本文主要是介绍[Excel]k-means聚類算法的應用,以評價現有供應商的水平為例。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
聚類算法系列中,k-means聚類算法是基礎,其屬於非監督式分類算法( Unsupervised Classification)。
所謂"非監督式",即是針對一堆未知標籤的數據集做分類,結果只會告知哪些數據屬於同一群體。換句話說,只有一堆輸入數據,但無定義輸出變量,常應用於對既有數據的內在分類的探討,如對顧客購買行為的分類。
k-means聚類算法的原理,係利用數據與和質心的歐式距離為判斷依據,不斷迭代直到預設收斂值,最終取得分類結果。其中輸入變量如下:
1.預計劃分為多少群體,即k值。
2.給訂初始質心值。
3.預設收斂值,一般可用新質心和舊質心的距離小於多少來定義。
在企業營運中,供應商的優劣對公司營運有著舉足輕重的角色,因此各產業的質量體系中,往往有一個章節提及供應商評價的內容,如同IATF16949和ISO9001質量體系。一般會以三項指標QCD來評價供應商的優劣。
Q:數據來源可以是由不良批次、客訴件數或是產線停線頻次的權重組合轉換而來。
C:數據來源可以是原物料單價或每年配合降價的幅度的權重組合轉換而來。
D:數據來源可以是準時卻未達量或是準時按量的頻次的權重組合轉換而來。
前提是各供應商的數據基礎必須一致,分析結果才有參考價值。
假設供應商的原始評價數據如表一,其分數定義為,該項指標越有競爭力,分數越高,滿分100分。

a.為了避免各項指標可能因絕對數據差異過大而造成結果失真,針對表一的原始數據做歸一化處理。該案例的三項指標滿分均為100分,因此若不做歸一化前處理,也不影響結果。歸一化結果如表二。

b.將表二的數據繪製成圖,如圖一所示。其中圓球體積為三項指標的總和(sum),換言之,由圖一可知,D供應商的綜合表最佳。

換個角度,A和C供應商的Quality分數最低,B供應商的Cost分數最低,均屬於單項指標較無競爭力的群體。

c.該案例預計將現有供應商分為三個群體(k=3),同時初始值挑選原則為最大值、中位數和最小值,因此D,E,J分別是三個水平的初始樣本。

經過上述初始值與各個數據的距離計算,第一次計算結果,如表四所示。[OS: 數據是我用亂數產生器給的,大部分供應商都屬於Medium,挺接近現實狀態~]

以表四的結果,重新計算三個群組的質心,如表五所示。
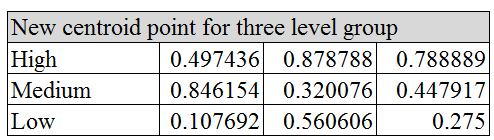
一樣計算新質心和各個數據的距離,有表六結果可知,雖然質心優化後,分類結果沒有變化。[OS: 有興趣的讀者,還可以繼續迭代下去~~]
討論:
1.或許眼尖的讀者會發現A和C供應商的Quality均為20,為所有供應商中最低分,但為何 A供應商屬於High level group,而C供應商屬於Low level group? 原因就出在k-means聚類算法是以在三維空間下,各個數據點與質心的距離來判斷歸屬群體,換言之,看的是QCD的綜合結果。
2.上述僅是利用k-means對既有供應商做聚類分析,在實際運作上,針對三項指標(QCD)進一步以層別法分類,將可有助標示出各個供應商的強項。
-----如果文章對您有幫助,打開微信掃一掃,請作者喝杯咖啡。-----

这篇关于[Excel]k-means聚類算法的應用,以評價現有供應商的水平為例。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








