本文主要是介绍轻量级网络模型ShuffleNet V2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在学习ShuffleNet V2内容前需要简单了解卷积神经网络和MobileNet,以及Shuffnet V1的相关内容,大家可以出门左转,去看我之前的几篇博客MobileNet发展脉络(V1-V2-V3),轻量级网络模型ShuffleNet V1🆗,接下来步入正题~
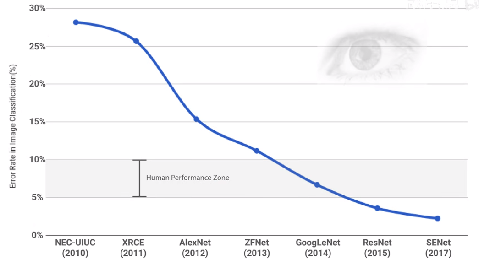
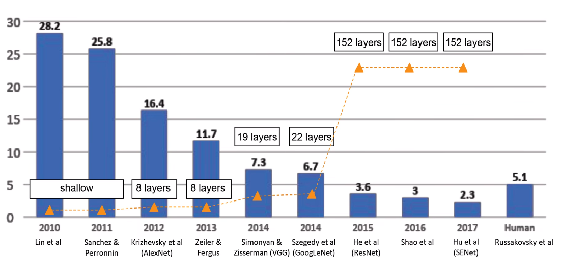
