trino专题

兼容Trino Connector,扩展Apache Doris数据源接入能力|Lakehouse 使用手册(四)
Apache Doris 内置支持包括 Hive、Iceberg、Hudi、Paimon、LakeSoul、JDBC 在内的多种 Catalog,并为其提供原生高性能且稳定的访问能力,以满足与数据湖的集成需求。而随着 Apache Doris 用户的增加,新的数据源连接需求也随之增加。因此,从 3.0 版本开始,Apache Doris 引入了 Trino Connector 兼容框架。 Tri

Trino大量查询会导致HDFS namenode主备频繁切换吗?
会,且肯定会 一、背景 今天还没起床就被智能运维叫醒了,说通过namenode审计日志查看访问源ip有我们的trino集群,并且访问量比较大,起床气范了,这不很正常吗,早上一般都是跑批高峰,也不一定是我们trino的问题,必须按时上班。 到了工位联系运维,被告知也不一定是我们的trino引起的namenode主备节点切换,因为那个时间段,有很多系统会访问大数据平台,不管怎样,既然有警告就得排查,
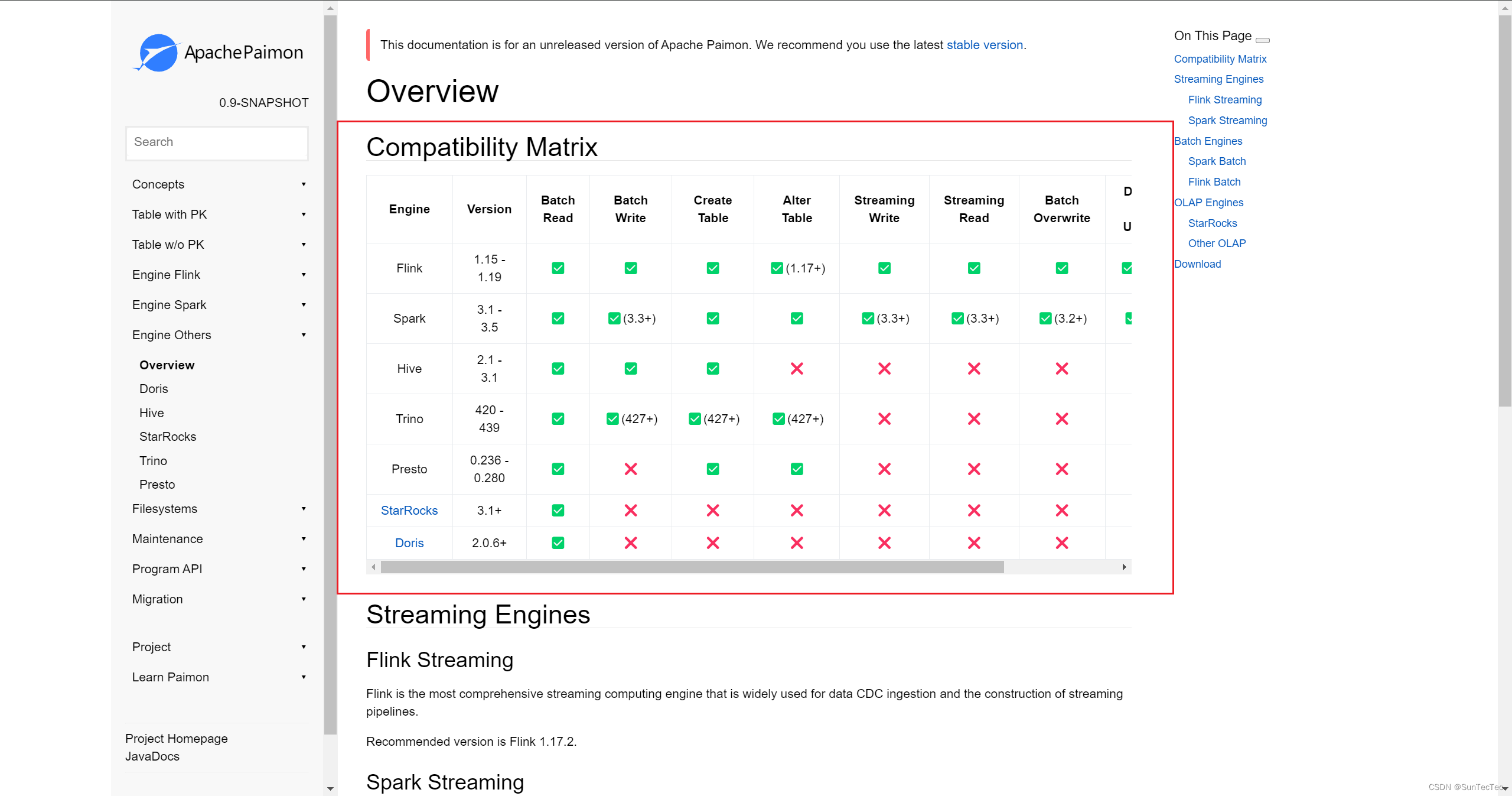
Paimon Trino Presto的关系 分布式查询引擎
Paimon支持的引擎兼容性矩阵: Trino 是 Presto 同项目的不同版本,是原Faceboo Presto创始人团队核心开发和维护人员分离出来后开发和维护的分支,Trino基于Presto,目前 Trino 和 Presto 都仍在继续开发和维护。 参考:

使用 Kubernetes 部署 MinIO 和 Trino
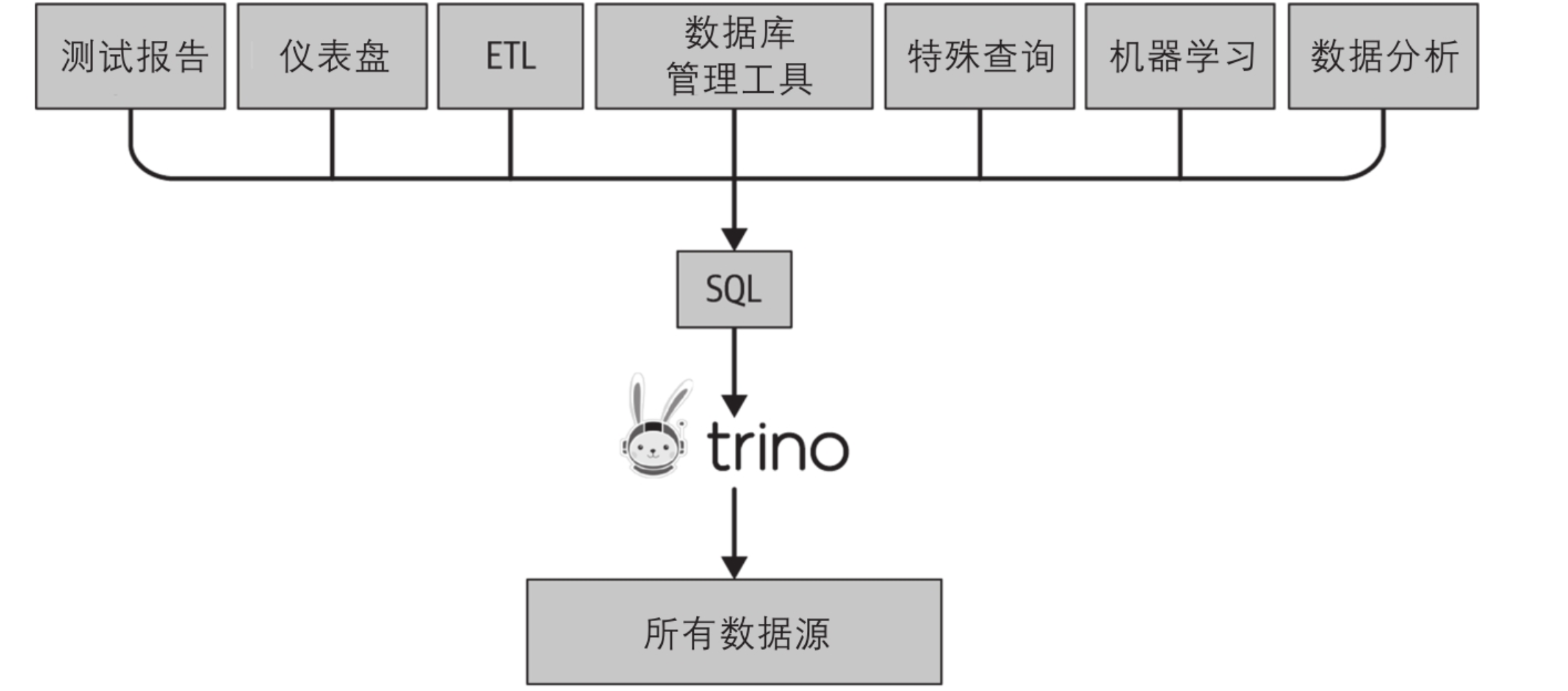
