本文主要是介绍博文推荐|Apache Pulsar 轻装上阵:迈向轻 ZooKeeper 时代,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文翻译自《Pulsar Isolation Part III: Separate Pulsar Clusters Sharing a Single BookKeeper Cluster》,原文链接:https://streamnative.io/blog/release/2022-01-25-moving-toward-a-zookeeperless-apache-pulsar/。作者 David Kjerrumgaard,Apache Pulsar Committer,StreamNative 布道师。
译者简介
李文奇,就职于微软 STCA,业余时间喜欢研究各类中间件技术及分布式系统。
首次!无 ZooKeeper 也能运行 Pulsar
Apache Pulsar™ 有时被视为一个较复杂的系统,有一部分原因是因为 Pulsar 使用了 Apache ZooKeeper™ 存储元数据。从设计之初,Plusar 就使用 ZooKeeper 存储分配给 topic 的 broker 信息、topic 的安全和数据留存策略等关键元数据信息。ZooKeeper 这个额外组件便加深了大家对于 Pulsar 是一个复杂系统的印象。
为了简化 Pulsar 的部署,社区发起了一项计划——Pulsar 改进规划 PIP-45[1] 来减轻对 ZooKeeper 的依赖,同时用可插拔的框架来替代。这种可插拔的框架支持用户按照实际的部署环境选择可替换的元数据及协调系统,从而减少了 Pulsar 在基础设施层面的必须依赖。
PIP- 45 的实现与未来计划
PIP-45 的代码已经被提交到了主分支上,并即将于 Pulsar 2.10 版本发布。Apache Pulsar 用户首次可以在没有 ZooKeeper 的情况下运行 Pulsar。
与 Apache Kafka 的 ZooKeeper 替换策略不同,PIP-45 的目的不是内部化 Apache Pulsar 平台本身的分布式协调功能。相反,它允许用户根据自身环境选用合适的技术组件来替换 ZooKeeper。
在非生产环境中,现在用户可以选择使用轻量级的替代方案,可将元数据保留在内存中或者本地磁盘上。开发人员便可收回之前在其笔记本上运行 Apache ZooKeeper 所需的计算资源。
在生产环境中,Pulsar 的可插拔框架支持用户利用那些早已在自身软件技术栈中运行的组件作为 ZooKeeper 的替代方案。
可以想象,如此重大的计划由多个步骤组成,目前其中一些已经实现。本文将带您浏览迄今为止已实现的步骤(步骤 1-4),并概述仍需要完成的工作(步骤 5-6)。请注意,本文中讨论的功能尚处于测试阶段,在实际发布版本中可能会有所变化。
第一步:定义元数据存储 API
PIP-45 为元数据管理和分布式协调提供了一个跨技术组件的接口,从而允许使用非 ZooKeeper 的方式管理元数据等,增加了系统的灵活性。
