本文主要是介绍YOLO系列:YOLO v1-v8、YOLOx、PP-YOLOE、DAMO-YOLO、YOLOX-PAI 设计思路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从YOLO v1-v8
- YOLO v1
- YOLO 流程
- 网格(grid)、锚点(anchors)、锚框(anchor boxes)
- 交并比
- 为什么把图像分割成 n*n 的格子呢?
- 边界框的作用?
- 为什么需要俩个边界框?
- 那如果一个格子有俩个以上的对象呢?
- 主干网络
- 损失函数解析
- 为什么不是一个损失函数?
- 怎么判断是否有物体以及预测准确性?
- 非极大值抑制去除重复预测结果
- YOLO v1 的优化思路
- YOLO v2
- 更轻量化网络Darknet-19
- k-means 聚类算法来选择先验框(prior bounding boxes)
- 直接位置预测 Dimension Clusters
- 损失函数解析
- 多尺度检测
- 批量归一化 BN
- 更大图像分辨率
- 引入passthrough层
- YOLO v3
- 三种尺度 * 三种宽高比的锚点
- 更深的网络 Darknet53
- 多尺度预测
- 特征金字塔网络FPN
- 特征进行融合是什么?
- 上采样的技术是什么?
- 预测框数量上升为9
- 多标签分类
- 损失函数解析
- YOLO v4
- 组合数据增强
- 新的损失函数 CIOU Loss 和 挑选机制 DIOU NMS
- 引入生成对抗
- 跨小批量标准化
- 空间注意力改为点注意力 CmBN
- 批量PAN方法
- CSPDarknet53(主干)
- SPP附加模块(颈)
- 用 PANet 来替代 FPN
- YOLO v5
- 自适应锚框
- 自适应图片缩放
- Focus结构
- 跨网格匹配
- 更精确的损失函数 GIOU_Loss
- SPP + PAN + CSP 设计
- YOLOx
- 解耦头 Decoupled Head
- Anchor-Free
- 正负样本匹配策略 SimOTA
- 损失函数 GIoU
- YOLO v6
- 更改激活函数
- 骨干网络 EfficientRep Backbone
- 同时检测多个目标特征 Rep PAN
- 损失函数 SIoU loss
- SimOTA标签分配策略
- YOLO v7
- E-ELAN
- MPConv
- 辅助头 auxiliary Head
- 将YOLOv5和YOLOx的正负样本分配策略相结合
- SPPSCP + 优化的PAN
- YOLO v8
- C3结构变成C2F结构
- 耦合头变成了解耦头,将分类和检测头分离
- 损失函数 VFL + DFL + CIoU
- 更好的激活函数
- 样本匹配

图片来源:CSDN@zyw2002。
总结:
YOLOv1拆解:网格、锚点、非极大值抑制、IoU、GoogleNet、IoU_loss。
问题:不适用于密集型目标检测、小物体检测、同一类物体出现的不常见的长宽比,由于交并比损失函数对大小物体的处理是同等对待,导致精度误差。
YOLOv2优化:k-means
聚类算法来选择先验框-解决长宽比、更轻量化的网络架构DarkNet-19-减少计算量、更准确的检测方法passthrough层-解决小物体检测。
YOLOv3优化:三种尺度 * 三种宽高比的锚点-增强模型对于不同类型对象的检测能力、更深的网络
Darknet53、更有效的特征集成方法FPN-在不同大小的尺度上都能有效地检测物体。
YOLOv4优化:更有效的训练方法-组合数据增强/跨小批量标准化、更精确的损失函数 CIOU
Loss-处理目标变形和中心点偏移的问题、更快更强的网络CSPDarknet53、空间金字塔池化SPP-输入的尺寸是可适应的、解决物体尺寸和位置的识别精度问题。
YOLOv5优化:更有效的检测方法Focus结构-提升速度、更精确的损失函数GIOU_Loss-更精确的边框预测、跨网格匹配-解决物体密集堆叠造成的误检和漏检。
