本文主要是介绍[23] T^3Bench: Benchmarking Current Progress in Text-to-3D Generation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

- 3D生成蓬勃发展,主流方法通过事例比较和用户调查来评价方法好坏,缺少客观比较指标;
- 本文提出
Bench,首次综合比较了不同生成方法;
- 具体来说,本文设计了质量评估(Quality Assessment)和对齐评估(Alignment Assessment),前者评价生成物体的质量,后者评价生成物体与文本的对齐程度;
- 针对质量评估,本文提出一种多视角ImageReward的评估方法。具体来说,本文以3D物体为中心,构建二阶二十面体(level-2 icosahedron),以多面体顶点为相机位置渲染161张图片。考虑到顶部和底部不适合评价3D模型,本文提出一种regional convolution mechanism,基于图建模多面体顶点对应分数,并平滑局部区域分数。
- 针对对齐评估,本文提出一种3D Caption + GPT4的评估方法。具体来说,本文以3D物体为中心,构建零阶二十面体,渲染12张图片。用BLIP描述每张图片,并用GPT-4融合这些描述,得到物体的3D描述。本文设计Prompt让GPT-4评价3D Caption和给定文本的匹配程度。
- 最终,作者通过与真实用户评分进行相关性检验,验证了所提评估方法的有效性。
Method
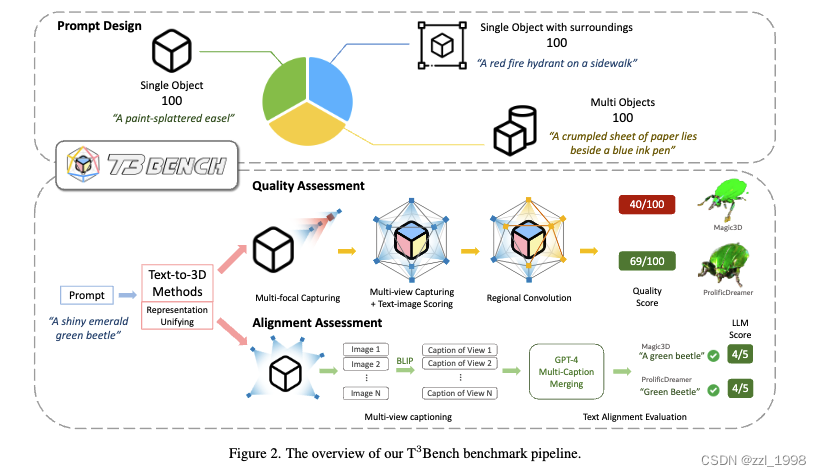
Prompt Design
- 本文设计了三组提示词,包括:单个物体(single object),具有环境描述的单个物体(Single object with surroundings)和多个物体(Multiple objects)。
- 首先用GPT-4生成候选提示词,人工筛选掉专有名词和地名。随后,用ROUGE-L去除相似的提示词。最终,得到N个不同的提示词。
Unified 3D Representation
- 考虑到应用便捷性,本文选择Mesh作为评估3D表征。
- 有两种方法将NeRF转换为Mesh:DMTet和Marching Cube,本文选择性能较好的那个进行评估。
Evaluation Metrics
Quality Assessment
- Mesh Normalization. 将3D场景缩放至[-1, 1]之间。
- Multi-Focal Capturing. 设计了5种不同的focla lengths,选择文本-图片匹配分数最高的作为该点分数。
- Multi-View Capturing. 以物体为中心,构建二阶二十面体(level-2 icosahedron),以多面体顶点为相机位置渲染161张图片。
- Scoring and Regional Convolution. 将二十面体视作图,顶点为渲染图片评价分数。通过下列工作递归求得区域均值。其中,
是第
点的相邻点。递归三次后,取最高分作为3D生成物体的最终评价分数。
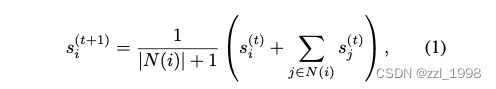
Alignment Assessment
- 本文以3D物体为中心,构建零阶二十面体,渲染12张图片。
- 用BLIP描述每张图片,并用GPT-4融合这些描述,得到物体的3D Caption。本文设计Prompt让GPT-4评价3D Caption和给定文本的匹配程度。
- 考虑到BLIP描述中会引入额外的细节,会导致与给定文本不匹配,分数降低。因此,本文设计了特定的prompt,让GPT-4仅考虑:给定文本中的特征,是否存在于3D Caption中。以下为测试样例:
Prompt: You are an assessment expert responsible for prompt-prediction pairs. Your task is to score the prediction according to the following requirements:
1. Evaluate the recall, or how well the prediction covers the information in the prompt. If the prediction contains information that does not appear in the prompt, it should not be considered as bad.
2. If the prediction contains correct information about color or features in the prompt, you should also consider raising your score.
