本文主要是介绍SVM分类---识别舰船和飞机,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SVM介绍
SVM网上已经有说的非常好的,有浅显易懂的也有从最基础的公式上一步步推导的,参考大神July的这篇关于SVM的博客,希望深入了解的可以看看这篇讲的非常好。
一、线性分类器:
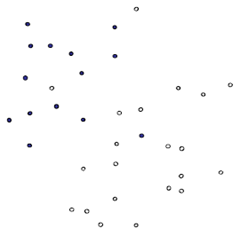
首先给出一个非常非常简单的分类问题(线性可分),我们要用一条直线,将下图中黑色的点和白色的点分开,很显然,图上的这条直线就是我们要求的直线之一(可以有无数条这样的直线)
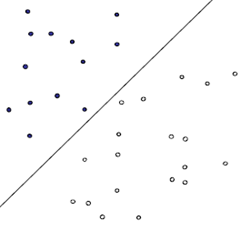
刚刚说了,我们令黑色白色两类的点分别为+1, -1,所以当有一个新的点x需要预测属于哪个分类的时候,我们用sgn(f(x)),就可以预测了,sgn表示符号函数,当f(x) > 0的时候,sgn(f(x)) = +1, 当f(x) < 0的时候sgn(f(x)) = –1。

一个很直观的感受是,让这条直线到给定样本中最近的点最远,这句话读起来比较拗口,下面给出几个图,来说明一下:
第一种分法:
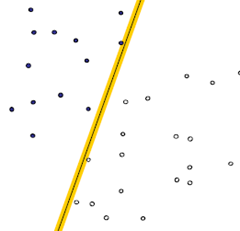
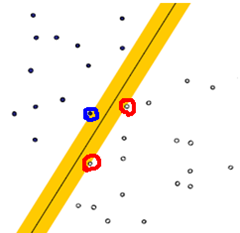
这两种分法哪种更好呢?从直观上来说,就是分割的间隙越大越好,把两个类别的点分得越开越好。就像我们平时判断一个人是男还是女,就是很难出现分错的情况,这就是男、女两个类别之间的间隙非常的大导致的,让我们可以更准确的进行分类。在SVM中,称为Maximum Marginal,是SVM的一个理论基础之一。选择使得间隙最大的函数作为分割平面是由很多道理的,比如说从概率的角度上来说,就是使得置信度最小的点置信度最大(听起来很拗口),从实践的角度来说,这样的效果非常好,等等。这里就不展开讲,作为一个结论就ok了,:)
上图被红色和蓝色的线圈出来的点就是所谓的支持向量(support vector)。
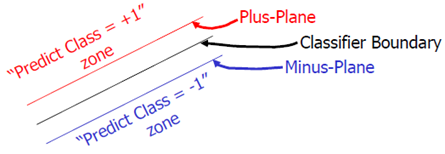
上图就是一个对之前说的类别中的间隙的一个描述。Classifier Boundary就是f(x),红色和蓝色的线(plus plane与minus plane)就是support vector所在的面,红色、蓝色线之间的间隙就是我们要最大化的分类间的间隙。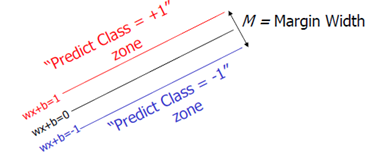
这里直接给出M的式子: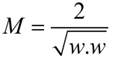
另外支持向量位于wx + b = 1与wx + b = -1的直线上,我们在前面乘上一个该点所属的类别y(还记得吗?y不是+1就是-1),就可以得到支持向量的表达式为:y(wx + b) = 1,这样就可以更简单的将支持向量表示出来了。
当支持向量确定下来的时候,分割函数就确定下来了,两个问题是等价的。得到支持向量,还有一个作用是,让支持向量后方那些点就不用参与计算了。这点在后面将会更详细的讲讲。
在这个小节的最后,给出我们要优化求解的表达式:
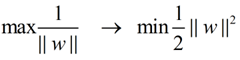
||w||的意思是w的二范数,跟上面的M表达式的分母是一个意思,之前得到,M = 2 / ||w||,最大化这个式子等价于最小化||w||, 另外由于||w||是一个单调函数,我们可以对其加入平方,和前面的系数,熟悉的同学应该很容易就看出来了,这个式子是为了方便求导。
这个式子有还有一些限制条件,完整的写下来,应该是这样的:(原问题)
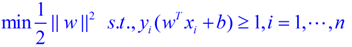
s.t的意思是subject to,也就是在后面这个限制条件下的意思,这个词在svm的论文里面非常容易见到。这个其实是一个带约束的二次规划(quadratic programming, QP)问题,是一个凸问题,凸问题就是指的不会有局部最优解,可以想象一个漏斗,不管我们开始的时候将一个小球放在漏斗的什么位置,这个小球最终一定可以掉出漏斗,也就是得到全局最优解。s.t.后面的限制条件可以看做是一个凸多面体,我们要做的就是在这个凸多面体中找到最优解。这些问题这里不展开,因为展开的话,一本书也写不完。如果有疑问请看看wikipedia。
二、转化为对偶问题,并优化求解:
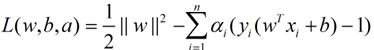
求解这个式子的过程需要拉格朗日对偶性的相关知识(另外pluskid也有一篇文章专门讲这个问题),并且有一定的公式推导,如果不感兴趣,可以直接跳到后面用蓝色公式表示的结论,该部分推导主要参考自plukids的文章。
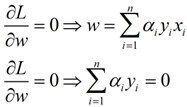
首先让L关于w,b最小化,分别令L关于w,b的偏导数为0,得到关于原问题的一个表达式
