本文主要是介绍论文笔记:Map-Matching for low-sampling-rate GPS trajectories(ST-matching),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ACM-GIS 2019
1 Intro
- 将GPS数据和地图路网数据匹配
- 提出全局地图匹配算法ST-matching(类似于HMM的思路)
- 考虑了道路网络的空间几何和拓扑结构
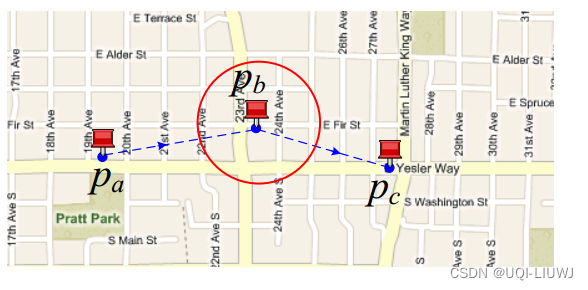
- 如果不考虑拓扑关系,直接进行matching的话,由于GPS信号的不准,可能轨迹会和实际情况差很多
- 考虑的轨迹的速度因素
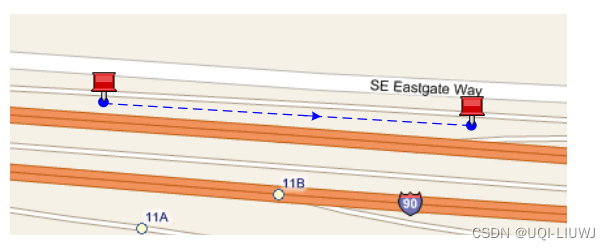
- 比如一条高速、一条公路平行,那么如果不考虑速度的话,这样一组GPS信号应该把它放到高速上?还是公路上?
- 考虑了道路网络的空间几何和拓扑结构
2 问题描述
2.1 GPS日志
- 一系列GPS点的集合
- 每个GPS的点包括经度、维度、时间戳

2.2 GPS轨迹
- 一条GPS轨迹T是一个GPS点的序列
- 一条轨迹任意两个相邻点之间的时间间隔不超过ΔT(一个阈值)
2.3 路段
- 一个路段 e 是一条有向边,具有编号 e.id、行驶速度 e.v、长度 e.l、开始点 e.start、结束点 e.end 和中间点列表.
- 一条道路可以包含多个路段
2.4 路网
一个有向图 G(V,E)
2.5 路径
- 给定路网 G 中的两个顶点 vi,vj,一条路径 P 是始于 vi 止于 vj 的一组连接的路段
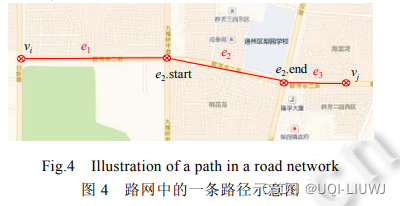
2.6 路网匹配
给定未加工的 GPS 轨迹 T 和路网 G(V,E),从 G 中寻找路径 P(实际路径匹配轨 迹 )
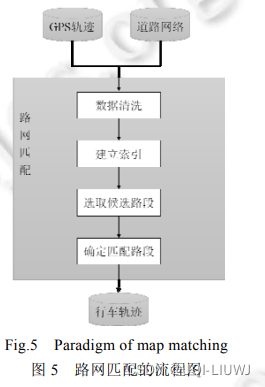
3 ST-matching
3.0 和HMM的概念对应
- 观测状态——从 GPS 设备中得到的位置信息(经度、纬度)
- 隐藏状态——拥有 GPS 设备的物体(车、人等)实际所在的位置
- 观测状态概率(输出概率)——观测的 GPS 样本点离候选路段越近,这个样本点在这个路段上的概率就越大.