Trino(以前称为 Presto)是一个 SQL 查询引擎,而不是 SQL 数据库。Trino 避开了 SQL 数据库的存储组件,只专注于一件事 - 超快的 SQL 查询。Trino 只是一个查询引擎,不存储数据。相反,Trino与各种数据库交互或直接在对象存储上交互。Trino 解析和分析您传入的 SQL 查询,创建并优化包含数据源的查询执行计划,然后调度能够智能查询它们所连接的基础数据库
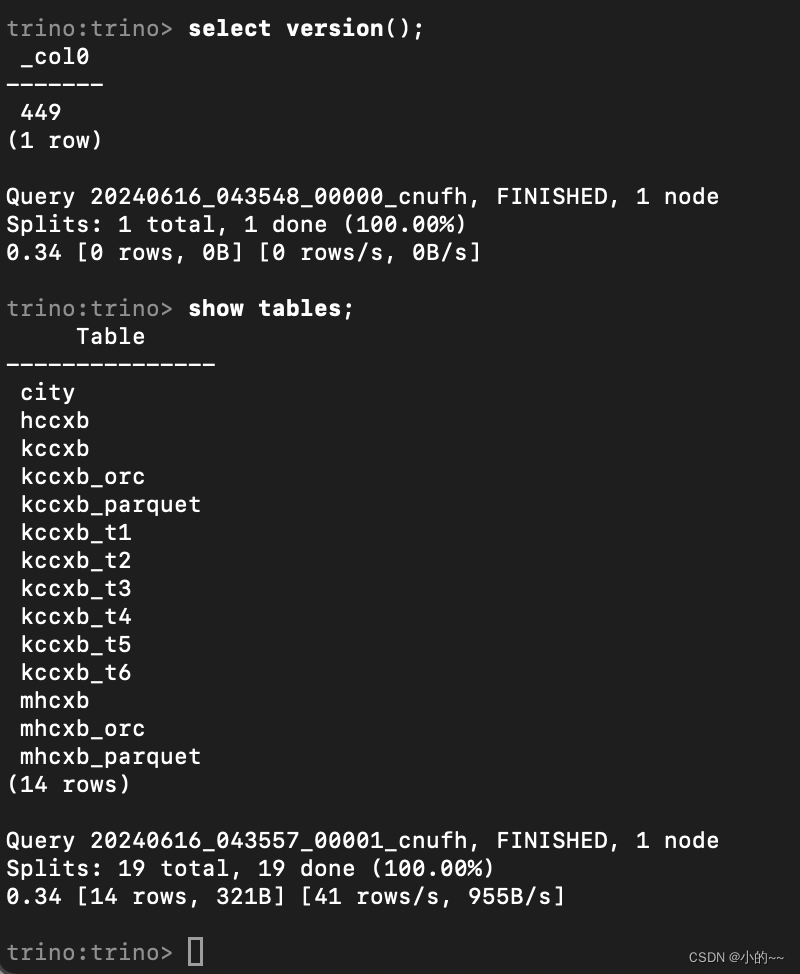
Mac M3 Pro 部署Trino-server-449
目录 1、下载安装包 2、解压并设置配置参数 3、启动并验证 4、使用cli客户端连接测试 1、下载安装包 官方:trino-server-449 CLI 网盘: server https://pan.baidu.com/s/16IH-H39iF8Fb-Vd14f7JPA?pwd=3vjp 提取码: 3vjp cli https://pan.baidu.com/s/1G
![Trino On K8S(Dockerfile)[建议]](/front/images/it_default.gif)
Trino On K8S(Dockerfile)[建议]
文章目录 Trino On K8S(Dockerfile)[建议]前期准备基础镜像下载java构建 Dockerfile编写 bootstrap.sh 脚本构建镜像 部署 Trino下载 Helm 源修改配置启动 增加 Hive Catalog挂载 core-site.xml hdfs-site.xml 配置修改 coordinator/worker configmap修改 coordina
【StarRocks系列】 Trino 方言支持
