本文主要是介绍NAST:时间序列预测的非自回归时空Transformer模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NAST:时间序列预测的非自回归时空Transformer模型
[Submitted on 10 Feb 2021]

关注人工智能学术前沿 回复 :ts22
5秒免费获取论文pdf文档,及项目源码
摘要
虽然Transformer在很多领域取得了突破性的成功,特别是在自然语言处理(NLP)领域,但将其应用于时间序列预测仍然是一个巨大的挑战。在时间序列预测中,规范化 Transformer模型的自回归译码不可避免地会引入巨大的累积误差。此外,利用Transformer来处理问题中的时空依赖性仍然面临着很大的困难。为了解决这些限制,本工作首次尝试提出一种用于时间序列预测的非自回归变压器架构,旨在克服标准变压器中的时间延迟和累积误差问题。此外,我们提出了一种新的时空注意机制,通过学习时间影响图来搭建一座桥梁,填补时空注意之间的空白,从而实现时空依赖关系的整体处理。以经验为基础,我们在多种以自我为中心的未来定位数据集上评估了我们的模型,并在实时性和准确性方面展示了最先进的性能。
1.介绍
考虑到在各个领域中广受赞誉的巨大优势和超越rnn的巨大潜力,Transformer可以成为处理时间序列预测问题的理想候选。
关键问题
1.现有的Transformer用于时间序列预测的解码机制,如图1(a)所示,并不直接适用,不够有效。
时间序列预测本质上是一个具有连续输入的回归任务,这与具有离散输入的自然语言处理中的分类任务明显不同。因此,典型的自回归(AR)解码不能有效地处理时间序列处理问题,主要是因为前n-1步的预测不能充分避免误差,使得第n步的条件是预测累积误差高,导致不满意的最终预测性能。此外,只使用编码器的方法是AR解码方法的简单变体,利用变压器编码器作为特征提取器和多层感知器(MLP)或卷积层块作为解码器。虽然这种方法可以在一定程度上消除累积错误,但它并不能从强大的注意机制中获益。
2.不同的时间序列数据通常具有很强的空间依赖性,例如交通流和基于骨架的动作序列。如图1(b)所示,在探索Transformer体系结构中空间和时间依赖的建模过程中,以前的工作可以根据它们连接空间和时间信息的不同方式(即并行方式或堆叠方式)分为两类。并行方式分别提取时空特征,然后聚合它们(Plizzari et al., 2020;Aksan等人,2020年)。而堆叠方式交替处理时间和空间相关性(Xu et al., 2020)。我们认为,在联合建模中,它们都没有完整地考虑时空依赖关系,因为在学习和预测空间关注时忽略了时间依赖关系。

作者的解决思路
为了解决上述具有挑战性的局限性,我们提出了一种新的时空转换器用于时间序列预测问题。首先,我们设计了一个非自回归(Non-Autoregressive, Non-AR)变压器架构,并提出了一个嵌入式查询生成块(Query Generation Block, QGB)作为该问题的核心模块。QGB在一个步骤内生成查询,查询的长度与目标序列相同。然后,利用生成的查询,我们的时空转换器解码器能够并行地执行预测。这样不仅可以大大避免累积错误,而且解码器可以更有效地从注意机制中获益。此外,相对于现有的并行和堆叠方式,我们提出了一种新的时空注意机制,以一个整体的方式联合建模时空依赖。首先,我们将输入特征嵌入到高维张量中,并沿空间和时间预测空间和时间注意地图。然后,我们对时间注意图进行换位,得到时间影响图,再用时间影响图与空间注意进行产品操作,得到联合学习的整体时空注意图。:
2.模型概述
具体内容涉及到大量公式介绍与推导过程,如果需要,请获取论文资源,自行研究。
关注人工智能学术前沿 回复 :ts22
5秒免费获取论文pdf文档,及项目源码
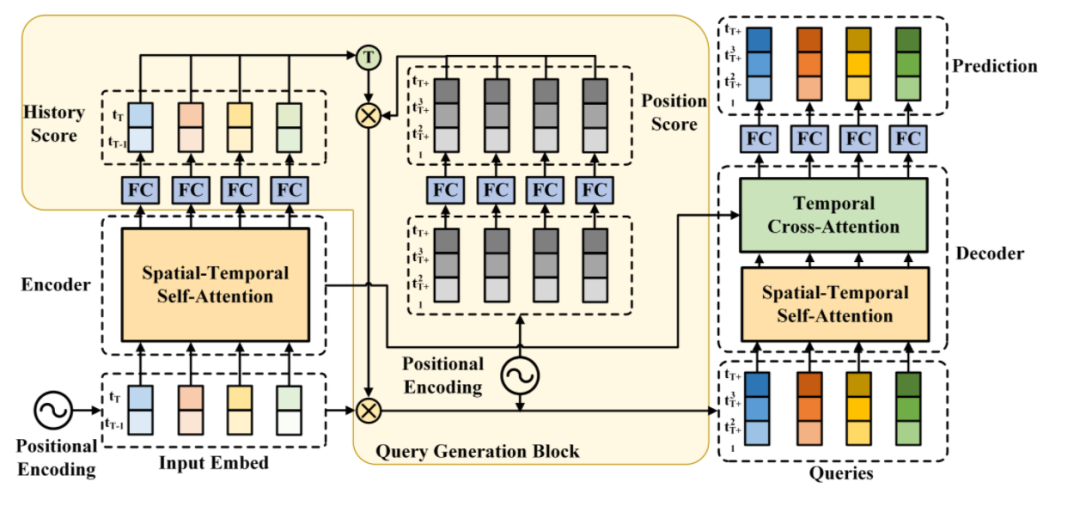
图2。提出的非自回归时空转换器(NAST)的架构说明。与规范的Transformer相比,在编码器和解码器之间插入了一个查询生成块(Query Generation Block, QGB)。采用一种新的时空注意机制对编码器和解码器中的自我注意进行建模和学习,从而对时空依赖性进行整合处理。FC表示全连接网络。
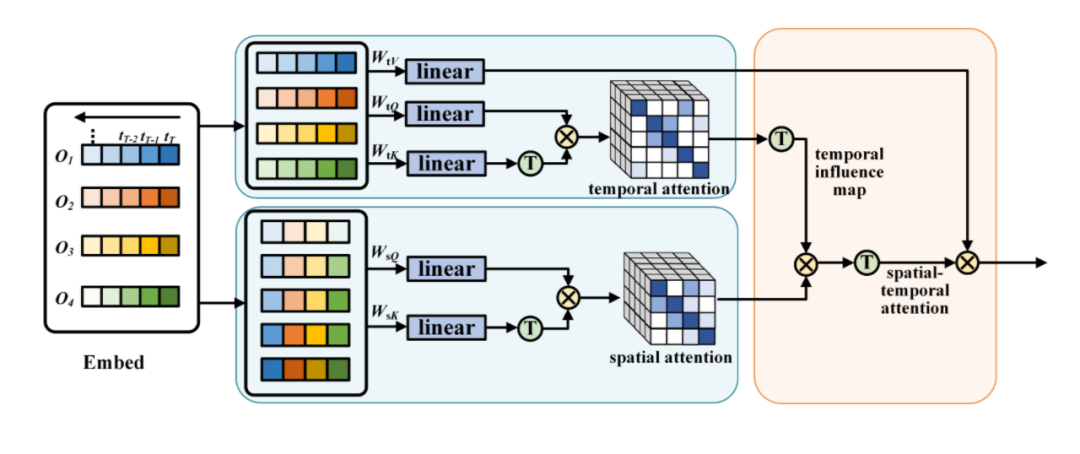
图3。时空注意力块。在该块中,沿输入特征的空间和时间预测空间和时间注意图。然后,对时间注意图进行移位操作,得到时间影响图,再利用时间影响图与空间注意进行产品操作,得到共同学习的时空注意图。
3.实验概述
数据集
NuScenes
作为一个巨大的自动驾驶数据集,NuScenes (Caesar等人,2020)包含1000个场景,每个场景拥有20秒。
SMARTS-EGO
一个名为SMARTS- ego的以自我为中心的大规模未来定位数据集,该数据集包含7700个场景,每个场景拥有10秒的时间。
对比模型
为了评估性能,我们将我们提出的模型与一个基于rnn的模型和两个基于transformer的模型进行比较,这两个模型代表了各种先进的方法。
RNN-ED:
姚等(2019a)提出的RNN-ED是一种基于rnn的编码器-解码器模型。我们去掉了它的光流编码分支,保留了所有其他设置。
Transformer:
我们遵循Wu等人(2020)提到的AR方式,将规范Transformer应用于此任务。另外,其他设置与我们的模型相同。
TST-NoLogSparse:
时间序列变压器(Time-Series Transformer, TST)由Li等人(2019)提出。作者只发布NoSparse版本,因此我们在任务中只验证它,所有其他设置都与原始设置相同。
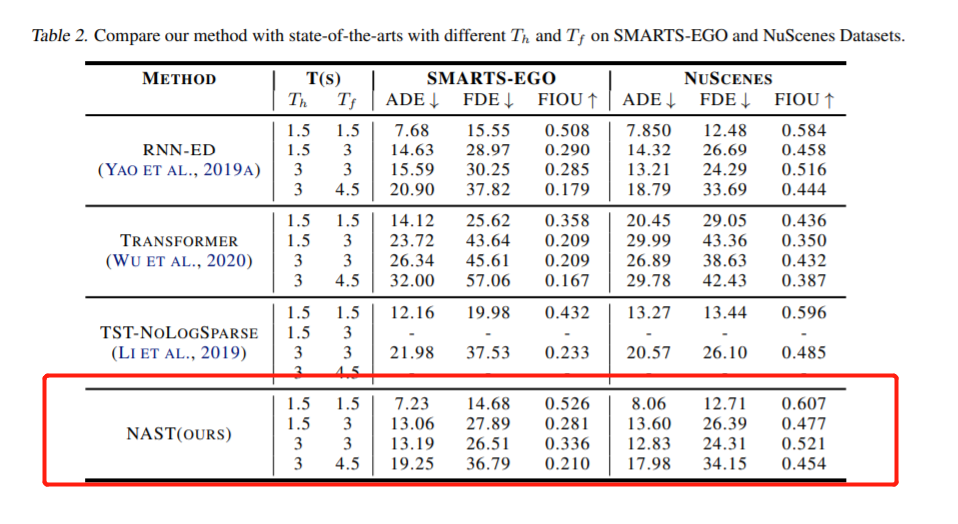
实验结果
总结
本文提出了一种非自回归变压器译码,并设计了一种新的时空注意机制,以联合方式处理时空注意。这是首次尝试将非自回归变压器模型引入具有空间和时间相关性的时间序列预测。实验结果表明,时空注意机制和非自回归解码方式都是必要的和有益的。因此,我们的模型远远优于其他基于transformer的方法,并取得了优于基于rnn的方法的有效性能。对于未来的工作,我们的模型可以作为一个坚实的基线,用Transformer预测时间序列。同时,更多可解释的查询生成方法和时空关注模型仍然是迫切需要的。
这篇关于NAST:时间序列预测的非自回归时空Transformer模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








