本文主要是介绍Discovering Exfiltration Paths Using Reinforcement Learning with Attack Graphs(2022),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Discovering Exfiltration Paths Using Reinforcement Learning with Attack Graphs(2022)
- 一、介绍
- 二、RL
- 三、MDP构建攻击图
- 四、实验评估
- 五、总结
一、介绍
文章提出了一种在攻击图中发现渗透路径的RL方法,在攻击图的动态模型中对基于服务的防御性网络结构进行建模,发现最优的N条攻击路径。
二、RL
RL通过与环境交互来学习,描述了一组近似动态规划的求解方法,环境通常通过MDP建模,被定义为一个五元组{状态,动作,状态-动作对,概率转移函数,期望的奖励函数}。
目前主要的两种RL方式:
- 基于值:他们试图找到或近似最佳值函数,这是一个动作和一个值之间的映射。 值越高,动作越好。 最著名的算法是Q学习及其所有增强的方法, 例如Deep Q Networks,Double Dueling Q Networks等。
- 基于策略的:基于策略的算法(例如“ 策略梯度” 和REINFORCE)尝试直接找到最佳策略,而无需Q值作为中间步骤。
当这两个算法流行以后,下一个显而易见的步骤是……尝试合并它们。 这就是演员——评论家的诞生方式。 演员评论家旨在利用基于价值和基于策略的优点,同时消除其弊端。
主要思想是将模型分为两部分:一个用于基于状态计算动作,另一个用于估计动作的Q值。
参与者演员可以是类似于神经网络的函数逼近器,其任务是针对给定状态产生最佳动作。 当然,它可以是全连接的神经网络,也可以是卷积或其他任何东西。 评论家是另一个函数逼近器,它接收参与者输入的环境和动作作为输入,将它们连接起来并输出评分值(Q值)。