我们在之前的文章中,介绍了 Doris 官方提供的两种方言转换工具,分别是 sql convertor 和方言 plugin。StarRocks 目前同样也提供了类似的方言转换功能。本文我们就一起来看一下这个功能的实现与 Doris 相比有何不同。 一、Trino 方言验证 我们可以通过如下 SQL 来验证 Trino 的方言转换在 SR 中的效果: set enable_profile =

面经:Presto/Trino高性能SQL查询引擎解析
作为一名专注于大数据技术的博主,我深知Presto(现更名为Trino)作为一款高性能SQL查询引擎,在现代数据栈中的重要地位。本文将结合我个人的面试经历,深入剖析Trino的核心特性和应用场景,分享面试必备知识点,并通过代码示例进一步加深理解,助您在求职过程中游刃有余地应对与Trino相关的技术考察。 一、面试经验分享 在与Trino相关的面试中,我发现以下几个主题是面试官最常关注的:
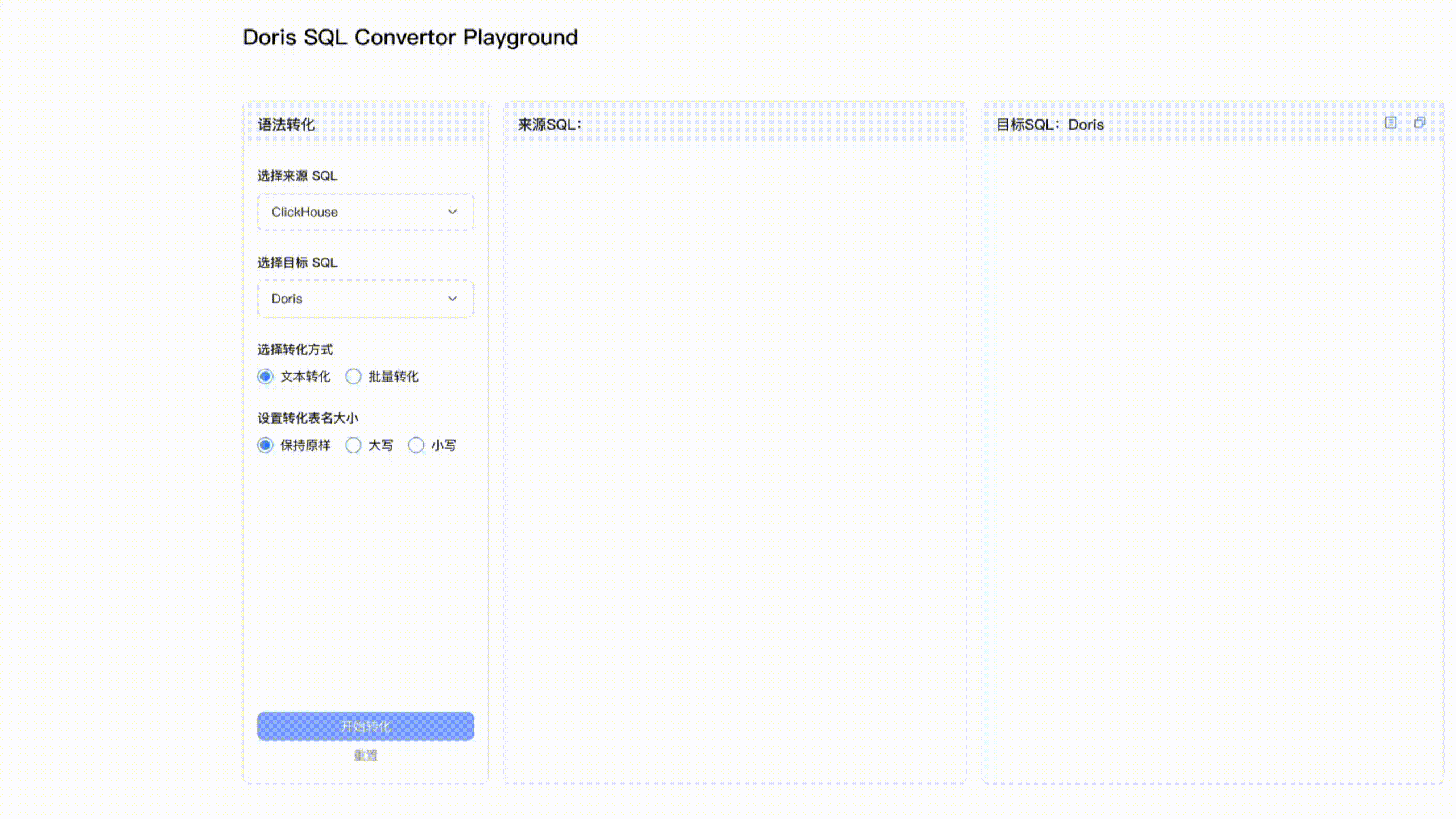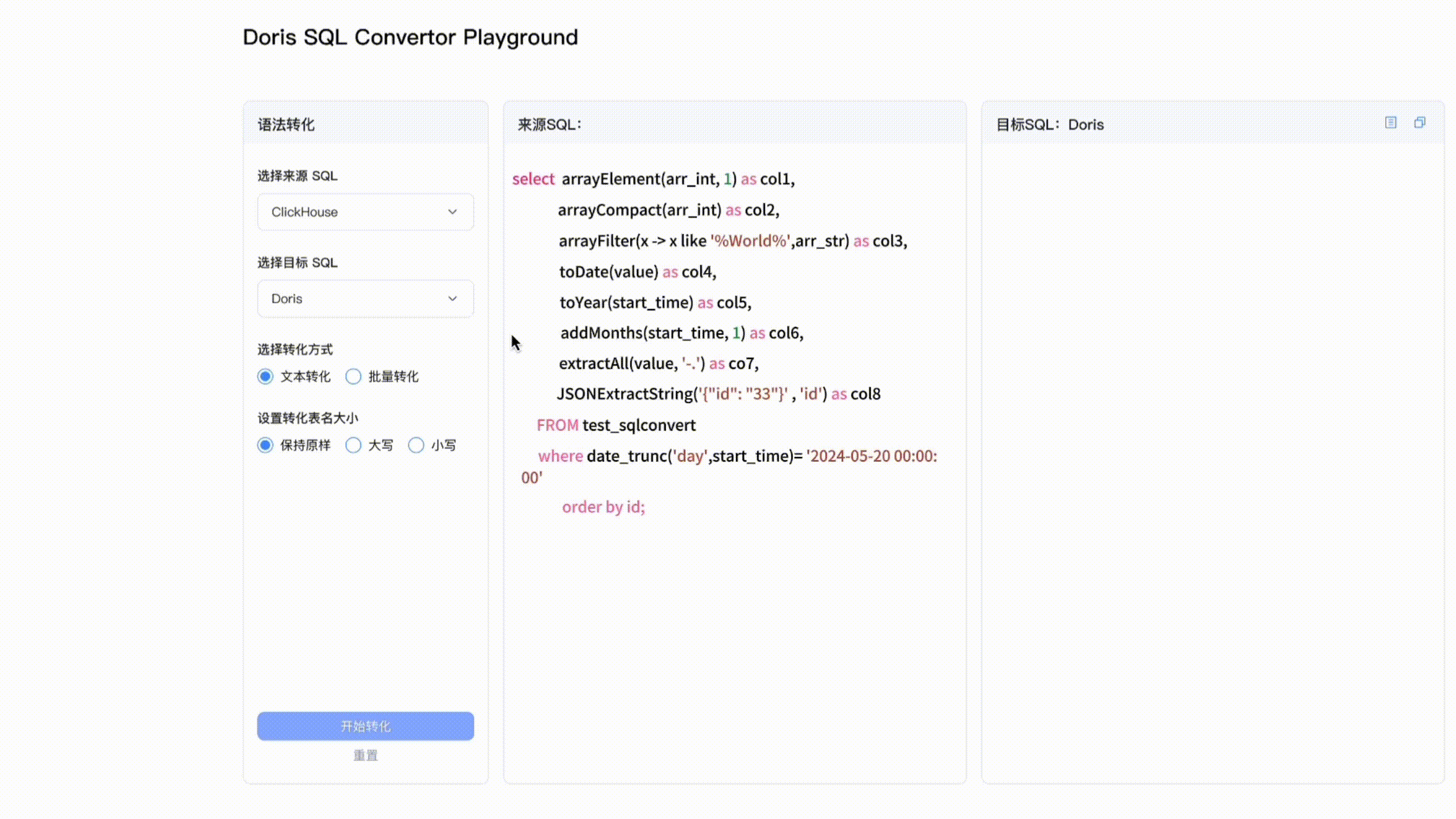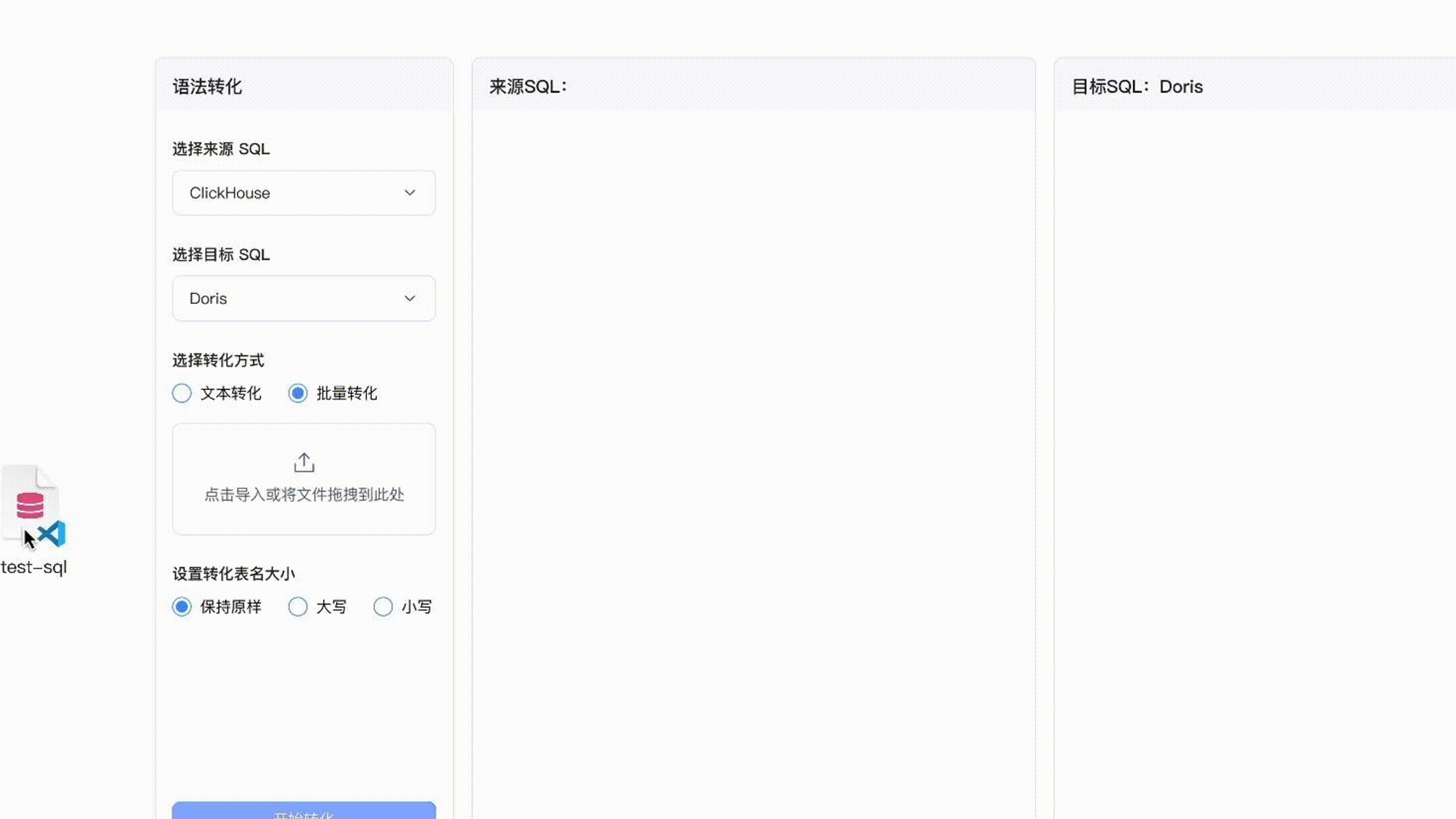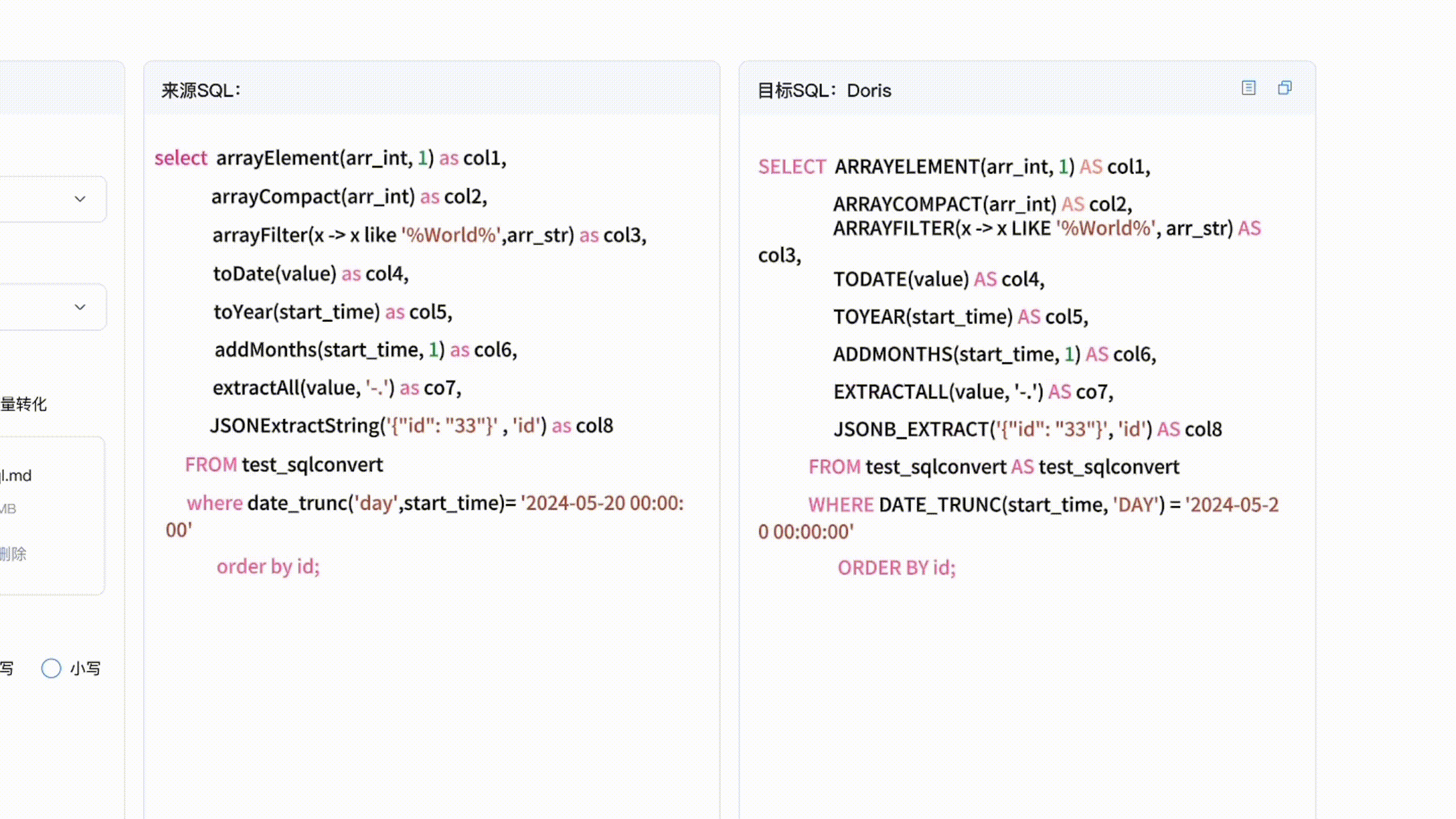
兼容 Presto、Trino、ClickHouse、Hive 近 10 种 SQL 方言,Doris SQL Convertor 解读及实操演示
随着版本迭代,Apache Doris 一直在拓展应用场景边界,从典型的实时报表、交互式 Ad-hoc 分析等 OLAP 场景到湖仓一体、高并发数据服务、日志检索分析及批量数据处理,越来越多用户与企业开始将 Apache Doris 作为统一的数据分析产品,以解决多组件带来的数据冗余、架构复杂、分析时效性低、运维难度大等问题。 然而在架构统一和升级的过程中,由于部分大数据分析系统有自己的 SQL