YOLOv6优化:贴近硬件的网络EfficientRep Backbone、更好的检测方法Rep PAN、更精确的损失函数SIoU
loss-考虑方向特征更快调整、SimOTA标签分配策略计算相似度-解决检测中不同大小和形状的问题。
YOLOv7优化:更快更强的网络 ELAN-DarkNet -
有空间注意力网络功能同时减少了计算量、更有效的检测方法辅助头-多了一个角度看问题。
YOLOv8优化:更精确的损失函数 VFL + DFL + CIoU、更有效的标签分配方法 TAL -
自动化锚点、更准确的检测方法分离解耦头-解决高度相似和复杂背景下的定位不准及分类错误。
改进实时目标检测模型的性能,往往要从以下几点入手:
1、更快更强的网络架构;
2、更有效的特征集成方法;
特征是物体的一些特征表现,比如颜色、形状等。比如我们要从一堆水果里找出苹果,我们就可以根据“红色”,“圆形”这些特征来找。
特征集成就是把这些特征放在一起,找出共同点帮助我们更准确地识别物体。
比如,除了苹果,“橙色”,“圆形”还能找出橙子,如果我们把"红色"、“圆形”、"有绿色的茎"这些特性集成在一起,就能更准确的找到苹果。
3、更准确的检测方法;
你可以把这个理解成在一个房间里寻找你的玩具。
你可以随便乱找,也可以按照一个特定的顺序找,比如先从房间的左边开始找再到右边,或者先看房间的地板然后看书架。更准确的检测方法就像你有一个特别好的方式找玩具,你总能第一时间找到你的玩具。
4、更精确的损失函数;
5、更有效的标签分配方法;
比如在你的房间里,你的妈妈把你的玩具、书本、衣物都放在了不同的箱子里,并且每个箱子都贴上了标签,标签上说明了箱子里装的是什么。
这样当你想拿玩具的时候,你就不用去所有的箱子里面翻找,直接找到标签上写着"玩具"的箱子就行。同理,给电脑处理的图片贴上标签(比如“猫”、“狗”、“汽车”),当电脑看到猫的样子,它就知道那个标签是“猫”。
6、更有效的训练方法。
你在学习数学。你可以通过看书、听老师讲课、做作业的方式来学习。你可能会发现有的方式适合你,有的方式可能就不太适合。比方说,有些人做作业的时候会学得更快,有人则是听老师讲解的时候学得更快。
电脑也是一样,它需要找到最有效的方式来学习新事物或者提高其识别准确度,这就需要调整训练方式,找到最合适它的训练方法。
YOLO = 网格、锚点、锚框、非极大值抑制、IoU + Backbone主干网络 + Neck(特征融合) + Head(损失函数、非最大值抑制) + 训练技巧(训练方法、标签分配、数据增强)
-
Backbone:提取特征的网络,其作用就是提取图片中的信息,供后面的网络使用
-
Neck : 放在 backbone 和 head 之间的,是为了更好的利用 backbone 提取的特征,起着“特征融合”的作用。
-
Head:利用前面提取的特征,做出识别
YOLO v1
YOLO 实时检测和准确性是工作中经常用到的算法,因为太频繁了,有时候还会说成别的算法,避免让老板觉得一直用这个。
YOLO 流程

把图像分割成 N*N 的格子,每个物体(如汽车、行人)都标注一个中心点,将物体中心点所在的格子视为所属格,探测到中心点的格子才认为探测到了物体。
YOLOv1在训练过程中并不是把每个单独的网格作为输入,网格只是用于物体中心点位置的分配,如果一个物体的中心点坐标在一个网格中,那么就认为这个网格就是包含这个物体,这个物体的预测就由该网格负责。
而不是对图片进行切片,并不会让网格的视野受限且只有局部特征。
但通常神经网络没那么精准,也会把旁边的格子也视为有物体。
为避免重复探测,给每个预测结果分配一个概率值,表示有多大可能是有物体的。
选择最大概率,舍弃其他。
网格一共是 S×S 个,每个网格产生 B 个检测框,每个检测框会经过网络最终得到相应的预测框。最终会得到 S×S×B 个预测框,每个预测框都包含5个预测值,分别是预测框的中心坐标 x,y、预测框的宽高 w,h 和置信度 C。
其中 C 代表网格中预测框能与物体的取得的最大交并比值。
网格(grid)、锚点(anchors)、锚框(anchor boxes)
