本文主要是介绍论文笔记-DIRECT MULTI-HOP ATTENTION BASED GRAPH NEURAL NETWORKS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:DIRECT MULTI-HOP ATTENTION BASED GRAPH NEURAL NETWORKS
论文链接:
更多图神经网络和深度学习内容请关注:

摘要
在图神经网络(GNN)中引入自注意力机制(self-attention)可以实现图表示学习的最先进(state-of-the-ar)性能。 然而自注意力机制仅在两个相互连接的节点之间进行计算,且图表示仅取决于两个相互连接节点。
自注意力机制缺点为: 这种注意力计算不能考虑提供了图结构上下文信息的多跳邻居(跳数大于等于2的邻居)对节点表示学习的影响。 这篇论文提出了用于图表示学习的基于直接多跳注意力机制的图神经网络(DAGN),这是将多跳邻接的上下文信息融入注意力值计算的方法,可在每一层进行远程交互。
DAGN将注意力分值从相邻节点扩展到非相邻节点(多跳邻居),增加每个消息传递层的感受野。与以前的方法不同,DAGN在注意力分值时采用扩散优先(diffusion prior)的方法,可有效地计算节点对之间的所有路径权重。这有助于DAGN捕捉每一层的更大范围结构信息,并了解更多信息的注意力分布。
引言
图注意力网络(Graph Attention Network,GAT)等相关模型将注意机制应用于图神经网络。它们根据某条边直接连接的节点计算注意力分数,使得模型能够根据它们的注意力分数处理边上的消息,注意力分数可理解为是一种权重。
然而,这种仅计算某条边连接的节点的注意力意味着一个节点可以只关注它的近邻(一跳邻居,即直连邻居)来计算它的下一层表示, 即单个消息传递层的感受野仅限于单跳图结构。虽然叠加多个图注意力网络层可以扩大对多跳邻居的感受野,学习非单跳邻居的相互作用,但这些深层图注意力网络通常存在过度平滑问题。此外,单个GAT层中的边注意力权重仅基于节点表示本身,不依赖于图结构的邻域上下文。总之,单跳注意机制限制了它们探索图结构信息与注意力权重之间相关性的能力。以前的工作(Xu et al.,2018;Klicpera et al.,2019b)已经显示出在单层中执行多跳消息传递的优势,表明了在单层中探索图结构信息是有益的,同时这些方法不是基于图注意力机制的。
本文提出了一种基于直接多跳注意力机制的图神经网络(DAGN),它通过一个新颖的图注意力扩散层(下图)对关系图数据进行高效的多跳自注意力(multi-hop self-attention)计算。
图注意力扩散层计算过程为:
- 首先计算边上的注意力权重(某条边直接相连接的节点对之间的注意力,由实线箭头表示)
- 然后利用边上的注意力权重通过一个注意力扩散过程(attention diffusion process )来计算其他节点对自我注意力权重(某条边不直接相连接的节点对之间的注意力即多跳邻居的注意力,由虚线箭头表示)

论文提出的DAGN模型主要有两个优点 :
- DAGN可每一层中捕获节点之间的远程交互(多跳邻居之间的交互信息),该模型可在多跳邻居实现有效的远程消息传递。
- DAGN中的注意力计算与上下文有关。GAT中的注意力值仅取决于直接连接节点之间的上一层的节点表示,未连接节点之间的注意力值为0。而对于选定的多跳邻域内的任何一对可达节点,DAGN都通过汇总节点对之间所有可能路径(长度≥1)上的注意力得分来计算注意力。 此外,从变transformer 架构中获得启发,DAGN还证明了使用层归一化和前馈层可以进一步提高性能。
正文
DAGN体系结构
DAGN建立在GNN的基础上,同时融合了图注意力机制和扩散技术(Graph Attention and Diffusion technique)的优势,DAGN的核心是多跳注意力扩散(Multi-hop Attention Diffusion)。DAGN体系结构如下图所示。
每个DAGN块均由注意力计算组件,注意力扩散组件,两个层归一化组件,前馈层组件和2个残余连接组件组成。DAGN块可以堆叠以构成一个深度模型。在下图右边子图,展示的是通过注意力分散过程实现了与上下文有关的注意力。其中 v i , v j , v p , v q ∈ V v_i,v_j,v_p,v_q∈V vi,vj,vp,vq∈V是图中的节点。

