本文主要是介绍ArcGIS/GeoScene脚本:基于粒子群优化的支持向量机回归模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
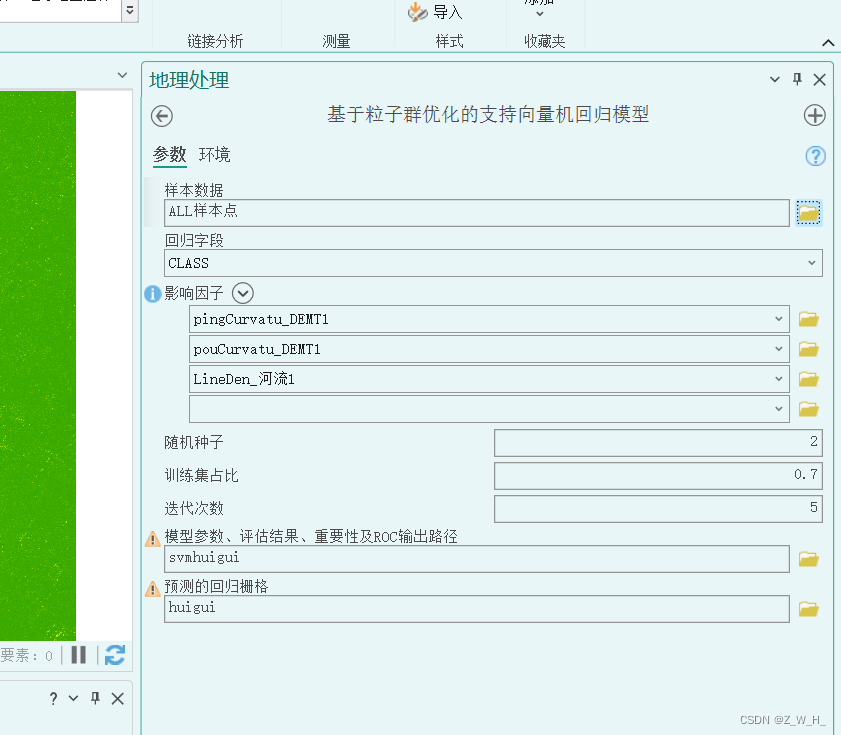
参数输入
1.样本数据必须包含需要回归的字段
2.回归字段是数值类型
3.影响因子是栅格数据,可添加多个
4.随机种子可以确保每次运行的训练集和测试集一致
5.训练集占比为0-1之间的小数
6.迭代次数:迭代次数越高精度越高,但是运行时间越长
7.模型参数、评估结果、重要性分析为一个文件夹
8.预测的回归栅格:输出结果是浮点类型的栅格数据
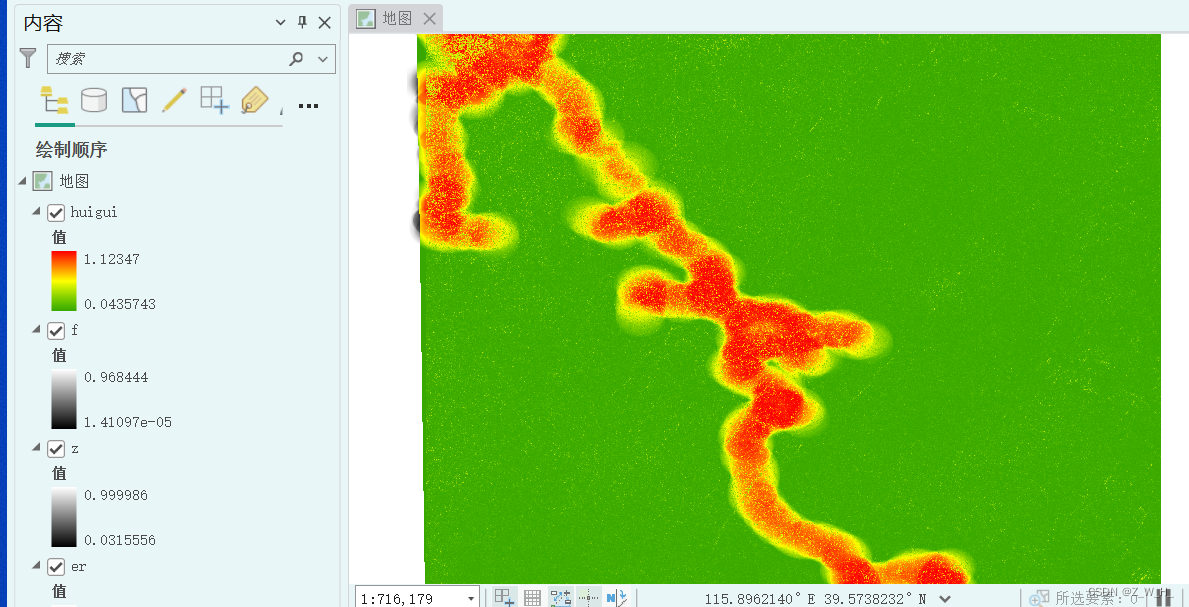
输出
回归栅格
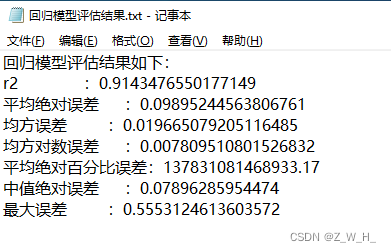
模型评估结果
这篇关于ArcGIS/GeoScene脚本:基于粒子群优化的支持向量机回归模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