网格,把一张图片像棋盘一样划分成很多个小方格。这就帮助我们把一个大的图片分解成了很多个小图片,这样我们就能更加容易地找到图中的物体。
锚点,物体中心点,计算机只有检测到这个点,才算看到物体。
锚框,你可以想象成是一个看不见的框框,这个框框的中心就是我们刚刚扔下的锚,也就是锚点。当我们找东西的时候就在这个框框里找,而不是到处乱找,可以提高我们找东西的效率。
比如我们在一张图里找一个苹果。
首先,我们在图片上随机设定一个锚点,然后以这个锚点为中心,我们画一个虚拟的锚框到picture上。
然后我们只要在这个锚框里面找是否有苹果,这样就会更快找到苹果,而不用在整个图片里面找。
如果这个锚框里没找到,那么我们就移动这个锚点,重新画一个锚框,再接着找。
通过这样的方式,我们就能快速准确地找到图片中的苹果了。
网格和锚框的不同,网格是对图像的空间划分,起到对目标空间定位的作用,而锚框则是在网格的基础上,用于捕捉不同大小和比例的目标物体。
YOLOv1并没有锚框,v2才引入。
是借鉴了Faster R-CNN中的RPN网络的思想。锚框能对物体的形状和大小进行先验,从而更准确的定位物体。
关于先验框的选择,YOLOv2采用了k-means聚类算法来确定先验框(Prior bounding box)的大小。这样做的目的是为了减小预设先验框和实际bounding box的形状差异,从而减小预测误差。
因此,YOLO从v1到v2的主要改变是:v1通过将图像分割为网格进行目标检测,而v2则在此基础上添加了先验框和多尺度检测,提高了模型的检测精度。
交并比

汽车所在位置被红色框标出,而神经网络识别的汽车所在位置被紫色框标出,而神经网络给出的定位并不精准,那我们该如何让神经网络知道自己的定位不精准呢?
咱们研究一下,红色框、紫色框的特点:
- 绿色部分:真实的汽车位置、神经网络给出的汽车位置,绿色部分包含了俩者,是并
- 金色部分:真实的汽车位置、神经网络给出的汽车位置的交集,金色部分包含的是俩者重叠位置,是交
于是,我们就提出了一个公式:
- 交并比:交 / 并,可以查看重叠的面积占了所有面积的百分比
一般交并比大于 0.5 时,就代表神经网络定位精确了。
因为 0.5 指重叠的地方大于 50%,那汽车的一半已经被包进去了。
当交并比等于 1 时,就说明预测 100% 精确,所有区域都重叠了。
人们定义交并比这个概念是为了评价你的对象定位算法是否精准,但更一般地说,交并比衡量了两个边界框重叠地相对大小。
IoU_loss 就是用来计算这个比值的损失,反映了预测的准确性。如果预测完全正确,那么IoU就是1,IoU_loss就是0,表示没有损失。而如果预测完全错误,那么IoU就是0,IoU_loss就是1,表示损失极大。
为什么把图像分割成 n*n 的格子呢?
图像中的对象并不一定刚好占据整个图像,有的对象可能只占据了图像的一部分。
那么,我们就需要一种方式去定位这些对象,而将图像分割成格子,就是一种有效的定位方法。
如果你看到一张包含一只猫和一只狗的图像,这只猫在图像的左上角,狗在右下角。
那么,你可以通过描述其格子的位置,来有效地定位这两个对象。
然后,图像分割成格子后,每个格子负责预测其内部的对象,使预测更为精确。
每个格子会预测两个边界框和一个类别,边界框主要是确定对象的大小,类别则告诉我们这个对象是什么。
这样做的好处是,我们可以把对象检测问题转化为回归问题,直接用神经网络进行回归预测,大大提高了处理速度,使得实时处理成为可能。
边界框的作用?
一个边界框可以跨越多个格子包含对象。在YOLO算法中,虽然每个格子只预测两个边界框,但预测的边界框大小并不受限于该格子的大小。
例如,如果一只大型狗在图像中占据了多个格子,YOLO可以预测一个边界框,覆盖所有包含狗的部分的格子。
这个预测的边界框不仅属于其中一个格子,也跨越了多个格子。
但是要注意,边界框的中心点是落在某个特定格子内的,也就是说,这个边界框是由这个特定格子来负责预测的。
这就解决了检测不同尺度对象的问题,并且即使这两个对象彼此重叠,多边界框设计也能有助于分开检测。
为什么需要俩个边界框?