卷积神经网络被广泛应用在图像分类、目标检测等视觉任务中,并取得了巨大的成功。然而,卷积神经网络通常需要较大的运算量和内存占用,在移动端以及嵌入式设备等资源受限的环境中受到限制,因此需要进行网络压缩。
ShuffleNet-V2是旷视推出的继ShuffleNet-V1的轻量级网络模型,旨在不过多牺牲模型性能的同时大幅度减小模型的尺寸和加快模型的运算速度。在同等复杂度下,ShuffleNet-V2比ShuffleNet-V1和MobileNet-V2更准确。
轻量级网络模型回顾
MobileNet v1: 提出了 深度可分离卷积和两个全局超参数-宽度乘法器和分辨率乘法器。
MobileNet v2: 在MobileNet V1深度可分离卷积的基础上提出了具有线性瓶颈的倒置残差块。
MnasNet: 提出了分层的神经网络架构搜索空间,使用NAS搜索各自基本模块,通过多目标优化的目标函数进行反馈和修正。
MobileNet v3:使用了 NAS 和 NetAdapt 算法搜索最优的模型结构,同时对模型一些结构进行了改进,在 MobileNet_V2的具有线性瓶颈的倒置残差块基础上引入MnasNet的Squeeze-and-Excitation注意力机制。
ShuffleNet v1:利用分组点卷积来降低参数量,利用通道重排操作来增强不同通道之间的交互和融合。
ShuffleNet v2:提出了四条有效的网络设计原则,并根据这四条原则设计了一个高效的网络结构。
轻量级网络模型比较