- 状态转移概率——隐藏状态之间的转换概率
3.1 确定候选点
- 给定一条确定轨迹
- 对每一个点pi,在半径为r的范围内搜索该路段的候选集
- 然后计算候选点,候选点是pi对这些路段的投影
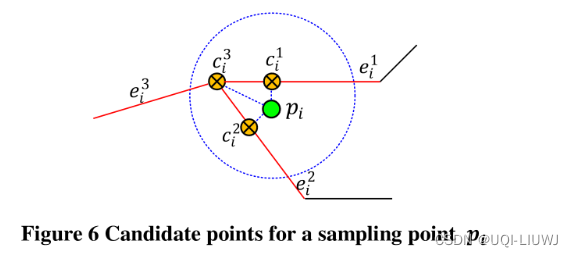
每一个点找到这样的一个候选点集合,得到候选点图
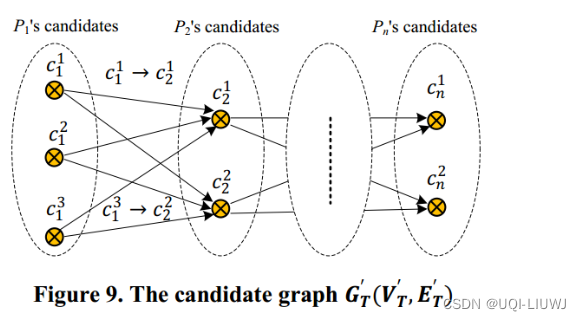
3.2 空间分析
3.2.1 观测状态概率(输出概率)
- oi是第i个观测点
是第i个观测点的第k个candidate
- 时刻 t 的观测点与候选点之间的距离越小,这个候选点是真正的实际点的概率就越大
- ——这里根据经验选择零均值、std为20的正态分布
- 观测概率不考虑前后GPS定位点,所以容易出现误匹配
3.2.2 空间分析函数
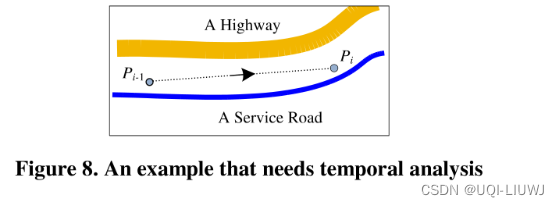
- 如下图,粗实线代表高速公路,细的垂线代表本地道路。
- 采样点(观测点)pi距离第一个候选点比较近,但是如果我们知道前一个采样点和后一个采样点在高速路上,所以理论上应该匹配到第2个采样点
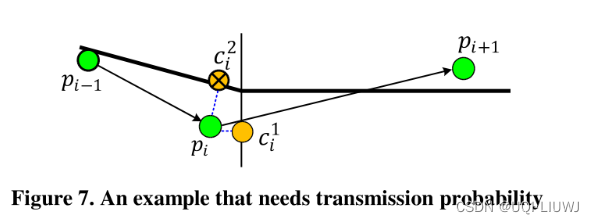
-
- ST-matching将空间拓扑关系也考虑了进来:【空间传递概率】
- 根据t+1和t时刻观测值和候选值的信息,推测从t时刻的观测值ot到t+1时刻的观测值
之间的真实路径是ci到cj最短路径的可能性
- 观测值之前的距离/候选点之间的距离
- 根据t+1和t时刻观测值和候选值的信息,推测从t时刻的观测值ot到t+1时刻的观测值
- ST-matching将空间拓扑关系也考虑了进来:【空间传递概率】
-
空间分析函数
-
-
结合了观测概率【几何信息】和传递概率【拓扑信息】
-
如果没有N(cj)的话,那么为了Fs越大越好,||ci-cj||越小越好,最后就会选择距离
路径距离最近的candidate了
-
3.3 时间分析
- 如果只使用空间分析的话,大部分真实路径都可以match,但是就如intro中说的那样,有一些情况无法处理:
-
