本文主要是介绍【论文阅读】EasyEdit:Editing Large Language Models: Problems, Methods, and Opportunities (三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【论文阅读】EasyEdit:Editing Large Language Models: Problems, Methods, and Opportunities
文章目录
- 【论文阅读】EasyEdit:Editing Large Language Models: Problems, Methods, and Opportunities
- 续
- 7. 相关工作
- 7.1 llm知识
- 7.2 终身学习和非学习
- 7.3 llm的安全和隐私
- 8. 总结
- 9. 局限性
- 9.1 编辑范围
- 9.2 编辑黑盒LLM
- 9.3 上下文编辑
续
(一)https://blog.csdn.net/qq_51392112/article/details/133748914
(二)https://blog.csdn.net/qq_51392112/article/details/133768337
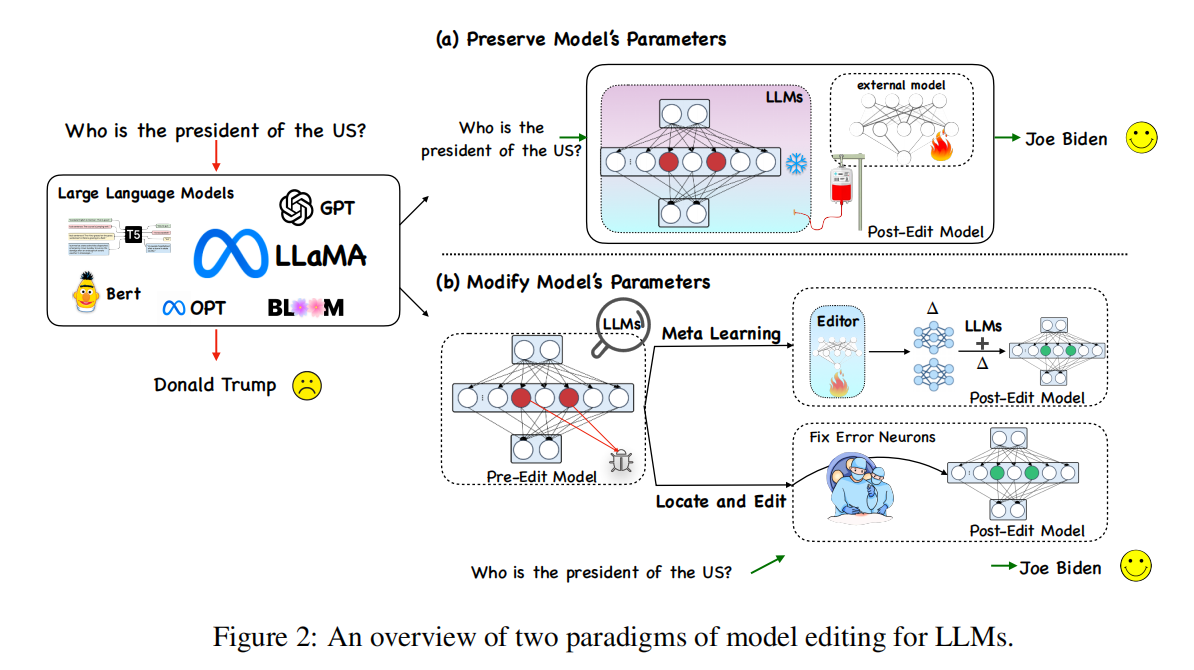
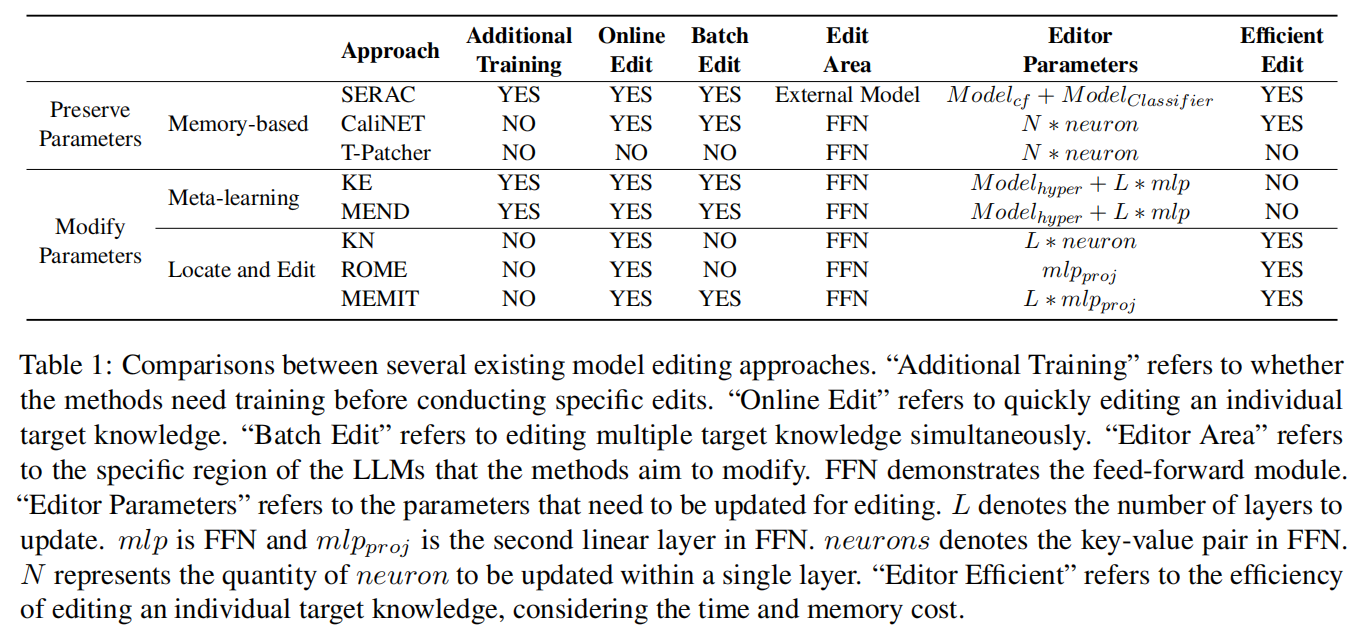
7. 相关工作
7.1 llm知识
几种模型编辑方法的目的是精确地识别存储在plm中的知识,并直接地改变模型的参数的。现有的工作正在研究plm如何存储知识的原则(Geva等人,2021,2022年;Haviv等人,2023年;Hao等人,2021年;埃尔南德斯等人,2023年;姚等人,2023年;曹等人,2023年),这有助于模型编辑过程。此外,模型编辑技术(操作外部知识)与知识增强方法也很相似,因为更新模型的知识也可以被认为是向模型中注入了新的知识。知识增强(张等,2019年;刘易斯等,2020;20张等,2022;安永等,2021;姚等人,2022)通常涉及通过提供外部或更新信息直接丰富模型,以应对目标任务,如问答(Chang等人,2020;陈等人,2017)。这种方法通常使用于模型现有知识不足,通常涉及训练融合模块(Wang et al.,2021)。
- 然而,模型编辑的目的是精确地修复和更新llm中的知识,绕过与训练一个全新的模型相关的计算负荷。
7.2 终身学习和非学习
模型编辑侧重于有针对性的更新和新知识组合,这对于最小的变化是有效的,而且通常需要更少的资源。另一方面,持续学习(Bi西亚尔斯卡等人,2020)增强了模型在不同任务和领域的适应能力,但它需要广泛的训练和更新,因此更适合学习广泛的任务和知识领域。Zhu等人(2020)采用持续学习方法更新中的知识边缘,证明了持续学习在模型编辑中的有效性。与此同时,正如Hase等人(2023)所指出的,一个模型忘记敏感知识(例如,私人数据)很重要,类似于机器遗忘的概念(Wu等人,2022;Tarun等人,2021年)。模型编辑可以看作是终身学习和不学习的统一特殊情况,模型能够自适应地、不断地添加和编辑新知识,同时也可以去除过时和错误的知识。