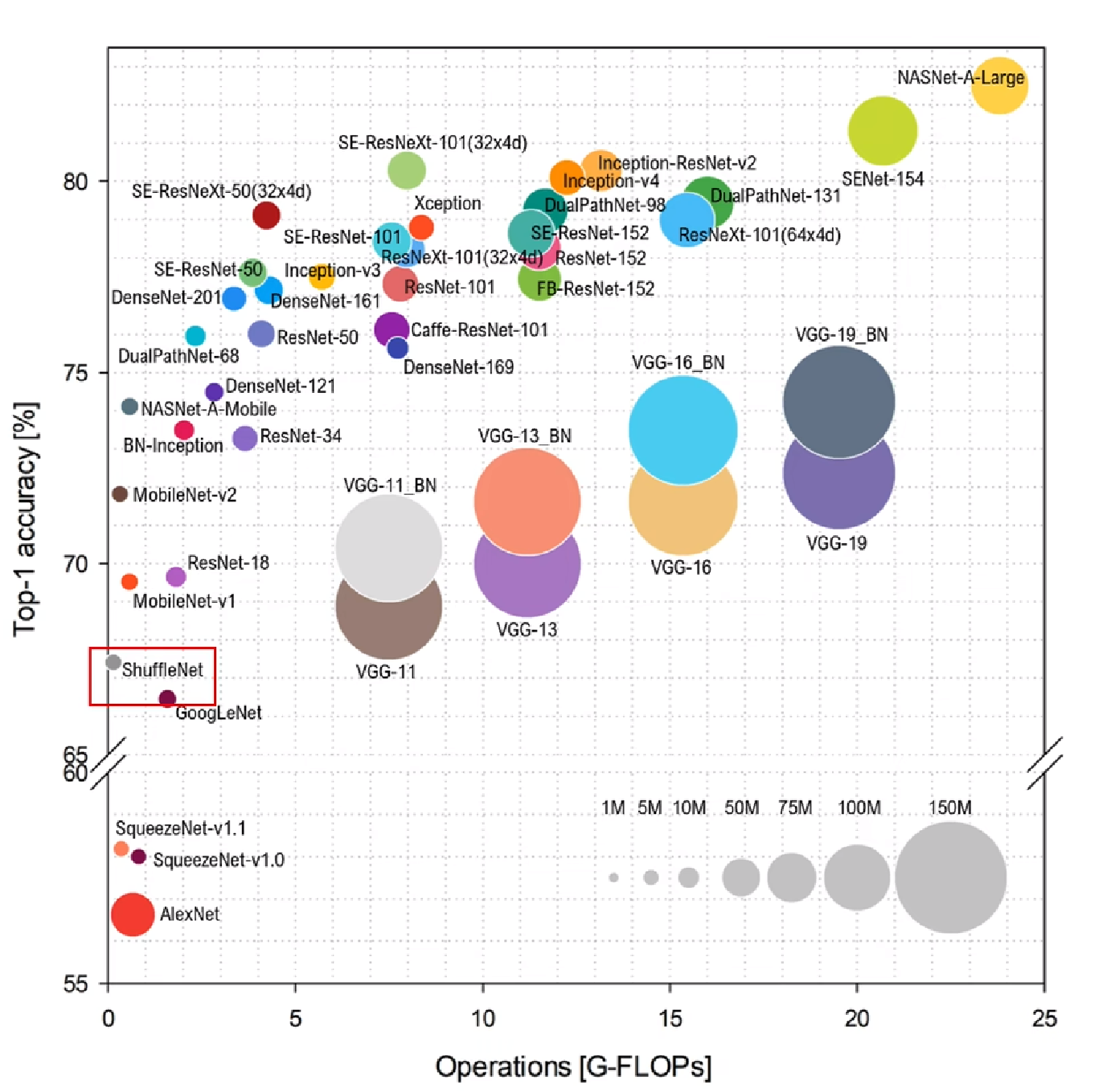
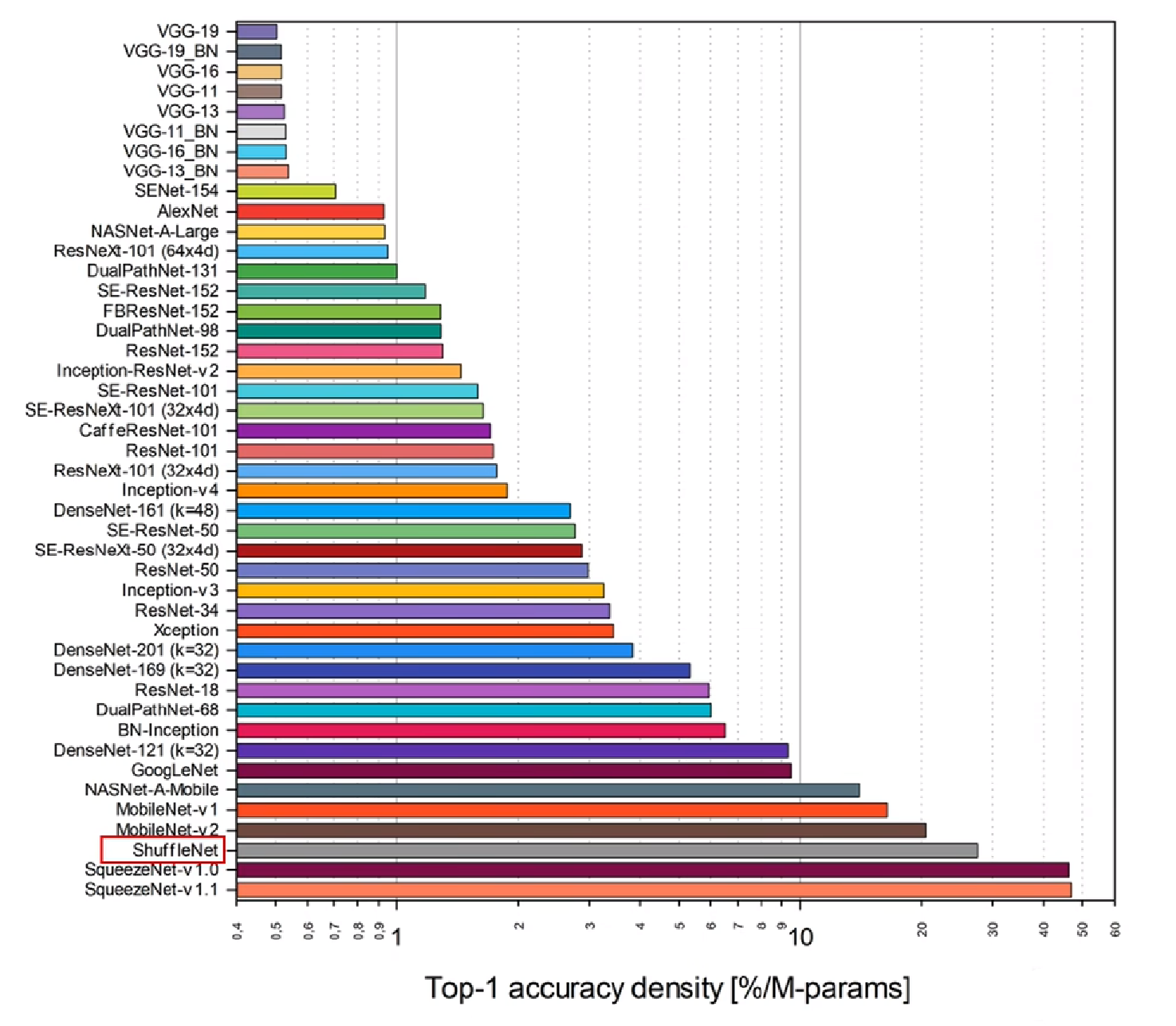
四条轻量级网络模型设计原则
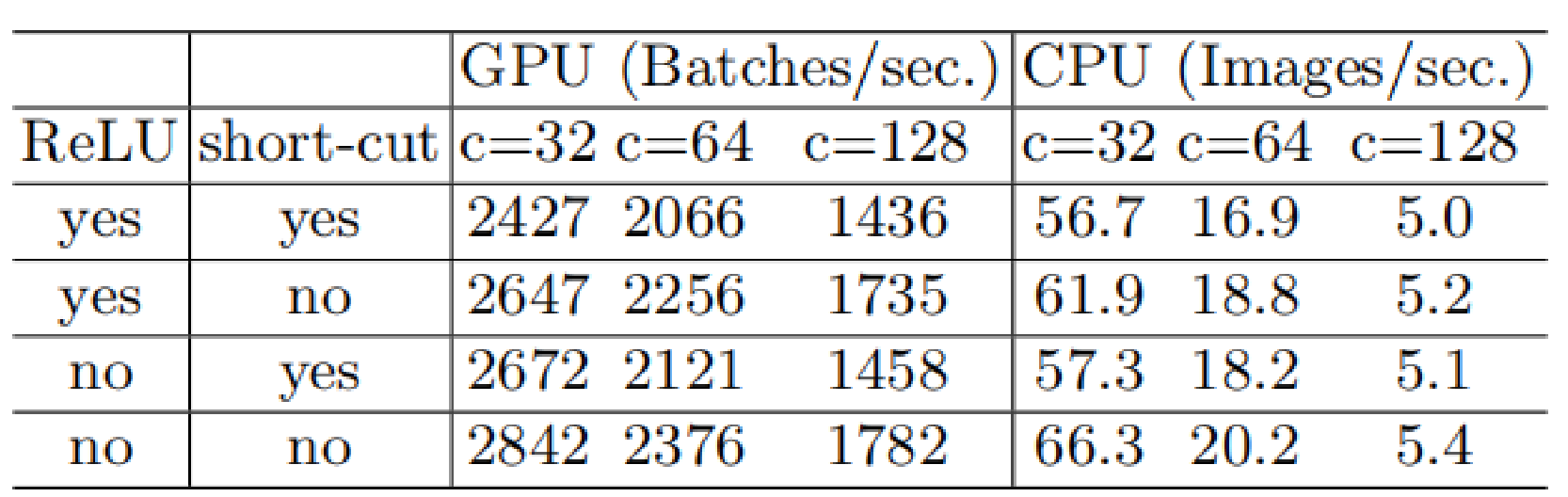
当输入输出通道相同的时候,内存访问量MAC最小,运行速度最快
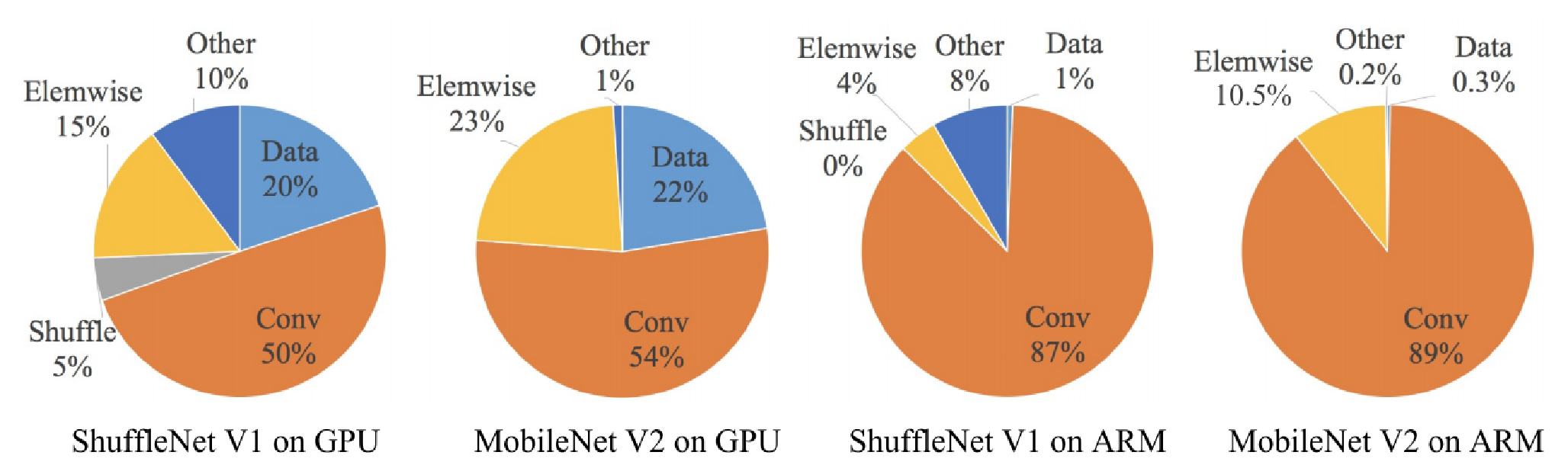
乘法-加法浮点运算次数FLOPs只反映卷积层,仅为间接的指标
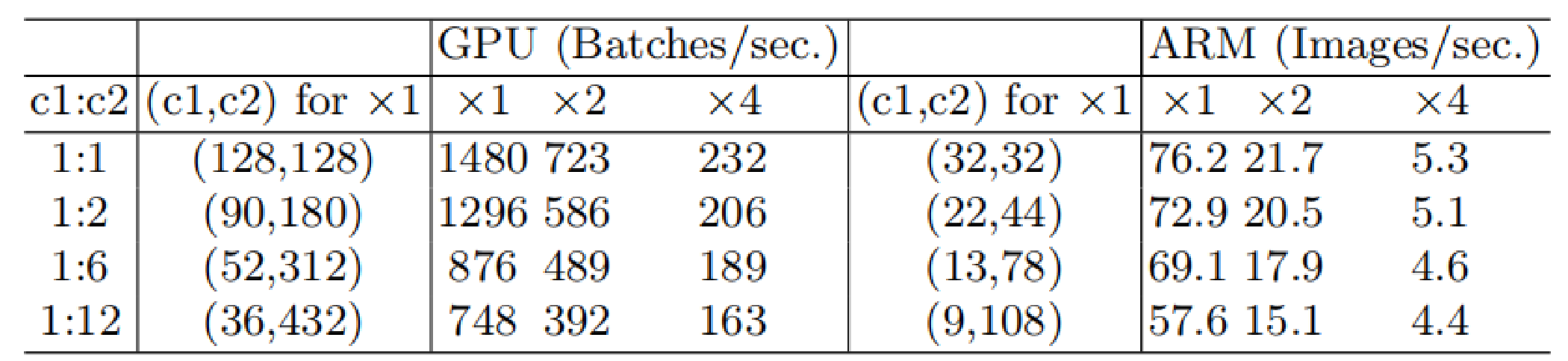
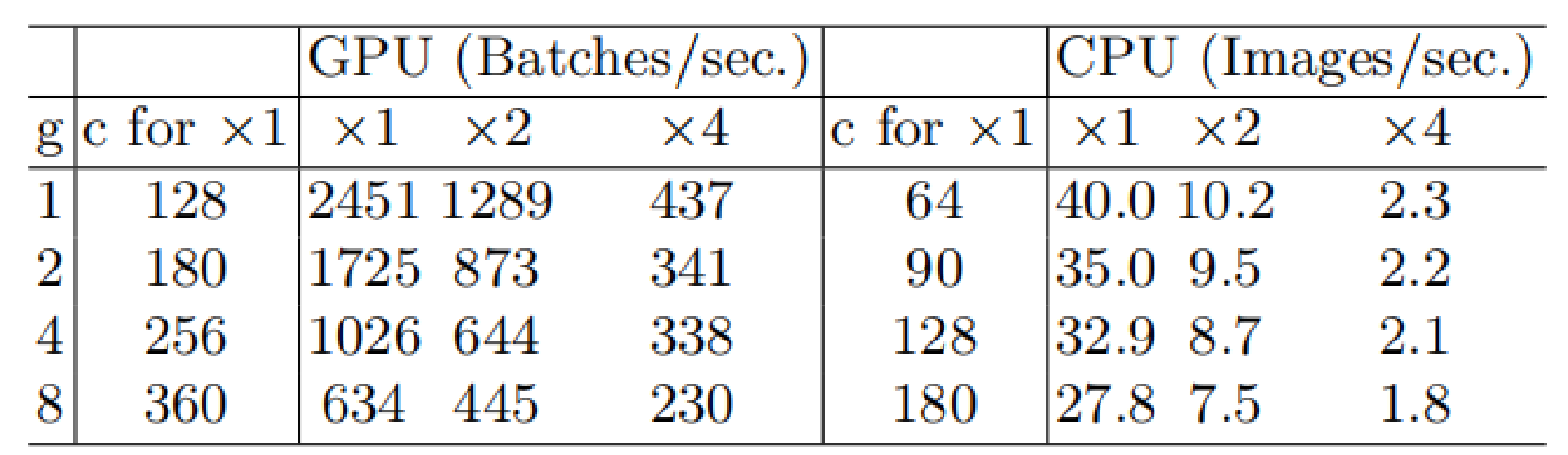