这时候就需要时间传递概率(速度传递概率)
- 时间分析函数
- 用余弦距离来衡量从候选点ci到候选点cj之间的平均速度,和路段速度约束之间的相似度
- ci到cj之间的路径被定义为一个路段列表:
- 每个路段的速度约束为
- 每个路段的速度约束为
是ci到cj的平均速率
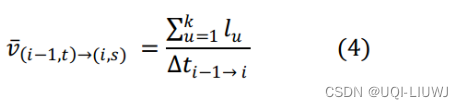
3.4 获取路径
- 将空间分析函数和时间分析函数结合,得到时空分析函数
- 真实路径T匹配的最优路径P为使得F(Pc)最大的候选点路径集合Pc

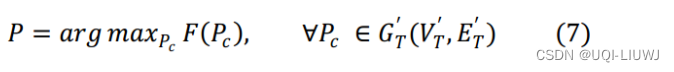
3.4.1 伪代码


3.5 本地ST-matching
- ST-Matching是全局算法,但是实际中不可能都给出完整路径
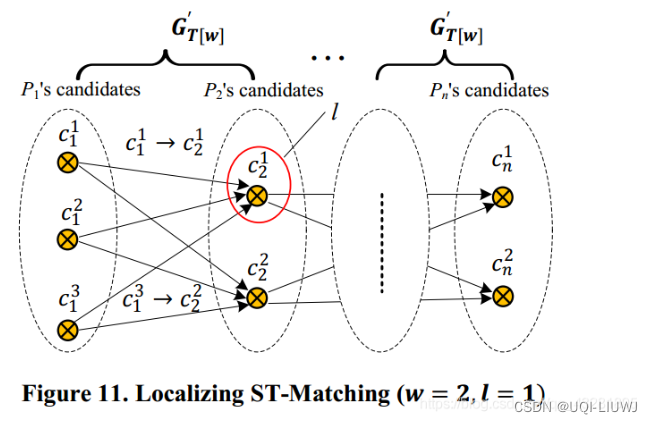
- ——>local ST-matching使用轨迹上的滑动窗口
- 局部候选图是轨迹T的一个子集
- 计算方式和全局算法一样
- 计算一个滑动窗口中的局部候选图后,移动滑动窗口,计算后续的滑动窗口
- 将轨迹划分为窗口可以:
- 减少平均延迟
- 节省用于在线处理的存储空间
- 但不一定会加快整体处理时间,因为ST匹配算法最昂贵的部分是最短的路径计算(空间分析函数中
的
)
- 为了降低计算复杂度,可以保留到目前为止,得分最高的l个候选点(而不是所有的候选点)
- ——>减少下一个采样点需要计算的最短路径的pair数量
- 当l=1时,退化成增量算法
- w=2——>滑动窗口为2,每次只考虑两个时刻组成的子路段
- l=1——>每次只保留F值最高的一个候选点,后续st-matching也只会考虑这一个点
3.6 复杂度
【推导过程我不确定,请评论区批评指正】
记轨迹中的采样点个数为n、路网中路段个数为m,每个采样点最多有k个候选点
- 每个点找候选点:O(n)
- 候选点图GT中最多有
条边
- 相邻的两个采样点对应的候选点之间最多k^2条边
- n个采样点,有n-1个间隔
- 每一条边计算
需要的开销
- Fs:
- 计算ci和cj的最小路径长度,使用堆优化的迪杰斯特拉算法,复杂度是O(mlogm)