7.3 llm的安全和隐私
先前的工作(Carrini等人,2020;Shen等人,2023)注意到,语言模型可能基于某些提示直接生成不可靠或个人样本。删除存储在大型语言模型(llm)中的私有和潜在有害信息的任务对于增强基于llm的应用程序的隐私性和安全性至关重要(Sun et al.,2023)。值得注意的是,Geva等人(2022)观察到,模型编辑可以抑制llm产生有毒或有害的语言,这表明模型编辑可以在解决与llm相关的安全和隐私问题方面发挥关键作用。
8. 总结
本文强调llm的编辑,系统地定义问题,提供各种方法的实证分析,并提出潜在的机会。作者的目标是帮助研究人员对现有模型编辑策略的特征、优势和缺点进行更深入的理解。作者的发现突出了未来发展的充足空间,特别是在可移植性、本地化性和效率等领域。鉴于在llm上投入的大量资源,高效的模型编辑技术可以提供更有效地反映他们所服务的人的更新需求和价值观的潜力。作者希望作者的工作能有助于解决正在进行的问题,并激发未来的研究。
9. 局限性
在本文中,仍然没有涉及到模型编辑的几个方面。
9.1 编辑范围
值得注意的是,模型编辑的应用不仅仅是事实上下文,强调了它巨大的潜力。诸如个性、情感、观点和信念等元素也在模型编辑的范围内。虽然这些方面已经进行了一些探索,但它们仍然存在相对未知的地区,因此在本文中没有详细介绍。此外,多语言编辑(Xu et al.,2022)代表了一个必要的研究方向,值得未来的关注和探索。
9.2 编辑黑盒LLM
与此同时,像ChatGPT和GPT-4这样的模型在广泛的自然语言任务中表现出显著的性能,但只能通过api访问。这就提出了一个重要的问题:作者如何编辑这些“黑箱”模型,它们在下游使用过程中也往往会产生不良的输出?目前,有一些工作利用上下文学习(Onoe等人,2023年)和基于提示的方法(Murty等人,2022年)来修改这些模型。它们在每个示例之前都有一个指定自适应目标的文本提示,这显示了作为模型编辑技术的前景。
9.3 上下文编辑
给定一个精炼的知识上下文(指令)作为提示符,该模型可以生成与所提供的知识相对应的输出。然而,这种方法可能会遇到上下文中介失败,因为语言模型可能不能一致地生成与提示符对齐的文本。此外,这些方法不能修改模型的内在知识,因为它需要每次预先文本进行编辑。值得注意的是,之前的研究表明,指导llm可以帮助回忆已经从之前学到的概念
这篇关于【论文阅读】EasyEdit:Editing Large Language Models: Problems, Methods, and Opportunities (三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
