本文主要是介绍随机森林评价变量重要性可以无条件信任吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
很多生态环境类的文章会不加思考地利用随机森林对变量的重要性进行评价,似乎随机森林是万金油一般可以解决一切的变量重要性的问题,下面我们可以利用代码说明随机森林的局限之处。
1. 代码思路与实现:
- 生成三个自变量,x1, x2 ,x3:每个自变量根据正态分布(mean = 0, sd = 1)随机生成100个数值;
x1 <- rnorm(100,mean = 0,sd = 1)
x2 <- rnorm(100,mean = 0,sd = 1)
x3 <- rnorm(100,mean = 0,sd = 1)
- 根据某一函数规则,将自变量转化为中间变量y1, y2, y3。其中:
y 1 = 1.2 x 1 + 0.3 y 2 = − x 2 2 + 0.8 x 2 + 0.2 y 3 = { 0.2 ( x 3 < 0.5 ) 2 x 3 + 0.2 ( x 3 ≥ 0.5 ) \begin{aligned} &y_1 = 1.2x_1+0.3 \\ &y_2 = -x_2^2 + 0.8x_2 +0.2\\ &y_3=\left\{ \begin{aligned} &0.2 (x_3<0.5)\\ &2x_3+0.2(x_3\geq0.5) \\ \end{aligned} \right. \end{aligned} y1=1.2x1+0.3y2=−x22+0.8x2+0.2y3={0.2(x3<0.5)2x3+0.2(x3≥0.5)
y1 <- 1.2*x1+0.3
y2 <- -x2^2 + 0.8*x2 +0.5
y3 <- ifelse(x3<0.5,0.2,2*x3+0.2)
- 生成最终的因变量: y = y 1 + y 2 + y 3 y = y_1+y_2+y_3 y=y1+y2+y3
y=y1+y2+y3
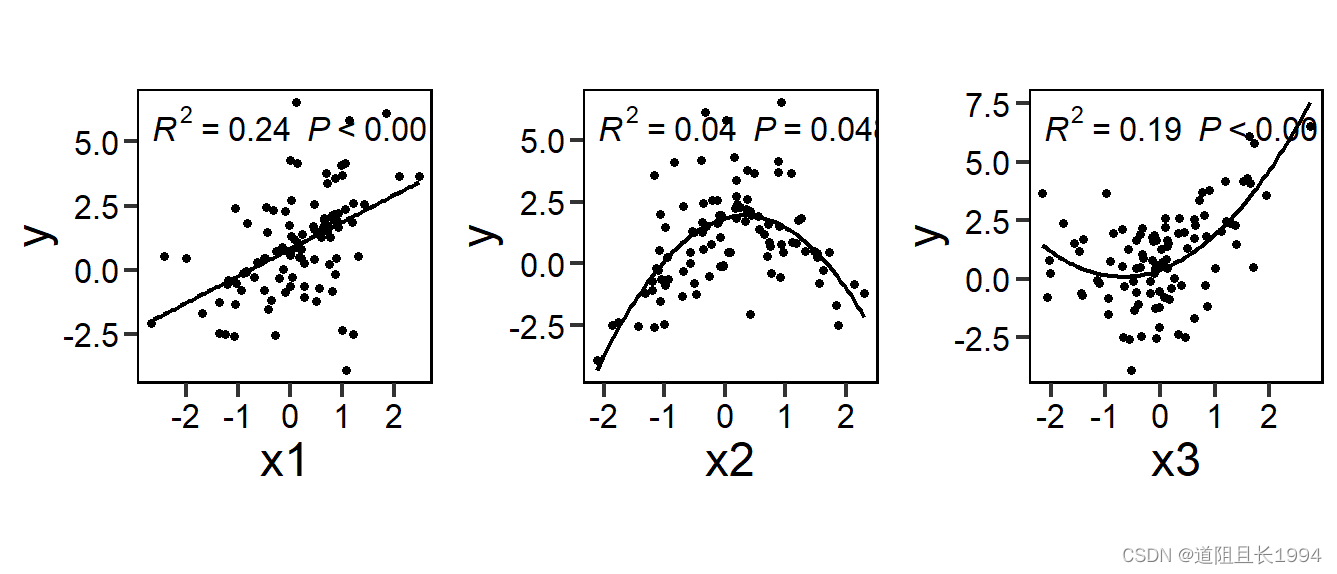
2. 自变量与因变量的统计关系
3. 利用随机森林评价变量重要性
library(randomForest)
rf <- randomForest(y~.,data=df,importance=TRUE,ntree=5000)
importance(rf, scale = TRUE)

随机森林得到的结果是 x 3 x_3 x3 最为重要。 x 1 x_1 x1与 x 2 x_2 x2的作用相差不大。
4. 生成机理的角度: y 1 y_1 y1, y 2 y_2 y2, y 3 y_3 y3与 y y y的关系
cor(y1,y)
[1] 0.4859979
cor(y2,y)
[1] 0.6067846
cor(y3,y)
[1] 0.6012034
可见, y 2 y_2 y2与 y y y的相关性最大,联系最为紧密,因此实际上 x 2 x_2 x2对 y y y的影响最大,这与随机森林的结果并不一致。
5.统计关系的角度: R 2 R^2 R2
随机森林得到的结果是 x 3 x_3 x3 最为重要,但 x 3 x_3 x3的 R 2 R^2 R2低于 x 1 x_1 x1的 R 2 R^2 R2,与随机森林的结果也不相符。
6. 结论
虽然随机森林被广泛用于评价变量的重要性,但其结果并不一定能反映真实的变量重要性。理解过程的原理(专业知识确定自变量与因变量的函数关系,再利用统计方法来确定参数)依然是重中之重,不能过分依赖机器学习。随机森林可以作为探索数据的重要工具,但不能对其获得的结果无条件信任,或许其它机器学习算法应用于生态环境研究时也有同样的问题。
资源链接:随机森林评价变量重要性可以无条件信任吗?R分析与可视化代码
这篇关于随机森林评价变量重要性可以无条件信任吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