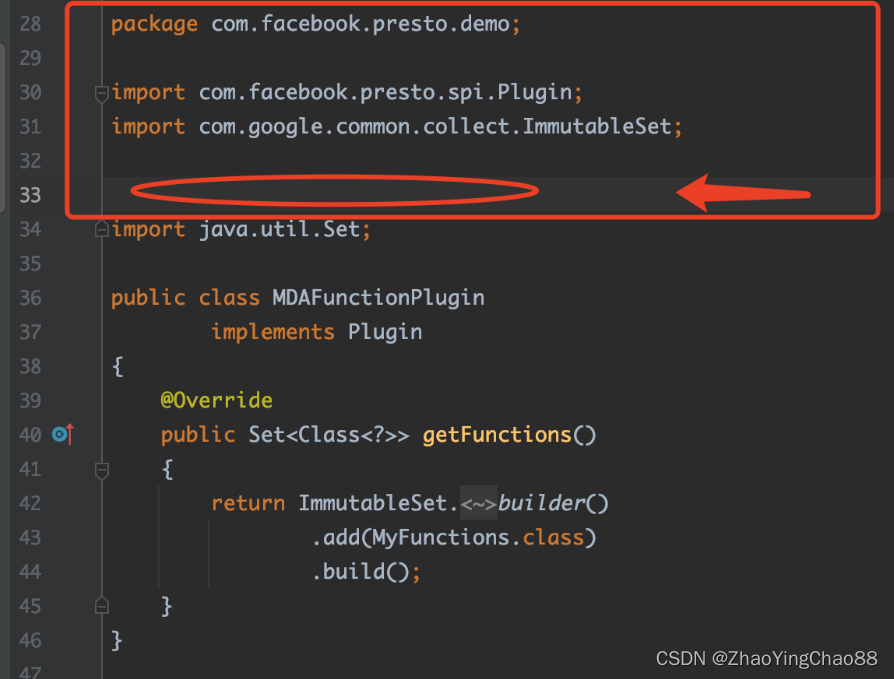
presto / trino plugin(自定义UDF函数)开发指南
方案1:自定义udf插件开发 1. Presto插件机制 presto不能像hive那样配置自定义的udf,而是采用插件机制实现。Presto 的插件(Plugin)机制,是 Presto 能够整合多种数据源的核心。通过实现不同的 Plugin,Presto 允许用户在不同类型的数据源之间进行 JOIN 等计算。Presto 内部的所有数据源都是通过插件机制实现, 例如 MySQL、Hive、

大数据之Trino高可用方案
系统架构 2、keepalive安装 2.1、安装(2台机器) yum install -y keepaliveduseradd keepalived_scriptecho keepalived_script | passwd --stdin keepalived_script 2.2、编写coordinator服务存活检测脚本(两台机器都需要) vim /usr/bin/c

trino-435:prune worker catalogs
一、前言 上一章节我们dynamic catalog restful API开发,其中catalog删除API仅仅在coordinator节点操作就可以了,那么woker几点的catalog是怎么与worker几点保持一致的呢?这一章节就重点介绍prune worker catalogs是如何做到的。 二、coordinator节点CatalogPruneTask类 在该类中存在如下的定时调
trino-435:dynamic catalog restful API开发
