本文主要是介绍【大数据】Docker部署HMS(Hive Metastore Service)并使用Trino访问Minio,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文参考链接置顶: Presto使用Docker独立运行Hive Standalone Metastore管理MinIO(S3)_hive minio_BigDataToAI的博客-CSDN博客
一. 背景
团队要升级大数据架构,需要摒弃hadoop,底层使用Minio做存储,应用层用trino火spark访问minio。在使用trino访问minio时,需要使用hive的metastore service,经过调查HMS(Hive Metastore Service)是可以独立于hive组件的,即不需要整体安装hive,只部署HMS就可以使用trino通过HMS来访问minio。
二. 环境和步骤
1. 一台centos7服务器,装有docker, IP地址10.38.199.202
2. 使用mysql5.7.35作为HMS的元数据存储,使用dockers部署mysql服务
3. 使用docker部署HMS,这里部署在另外一台server上,IP地址10.38.199.201
4. 部署minio对象存储服务(本篇略去,使用已提供的服务)
5. 部署trino,配置metasotre服务及访问minio,trino部署在IP地址10.38.199.203
三. 部署mysql服务
1.拉取mysql镜像,版本5.7.35
docker pull mysql:5.7.35
2.查看镜像
docker images|grep mysql
3.启动mysql服务
docker run -p 3306:3306 --name mysql --privileged=true \
-v /usr/local/mysql/log:/var/log/mysql \
-v /usr/local/mysql/data:/var/lib/mysql \
-v /usr/local/mysql/conf:/etc/mysql \
-v /etc/localtime:/etc/localtime:ro \
-e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.354.查看mysql容器
docker ps|grep mysql
5.查看mysql日志