- Ft:
- 这个不怎么占复杂度,可以视为O(m)
- ——>构建候选点图需要的复杂度
【 algorithm 1】(n-1和n没有区别)
- Fs:
- 进行地图matching需要的开销
- 每一条边只需要遍历一次
- ——>复杂度是
- ——>复杂度是
- 每一条边只需要遍历一次
- ——>总的复杂度是
4 实验
4.1 实验配置
4.1.1 路网
- 北京的路网
- 58624个点
- 130714条路段
4.1.2 数据
- 人工数据
- 首先随机选择两个点
- 在这两个点之前选择前K段的路径
- 在这K段路径中,随机选择一条,记作
- 指定一个采样间隔k',从G中以这个间隔挑选点
- 用这些挑选出来的点match轨迹,看和ground-truth一不一样
- 首先随机选择两个点
- 真实数据
- 从GoeLife系统中采集28条轨迹,这些轨迹都手工标注的label(作为ground truth)
-
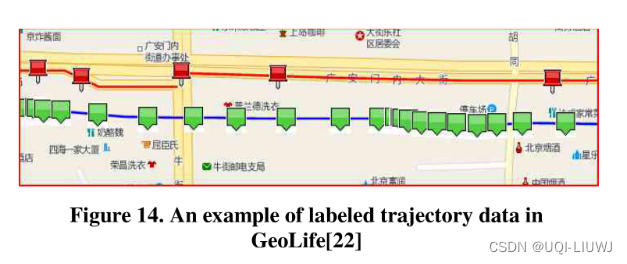 绿色+蓝色是GPS轨迹,红色是用户的实际轨迹
绿色+蓝色是GPS轨迹,红色是用户的实际轨迹
- 从GoeLife系统中采集28条轨迹,这些轨迹都手工标注的label(作为ground truth)
4.2 评估标准

4.3 结论
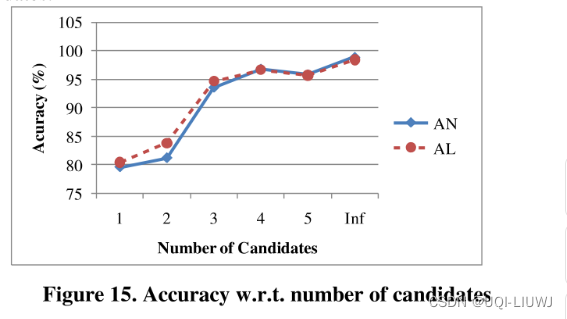
4.3.1 候选点数量的影响
准确率
运行时间

4.3.2 S-matching 和 ST-matching
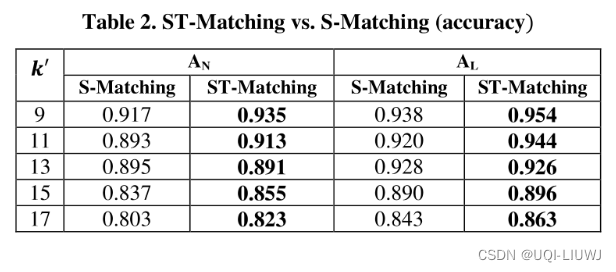
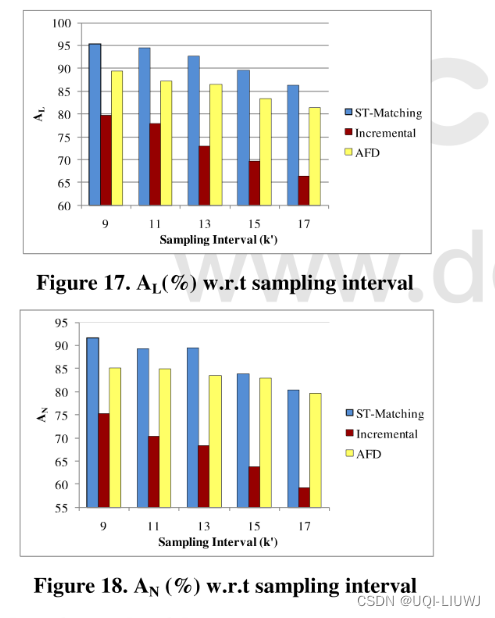
4.3.3 和Baseline的比较
AFD——最小平均Frechet距离
这篇关于论文笔记:Map-Matching for low-sampling-rate GPS trajectories(ST-matching)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