前置内容 restful API开发所在的位置core->trino-main->metadata模块下。主要实现查看已有catalog、注册catalog实现动态扩展、catalog的删除操作。coordinator和worker节点对该功能接口的实现是有区别的: coordinator节点包含查看已有catalog、注册catalog实现动态扩展、catalog的删除操作这三个功能。coo
trino-435: 理论基础
一、trino介绍 Trino是⼀种⽀持使⽤ SQL 访问任意数据源的 开源的分布式SQL 查询引擎,其能够提供更加灵活与⾼效的查询服务。为不同的异构数据源提供统⼀的sql访问,并⽀持联邦查询和并⾏查询。 应⽤场景 Trino是定位在数据仓库和数据分析业务的分布式SQL引擎,适合以下应⽤场景: • 统⼀SQL访问各类数据源 • 执⾏sql转换与ETL • Ad-Hoc查询 • 海量结构化数据或
trino-435:dynamic catalog
一、背景: trino对于数据源的注册方式为静态注册,在服务启动前需要配置好相关数据源的信息,当添加新的数据源时需要停止服务进行数据源的静态注册然后在重启服务;由于该操作可能会中断正在执行的任务,因此生产环境中这种方式是不可取的。为此再生产环境中需要进行数据源的动态配置,以满足生产环境的需求。在github trino issue Dynamic Catalogs #12709(https://
【Trino权威指南(第二版)】Trino的架构、trino架构组件、 trino连接器架构的细节、trino的查询执行模型
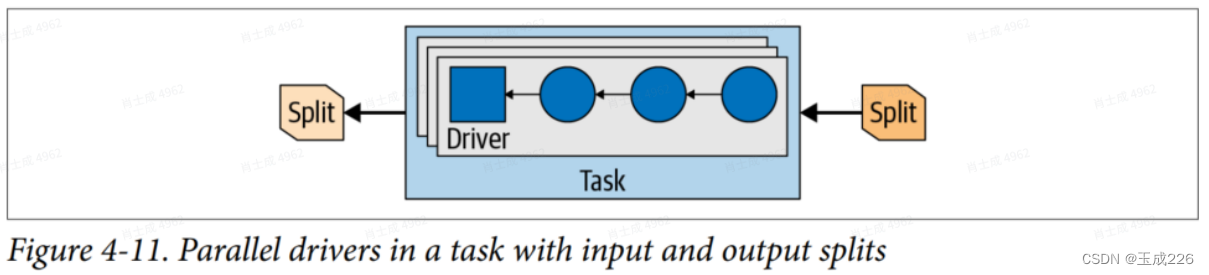
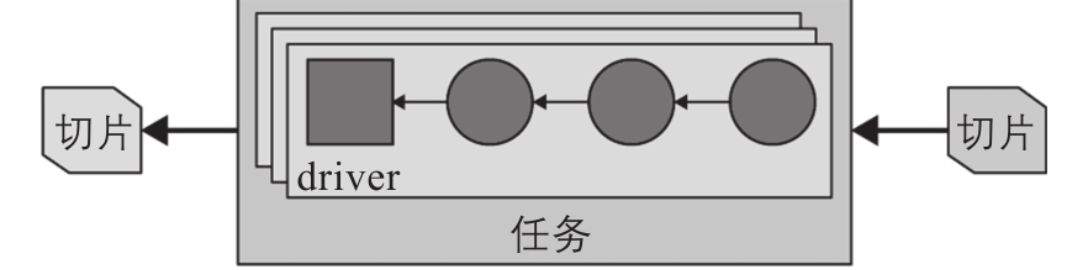