docker logs -f mysql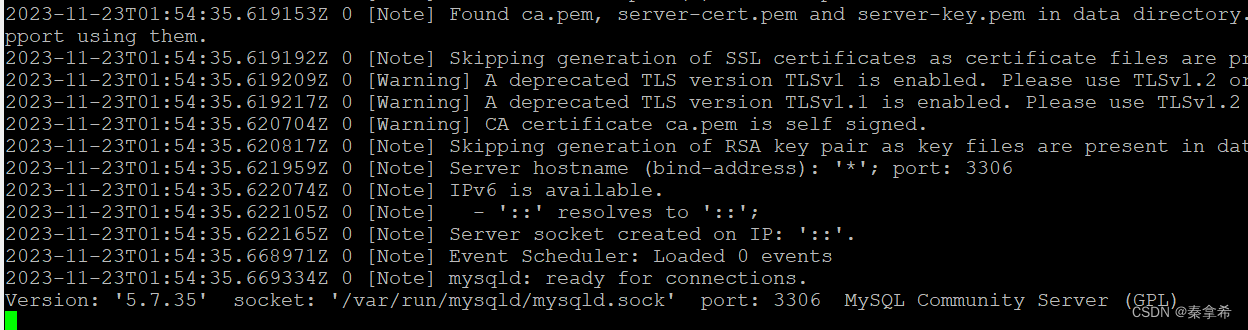
启动成功
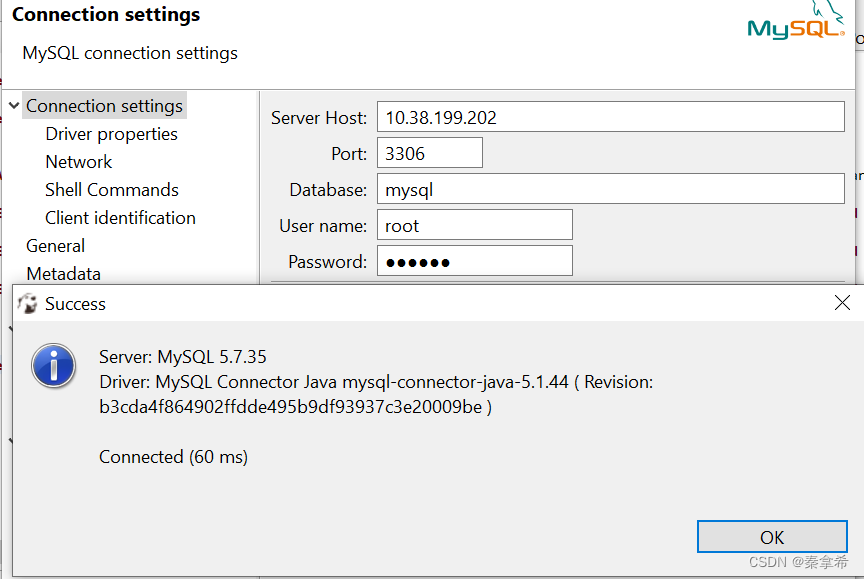
6.使用DBEVEA连接mysql服务,成功连接,并查看database
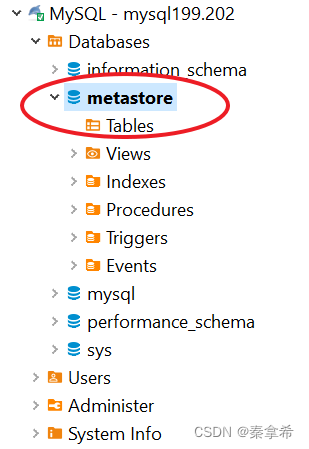
7.创建一个HMS的空数据库metastore,后面HMS会用这个数据库存储元数据
四. 部署HMS,mestasotre service
1.部署前需要几个安装包
- jdk安装包,自行下载,版本1.8以上
- HMS安装包hive-standalone-metastore-3.1.2-bin.tar.gz,地址Central Repository: org/apache/hive/hive-standalone-metastore/3.1.2
- mysql connect jar包mysql-connector-java-5.1.49.jar,地址https://mvnrepository.com/artifact/mysql/mysql-connector-java/5.1.49
- hadoop环境包hadoop-3.2.2.tar.gz,HMS需要依赖于它,地址Index of /dist/hadoop/common/hadoop-3.2.2
2.编写metastore.xml
编写前注意几个参数
minio的参数必须给出
- fs.s3a.endpoint
- fs.s3a.access.key
- fs.s3a.secret.key
mysql参数
- javax.jdo.option.ConnectionURL
- javax.jdo.option.ConnectionUserName
- javax.jdo.option.ConnectionPassword
metastore参数
- metastore.thrift.uris 准备发布的metastore service URL
- metastore.warehouse.dir hive表数据存储位置
