本文主要是介绍一分钟!图片生成32种动画;Adobe绘画工具大升级;复盘Kaggle首场LLM比赛;VR科普万字长文 | ShowMeAI日报,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

🔥 Adobe Firefly 大升级!图像高清、操作便利,体验感拉满

https://firefly.adobe.com
Adobe Firefly 升级了,增加了很多定制化功能,模型能力也更强大了!生成图片的默认分辨率居然是2048*2048,远超一般图片平台的清晰度了。本次升级要点如下,使用魔法访问上方链接,就可以免费体验了!
模型升级到 Firefly Image 2,可以创建更逼真的图像,图像质量更高
支持图生图:相当于 Midjourney 垫图功能
支持设置照片参数:可以像相机一样更改光圈、快门速度和视角等参数
提供提示词建议,支持添加反向提示词,支持云储存生成的图片
将鼠标放在生成的图片上,可以对图片进行二次编辑 ⋙ 官方博客

🧰 图片转动画在线AI工具,一分钟就可以做出32个动画

https://sketch.metademolab.com
前两天社群小伙伴找一个AI工具,用一张图片就可以做成动画。当时,整个群一起沉默了。。。不过!逛小红书时看到了「Animated Drawings」,完美满足需求!无需魔法,点击鼠标就可以让一张图片动起来,还能在32种动作类型中切换!
第1步:准备素材,注意四肢不与身体重叠,纯白背景,确保清晰度
第2步:上传图片并裁剪出角色
第3步:AI自动识别角色边界,将主体与背景分开
第4步:AI智能识别骨骼,可以调整绑定关节
第5步:系统预设了32种动画,点击可以查看角色动作
第6步:点击图像右下角标识,可以下载动画 .mp4 视频,找在线工具就可以转成 .gif 格式啦 ⋙ 小红书-视频教程

🧩 Kaggle 首场大模型比赛,金牌解决方案复盘

https://www.kaggle.com/competitions/kaggle-llm-science-exam
Kaggle 作为全球知名的数据科学比赛平台,也参与到了大模型浪潮当中,陆续上线 LLM 相关的比赛和主题分享。
今天要讲的这场比赛「LLM Science Exam」,设定与传统的大模型测评场景比较类似,即给定科学类题目和5个选项ABCDE,选出一个正确答案。
在 Kaggle 平台限制了计算资源、项目时间的情况下,全球大牛们各显神通,给出了不同思路的解决方案。前5名的大佬们用了哪些模型和处理技巧?各类模型表现排名如何?在这篇笔记里写得很清晰了 ⋙ 阅读原文

