benchmarking专题

论文翻译:Benchmarking Large Language Models in Retrieval-Augmented Generation
https://ojs.aaai.org/index.php/AAAI/article/view/29728 检索增强型生成中的大型语言模型基准测试 文章目录 检索增强型生成中的大型语言模型基准测试摘要1 引言2 相关工作3 检索增强型生成基准RAG所需能力数据构建评估指标 4实验设置噪声鲁棒性结果负面拒绝测试平台结果信息整合测试平台结果反事实鲁棒性测试平台结果 5 结论 摘要

Apache HTTP server benchmarking tool(ab)-服务器基准测试工具一文上手
这是一个非常简单的工具,用途比较有限,只能针对单个URL进行尽可能快的压力测试。 Windows下如何下载安装(Linux安装十分简单) Apache HTTP server benchmarking tool(ab)下载地址 资源 2.4版本 httpd-2.4.48-o111k-x64-vc15.zip 解压移动至C盘 管理员身份运行CMD,进入bin目录,执行

ios Benchmarking
计算代码执行时间 第一种: CFTimeInterval startTime = CACurrentMediaTime();CFTimeInterval endTime = CACurrentMediaTime();endTime - startTime; 第二种:dispatch_benchmark(黑科技,不要发布,不要发布,不要发布,自己测试用即可) 这个方法没有被公开声明,需要
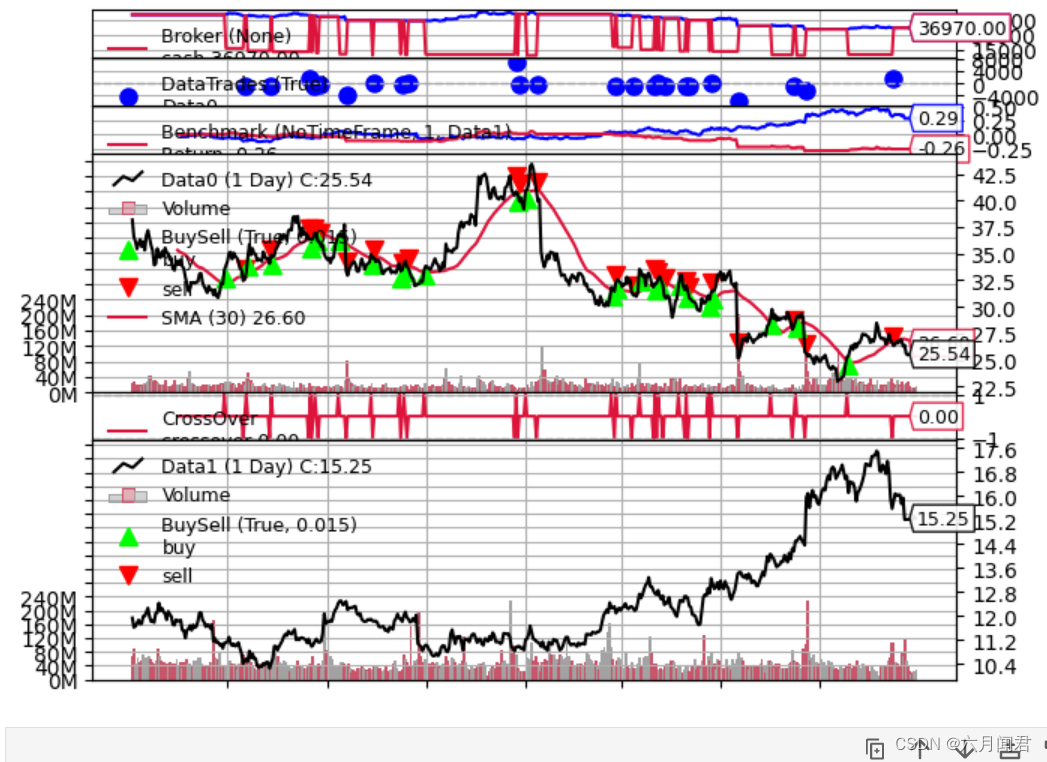
Backtrader 文档学习- Observers - Benchmarking
Backtrader 文档学习- Observers - Benchmarking 1.概述 backtrader包括两种不同类型的对象,可以帮助跟踪: Observers 观察者Analyzers 分析器 在分析器领域中,已有TimeReturn对象,用于跟踪整个组合价值(即包括现金)的回报率的演变。 显然作为观察者,在添加一些基准测试的同时,还可做一些工作,将观察者和分析器组合在一起,

【PyRestTest】进行Benchmarking测试
PyRestTest支持通过Curl请求本身收集比较差的网络环境下的性能指标。 基准测试:它们扩展了测试中的配置元素,允许你进行相似的REST调用配置。然而,它们不对HTTP响应情况进行验证,它只收集指标数据。 下列选项被指定用于benchmark: warmup_runs:如果没有指定该选项,默认为10。在开始收集数据之前,多次运行这个基准测试调用,以允许JVM warmup、缓存等。be

Benchmarking Denoising Algorithms with Real Photographs_CVPR2017
Abstract 1、在过往研究中,图像去噪算法缺少无噪声的真值,而人为构建的噪声模型不真实,效果不好。 2、作者的思路:构建有噪图&对应的无噪图的成对真实数据集。 Amber:这是很硬核的做实事的思路,实现过程必然遇到很多工程问题。 获取有噪图和对应无噪图的方法:不同 ISO +适当调整曝光时长为获得真值的后处理步骤 基于异方差 Tobit 回归模型的线性强度变换来校正空间错位,处

【文献阅读】3-MOABB: trustworthy algorithm benchmarking for BCIs 2018
系列文章目录 EEG的相关文献阅读—第一篇 综述类 EEG的相关文献阅读—第二篇 BCI应用 MOABB:关于脑机接口的可信算法的基准测试 系列文章目录摘要关键词背景创新点方法实验结论与不足参考 摘要 摘要部分通过四个小标题来分块完成:Objective,Approach,Main results,Significance。本文建立于MNE工具包【文献13】【文献14】,

Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Diet Architecture Benchmarking
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Diet Architecture Benchmarking Sara - Rasa 演示机器人 DIET 论文 https://arxiv.org/pdf/2004.09936.pdf Sara - Rasa 演示机器人github:https://github.com/RasaHQ/rasa-demo Sara - Rasa
![[23] T^3Bench: Benchmarking Current Progress in Text-to-3D Generation](https://img-blog.csdnimg.cn/3138c2fb35ee4adb8d30bcaf423a72e6.png)
[23] T^3Bench: Benchmarking Current Progress in Text-to-3D Generation
3D生成蓬勃发展,主流方法通过事例比较和用户调查来评价方法好坏,缺少客观比较指标;本文提出Bench,首次综合比较了不同生成方法;具体来说,本文设计了质量评估(Quality Assessment)和对齐评估(Alignment Assessment),前者评价生成物体的质量,后者评价生成物体与文本的对齐程度;针对质量评估,本文提出一种多视角ImageReward的评估方法。具体来说,本文以3

Benchmarking Chinese Text Recognition: Datasets, Baselines| OCR 中文数据集【论文翻译】
基础信息如下 https://arxiv.org/pdf/2112.15093.pdfhttps://github.com/FudanVI/benchmarking-chinese-text-recognition Abstract 深度学习蓬勃发展的局面见证了近年来文本识别领域的迅速发展。然而,现有的文本识别方法主要针对英文文本。作为另一种广泛使用的语言,中文文本识别在各个领域都有广泛