分组卷积以及过大的分组数会导致内存访问量MAC变大
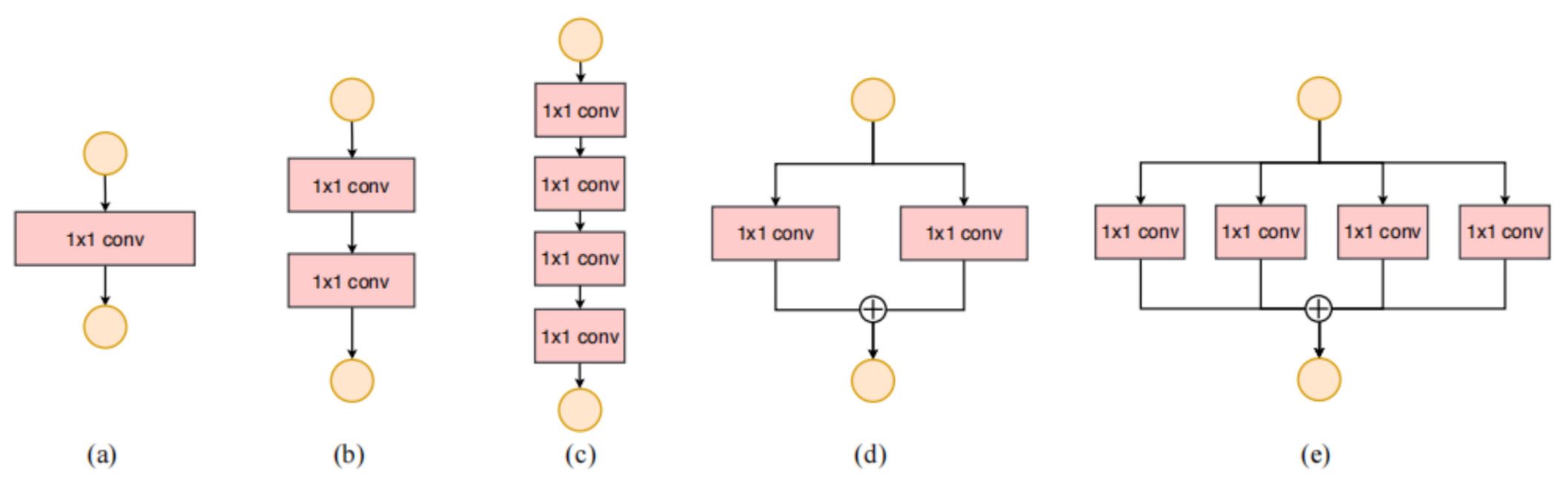
分支结构会产生碎片化并降低并行能力

逐元素操作的开销不可忽略
轻量化网络模型总结
ShuffleNet V2中提出的四条轻量化网络设计准则:
一、输入输出通道相同时内存访问量MAC最小
二、分组数过大的分组卷积会增加MAC
三、碎片化的操作对网络并行加速不友好
四、逐元素操作带来的内存和耗时不可忽略
MobileNet v2在MobileNet V1深度可分离卷积的基础上提出了具有线性瓶颈的倒置残差块,输入输出通道不一致,不满足准则一。