Q值实际上可以分解为两部分:状态值函数V(s)和优势值A(s,a):
Q(s,a)= V(s)+ A(s,a)
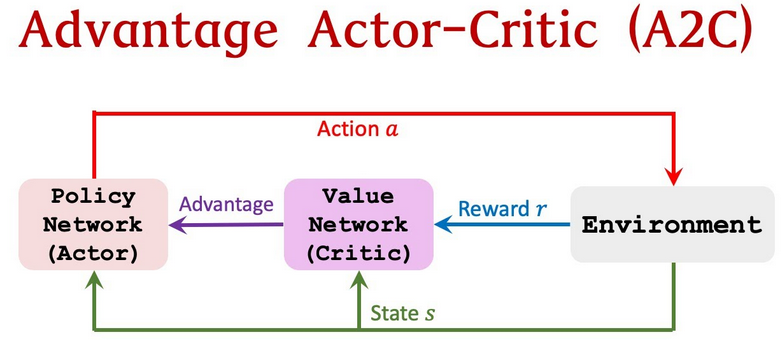
本文使用基于RL的渗透测试双代理模型:一个用于迭代扫描网络以建立结构模型,另一个用于利用所建模型。其中两个代理都是A2C,我们与标准A2C算法进行比较。
三、MDP构建攻击图
攻击图对计算机漏洞和利用所形成的网络进行建模,创建一个不一定与物理网络拓扑结构相匹配的抽象。
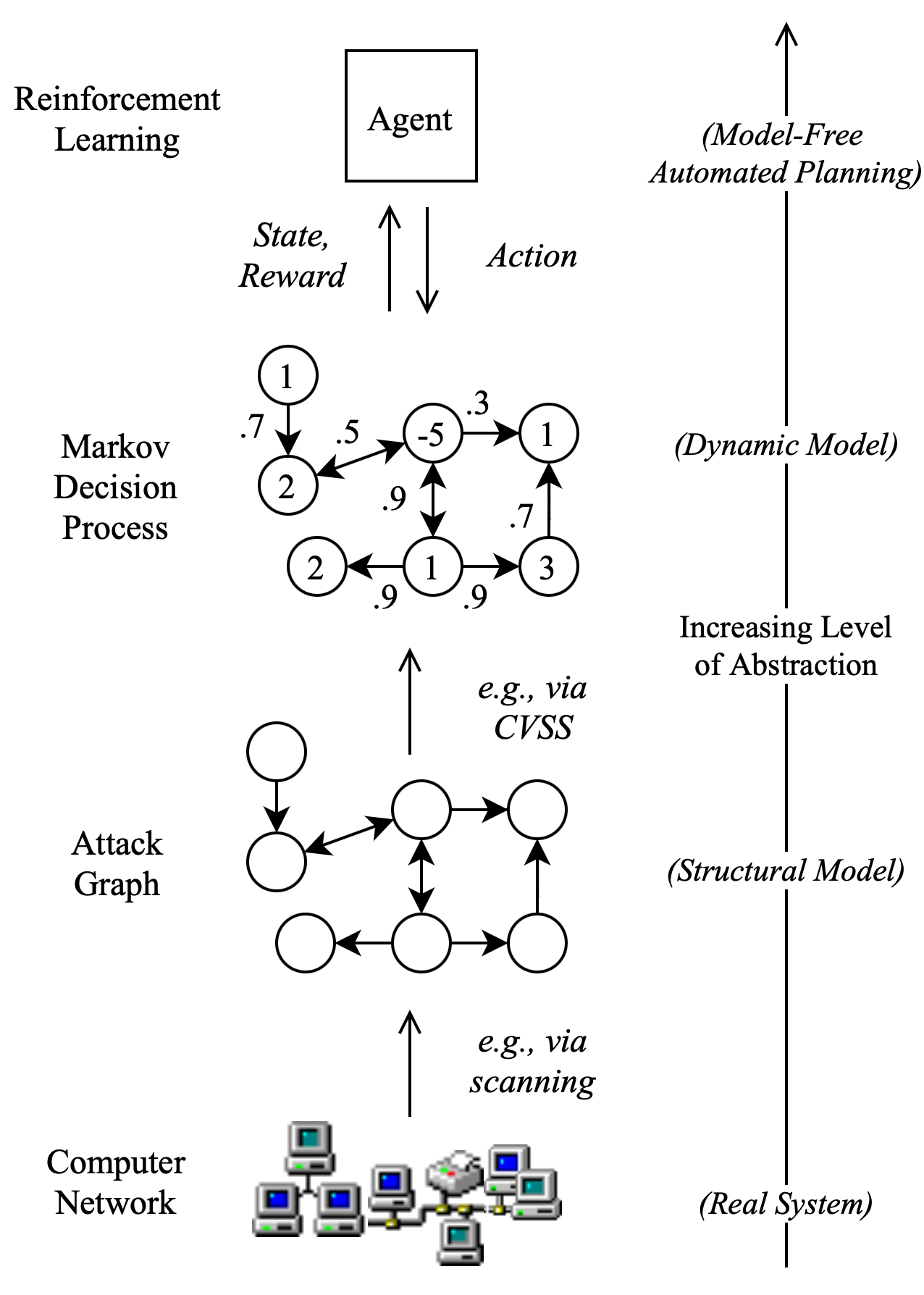
部分可观察的马尔科夫决策过程(POMDP)被认为是比MDP更现实的计算机网络表示。在POMDP中,行动是随机的,网络结构和配置是不确定的。但是,POMDP 还没有被证明可以扩展到大型网络,并且需要对许多先验概率分布进行建模。
CVSS正在成为在攻击图上为RL建立MDP模型的标准方法,虽然CVSS评分在实践中很有用,而且目前被认为是行业标准,但重要的是要记住,威胁严重程度的衡量标准不等于风险的衡量标准,它们不能概括地提供对评估通过网络的整个攻击路径有用的信息。从攻击者的角度来看,更大的风险意味着更大的被发现的机会。虽然在这里的模型中,漏洞的CVSS评分确实告知了任何特定的利用的成功概率,但RL代理行为的真正驱动力应该是围绕着网络拓扑。
我们提出了一种在CVSS-MDP中对基于服务的防御地形进行建模的新方法。我们不在MDP的状态中明确定义防御,而是做出类似于人类攻击者的假设:即使攻击者不能直接检测到防御,但根据他们的经验,他们可以根据特定主机上的服务来推断防御的存在。常见的网络防御措施可以包括基于主机的防病毒和恶意软件检测软件,子网间路由器防火墙,或认证日志跟踪。