YOLO算法设计每个格子预测两个边界框是为了更好地处理某个格子内存在多个目标对象的情况。
每个边界框都会预测一个对象及其类别和概率,如果一个格子内只有一个对象,那么两个边界框可能会预测同一个对象。
如果一个格子内有两个对象,那么可以通过两个边界框来分别定位并预测他们,就算他们俩的中心点都在同一个位置也可以。
那如果一个格子有俩个以上的对象呢?
如果一个格子内有超过两个对象,YOLO算法在该格子内的预测就可能存在一些限制。
尽管每个格子预测两个边界框,如果一个格子内存在多于两个对象,那么可能会出现预测不准的情况。
例如,假设一个格子里有三只小鸟,但YOLO只能预测两个边界框,那么可能会有一个鸟没有被检测到,或者三只鸟被错误地检测为两只。
虽然YOLO对两个对象的处理效果较好,但要处理三个或更多对象的情况,则需要更复杂的方法,例如使用多尺度特征、更复杂的网络配置等。
另外,在实际应用中,我们通常能够控制图像的输入和预处理方式,尽量避免这种情况的发生。
例如,我们可以通过改变图像的尺度、剪裁等方式,调整图像使得一个格子包含的对象数量保持在合理范围内。
主干网络
YOLO v1 的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个前向计算,得到边界框的位置及其所属的类别。
v1 = 预处理(n*n图像格子) + GoogleLeNet + 判断是否有物体以及预测准确性(2个边界框)+ 预测结果
GoogleLeNet是一种深度卷积神经网络,它的特点是引入了Inception模块。
基本上,你可以将GoogleLeNet看作是由很多小的神经网络(Inception模块)堆叠组成的大神经网络。
每个Inception模块由一系列并行的,不同尺度的卷积操作和池化操作组成,从而使网络在同一层次可以学习到不同尺度,不同复杂度的特征。
在每一个Inception模块结束后,通常都会使用池化操作进行降维,并避免过拟合。
损失函数解析
YOLOv1 的损失函数可以分为检测框的回归损失,置信度误差损失以及分类误差损失。
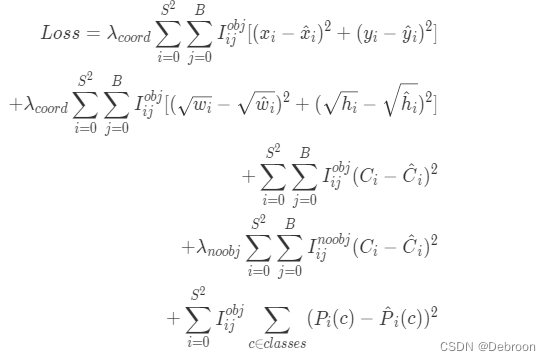
第一行,检测框的中心点损失。
I i j o b j I^{obj}_{ij} Iijobj 表示这个预测框与物体的中心点预测框的交并比值,和其他预测框相比是否是最大的。如果是最大,为1;否则为0。
第二行,宽高的回归损失。
宽高回归损失中使用了开根号的操作,这是考虑到了小目标与大目标对应的检测框会存在差异,并消除这个差异。
不开根号时,损失函数往往更倾向于调整尺寸比较大的检测框。
如 8 个像素点的偏差,对于 1024×1024 的检测框几乎没有影响,因为此时的交并比值还是很大,但是对于 12×12 的小检测框影响就很大。
第三行和第四行代表了置信度误差损失,分别是含物体的置信度误差损失、不含物体的置信度误差损失。
当网格中含有物体时, I i j o b j = 1 、 I i j n o b j = 0 、预测置信度 C ^ = 1 I^{obj}_{ij}=1、I^{nobj}_{ij}=0、预测置信度 \hat{C}=1 Iijobj=1、Iijnobj=0、预测置信度C^=1。
反之, I i j o b j = 0 、 I i j n o b j = 1 、预测置信度 C ^ = 0 I^{obj}_{ij}=0、I^{nobj}_{ij}=1、预测置信度 \hat{C}=0 Iijobj=0、Iijnobj=1、预测置信度C^=0。
