandas as pd收集数据
我们将从已公开的 Google Drive 链接下载数据集:
!gdown --id 1eTtRs5cUlBP5dXsx-FTAlmXuB6JQi2qj
!unzip PUBHEALTH.zip这将产生以下输出:
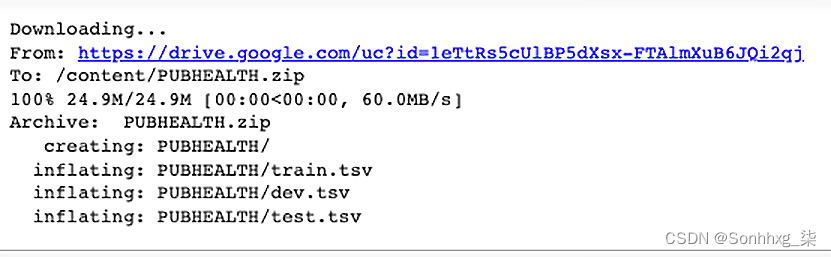
图 3.10 – 下载数据集
在前面的代码中,我们正在下载数据集,然后将其提取到 Google Colab 文件夹中。现在我们要将数据集读入 pandas 数据框:
pub_health_train = pd.read_csv("PUBHEALTH/train.tsv", sep='\t')
pub_health_test = pd.read_csv("PUBHEALTH/test.tsv", sep='\t')我们到了将train.tsv和test.tsv文件加载到名为pub_health_train和pub_health_test的 pandas 数据框中。
准备数据集
pub_health_train = pub_health_train[pub_health_train['label'] != 'snopes']
pub_health_train = pub_health_train[['main_text','label']]
pub_health_train = pub_health_train.dropna(subset=['main_text', 'label'])我们在前面的代码中执行了以下数据处理步骤:
- 只有 27 个实例将训练数据归类为“snopes”,而测试数据不包含任何此类实例,因此我们将其从训练数据集中删除。
- 然后,我们只选择感兴趣的两列——“主文本”,其中包含公共卫生声明的文本,以及“标签”列,代表各自公共卫生声明的四个类别之一。
- 最后,我们将删除在两列之一中包含缺失值的任何行。我们将对测试数据集执行相同的步骤(完整代码可在 GitHub 上获得)。

图 3.11 – 删除缺失值后的数据集视图
公共卫生声明的类别是错误的、混合的、真实的和未经证实的。这些需要将其转换为数字,以便可以从标签列表中创建张量:
pub_health_train['label'] = pub_health_train['label'].map({"true":0, "false":1, "unproven":2, "mixture":3})
pub_health_test['label'] = pub_health_test['label'].map({"true":0, "false":1, "unproven":2, "mixture":3})在这里,我们将标签从 0 映射到 4,以利用 PyTorch 闪电的prepare_data生命周期方法。
准备数据的过程可能涉及加载数据、拆分数据、转换、特征工程和许多其他活动,以提供更好的结果,更重要的是,被模型接受。到目前为止,我们已经执行了一些数据处理步骤来从原始数据集中提取相关数据。
现在,为了提取特征和加载数据,我们将利用 PyTorch Lightning 库的prepare_data生命周期方法。这种数据转换和任何特征工程都可以在我们的TextClassifier类之外完成;但是,PyTorch Lightning 允许我们将所有内容整合在一起。prepare_data生命周期方法在任何训练开始之前触发;在我们的例子中,它在其他生命周期方法之前触发,例如train_dataloader、test_dataloader、training_step和testing_step。
在prepare_data方法中,我们首先初始化BertTokenizerFast。以下是这个的代码片段:
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')# 对训练集中的序列进行标记和编码tokens_train = tokenizer.batch_encode_plus(pub_health_train["main_text"].tolist(),max_length = self.max_seq_len,pad_to_max_length=True,truncation=True,return_token_type_ids=False)# 在测试集中标记和编码序列tokens_test = tokenizer.batch_encode_plus(pub_health_test["main_text"].tolist(),max_length = self.max_seq_len,pad_to_max_length=True,truncation=True,return_token_type_ids=False)在前面的代码中,我们首先从BertTokenizerFast模块为我们的 BERT 模型初始化标记器,并将其存储为标记器对象。然后,我们使用标记器对象对pub_health_train和pub_health_test数据集中的main_text列进行标记。分词器的batch_encode_plus方法返回一个具有input_ids和attention_mask的对象。将使用input_ids和attention_mask作为我们的文本分类模型的特征。传递max_seq_len以截断超过已建立的最大序列长度的任何文本数据。pad_to_max_length参数设置为True,这意味着将填充最大序列长度之后的任何内容。训练和测试数据的标记分别存储为tokens_train和tokens_test。现在我们需要创建特征并从数据集中提取目标变量。下面的代码演示了这一点:
self.train_seq = torch.tensor(tokens_train['input_ids'])self.train_mask = torch.tensor(tokens_train['attention_mask'])self.train_y = torch.tensor(train_data["label"].tolist())self.test_seq = torch.tensor(tokens_test['input_ids'])self.test_mask = torch.tensor(tokens_test['attention_mask'])self.test_y = torch.tensor(test_data["label"].tolist())在前面的代码中,我们提取了 input_ids和attention_mask并将它们存储为训练数据集的train_seq和train_mask ,以及测试数据集的test_seq和test_mask。此外,我们正在为训练数据集创建一个目标变量train_y,为测试数据集创建一个test_y 。现在我们拥有了模型所需的所有特征和目标,它们将用于其他生命周期方法,我们将在稍后介绍。
在prepare_data生命中循环方法,我们首先加载我们的公共卫生声明数据集,对数据进行标记,并创建特征和目标变量。
设置 DataLoader 实例
我们已经完成了在prepare_data生命周期方法中加载数据、准备特征、提取目标的数据处理步骤。所以,我们现在可以使用DataLoader生命周期方法为训练和测试数据集创建DataLoader实例。以下是用于创建测试和训练DataLoader实例的生命周期方法的代码片段:
def train_dataloader(self):train_dataset = TensorDataset(self.train_seq, self.train_mask, self.train_y)self.train_dataloader_obj = DataLoader(train_dataset, batch_size=self.batch_size)return self.train_dataloader_objdef test_dataloader(self):test_dataset = TensorDataset(self.test_seq, self.test_mask, self.test_y)self.test_dataloader_obj = DataLoader(test_dataset, batch_size=self.batch_size)return self.test_dataloader_obj在前面的代码中,我们有两个生命周期方法,train_dataloader和test_dataloader。在这两种方法中,我们都在上一步中创建的特征和目标上使用TensorDataset方法来创建train_data和test_data数据集。然后,我们传递train_dataset和test_dataset数据集以使用DataLoader模块创建train_dataloader_obj和test_dataloader对象。两种方法都返回这个调用时的数据加载器对象。
构建模型
到现在为止,你应该已经熟悉了,每当我们在 PyTorch 中构建模型时Lightning,我们总是创建一个从 Lightning 模块扩展/继承的类,以便我们可以访问 Lightning 生命周期方法。
让我们首先创建一个名为HealthClaimClassifier的类,如下所示:
class HealthClaimClassifier(pl.LightningModule):我们现在将初始化HealthClaimClassifier,如下所示:
def __init__(self, max_seq_len=512, batch_size=128, learning_rate = 0.001):在上述代码中,HealthClaimClassifier接受三个输入参数:
- max_seq_len:此参数控制 BERT 模型可以处理的序列的最大长度,换句话说,就是要考虑的单词的最大长度。在这种情况下,默认值设置为512。
- batch_size:batch size 表示我们训练样本的子集,将用于训练每个 epoch 的模型。默认值为128。
- learning_rate:学习率控制着我们根据损失梯度调整网络权重的程度。默认值为0.001。
重要的提示
任何小于max_seq_len值的输入文本数据都将被填充,任何更大的文本数据都将被修剪掉。
我们现在将在__init__方法中初始化所需的变量和对象,如下所示:
super().__init__()self.learning_rate = learning_rateself.max_seq_len = max_seq_lenself.batch_size = batch_sizeself.loss = nn.CrossEntropyLoss()在__init__方法中,我们首先设置由HealthClaimClassifier接收的输入—— learning_rate、max_seq_len和batch_size。