文章目录 一. Trino架构1. 架构概览2. 协调器3. 发现服务4. 工作节点 二. 基于连接器的架构三. 查询执行模型1. 解析—>查询计划2. 查询计划 —> 分布式查询计划3. 运行阶段3.1. 基础概念切片:并行单元page 与 exchange算子pipeline切片的driverOperator 3.2. running 概述 本文主要讨论了 Trino的
【Trino权威指南(第二版)】Trino介绍:trino解决大数带来的问题
文章目录 一. 大数据带来的问题二. Trino来救场1. 为性能和规模而生2. SQL-on-Anything3. 数据存储与查询计算资源分离 三. Trino使用场景 一. 大数据带来的问题 数据现状 数据存储机制日益多样:关系型数据库、NoSQL数据库、文档数据库、键值存储和对象存储系统等。对于当今的组织结构,它们当中很多是必备的,只使用其中一种已经不够了。 数据分
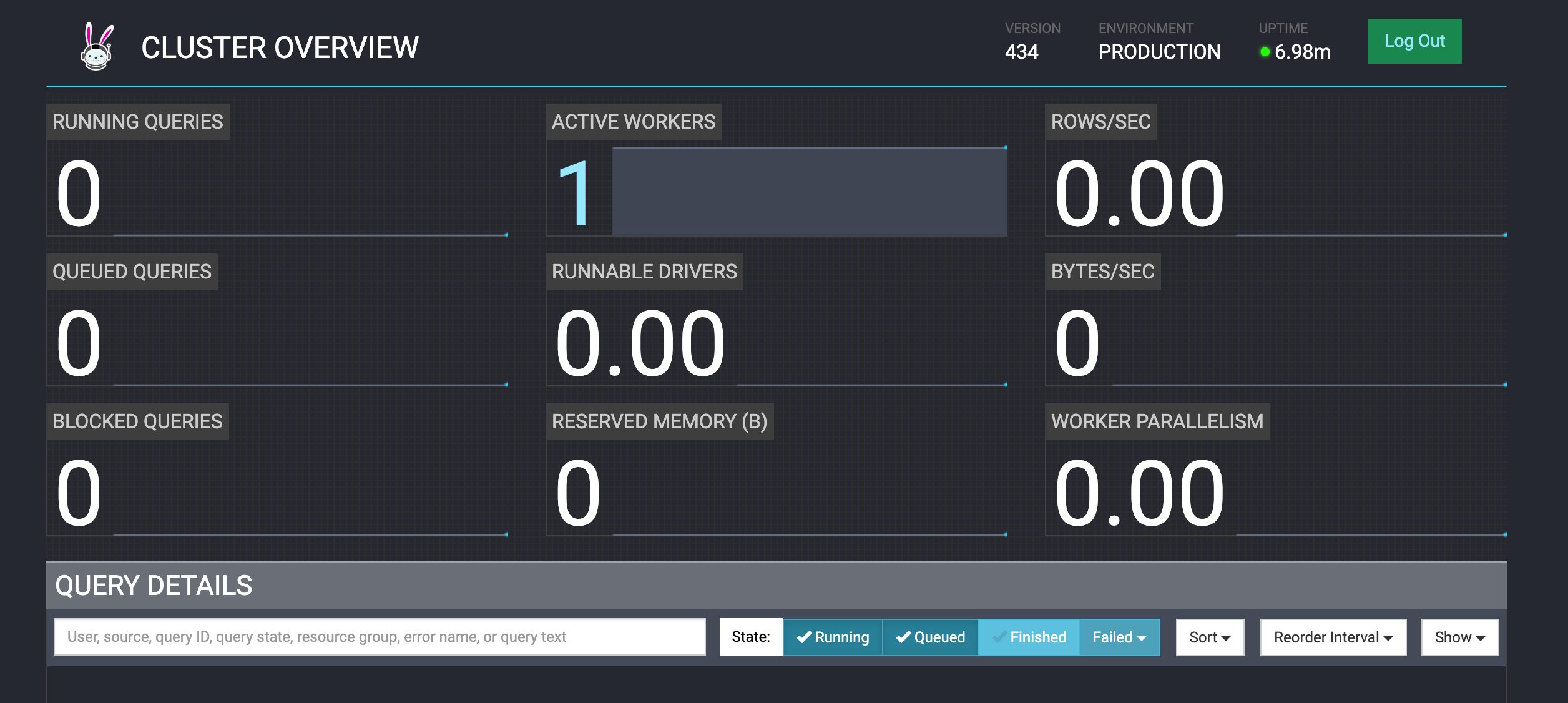
【部署】Deploying Trino on linux
文章目录 一. Requirements1. Linux operating system2. Java 环境3. Python 二. Installing Trino三. Configuring Trino1. 节点配置2. JVM 配置3. Config properties4. Log levels5. Catalog properties 四. Running Trino
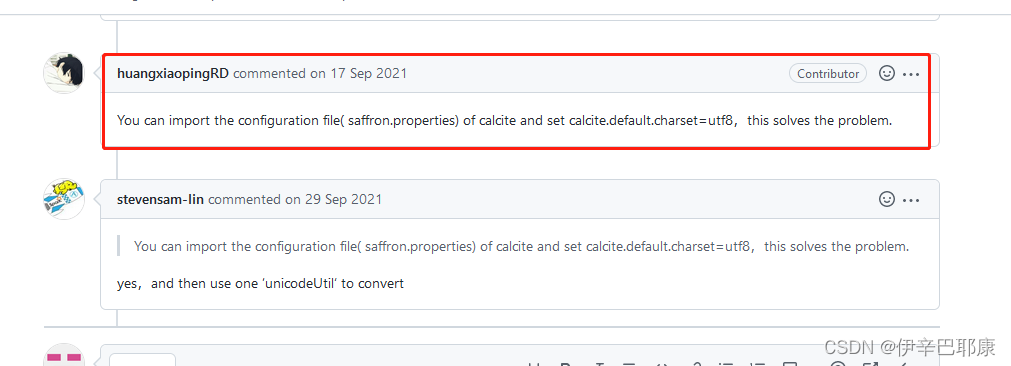
在使用Coral-trino翻译Hivesql2PrestoSql遇见的问题和解决方法