ZooKeeper 客户端 API 历来贯穿整个 Apache Pulsar 代码库,因此我们首先需要通过单个通用的 MetadataStore 接口来整合所有这些 API 调用。该接口的构造是基于 Pulsar 在与元数据间交互的需求以及一些由现有的元数据储存引擎(如 ZooKeeper 及 etcd)提供的场景语义。
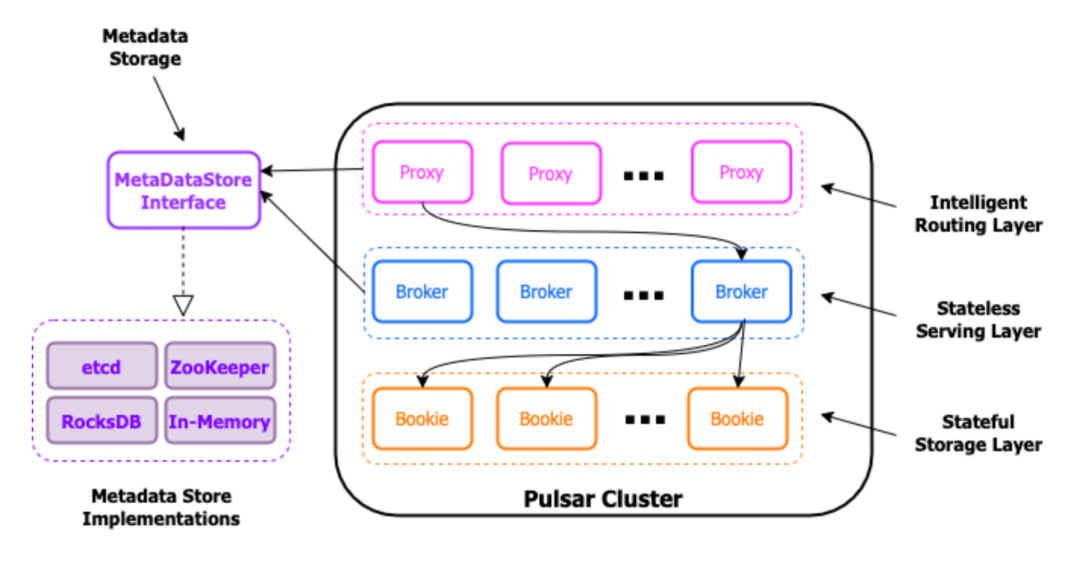
图 1:支持开发不同的 MetadataStore 接口实现方式,从而用接口来代替对 Apache ZooKeeper 的直接依赖,并提供了用户根据自身环境选用的灵活性。
这一步不仅将 Pulsar 与 ZooKeeper API 进行了解耦,同时也构建了一种可插拔框架,这样不同的接口实现便能在开发环境中互相替换。
这些新接口允许 Pulsar 用户根据 broker 配置文件中的 metadataURL 属性值轻松地将 Apache ZooKeeper 替换为其他元数据管理系统或其他协调服务。这套框架会根据 URL 的前缀自动产生正确的实例。例如,如果 metadataURL 配置属性值以Rocksdb:// 开头,则将使用 RocksDB 作为接口的实现。
第二步:创建基于 ZooKeeper 的实现
一旦定义了这些接口,会创建一个基于 Apache ZooKeeper 的默认实现,以便为现有的 Pulsar 平稳过渡到新的可插拔框架。
这一阶段我们的主要目标是对于那些想保留 Apache ZooKeeper 的用户,防止因 Pulsar 升级到新版本而产生任何重大的变更。因此,我们需要确保当前存储在 ZooKeeper 中的现有元数据在升级后也可以保存在与以前相同的位置和相同的格式中。
基于 ZooKeeper 的实现允许用户继续选择使用 ZooKeeper 作为元数据存储层,并且在 etcd 版本完成以前,这是目前唯一在生产环境中可用的实现方式。
第三步:创建基于 RocksDB 的实现
在解决了这些向后兼容问题之后,下一步是提供不基于 ZooKeeper 的实现方式,以展示框架的可插拔性。验证该框架的最简单方式是在单机模式(standalone 模式)下基于 RocksDB 实现 MetaDataStore。
这不仅证明该框架具有在不同 MetaDataStore 实现方式切换的能力,同时也能大大减少完整运行完全独立的 Pulsar 集群所需的资源总量。该步骤的实现对选择在本地(通常是 Docker 容器)进行开发和测试的开发者们有直接的影响。
第四步:创建基于内存的实现
缩减元数据存储也对单元与集成测试大有裨益。我们发现,MetaDataStore 的内存实现更加适合测试场景,这就减少了反复启动 ZooKeeper 集群以执行一套测试然后将其关闭的成本。
同时,不仅能够减少运行 Pulsar 全套集成测试所需的资源量,而且还能够减少测试的时间。
通过利用 MetaDataStore 的内存实现,Pulsar 项目的构建和发布周期将会大大缩减,构建、测试和发布也能够更快地变更到社区。
第五步:创建基于 Etcd 的实现
鉴于 Pulsar 云原生的设计架构,ZooKeeper 最明显的替代者便是 etcd。etcd 是一致性、高可用的键值存储系统,用作 Kubernetes 的所有集群元数据的存储。