👀 Poe主流大模型测评榜单:GPT-4完胜,但有意外收获!
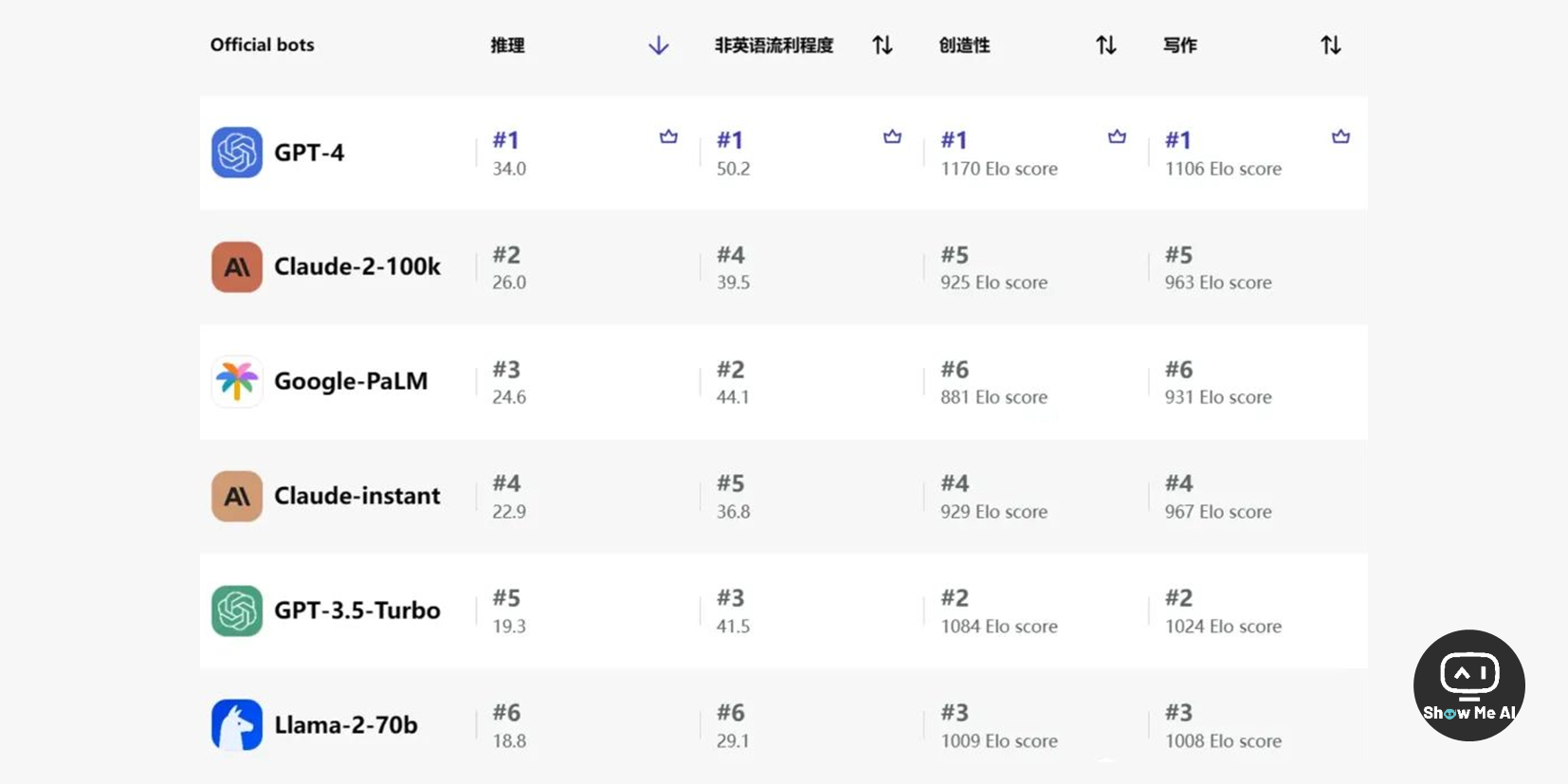
https://poe.com/bot_rankings
Poe 是一款聚合了海外主流大模型的AI聊天机器人应用,最近和SurgeAI合作对主流LLM进行了4个维度的评估:推理、和非英语流利程度、创造力性、写作。结果如上图所示,整体客观可信。
GPT-4 拿到了所有第1名,一如既往是「别人家的孩子」。不过,Google-PaLM 对非英语地支持能力排在第2名,Llama-2-70b 在创造性和写作测评中获得第3名,倒是让人耳目一新!值得多做一些模型应用尝试和摸索。测评原理可以访问上方 Poe 链接查看博文~