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.s3a.access.key</name><value>bymOcmUZ6K8n5ApBu7Ee</value></property><property><name>fs.s3a.secret.key</name><value>lVtSARGXqypPpCRQ7LesGsfhRw3dE4imZoBs8ydS</value></property><property><name>fs.s3a.connection.ssl.enabled</name><value>false</value></property><property><name>fs.s3a.path.style.access</name><value>true</value></property><property><name>fs.s3a.endpoint</name><value>http://10.38.199.211:9000</value></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://10.38.199.202:3306/metastore?useSSL=false&serverTimezone=UTC</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property><property><name>metastore.thrift.uris</name><value>thrift://10.38.199.201:9083</value><description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description></property><property><name>metastore.task.threads.always</name><value>org.apache.hadoop.hive.metastore.events.EventCleanerTask</value></property><property><name>metastore.expression.proxy</name><value>org.apache.hadoop.hive.metastore.DefaultPartitionExpressionProxy</value></property><property><name>metastore.warehouse.dir</name><value>/tmp</value></property>
</configuration>将这些包和metastore.xml文件放在同一目录
3.创建Dockerfile
编写Dockerfile
FROM centos:centos7WORKDIR /installADD jdk.tar.gz /installRUN pwd
ADD hive-standalone-metastore-3.1.2-bin.tar.gz /install
RUN mv /install/apache-hive-metastore-3.1.2-bin metastoreADD hadoop-3.2.2.tar.gz /install
#RUN mv /install/hadoop-3.2.2 hadoopRUN ls
ADD mysql-connector-java-5.1.49.jar ./metastore/libENV JAVA_HOME=/install/jdk
ENV HADOOP_HOME=/install/hadoop-3.2.2RUN rm -f /install/metastore/lib/guava-19.0.jar \&& cp ${HADOOP_HOME}/share/hadoop/common/lib/guava-27.0-jre.jar /install/metastore/lib \&& cp ${HADOOP_HOME}/share/hadoop/tools/lib/hadoop-aws-3.2.2.jar /install/metastore/lib \&& cp ${HADOOP_HOME}/share/hadoop/tools/lib/aws-java-sdk-bundle-*.jar /install/metastore/lib# copy Hive metastore configuration file
ADD metastore-site.xml /install/metastore/conf/# Hive metastore data folder
VOLUME ["/tmp"]WORKDIR /install/metastoreRUN bin/schematool -initSchema -dbType mysqlCMD ["/install/metastore/bin/start-metastore"]创建镜像,创建的同时会在mysql的metastore数据库中创建基表
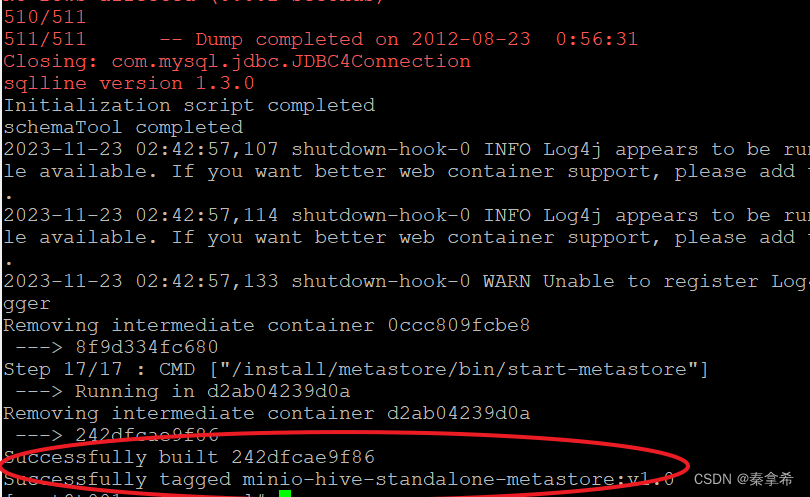
查看mysql中的metastore数据库中是否创建了基表,成功