第五行代表了分类误差损失,只有当 I i j o b j = 1 I^{obj}_{ij}=1 Iijobj=1 才会计算。
目标检测中存在一个常见问题,那就是类别不均衡问题。
在一张图像中物体往往只占一小部分,大部分还是背景为主。
故在置信度误差损失中设置了 λ coord =5 和 λ noobj = 0.5,来平衡含物体的置信度误差损失和不含物体的置信度误差损失两者的权重,让模型更加重视含物体的置信度误差损失。
YOLO使用的目标函数是一个有些复杂的多部分损失函数,主要由坐标预测误差、维度预测误差、对象置信度误差、类别预测误差四个部分来共同构成。
想象一下你正在玩一个掷靶的游戏,你的目标就是把飞镖扔到靶心上。我们可以把这个游戏看作是 YOLO 的目标函数,靶心就如同我们想要正确的预测结果。
下面是四个部分相当于飞镖游戏中的哪些方面:
-
坐标预测误差:这就像看你的飞镖落在靶面上的哪个位置。如果你的飞镖偏离了靶心,你会得到一个较大的坐标预测误差。
-
维度预测误差:这就是飞镖离靶心距离的大小,如果你的飞镖距离靶心越远,你就有一个较大的维度预测误差。
-
对象置信度误差:这就像你对自己投掷飞镖的准确性的信心。假设你连续投掷出了很多好的飞镖,你的信心就会增强,并且对象置信度误差就会降低。
-
类别预测误差:这就像你投掷飞镖时的目标。如果你的目标是靶心,但你却投向了靶面的其他位置,那你就有一个较大的类别预测误差。
因此,这个目标函数尝试最小化这四个损失,让你的飞镖尽可能的靠近靶心。每一次的预测结果都像是在掷一支飞镖,我们希望每次都能尽量靠近靶心。
所以,YOLO就是通过调整这四个部分,让结果尽可能的准确。
为什么不是一个损失函数?
这就像练习投篮,业余打球人只看到左偏、右偏。
有篮球天赋的还能觉知到自己手指(尤其是食指)状态,及觉察到提膝、腰、肩膀、手肘等一系列对投篮有影响的地方。
刻意练习再怎么努力也就是业余水平,超精细 + 刻意练习才是真的有天赋。
怎么判断是否有物体以及预测准确性?
每一个网格都会预测2个边界框和每个边界框的置信度,以及C个类别概率。
每个边界框除了位置(中心位置和宽/高)参数外,也还预测一个置信度,对该预测框能包含一个物体以及预测准确度的置信程度。
- 置信度是指模型对于某个边界框中是否包含物体,以及该边界框预测的准确的信心程度。置信度是预测边界框和实际边界框的交并比。
非极大值抑制去除重复预测结果
卷积神经网络可能对同一目标有多次检测, 非极大值抑制(NMS)是一种让你确保算法只对每个对象得到一个检测框的方法。

通过计算类别概率与置信度的乘积来得到最终的类别检测结果
最后通过非极大值抑制来去除重复的检测结果。
-
为每个预测结果分配一个概率值,表示有多大可能是物体。
-
YOLO每个格子就都有一个概率值,0代表没有物体,1代表100%有物体。
-
我们直接排除 0.6 以下的格子,在0.6以上的格子中寻找最大格子,把最大格子附近的重叠格子全部去除。
-
然后在剩余0.6以上的格子中找次最大格子,把次最大格子附近的重叠格子全部去除。
-
不停排除,最后剩下的就是有物体且不重复的格子。
让我们以一个更简单的比喻来解释这个过程。
假设你正在玩一个寻宝游戏。你的任务就像YOLO模型一样,要在一张地图上找到宝藏的位置。地图就像我们的图像,而宝藏就像我们需要找到的物体。
-
首先,你将地图分成了很多小块,这就像模型把图像分成网格。
-
然后,你开始研究每一小块地图,看看它们可能隐藏宝藏的几率有多高。这个过程就像模型为每个网格预测出类别概率。
-