将两式带回L(w,b,a)得到对偶问题的表达式
新问题加上其限制条件是(对偶问题):
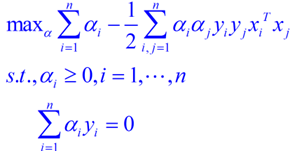
这个就是我们需要最终优化的式子。至此,得到了线性可分问题的优化式子。
求解这个式子,有很多的方法,比如SMO等等,个人认为,求解这样的一个带约束的凸优化问题与得到这个凸优化问题是比较独立的两件事情,所以在这篇文章中准备完全不涉及如何求解这个话题,如果之后有时间可以补上一篇文章来谈谈:)。
三、线性不可分的情况:
接下来谈谈线性不可分的情况,因为线性可分这种假设实在是太有局限性了:
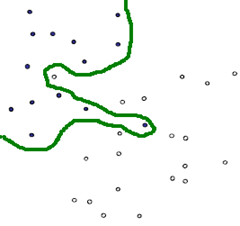
下图就是一个典型的线性不可分的分类图,我们没有办法用一条直线去将其分成两个区域,每个区域只包含一种颜色的点。
要想在这种情况下的分类器,有两种方式,一种是用曲线去将其完全分开,曲线就是一种非线性的情况,跟核函数有一定的关系:
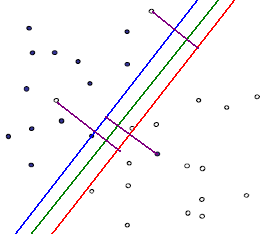
另外一种还是用直线,不过不用去保证可分性,就是包容那些分错的情况,不过我们得加入惩罚函数,使得点分错的情况越合理越好。其实在很多时候,不是在训练的时候分类函数越完美越好,因为训练函数中有些数据本来就是噪声,可能就是在人工加上分类标签的时候加错了,如果我们在训练(学习)的时候把这些错误的点学习到了,那么模型在下次碰到这些错误情况的时候就难免出错了(假如老师给你讲课的时候,某个知识点讲错了,你还信以为真了,那么在考试的时候就难免出错)。这种学习的时候学到了“噪声”的过程就是一个过拟合(over-fitting),这在机器学习中是一个大忌,我们宁愿少学一些内容,也坚决杜绝多学一些错误的知识。还是回到主题,用直线怎么去分割线性不可分的点:
我们可以为分错的点加上一点惩罚,对一个分错的点的惩罚函数就是这个点到其正确位置的距离:
公式中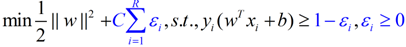
接下来就是同样的,求解一个拉格朗日对偶问题,得到一个原问题的对偶问题的表达式:
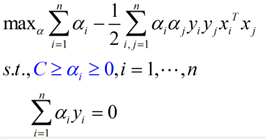
蓝色的部分是与线性可分的对偶问题表达式的不同之处。在线性不可分情况下得到的对偶问题,不同的地方就是α的范围从[0, +∞),变为了[0, C],增加的惩罚ε没有为对偶问题增加什么复杂度。
四、多分类问题:
上面所谈到的分类都是2分类的情况,当N分类的情况下,主要有两种方式,一种是1 vs (N – 1)一种是1 vs 1,前一种方法我们需要训练N个分类器,第i个分类器是看看是属于分类i还是属于分类i的补集(出去i的N-1个分类)。
后一种方式我们需要训练N * (N – 1) / 2个分类器,分类器(i,j)能够判断某个点是属于i还是属于j。
这种处理方式不仅在SVM中会用到,在很多其他的分类中也是被广泛用到,从林教授(libsvm的作者)的结论来看,1 vs 1的方式要优于1 vs (N – 1)。
应用SVM分类舰船和飞机
使用Matlab自带的SVM分类其来进行舰船和飞机的分类,舰船和飞机的样本如下图所示:
舰船包含多类,比如航母,驱逐舰,潜艇等,飞机也有比如战斗机,直升机等等.对于二分类问题来说,只需要将所有的舰船和飞机的样本放一起就可以了.
(1)提取特征
我们使用了Gabor滤波来进行形状和纹理的提取,原因就是基于直观的映像,飞机和检查"长得"差别很大,至于如何使用Gabor滤波,可以参照这个,我也会将我使用的Gabor代码上传.
Gabor滤波提取的特征长度为4400,按照列来进行存储.
(2)应用SVM分类器
SVM分类代码:
%% load the test data and do SVM classification
group = svmclassify(svmClassifier,test_all_data');svmClassifier是SVM的分类器:
%% SVM TRAIN
labels = [ship_label;plane_label];
train_all_data = [ship_data';plane_data'];
svmClassifier = svmtrain(train_all_data,labels);ship_label和plane_label是相应的标签,大小为1xN的行向量,ship_data和plane_data是相应的Gabor特征向量,大小为4400*N.
如果我们将舰船label设置为0,飞机设置为1,则SVM会输出两个值1或者0.
(3)实际效果
我的数据集是舰船图片514张,飞机320张,测试集合总共50张,可以做到86%左右的成功率(对了43张),效果还是可以的
PS:我的整个代码已经上传CSDN,可以点击这里下载
参考:
[1]Gabor滤波
[2]SVM简介
[3]SVM
这篇关于SVM分类---识别舰船和飞机的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