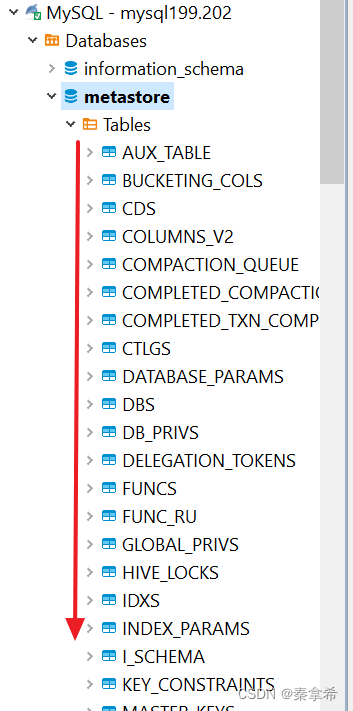
4.启动metastore service容器并查看状态
--启动容器
docker run -d -p 9083:9083/tcp --name minio-hive-metastore minio-hive-standalone-metastore:v1.0--查看容器
docker ps|grep minio-hive-metastore
五. 部署并配置trino
trino单机部署不再介绍,catalog中参数配置如下,最新配置了hiveminio.properties这个catalog

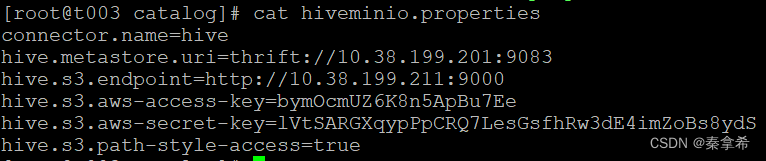 启动trino
启动trino
bin/launcher start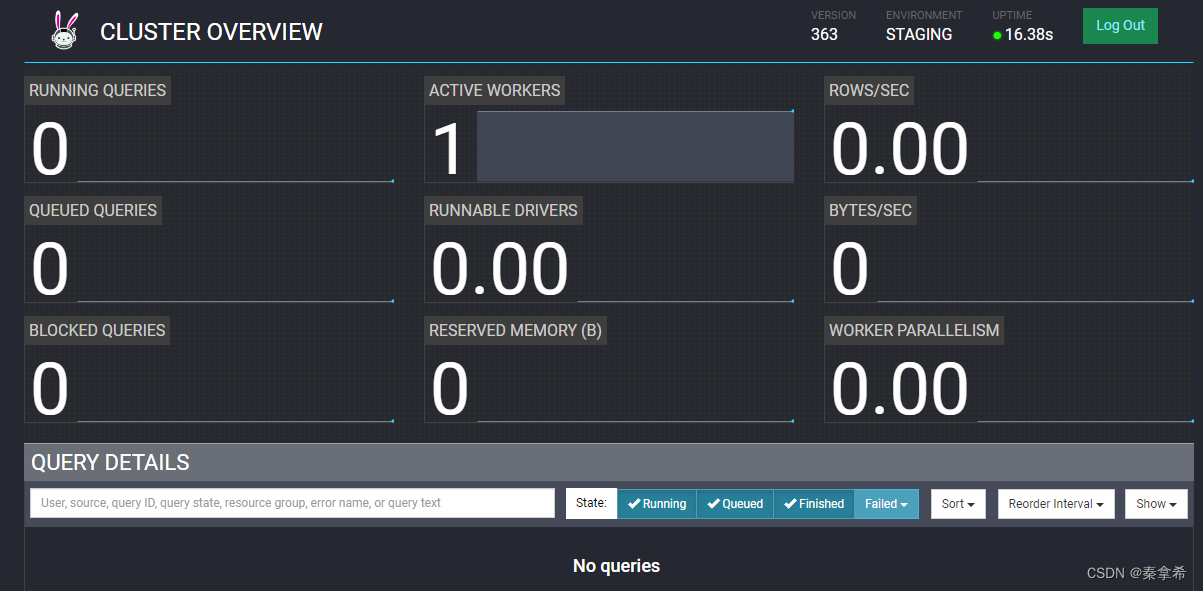
六.测试trino通过HMS访问minio
1.进入trino控制台
./trino --server http://10.38.199.203:8091 --catalog hiveminio --schema defaultshow schemas;show tables;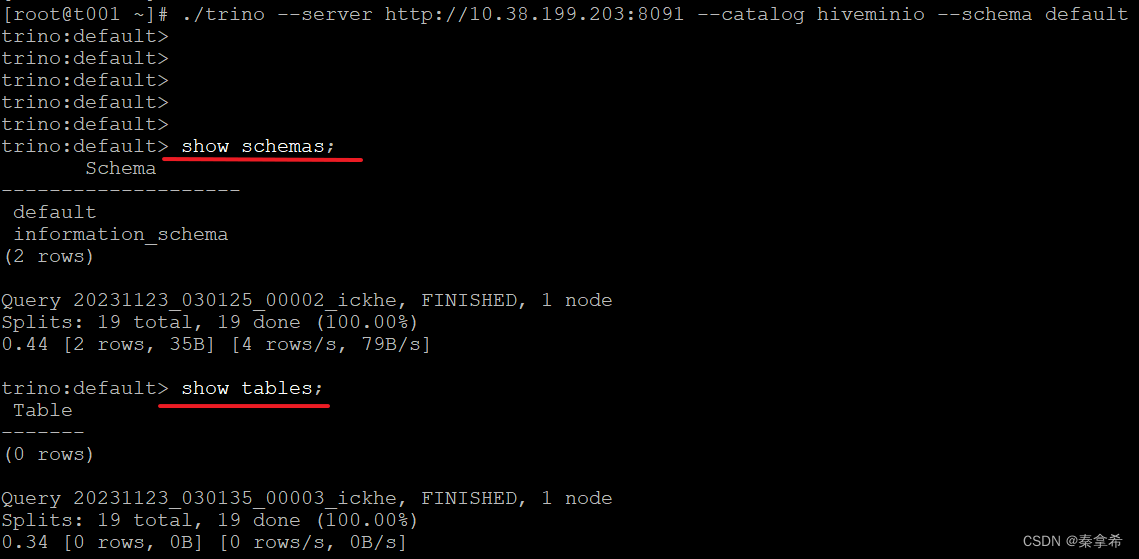
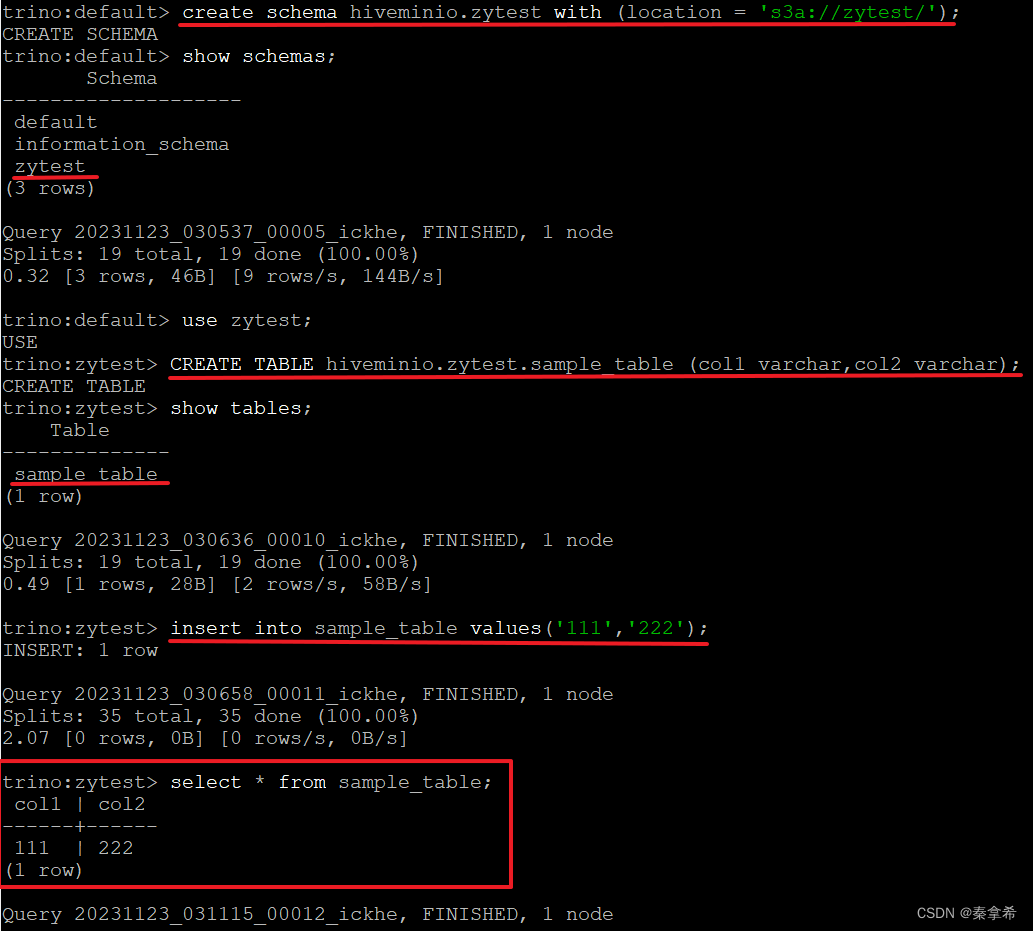
2.创建一个schemas “zytest”,指向mino的buket “zytest”,并创建一张表sample_table,插入一行数据,检查mimio界面是否插入成功
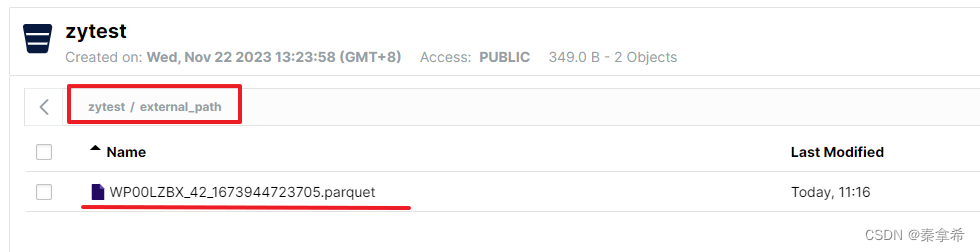
 3.文件挂载,在minio的zytest下面,创建一个新的path external_path,然后放入一个parquet文件
3.文件挂载,在minio的zytest下面,创建一个新的path external_path,然后放入一个parquet文件
在trino中创建表挂载这个目录,并查询表数据
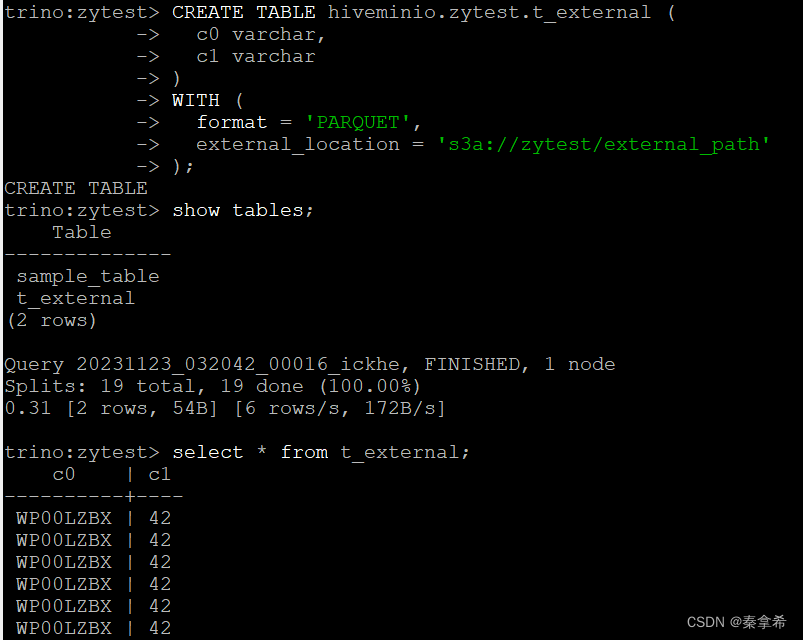
至此,整个测试完成!
这篇关于【大数据】Docker部署HMS(Hive Metastore Service)并使用Trino访问Minio的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