本文的渗出路径发现方法使用多个终端状态,对应于各种感兴趣的出口节点,只有一个初始节点。然后,代理人以一系列独立事件的方式与网络互动,以了解哪个是预期回报的最佳出口节点。为了给使用该工具的网络运营商提供一个全面的路径分析,通过迭代求解MDP以找到最佳出口节点,移除最佳出口节点,并再次求解MDP,从而找到前N个出口节点。

四、实验评估
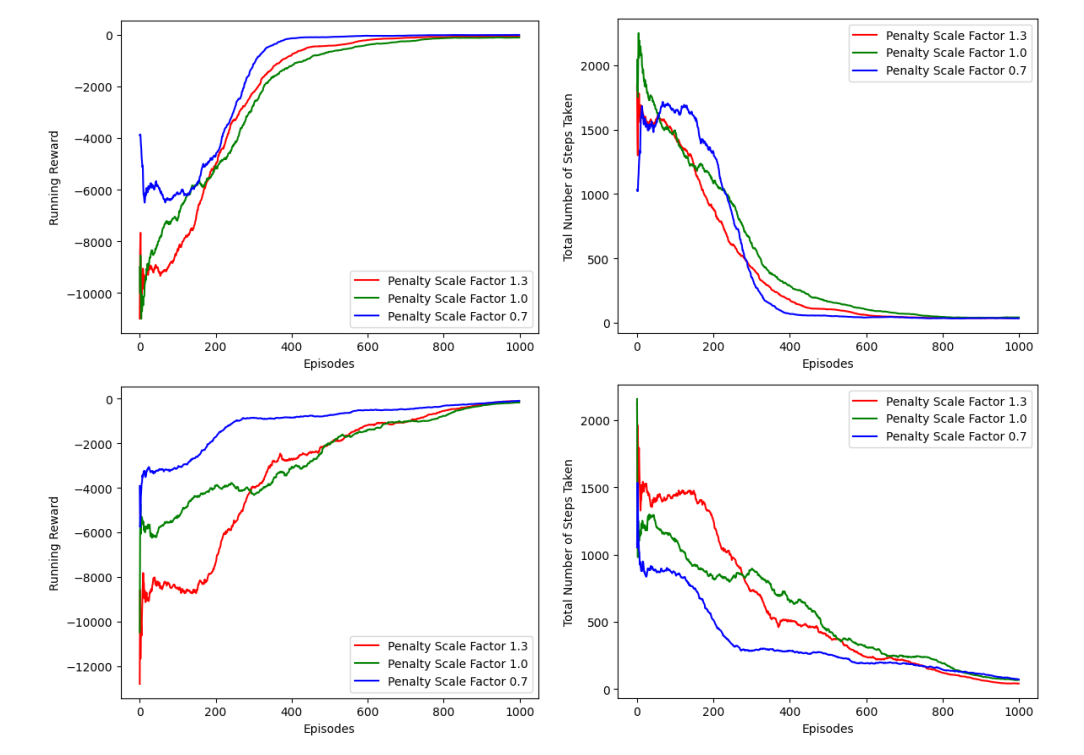
左边的图显示了每关的平均奖励,右边的图显示了每关的平均步骤数。上面的图是使用A2C代理运行RL的结果,下面的图是利用双重代理方法的结果。线条的颜色反映了代理人在避免被发现方面受到的激励程度:绿色表示风险中立,蓝色表示接受风险,红色表示风险规避。“episode”是强化学习agent在环境里面执行某个策略从开始到结束这一过程。
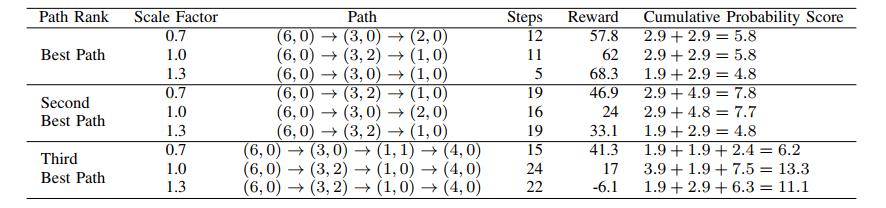
这里是双重代理发现的前3个渗透路径。比例系数表示风险接受(0.7)、风险中立(1.0)和风险规避(1.3)的服务惩罚比例。路径给出了从初始节点到退出节点的最短路径,它来自于收敛代理在一个事件中采取的行动集合。相比之下,步骤和奖励指的是代理人在一个情节中的最佳表现(即,不仅仅是为形成路径而采取的行动)。累积概率得分报告了一个自定义的、类似于CVSS的漏洞评分的路径。
五、总结
本文为安全从业者和网络维护者提供了一种使用RL的定量方法,以确定数据泄露的最佳路径。实验中所提出的RL方法确定了在数据泄露时最可能使用的主机和服务,并获取了网络风险评估中使用的指标。通过识别模仿现实世界漏洞的故意网络错误配置,验证了这种方法的优势。
这篇关于Discovering Exfiltration Paths Using Reinforcement Learning with Attack Graphs(2022)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