除了其社区不断扩大且活跃,项目的广泛使用,以及性能和可扩展性的改进之外,作为控制面的一部分,etcd 早已在 Kubernetes 中可用。由于 Pulsar 天然支持在 Kubernetes 内运行,在大多数生产环境中都可以直接访问到运行的 etcd 实例,因此用户可以直接使用已有的 etcd,而不会额外增加 ZooKeeper 带来更多运营成本。
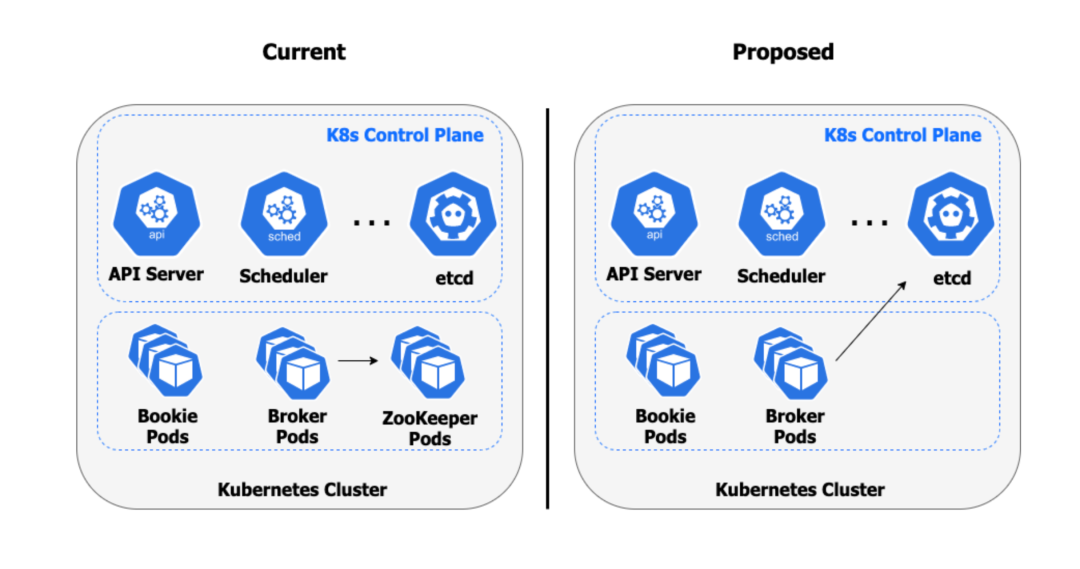
图 2: 当在 Kubernetes 中运行 Pulsar 时,用户可以使用已有的 etcd 实例来简化部署
利用在 Kubernetes 集群内运行的现有 etcd 服务来作为元数据存储,用户可以完全不需要运行 ZooKeeper。这不仅减少了 Pulsar 集群的基础设施占用的资源,还减轻了运行和操作复杂的分布式系统所需的运营负担。
etcd 的所带来的性能提升是一项令人特别兴奋的技术进展——etcd 旨在解决与 ZooKeeper 相关的一些问题。对于初学者来说,etcd 完全是用 Go 编写的,ZooKeeper 主要是用 Java 编写的,而 Go 通常被认为是比 Java 性能更高的编程语言。
此外,etcd 使用较新的Raft[2]共识算法,该算法在容错和性能方面与 ZooKeeper 使用的 Paxos 算法差别不大。但是,它比 ZooKeeper 使用的 ZaB 协议更容易理解和实现。
etcd 的 Raft 实现与 Kafka(KRaft)实现的最大区别在于后者使用基于拉的模型进行同步更新,在延迟上略有劣势。Raft 算法的 Kafka 版本也是用 Java 实现的,它在垃圾回收期间可能会出现长时间的停顿。而在基于 Go 语言的 Raft 算法的 etcd 版本中则没有这个问题。
第六步:缩放元数据层
如今,Pulsar 集群扩展的最大障碍是元数据层的存储容量。使用 ZooKeeper 存储此元数据时,必须将数据保留在内存中,以提供较好的延迟性能。用一句话概括便是"磁盘就是 ZooKeeper 的死穴"[3]。
然而,etcd 中的数据存储方式是 B 树数据结构,而不是 ZooKeeper 使用的分层树结构,etcd 所用的数据存储结构存储在磁盘上并映射到内存中以提供低延迟的访问。
这样做的意义在于,它有效地将元数据层的存储容量从内存规模增加到磁盘规模,使我们能够存储大量的元数据。对比 ZooKeeper 与 etcd ,存储容量从 ZooKeeper 的几 G 内存扩展到了超过 100G 的 etcd 磁盘[4]。
安装与更多细节
在过去几年中,Pulsar 成为了最活跃的 Apache 项目之一[5],正如 PIP-45 项目所展示的那样,一个充满活力的社区将继续推动项目的创新和改进。
迫不及待想要尝试去 ZooKeeper 的 Pulsar 吗?下载最新版本的 Pulsar,并在独立模式下运行[6],或者参考文档[7]。
除了去除对 ZooKeeper 的强依赖,Apache Pulsar 2.10.0 版本包含来自于 99 位贡献者的 1000 个 commit,引入了多达 300 项重要的更新。即将发布的新版本中还有诸多令人兴奋的技术进展:
• 引入 TableView 降低用户构建键值对视图的成本;
• 在客户端添加多集群自动故障转移策略;
• 增加消息重试指数退避延迟策略;
• ……
