本文主要是介绍读论文,第八天:Recognition of Human Arm Gestures Using Myo Armband for the Game of Hand Cricket,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
手势识别是生物机器人技术领域的最新进展。本文提出了一种基于低成本传感器的手板球游戏手势识别技术。手板球在南亚国家是一种流行的游戏,它涉及到使用人类的手指手势来得分。这个游戏通常在两个玩家之间进行。每个玩家都有一个预先定义的手势来表示得分1、2、3、4和6。这两名球员都必须戴着Myo的袖章。Myo臂带用于捕获在每一个肌肉动作中触发的生物电位。在这个游戏中执行的各种手势会触发各种肌肉群信号。一个数据集是通过收集每个玩家的每个手势的8个通道生物电位来创建的。对所得到的数据集进行了预处理和特征提取。现在,机器学习技术在数据集中执行,以最高的精度对所有五种不同的手势进行分类。支持向量机(SVM)对两名玩家的数据集进行分类提供了最大的精度。两家参与者的效率分别为92%和84%。该系统利用两名玩家获得的数据集进行训练,并在两台计算机上的两台MATLAB的帮助下实时玩游戏。随着数据的分类,个人玩家的分数被计算和显示。通过显示的分数,我们可以确定得分最高的玩家,并可以确定游戏的获胜者。
介绍
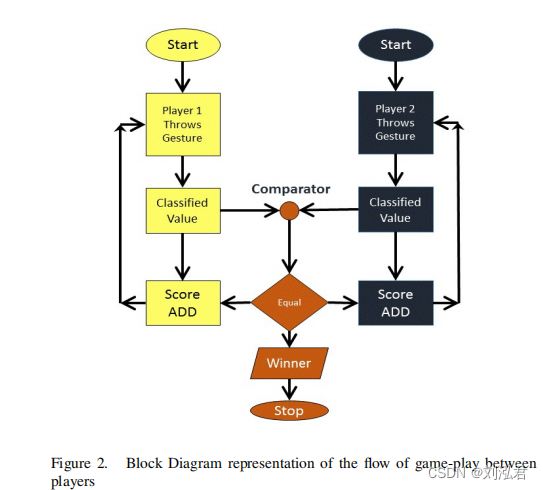
手板球是一种不需要任何外部物理环境的板球形式。这个游戏需要两个人类玩家来做出真正能计算分数的手势。这个游戏类似于石头剪刀布的[8]。该游戏包括使用带有重要意义的手势(称为“投掷”),由两名玩家同时投掷。两个玩家在每款游戏中都使用一只手。预先定义的手势对应于分数1、2、3、4和6。这些分数的计算是为了确定比赛的获胜者。每个玩家的得分相加,直到两个玩家做出相同的手势。
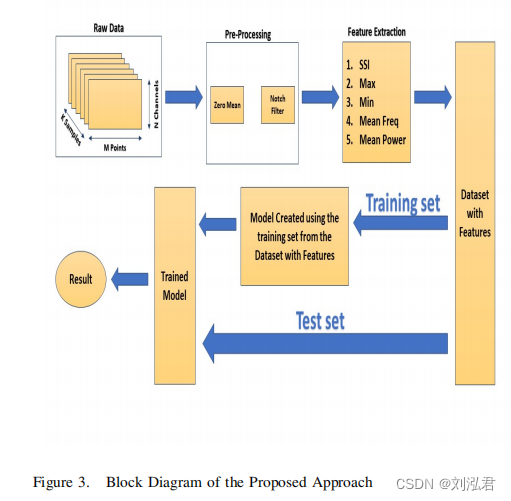
手势模式包括触发人类手臂中的某些肌肉群。这种触发机制在人类手臂[10]中诱导了一种生物潜能。这些信号被Myo臂标捕获。Myo臂带是一个由8个通道和16个电极组成的臂带。myo臂带是丘脑实验室[5]公司的产品。每当人类手臂有任何运动,包括人类手指的运动,都会触发特定的肌肉群。Myo的臂带在包装盒中带有一个蓝牙功能。这个蓝牙模块用于将数据无线地发送到计算机上。然后对捕获的信号进行过滤和处理,从而给出与每个手势对应的清晰数据集。通过定义的手势,为游戏中的两个玩家收集数据集。这个数据集的收集是训练代理清楚地识别每个玩家的手势的初始过程。数据集最初是为40个实例玩家的每个手势收集的。数据集被过滤,以消除所有不需要的噪声和不需要的信号,而不导致任何手势。对数据集的过滤是分类的第二大最重要的任务。过滤有助于减少数据集,也提高了分类器的效率。在这个方案中执行的各种过滤技术是直流偏移去除和缺口滤波器。特征提取技术用于提取在给定的过滤数据集中对应于特定手势的特定特征。简单平方积分、最小值、最大值、平均频率和平均功率是特征提取方法,改进了待分类的数据集。