同时,你还要预测每一块地图上可能存在宝藏的“范围”,这个范围就是边界框。
-
然后,你将每一块地图上的可能性和范围相结合,得出综合的预测。这就相当于模型计算类别概率与置信度的乘积。
-
在你检查所有地图块后,你可能会注意到有些地方被预测为包含宝藏的可能性很高。
但是,如果这些地方彼此相邻或者重叠,那你就需要选择可能性最高的那个,并忽略其他的。
这就像模型使用非极大值抑制去除重复的预测结果。
所以,通过这个过程,YOLO模型就像你在寻宝游戏中一样,一次看整个地图,然后找出藏有宝藏的位置。
这就是为什么它的名字叫"You Only Look Once"(只看一次)。
YOLO v1 的优化思路
由于YOLOv1每个网格的检测框只有2个,对于密集型目标检测和小物体检测都不能很好适用。
训练时,当同一类物体出现的不常见的长宽比时泛化能力偏弱。
-
不适用于密集型目标检测:YOLO将整个图像分为 SxS 个网格,每个网格负责预测 B(2) 个边界框和相应的类别。如果一个网格中包含多个对象,YOLO只能预测出最多B(2)个对象,这就限制了它在密集目标检测场景中的性能。
-
小物体检测困难:YOLO 的设计假设每个网格中只包含一个对象的中心。对于小物体,可能多个对象的中心会落在同一个网格中,导致预测结果不准确。
比如我们在观察一张含有大量小蜜蜂的照片,每只蜜蜂的大小远小于YOLO的单个网格尺寸。在这种情况下,很可能会有多只蜜蜂的中心点落在同一个YOLO的单个网格中。然而,YOLO的设计原理是一个网格只负责产生一个物体的预测。因此,对于这样一张图片,YOLO可能只能检测到其中的一只蜜蜂,而忽视了其余的蜜蜂。这就是YOLO在小物体检测上的一大困难。
-
同一类物体出现的不常见的长宽比:YOLO的损失函数对不同尺度的误差处理方式是一样的,对于特别小或者特别大的边界框预测,这可能会导致一些问题。
YOLO对于物体的形状和比例有一定的预设假设,比如它采用几何形状的锚框来处理物体的长宽比。这些预设的锚框通常是根据常见的物体形状和比例设定的。但是对于不常见的长宽比,比如被拉长或压扁的物体,可能就会预测得不准确。
由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
你可以把YOLOv1想象成一个捕鱼的大网,这个大网被划分成了很多个小格子,每个小格子都负责捕捉掉入其中的鱼。鱼在这里表示我们想要检测的物体。
我们希望这个大网能准确地捕捉到鱼的位置,也就是我们希望YOLOv1能准确地定位到物体。但是因为YOLOv1的损失函数设计的问题,就好像有一些小格子不能很好地适应鱼的大小。就比如有些小格子太大了,出现了一条小鱼,捕鱼网可能会以为它比实际大小要大,反之如果鱼太大但是小格子太小,那么捕鱼网可能会以为鱼比实际上小,这就造成了定位误差。
比如使用YOLOv1这个捕鱼网来捕捉两种鱼:金鱼和鲸鱼。金鱼很小,鲸鱼很大。
现在,我们的捕鱼网网格被设计得相当大。每一个大格子都适合捕捞鲸鱼,但是对于小巧的金鱼来说就显得太大了。因此,每次金鱼落入这些大网格中时,网格可能会误判其大小,认为金鱼比实际大小要大。
同样的,如果我们把捕鱼网网格设计得很小,每个小格子都适合捕捞小巧的金鱼。但对于巨大的鲸鱼来说,这些小格子就显得太小了。因此,当鲸鱼落入这些小网格中时,网格可能会误判其大小,认为鲸鱼比实际大小要小。
这就是定位误差,会导致我们不能准确地知道捕到的鱼的真正大小。这就影响了我们对物体(在这个例子中是鱼)大小和位置的准确识别,进而影响了目标检测的效果。
这不是网格大小问题吗,和损失函数有什么关系?
