本文主要是介绍大数据之Hudi数据湖_执行编译hudi命令和jar包位置_hudi和hive集成_和spark集成_和presto集成_和flink集成_和trino集成---大数据之Hudi数据湖工作笔记0004,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
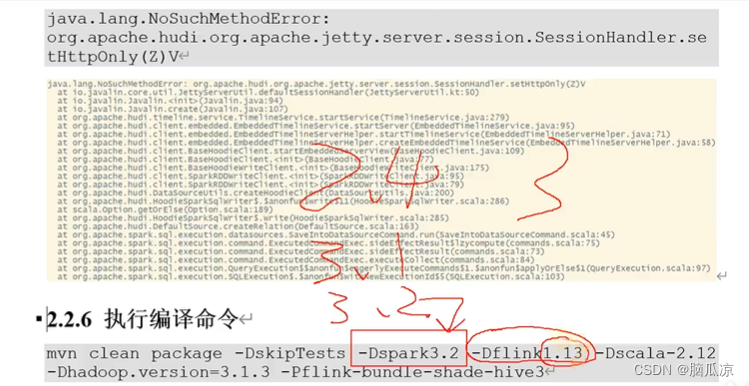
在hudi源码的根目录执行就可以了,注意要指定spark的版本上面指定的是3.2 如果不指定默认是3,最好都指定一下.

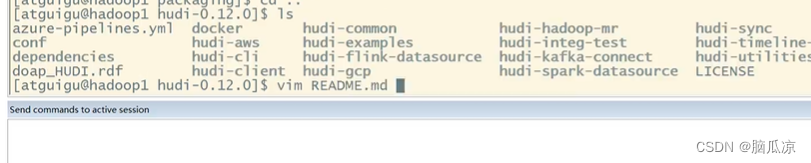
这里在执行编译之前,我们可以先去看一下在hudi的源码目录下,有个README.md
这个文件
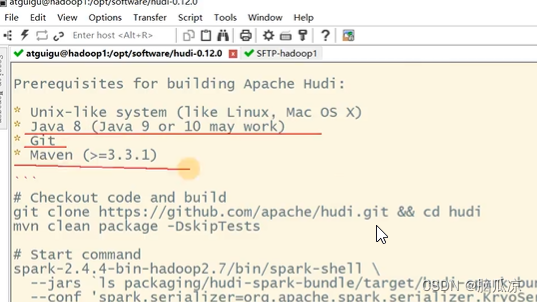
去看看她支持的java 版本和git maven版本
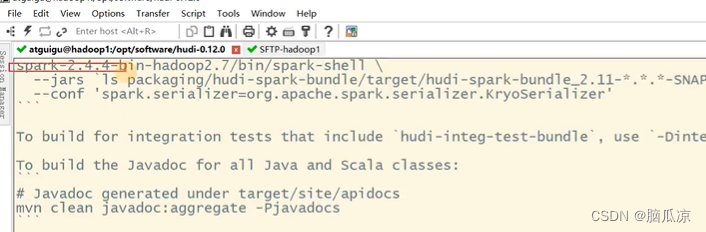
看看spark支持的版本
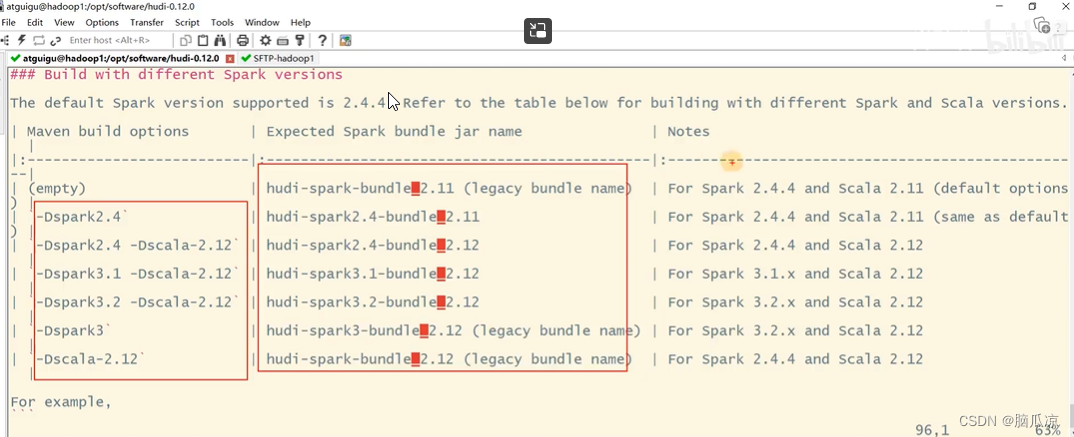
看看对应的scala的版本等.最好的就是我们这里执行命令的时候
直接给他指定版本就可以了.
这篇关于大数据之Hudi数据湖_执行编译hudi命令和jar包位置_hudi和hive集成_和spark集成_和presto集成_和flink集成_和trino集成---大数据之Hudi数据湖工作笔记0004的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