MnasNet提出了分层的神经网络架构搜索空间,使用NAS搜索各自基本模块,通过多目标优化的目标函数进行反馈和修正,各个block碎片化,不利用并行,不满足准则三。
MobileNet v3使用了 NAS 和 NetAdapt 算法搜索最优的模型结构,同时对模型一些结构进行了改进,在 MobileNet_V2的具有线性瓶颈的倒置残差块基础上引入MnasNet的Squeeze-and-Excitation注意力机制,不满足准则一和三。
ShuffleNet v1利用分组点卷积来降低参数量,利用通道重排操作来增强不同通道之间的交互和融合。使用分组卷积不满足准则二。
此外,所有的轻量级网络模型都是用了逐元素操作,都不满足准则四。
ShuffleNet V2 网络模块
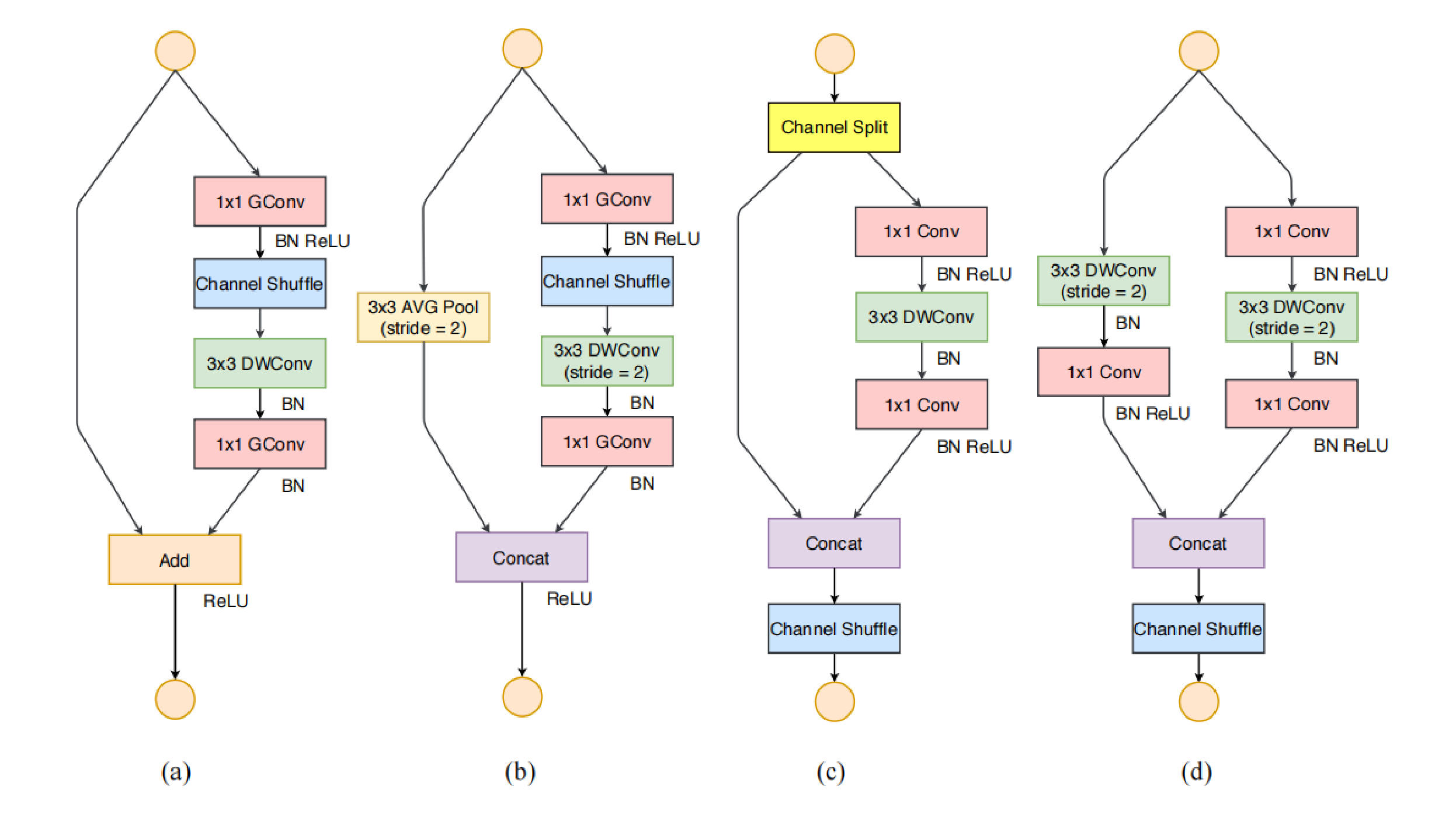
ShuffleNet V1 ShuffleNet V2
ShuffleNet V2 模型结构
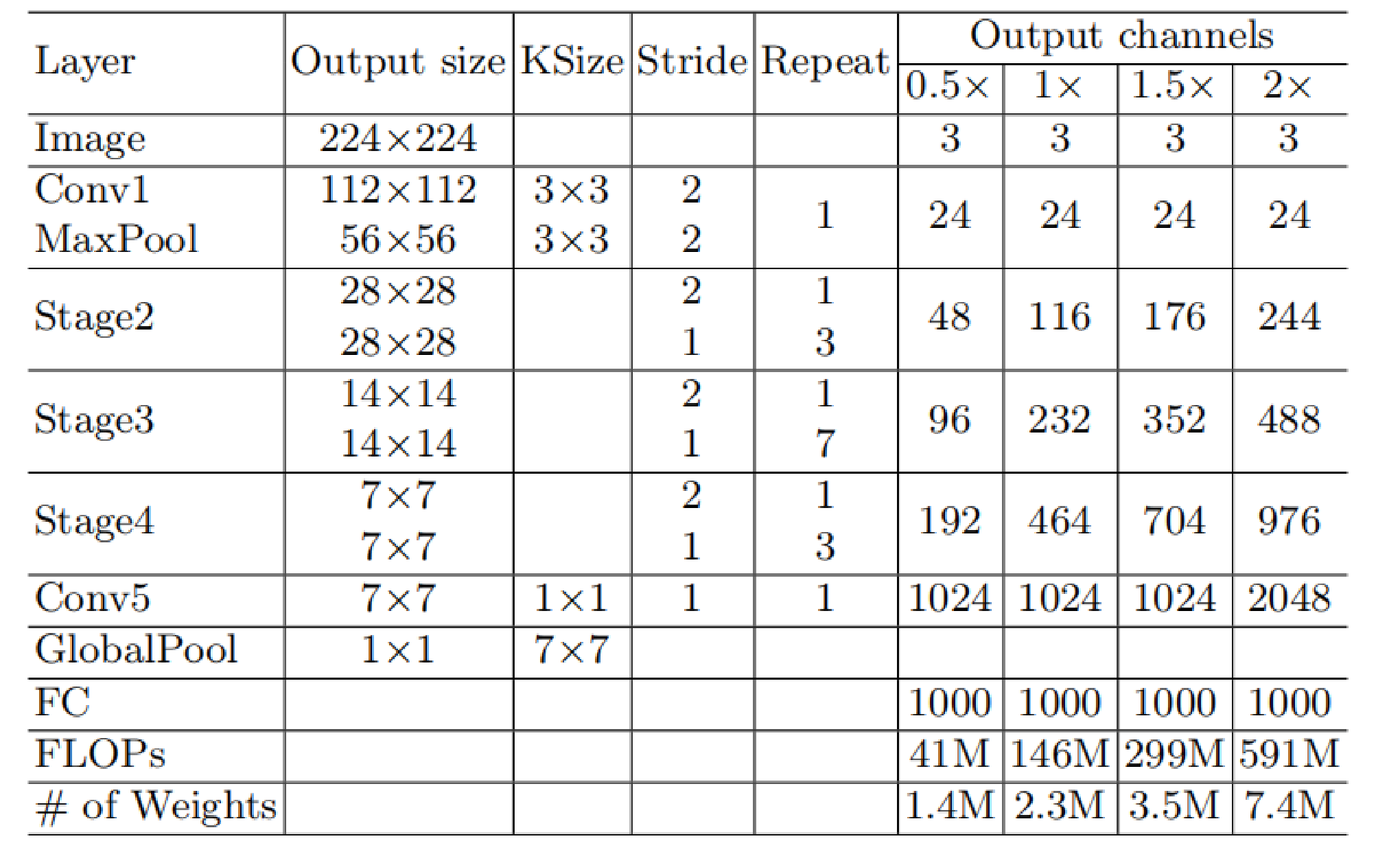
ShuffleNet V2 实验对比
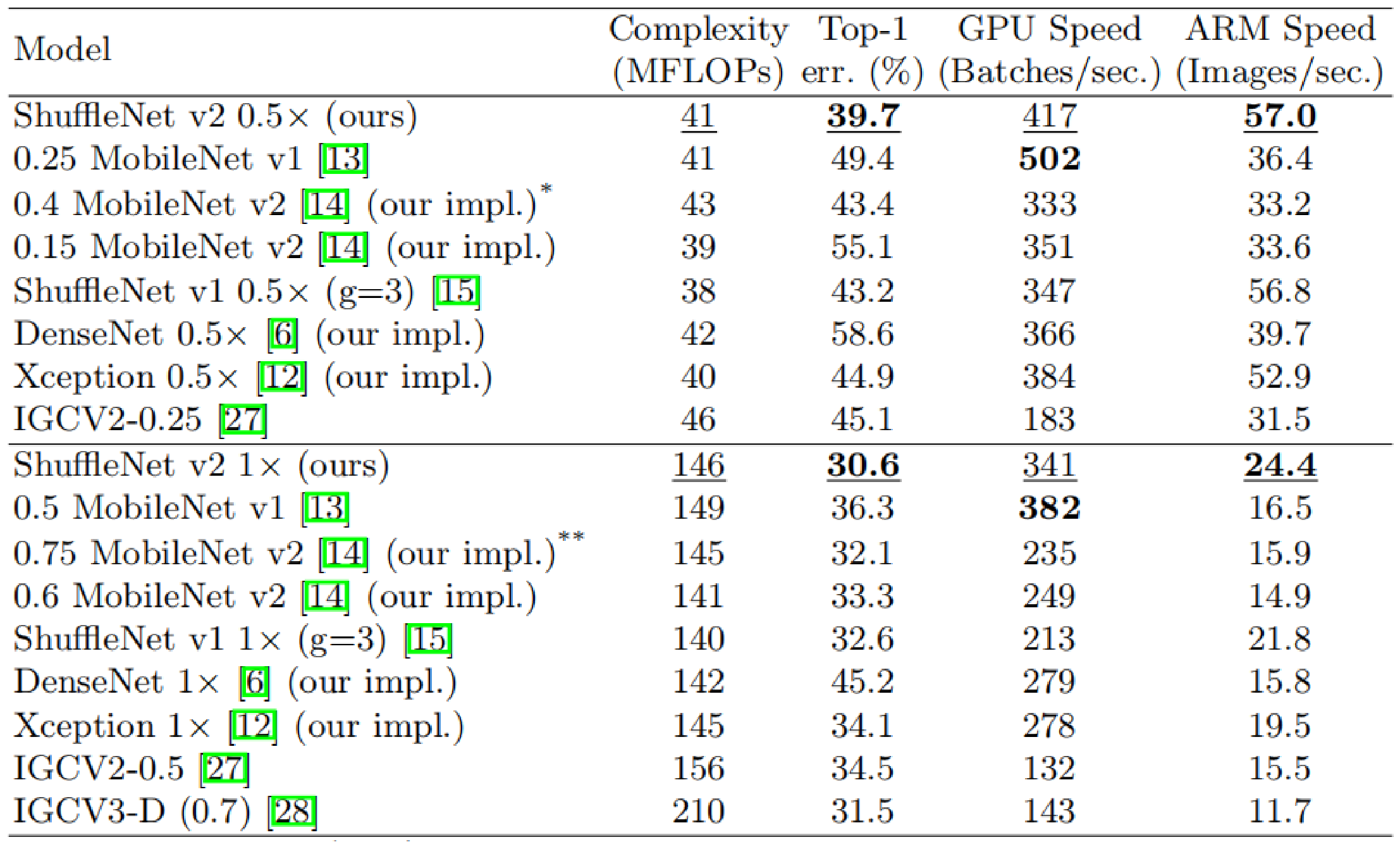
ShuffleNet V2模型总结
一、提出了四条轻量化网络模型设计原则,并根据这四条准则设计了shufflenet v2网络结构。
输入输出通道相同时MAC最小
分组数过大的分组卷积会增加MAC
碎片化操作对网络并行加速不友好
尽量避免逐元素操作