假设我们预测一个物体在一个大网格中,尽管框的中心点预测是准确的,但因为网格大,物体占用的区域相对较小,这会导致我们对边界框大小的预测会比实际物体大。另一方面,如果网格小,物体占用的区域相对较大,我们可能会预测出比实际物体小的边界框。因为YOLOv1的损失函数对这两种误差处理是同等对待的,这就导致了定位误差。
此外,YOLOv1的backbone结构中使用了Leaky ReLu激活函数,但并没有引入BN层。
YOLO v2
YOLO v2 与其前身YOLO v1相比,改进很大。
更轻量化网络Darknet-19
YOLOv2的Backbone在YOLOv1的基础上设计了轻量级的网络架构 Darknet-19,性能并不逊色于GoogleLeNet,并引入了BN层优化模型整体性能。
这就像是飞镖比赛中,你换了一种更轻更精准的飞镖,虽然它的设计更简单,但是可以让你更准确地命中目标。
在YOLOv2的Backbone中加入BN层之后,使得mAP提升了2%,而BN层也成为了YOLO后续系列的标配。
k-means 聚类算法来选择先验框(prior bounding boxes)
YOLOv2 使用 k-means 聚类算法来选择先验框(prior bounding boxes),也就是预设的锚框(anchor boxes)。这个改进的好处是锚框可以更好地对应到训练数据集中的真实物体的形状和大小,从而改善了物体检测的精度。
例如,假设我们的任务是检测的物体主要是人和汽车。人的形状大致是瘦长型的,而汽车的形状则大致是扁平型的。如果我们手动设置锚框,可能会选择一些标准的方形或者正方形,但这些形状可能无法很好地匹配到人和汽车的真实形状。
通过使用 k-means 聚类,我们可以根据训练数据集中的人和汽车的真实边框形状,自动选择出两个最佳的锚框,一个匹配人,另一个匹配汽车。这样,模型在预测时,就可以根据这两个更接近真实的锚框来预测物体的位置,从而提高了识别的精度。
直接位置预测 Dimension Clusters
优化了锚框预设置后,YOLOv2设计了【直接位置预测】,直接获取目标边界框的位置,而不需要依赖锚框或预测框。
传统的目标检测算法通常使用锚框或预测框作为参考,在锚框的基础上预测目标的位置和边界框。
这需要进行锚框与真实目标的匹配,并通过回归来修正锚框的位置。
具体步骤是:
-
首先,每个预测的边界框由五个元素定义:(x, y, w, h, c),其中(x, y)代表中心点的坐标,(w, h)代表框的宽度和高度,c则代表置信度。
-
与标准的YOLO模型不同,在YOLOv2中,网络输出的预测边界框的中心坐标(x, y)被与当前单元格左上角的相对位置的偏差相关联,然后通过sigmoid函数限制其范围在0和1之间。
-
同样的,网络输出的预测边界框的宽度和高度的自然对数(w, h)被与ground truth边界框的宽度和高度的对数的差(offset)相关联。而ground truth边界框的尺寸是通过预设的锚框的尺寸来定义的。
ground truth是指真实的边界框和对应的类别标签。
如果你在训练一个能识别照片中狗和猫的YOLO模型,那么每张训练照片(比如一张照片显示一只狗在草地上)都应该包含一个或多个"ground truth"边界框(该边界框精确标出照片中狗的位置)以及标签(“狗”)。
YOLO模型的目标是通过训练,尽可能地减小预测的边界框和实际的ground truth之间的差距。此外,还希望模型能正确预测每个边界框内物体的类别。
为什么用自然对数呢?这是因为小的预测错误对大的box和小的box应该有差异的惩罚。
假设我们有两个箱子,一个是大箱子,一个是小箱子。现在我们希望把这两个箱子放到准确的位置。
对于大的箱子,如果我们的位置预测偏离了1厘米,那么在整个大箱子的尺寸中,这1厘米可能并不会引起太大的问题,因为它在整个大箱子尺寸中所占的比例很小。
对于小的箱子来说,如果位置预测偏离了1厘米,那么在整个小箱子的尺寸中,这1厘米可能就会显得很明显,因为它在小箱子尺寸中所占的比例较大。
自然对数就有这个功能,当我们的预测错误(偏离的距离)很小时,自然对数值也很小;当预测错误大的时候,自然对数值也会变得更大。
这就意味着,对于小箱子的预测错误,我们会有更大的惩罚(因为自然对数值更大);对于大箱子的预测错误,惩罚就相对较小(因为自然对数值小)。