多跳注意力扩散
我们首先介绍注意力扩散,它作用于DAGN每一层的注意力分数。扩散操作算子的输入是一组三元组 ( v i , r k , v j ) (v_i,r_k,v_j) (vi,rk,vj),其中 v i , v j v_i,v_j vi,vj为节点 i i i和节点 j j j, r k r_k rk为节点 i i i和节点 j j j之间边类型。 DAGN首先计算所有边上的注意力得分,然后注意力扩散模块通过扩散过程,基于边注意力分数计算未被边直接连接的节点对之间的注意力值。
边注意力计算
在第 l l l层,为每个三元组 ( v i , r k , v j ) (v_i,r_k,v_j) (vi,rk,vj)计算一个向量消息。为了计算结点 v j v_j vj在 l + 1 l+1 l+1层的表示,所有从三元组到 v j v_j vj的所有消息被聚合成一个消息,然后将其用于更新 v l + 1 v_{l+1} vl+1。
首先,一条边 ( v i , r k , v j ) (v_i,r_k,v_j) (vi,rk,vj)的注意力得分由以下公式计算
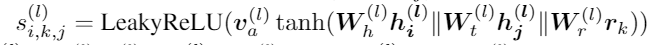
每个参数意义如下
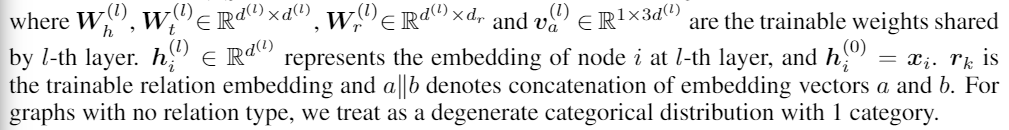
在图G的每一条边上应用上述公式,我们可得到一个注意力得分矩阵 S ( l ) S^{(l)} S(l)
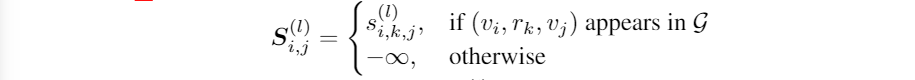
随后通过对注意力得分矩阵 S ( l ) S^{(l)} S(l)执行行式softmax来获得注意力矩阵 A ( l ) A^{(l)} A(l): A ( l ) = s o f t m a x ( S ( l ) ) A^{(l)}= softmax(S^{(l)}) A(l)=softmax(S(l))。 A i j ( l ) A^{(l)}_{ij} Aij(l)表示从节点 j j j到节点 i i i聚合消息时在第 l l l层上的注意力值。
(注:这一步与GAT和异构GAT比较类似)
多跳邻居的注意力扩散
在网络中未直接连接的节点之间的启用注意力,通过以下注意力扩散过程来实现这一点。该过程基于单跳注意力矩阵A的幂,通过图扩散来计算多跳邻居的注意分数:
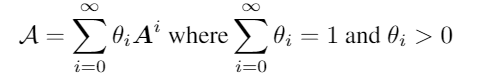
其中 θ i θ_i θi是注意力衰减因子且 θ i > θ i + 1 θ_i>θ_{i+1} θi>θi+1。注意力矩阵A的幂 A i A^i Ai,给出了从节点 h h h到节点 t t t的关系路径的数量,长度为 i i i,扩大了注意力的感受野。
该机制允许两个节点之间的注意力不仅依赖于它们之前的层表示,而且还考虑到节点之间的路径,有效地在未连接的节点之间启用注意力。根据 θ θ θ和路径长度,每条路径的注意力权重也不同。
在作者的实现中利用了几何分布 θ i = α ( 1 − α ) i θ_i=α(1-α)^i θi=α(1−α)i,其中 α ∈ ( 0 , 1 ) α∈(0,1) α∈(0,1)。这种选择是基于这样一种归纳偏差,即使得远处的节点对应的weight应该较少;同时对与目标节点关系路径长度不同的节点权重应该相互独立。注:初始化时, θ 0 = α ∈ ( 0 , 1 ) , A 0 = I θ_0=α∈(0,1),A_0=I θ0=α∈(0,1),A0=I。
基于图注意力扩散的特征聚合可定义为:
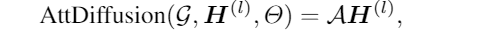
注意力扩散的近似计算
对于大型图来说,使用以下公式计算注意力矩阵 A A A的开销巨大。
而DAGN只需要通过 A H AH AH进行聚合,故可以通过定义一个收敛于 A H ( l ) AH^{(l)} AH(l)真值数列 Z ( k ) Z^{(k)} Z(k)来近似 A H ( l ) AH^{(l)} AH(l)(K→∞)。
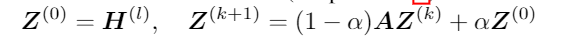
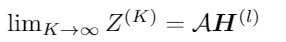
基于直接多跳注意力的神经网络体系结构
多头图注意力扩散层
多头注意力机制:让模型以不同的视角关注来自不同表示子空间的信息。
采用多头注意力机制,每个head都是单独计算然后进行聚合:
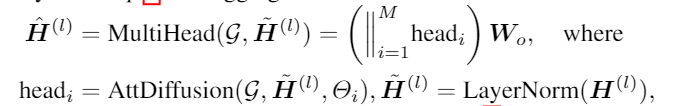
深层聚合
此外,这篇论文的DAGN块包含一个完全连接的前馈子层,该子层由两层前馈网络组成。同时两个子层中添加了层规范化和残差连接,为每个DAGN块提供了更具表现力能力。
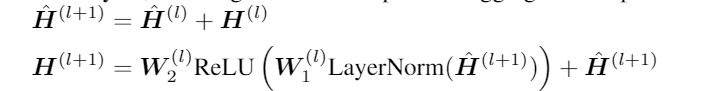
DAGN 推广了 GAT
DAGN通过扩散过程扩展GAT。GAT的聚合过程可定义为
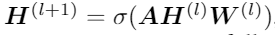
其中σ是一个激活函数,如ReLU函数。可将GAT的聚合过程分为两部分:
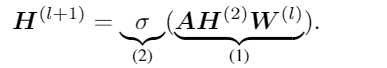
在(1)部分中,DAGN加入了多跳邻居的注意力,而不需要额外的参数,因为A是从A中导出的;对于(2)部分,DAGN使用层归一化和深度聚合(前馈子层)。
这篇关于论文笔记-DIRECT MULTI-HOP ATTENTION BASED GRAPH NEURAL NETWORKS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