3. Assign a score between 1 and 5, with 5 being the highest. Do not provide a complete answer; give the score in the format: 3
Prompt: A photographer is capturing a beautiful butterfly with his camera
Prediction: A man photographing a butterfly near a tree and map, surrounded by plants
Answer: 4
Experiments
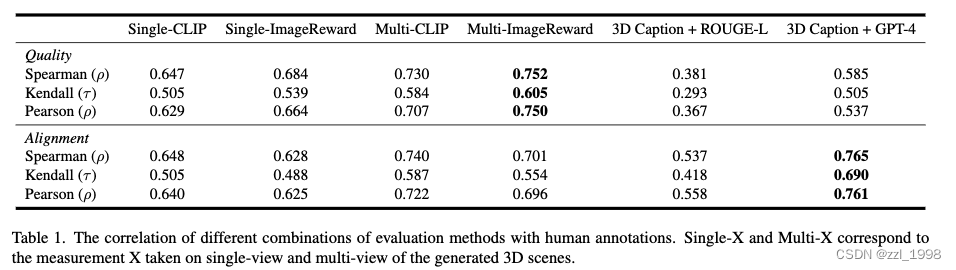
Metric Evaluation
- 本文首先让评估专家,对6种3D生成方法的30%生成结果进行打分,得到1080个分数。
- 本文用Spearman's
,Kendall's
和Pearon's
Benchmarking Results
- Experimental Setup. 本文为3组提示词,每组生成100个提示词,得到最终300个提示词。基于ThreeStudio测试了DreamFusion,Magic3D,LatentNeRF,Fantasia3D,SJC和ProlificDreamer。渲染图片分辨率为512 x 512。对SJC,Magic3D和Fantasia3D使用DMTet提取Mesh,其他方法使用Marching Cube algorithm。
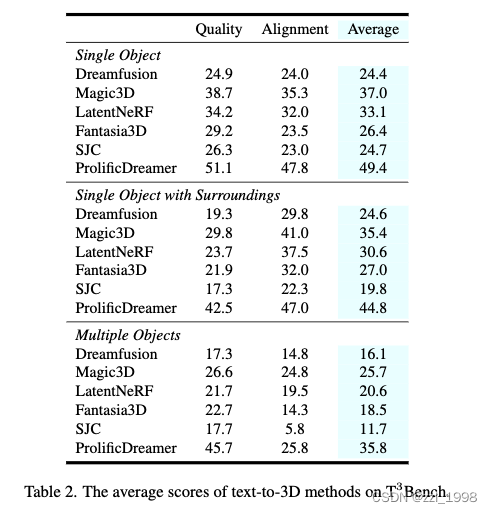
- Comparison of different methods. 1)Dreamfusion:生成纹理较差,不能生成较复杂的几何;2)Magic3D和LatentNeRF:受益于coarse-to-refine策略,但是对环境和多物体生成效果较差;3)SJC:场景中噪声较多,较难提取高质量3D mesh;4)Fantasia3D:对复杂场景较难生成准确几何;5)ProfilifcDreamer:VSD引入了大量不想管信息或几何噪声,随着目标数量增加,导致评价指标下降。
2D Guidance Analysis
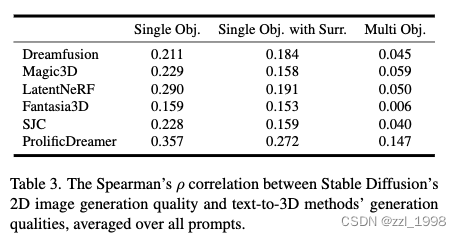
- 本文用相同的提示词生成图像,并计算图像分数和3D物体分数的Spearman相关性系数。
- 实验发现,所有相关性都较弱。1)在text-to-3D中生成效果较好的方法,相关性系数更高;2)在Single Object比Single Object with Surroundings好,进一步优于Multiple Objects。本文认为,SD在多数时间可以生成合理的2D图像,却无法生成合理的3D物体,这说明现有2D引导词不适用于text-to-3D方法。text-to-3D的瓶颈在于2D guidance的view consistency,而不是SD本身的生成能力。
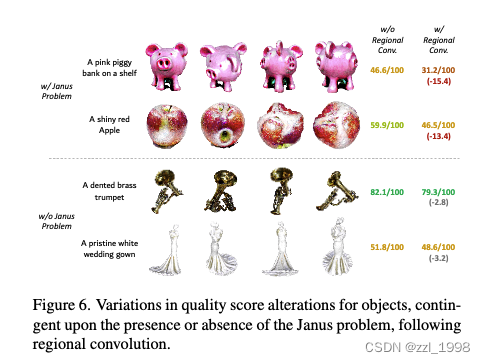
Multi-view Inconsistency Analysis
- 当前评分可以较好反应多脸问题(Janus Problem)
More Results of Test Prompts



这篇关于[23] T^3Bench: Benchmarking Current Progress in Text-to-3D Generation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