在上周日的 TGIP-CN 037 直播中,Apache Pulsar PMC 成员,StreamNative 首席架构师李鹏辉为大家介绍了即将发布的 Apache Pulsar 2.10 版本特性,敬请关注本周 Apache Pulsar 公众号推送~
不过可以提前浏览回顾视频哟:

参考文献
• PIP-117: Change Pulsar standalone defaults[8]
• Apache ZooKeeper vs. etcd3[9]
• Performance optimization of etcd in web scale data scenario[10]
引用链接
[1] PIP-45: https://github.com/apache/pulsar/wiki/PIP-45%3A-Pluggable-metadata-interface[2] Raft: https://raft.github.io/[3] "磁盘就是 ZooKeeper 的死穴": https://zookeeper.apache.org/doc/r3.4.8/zookeeperAdmin.html#sc_commonProblems[4] 存储容量从 ZooKeeper 的几 G 内存扩展到了超过 100G 的 etcd 磁盘: https://www.alibabacloud.com/blog/fast-stable-and-efficient-etcd-performance-after-2019-double-11_595736[5] Pulsar 成为了最活跃的 Apache 项目之一: https://blogs.apache.org/foundation/entry/apache-in-2021-by-the[6] 在独立模式下运行: https://pulsar.apache.org/docs/en/standalone/#start-pulsar-standalone[7] 文档: https://pulsar.apache.org/docs/en/standalone-docker/[8] PIP-117: Change Pulsar standalone defaults: https://github.com/apache/pulsar/issues/13302[9] Apache ZooKeeper vs. etcd3: https://dzone.com/articles/apache-zookeeper-vs-etcd3[10] Performance optimization of etcd in web scale data scenario: https://www.cncf.io/blog/2019/05/09/performance-optimization-of-etcd-in-web-scale-data-scenario/
▼ 关注「Apache Pulsar」,获取更多技术干货 ▼
👇🏻加入 Apache Pulsar 中文交流群👇🏻

这篇关于博文推荐|Apache Pulsar 轻装上阵:迈向轻 ZooKeeper 时代的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