然后我们还使用torch.nn模块中的CrossEntropyLoss函数创建了一个损失对象。我们将在本章后面部分讨论如何使用损失函数。
现在,我们将使用以下代码片段设置我们的 BERT 模型:
self.pretrain_model = AutoModel.from_pretrained('bert-base-uncased')
self.pretrain_model.eval()
for param in self.pretrain_model.parameters():param.requires_grad = False在前面的代码片段中,我们首先使用转换器的AutoModel模块将 BERT 基础未封装模型加载为pretrain_model。然后,我们将按照之前图像分类部分中看到的相同步骤进行操作。因此,我们将模型切换到评估模式,然后将所有模型参数设置为false,以冻结现有权重并防止重新训练现有层。
自定义输入层
现在我们需要调整预训练模型以接受我们自己的自定义输入,类似于我们在CancerImageClassifier模块中做了。这可以在__init__方法中完成,如下代码所示:
self.new_layers = nn.Sequential(nn.Linear(768, 512),nn.ReLU(),nn.Dropout(0.2),nn.Linear(512,4),nn.LogSoftmax(dim=1))预训练的 BERT 模型返回大小为 768 的输出,因此我们需要调整大小参数。为此,我们在前面的代码中创建了一个序列层,它由两个线性层、ReLU和LogSoftmax激活函数以及 dropout 组成。
第一个线性层接受大小为 768 的输入,这是预训练的 BERT 模型的输出大小,并返回大小为 512 的输出。
然后,第二个线性层接收第一层大小为 512 的输出,并返回输出 4,即公共卫生声明数据集中的类别总数。
这是我们文本分类器的init方法的结尾。回顾一下,主要有以下三个方面:
- 我们首先设置所需的参数和损失对象。
- 然后,我们在评估模式下初始化预训练的 BERT 模型并冻结现有的权重。
- 最后,我们通过创建与 BERT 模型一起使用的顺序层对预训练模型进行了一些调整,以返回数据集中可用的 4 种不同类别的公共卫生声明的大小为 4 的输出。
现在我们需要将预训练的 BERT 模型与我们的序列层连接起来,以便模型返回大小为 4 的输出。输入数据必须首先通过预训练的 BERT 模型,然后进入我们的顺序层。我们可以使用前向生命周期方法来连接这两个模型。我们已经在上一节和前几章中看到了forward方法,这是最好的方法,因此我们将在本书中继续使用它。
以下是forward方法的代码片段:
def forward(self, encode_id, mask):_, output= self.pretrain_model(encode_id, attention_mask=mask)output = self.new_layers(output)return output在前面的forward方法中,在prepare_data生命周期方法的 tokenize 步骤中提取的encode_id和mask被用作输入数据。它们首先传递给预训练的 BERT 模型,然后传递给我们的顺序层。forward方法返回最终顺序层的输出。
设置模型训练和测试
你应该现在熟悉了,我们再次使用training_step生命周期方法来训练我们的模型,如下面的代码块所示:
def training_step(self, batch, batch_idx):encode_id, mask, targets = batchoutputs = self(encode_id, mask)preds = torch.argmax(outputs, dim=1)train_accuracy = accuracy(preds, targets)loss = self.loss(outputs, targets)self.log('train_accuracy', train_accuracy, prog_bar=True, on_step=False, on_epoch=True)self.log('train_loss', loss, on_step=False, on_epoch=True)return {"loss":loss, 'train_accuracy': train_accuracy}在前面的training_step方法中,它以批次和批次索引作为输入。然后,将特征(encode_id和mask)以及目标传递给模型并存储输出。然后,创建preds对象以获取预测从使用torch.argmax函数的输出。此外,使用torchmetrics.functional模块中的准确度函数计算各个批次的训练准确度。除了准确率,损失也通过交叉熵损失函数计算。准确性和损失都记录在每个时期。
重要的提示
在training_step中,我们正在计算各个批次的准确度;这种准确性与完整的数据集无关。
设置模型测试
同样,我们将再次使用test_step生命周期方法来评估模型。将为此方法访问来自DataLoader测试的测试数据。准确度由于test_step方法接受来自DataLoader实例的数据批次,因此在此步骤中计算的或损失将仅与特定批次有关。因此,这一步不会计算整个测试数据集的整体准确率。如上一节所示,我们将使用名为test_epoch_end的生命周期方法来计算完整测试数据集的准确度。此方法在测试时期结束时调用,并带有所有测试步骤的输出:
def test_step(self, batch, batch_idx):encode_id, mask, targets = batchoutputs = self.forward(encode_id, mask)preds = torch.argmax(outputs, dim=1)test_accuracy = accuracy(preds, targets)loss = self.loss(outputs, targets)return {"test_loss":loss, "test_accuracy":test_accuracy}- 测试数据分批传给模型,使用torchmetrics.functional.accuracy方法计算准确率,使用交叉熵损失函数计算loss;返回损失和准确性。
- 在这里,我们可以批量访问测试数据,因此计算每个批次的准确率和损失。为了计算整个测试数据集的准确性,我们可能需要等待测试数据集被处理。这可以使用名为test_epoch_end的生命周期方法来实现。
- test_epoch_end生命周期方法是在 test_step 生命周期方法中处理完所有数据后触发的。下面是test_epoch_end方法的代码:
def test_epoch_end(self, outputs):test_outs = []for test_out in outputs:out = test_out['test_accuracy']test_outs.append(out)total_test_accuracy = torch.stack(test_outs).mean()self.log('total_test_accuracy', total_test_accuracy, on_step=False, on_epoch=True)return total_test_accuracy
训练模型
我们将再次使用我们在上一节和上一章中使用的相同过程来训练模型。下面是训练模型的代码片段:
model = HealthClaimClassifier()
trainer = pl.Trainer(max_epochs=10, gpus=-1)
trainer.fit(model)在这里,我们调用HealthClaimClassifier的一个实例作为模型,然后从 PyTorch Lightning 初始化训练器。最大 epoch 数限制为 10,我们将gpu设置为-1以使用机器上所有可用的 GPU。最后,我们将模型传递给fit方法来训练模型。PyTorch Lightning 在内部使用生命周期方法,包括我们之前创建的DataModule实例。fit方法中触发的一系列生命周期方法如下:prepare_data、train_dataloader和training_step。

图 3.12 – 为 10 个 epoch 训练一个文本分类器
我们有现在使用预训练的 BERT 模型对我们的HealthClaimClassifier进行了 10 个 epoch 的训练。下一步是在测试数据集上评估模型。
评估模型
我们将调用test_step生命周期方法来测量模型在使用以下代码测试数据集:
trainer.test()当调用训练器类中的测试方法时,会触发以下生命周期方法序列:prepare_data、test_dataloader、test_step,然后是 test_epoch_end。在最后一步中,test_epoch_end计算测试数据集的总准确率,如下所示:

图 3.13 – 完整测试数据集的文本分类器准确度
我们可以观察到,我们已经能够在测试数据集上达到 61% 的准确率,只需 10 个 epoch 并且无需任何超参数调整。HealthClaimClassifier上的模型改进练习甚至可以帮助我们通过预训练的 BERT 模型获得更好的准确性。
回顾一下,我们使用传输从 BERT 转换器模型构建了一个文本分类器模型学习。此外,我们使用 PyTorch Lightning 生命周期方法来加载数据、处理数据、设置数据加载器以及设置训练和测试步骤。使用 PyTorch Lightning 方法在HealthClaimClassifier类中实现了一切,在HealthClaimClassifier类之外没有太多数据处理。
概括
迁移学习是用于降低计算成本、节省时间和获得最佳结果的最常用方法之一。在本章中,我们学习了如何使用 ResNet-50 和使用 PyTorch Lightning 预训练的 BERT 架构构建模型。
我们已经构建了一个图像分类器和一个文本分类器,并且在此过程中,我们介绍了一些有用的 PyTorch Lightning 生命周期方法。我们已经学会了如何利用预训练模型以更少的努力和更少的训练时期来处理我们定制的数据集。即使模型调整很少,我们也能够达到不错的准确性。
虽然迁移学习方法效果很好,但也应牢记它们的局限性。它们非常适合语言模型,因为给定数据集的文本通常由与核心训练集中相同的英语单词组成。当核心训练集与给定数据集有很大不同时,性能就会受到影响。例如,如果您想构建一个图像分类器来识别蜜蜂,而 ImageNet 数据集中没有蜜蜂,那么您的迁移学习模型的准确性会更弱。您可能需要进行完整的培训选择。
这篇关于【Pytorch Lighting】第 3 章:使用预训练模型进行迁移学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