📜 AI会对HR工作产生哪些影响?这里有一份调查报告
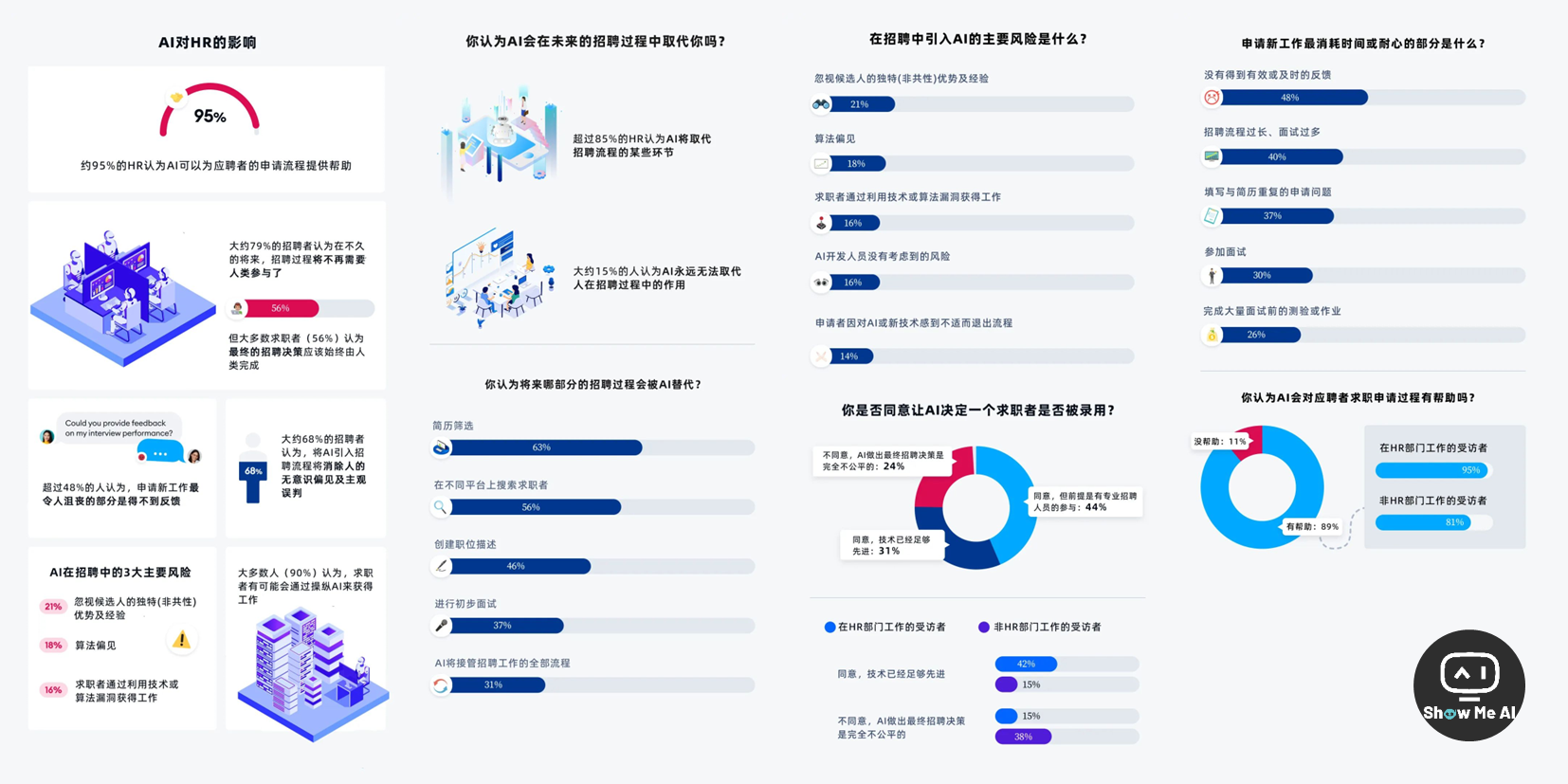
国内外的人才平台和招聘平台正在陆续引进大模型功能。AI对招聘和求职将带来什么影响呢?HR和应聘者持乐观还是悲观态度呢?这份报告给出了1000+人的调研结果。整体来说,双方都对技术发展持乐观态度,但也担心AI偏见等导致的决策失误。
选出了几个调研的关键数据,完整报告和分析可以前往下方原文查看:
约 77% 的HR认为,AI很快就会足够先进,承担聘用决策的重任
约 89% 的受访者认为,AI可以帮助求职者完成申请流程
约 31% 的受访者同意由AI来决定他们是否被录用 ⋙ 阅读原文