二、在相同FLOPs的情况下,ShuffleNet V2准确率比其他轻量级模型要高。
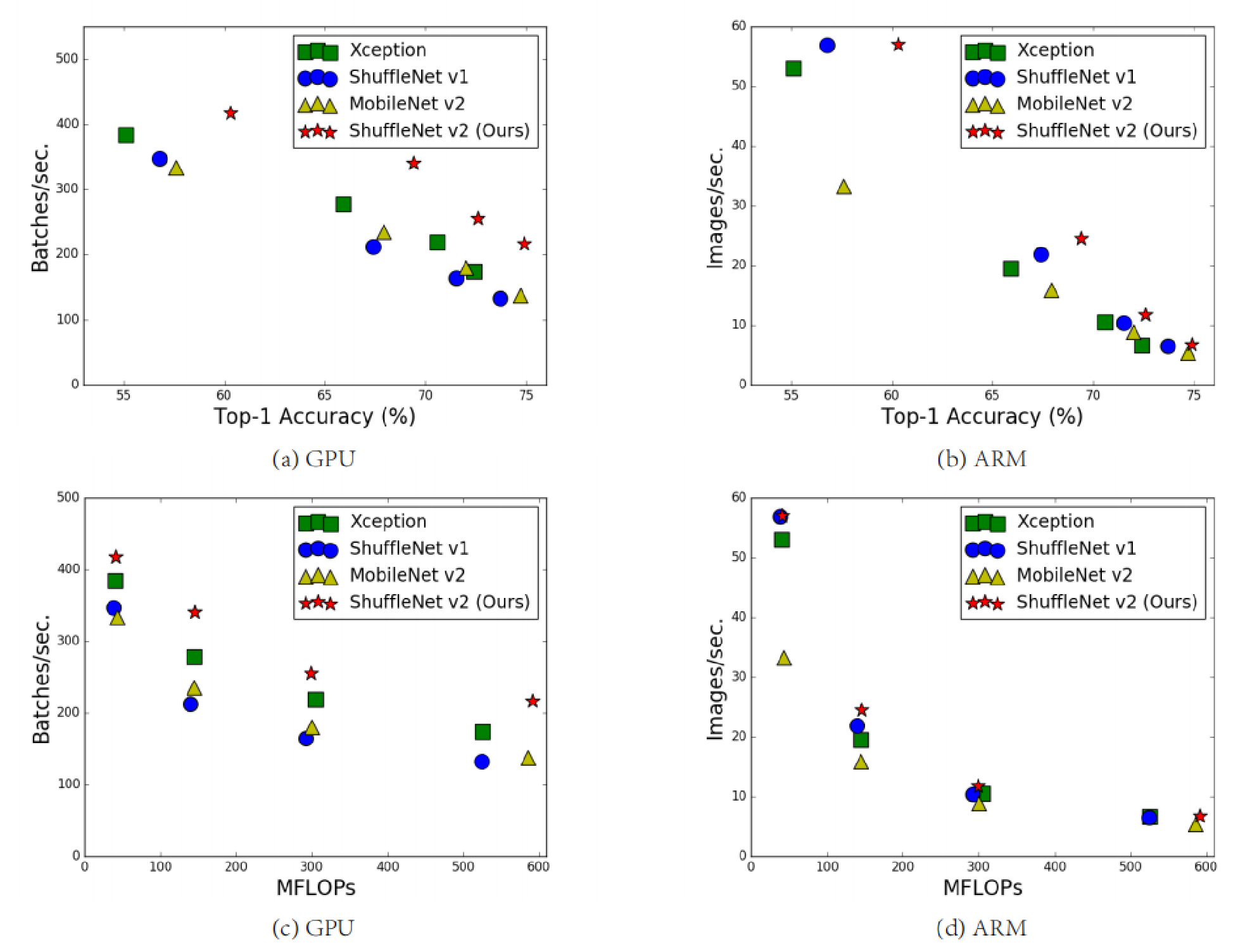
OK,至此我们以及介绍完了轻量级网络的MobileNet系列包括(MobileNet V1,MobileNet V2,MobileNet V3),MnasNet以及ShuffleNet系列包括(ShuffleNet V1,ShuffleNet V2),有兴趣的同学可以去看这几篇相关的博客,也欢迎大家一起交流~
这篇关于轻量级网络模型ShuffleNet V2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