随着公司业务的发展,hive, kylin在用户的即时查询时,越来越难以满足用户快速的需求。另外最近Presto在大数据即时查询方面性能越来越来,很多企业都在接入和使用presto,网上相关的技术文章很多,因此,我们在接入Presto查询引擎以后,也不得不处理Sql路由的问题。现在数据分析师和数据ETL开发的同学已经习惯了Hive常用的写法,虽然prestoSql 与hiveSql在语法方法很接近
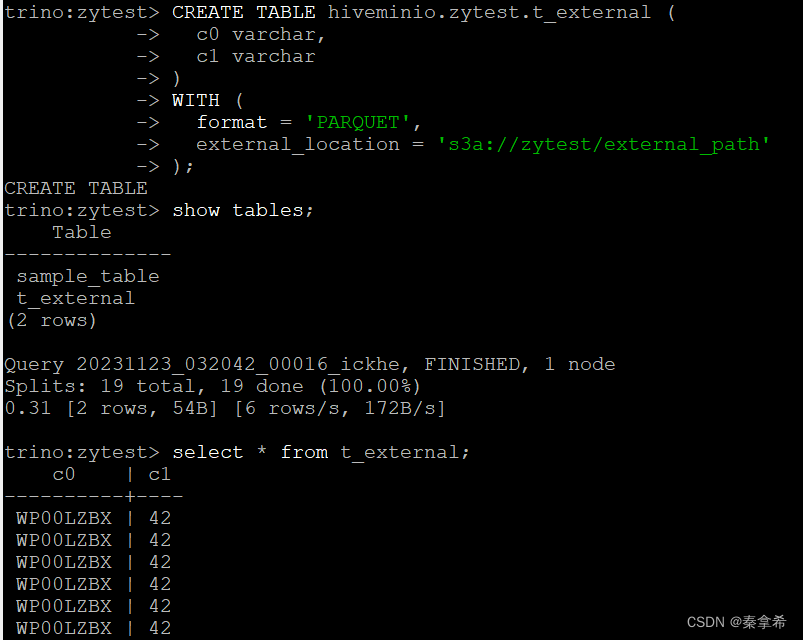
【大数据】Docker部署HMS(Hive Metastore Service)并使用Trino访问Minio
本文参考链接置顶: Presto使用Docker独立运行Hive Standalone Metastore管理MinIO(S3)_hive minio_BigDataToAI的博客-CSDN博客 一. 背景 团队要升级大数据架构,需要摒弃hadoop,底层使用Minio做存储,应用层用trino火spark访问minio。在使用trino访问minio时,需要使用hive的metastor
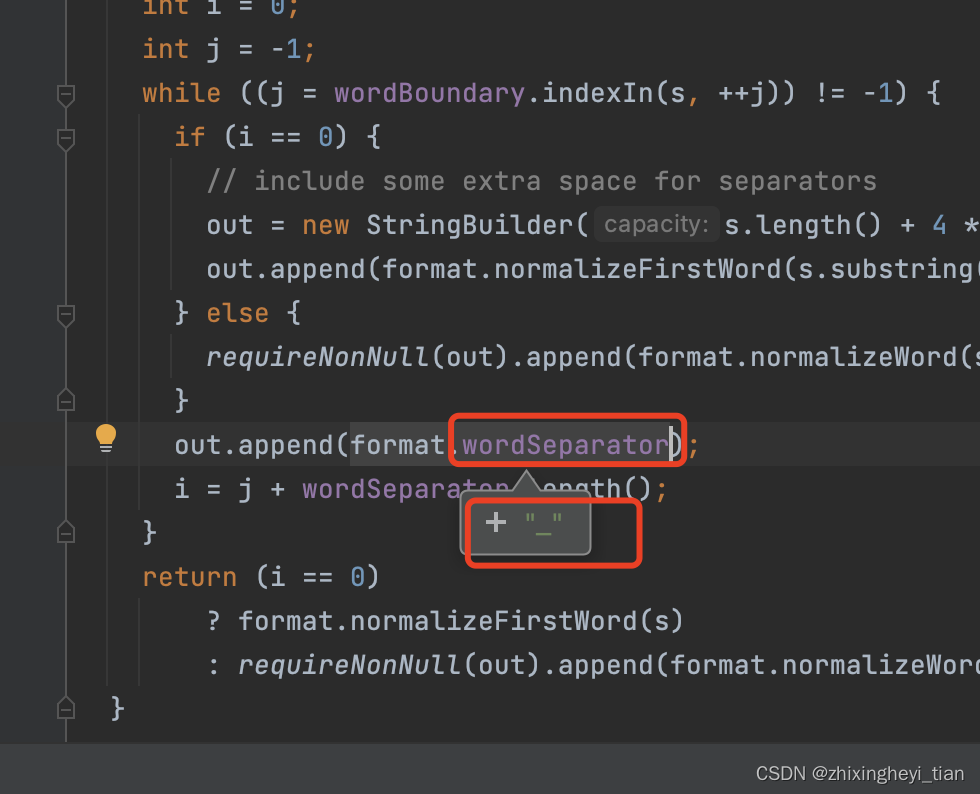
Trino 源码剖析
Functions function 反射和注册 io.trino.operator.scalar.annotations.ScalarFromAnnotationsParser 这里是提取注解元素的方法 String baseName = scalarFunction.value().isEmpty() ? camelToSnake(annotatedName(annotated)) :
Trino文档 - 概览(新)