📚 万字长文!VR 不完全科普指南,一文了解VR原理和前景

这是一篇易懂又全面的 VR (虚拟现实) 技术的科普文章,全面介绍了 VR 技术发展历史、核心原理和应用前景,读完可以对这一领域有着透彻的理解,跟上目前眼花缭乱的产品发布节奏。以下是文章要点,可以对照查看原文:
一、上帝的画笔:介绍了VR起源,它实现了让人类真正拿起创世神的画笔、描绘并体验虚拟世界的梦想
二、我们应该如何呈现世界
一块屏幕:介绍了VR中使用的显示屏技术的发展和优劣势
把光映入眼中:说明了VR利用凸透镜的原理实现近距离成像和视觉放大
沉浸感的实现:通过双屏幕呈现立体视差,利用人眼合成立体图像的原理
远近感知:讲解了人眼判断距离的生理机制,以及VR中利用眼动调节解决远近感知问题
三、世界应该如何与我们交互
空间定位:介绍了IMU和内外部摄像头追踪的工作原理
面部、眼动和手势追踪:说明了各种传感器实现面部追踪、眼动追踪和手势交互的技术
全彩透视:可以将VR捕捉真实环境,实现数字孪生等应用
四、把大象塞进冰箱的最后一步:对VR头显的核心部件如传感器、芯片进行概述
五、后记:总结了作者的写作心得,对VR技术发展的期待 ⋙ 阅读原文

📋 从VAE到DDPM,一文搞懂AIGC 图像生成模型的发展历程

AIGC 指的是人工智能生成内容 (AI Generated Content),就是最近大火的基于AI生成文字、图片、视频、音频等。AIGC 生成图像的过程用到了 DALL-E、Stable Diffusion 等模型,它们都是基于Diffusion Model、特别是 Conditional DDPM 算法实现的。
这篇文章将原理、公式和代码结合在一起,展示了图像生成模型由简单到复杂的技术发展历程。如果你在学习 Diffusion Model 之前需要补充基础知识,记得回看这篇文章。
AE (AutoEncoder):最基础的重构模型,通过编码器提取图片特征,解码器重构图片
VAE (Variational AutoEncoder):在AE基础上,编码器输出是连续latent变量,使其服从某分布 (如高斯分布),可以生成新的样本
CVAE (Conditional VAE):在VAE基础上引入条件,可以控制生成结果
DDPM (Denoising Diffusion Probabilistic Model):一种生成模型,将数据逐步添加高斯噪音,再逐步去噪重构,可以生成高质量样本
Conditional DDPM:在DDPM中引入条件,控制生成过程 ⋙ 阅读原文

📚 RLHF + Diffusion Models = ?一次很有意思的尝试!

https://www.tanishq.ai/blog/posts/ddpo.html
近年来,生成式AI主要有两大进展,一个是语言模型 (如ChatGPT、LLaMA-2),另一个是图像生成模型 (如DALL-E、Stable Diffusion)。语言模型使用了强化学习中的人类反馈 (RLHF) 技术,使其更容易遵循指示。因此作者提出, RLHF 能否也应用于后者?
作者尝试将强化学习中的 DDPO 算法应用于Stable Diffusion等扩散模型,以优化生成图像的审美质量。具体来说,文章首先建立了将扩散模型形式化为马尔可夫决策过程的框架,然后推导出了DDPO的目标函数,并给出了完整的训练流程。
在ImageNet动物数据集上进行的实验表明,这种方法可以有效提升图像的视觉质量和美感。当然,由于奖励函数本身并不包含语义指示,所以有时生成的图像会偏离原始提示。
总体来说,这项工作展现了强化学习在提升生成模型表现方面的潜力!
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!
订阅合集 #ShowMeAI日报,查看历史消息,接收每日最新推送; 点击公众号底部菜单栏,或者回复关键字 日报 ,可以获取独家AI发展趋势报告、原创AI专题资料合集等。

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!
这篇关于一分钟!图片生成32种动画;Adobe绘画工具大升级;复盘Kaggle首场LLM比赛;VR科普万字长文 | ShowMeAI日报的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