机器学习技术有助于将这五种手势分别进行分类。该方法采用支持向量机(SVM)作为分类算法。SVM对这两名玩家的数据集进行了分类。在执行了预处理和特征提取技术后,支持向量机现在可以很容易地对类进行最高效的分类。该模型通过机器学习技术进行训练。这些训练后的数据被用作对实时获得的信号进行分类的参考。
MATLAB软件有两台计算机。在两台计算机中的matatlab是必要的,以便计算和比较两个玩家的分数。实时数据的处理时间在计算机中需要一点时间,我们需要两个人来玩游戏。这有助于计算机比较分数,并确定玩家是否“退出”,游戏是否被终止。这个记分牌的计算是必要的,以确定比赛的获胜者。
MYO
利用表面肌电图电极收集肌电图信号。作者[6]提出了生物无线电在美国手语检测的人类手势方面的局限性。还激发了一个新的设备“妙臂带”来收集数据。数据采集采用了myo臂带的8个通道。作者使用了Myo服务器Matlab函数,有效地实现了数据收集。关于石头剪刀布[8]游戏的论文,作者使用Myo臂标的手势,如拳头,展开的手势作为石头和纸,并添加了额外的手势来描述剪刀。在这种情况下,作者只考虑了三个类。该系统由用户定义的投掷1、2、3、4和六的手势组成。所以这个数据集由五个类组成。玩家抛出的每一个动作都会通过各种预处理算法来传递。预处理算法有助于去除不需要的信号和对任何类都没有显著贡献的信号。
提出的方法
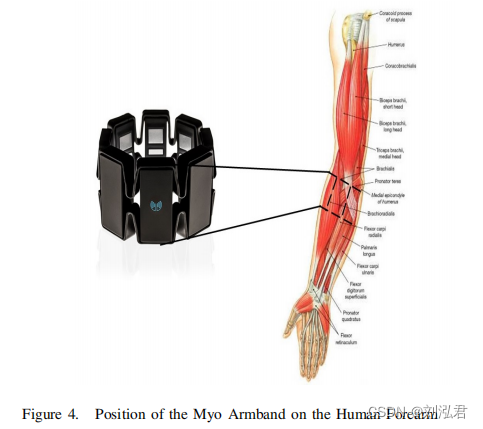
每当人类图4抛出任何手势时。Myo臂带在人类前臂臂上的位置,在肌肉群[3]中存在一种生物电位。这些生物电势被myo臂带捕获。Myo臂带由8个通道组成,不同肌肉群触发的信号可以识别在不同的通道中。肌臂带通常放置在人类手腕的凸起处。肌臂带的8个通道在各自的肌肉群中自动缩短。这个位置被标记,臂带的位置是参考初始位置。这样做是为了防止被触发的信号中的差异。上图4描述了肌臂带连接的肌肉群。myo臂带由预定义的功能组成,可用于各种应用。
从人体手臂上收集到的肌电图生物电位由各种噪声和其他信号组成。应去除这些噪声和其他信号,以便获得一个干净的和处理过的数据,这有助于提高分类算法的准确性。该方法采用直流偏移去除滤波器和凹槽滤波器来提高所得信号的质量。
特征提取是改进数据集的过程。这通常是通过获取数据的特定部分来完成的,这赋予了一个特定手势的高度意义。该技术提高了用于对不同手势进行分类的分类器的效率。
结果
如前面提到的关于数据收集的数据,实时收集来自受试者的数据也是为了做一个大小的手势(8个通道x400个实例x1次迭代)。该数据集经过了过滤和预处理技术,最后提取了其特征。提取特征后,将数据集发送到预测器,然后预测器预测响应。这项研究只有两名玩游戏的受试者。
这篇关于读论文,第八天:Recognition of Human Arm Gestures Using Myo Armband for the Game of Hand Cricket的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)