概览 使用案例Trino 不能做什么Trino 可以做什么 1.2 Trino 概念概览Server类型Coordinatorworker 数据源ConnectorCatalogSchemaTable Query执行模型StatementQueryStageTasksplitDriver OperatorExchange Trino 是一个分布SQL查询引擎,设计用来查询大的分
trino(prestoSQL 329)文档 - 1.概览
概览 1.1 使用案例Prosto 不能做什么Presto可以做什么 1.2 Presto概念介绍Server类型Coordinatorworker 数据源ConnectorCatalogSchemaTable 查询模型StatementQueryStageTasksplitDriver OperatorExchange Presto 是一个分布SQL查询引擎,设计用来查询大的

基于trino实现Sort Merge Join
背景 当前,社区Trino已对Equi join场景支持了Broadcast Hash Join和Shuffle Hash Join两种Join实现。Broadcast Hash Join适用于大表与小表之间的Join,当Build Side的数据量比较小时,使用Broadcast方式将小表发送给Probe Side,避免了Hash Exchange操作,因而性能较佳。而Shuffle Hash
trino tpcds测试
先下载https://github.com/gregrahn/tpcds-kit(有Linux和macOS),根据其文档生成数据。 然后https://github.com/hortonworks/hive-testbench,在ddl-tpcds/text/alltables.sql中有建表语句(用hive建表)。 建完表后LOAD DATA local INPATH "/Users/din