这样就保证了我们的模型对于大箱子和小箱子的预测错误有不同的处理方式,使得预测更为准确。
-
这些计算考虑了空间位置和预期物体尺寸的信息,有助于提高模型在空间定位和尺寸推断上的预测精度。
简单来说,YOLOv2通过计算预测框和anchor框的位置和大小偏差,优化模型对目标物体的定位。更具体的计算方法,需要深入理解一些深度学习和物体检测的知识。
YOLOv2是一种机器可以“看”和识别图片中物体的方法。但是我们不能直接让机器去“看”,我们需要先给它一些“眼镜”,这些眼镜被称为锚框。
这些眼镜的形状大小是由我们事先定义的,类似于我们预设的框框。
“Direct location prediction” 这个方法,可以让机器更准确地找出真正物体在图片中的位置。机器会根据这些预设的“眼镜”,去猜测物体的准确位置和大小。
机器会先看到一副图片,再通过眼镜看图片,然后猜测每个物体的具体位置和大小。这个猜测的结果就是这个物体的边界框。
这个猜测的过程就是算出机器猜测的位置和大小,与预设“眼镜”(锚框)的位置和大小之间的差别。
假如我们正在进行一项用机器视觉来识别篮球的任务,我们的模型预设了一个“眼镜”的大小和位置来猜测篮球的大小和位置。
假设在图像中,预设的“眼镜”(anchor box)的中心坐标是(2, 2),并且大小是2x2。
然而,真实的篮球的中心坐标是(2.5, 2.5),大小是2.5x2.5。
这样,机器预测的和实际的篮球之间的偏差就是0.5x0.5在位置上,和0.5x0.5在尺寸上。
计算得到这个偏差后,机器就能够更改预设的“眼镜”(锚框),使得预测更加接近真实的情况。
对于每一个“眼镜”,都会计算得到一个偏差,然后这个偏差会反馈回模型,模型在通过学习这些偏差,不断的优化和修正自身的预设,“眼镜”的大小和位置,使得预测的效果越来越准确。
修正偏差一般通过反向传播、梯度下降等方法进行。
具体修订方式:
在上述篮球识别的例子中,首先,我们会计算出预测位置和大小与真实位置和大小之间的差异,这就是我们的损失函数(Loss Function)。
然后我们会用这个损失函数对模型参数(在这里是“眼镜”的位置和大小)进行微分,得到每个参数对应的梯度值。
这个梯度值反映了如果参数变化一小部分,损失函数会改变多少。
借由这个梯度值,我们可以知道应该如何调整参数才能使损失函数尽可能地减小。
所以,在每次模型训练迭代过程中,我们都会用这个梯度值去更新参数,即新的参数 = 旧的参数 - 学习率 * 对应的梯度。这样循环迭代,模型的参数就会逐渐接近使损失函数最小的那一组参数,也就达到了修正偏差的目的。
损失函数解析

在计算检测框的回归损失时,YOLOv2 去掉了开根号操作,进行直接计算。
但是根据ground truth的大小对权重系数进行修正: ( 2 − w ^ ∗ h ^ ) (2-\hat{w}*\hat{h}) (2−w^∗h^), w ^ 、 h ^ \hat{w}、\hat{h} w^、h^ 都归一化到 [0,1]。
这样对于尺度较小的预测框其权重系数会更大一些,可以放大误差,起到和YOLOv1计算平方根相似的效果。
多尺度检测
YOLO v1只在一个固定的尺度下进行检测,这可能会导致对小物体的识别率不高。
而YOLO v2引入了多尺度检测,可以在不同大小的特征图上进行检测,提高了对小物体的检测能力。
想象篮筐有大有小,有远有近。那么我们需要让小朋友学会在不同的位置和大小的篮筐上投篮。
这就像机器学习模型需要学会在不同大小和位置的对象上进行识别,这就是"多尺度检测"。
实现方式就是,在训练的时候,我们不断地调整输入图片的大小,小朋友就能学会投向不同大小的篮筐。
YOLOv2每迭代几次都会改变网络参数。每10个Batch,网络会随机地选择一个新的图片尺寸。
由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352……608},最小320,最大608,网络会自动改变尺寸,并继续训练的过程。
批量归一化 BN
降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性
假设一个小学班上的学生们正在比赛跳远。他们每个人跳得有远有近。有的人跳了1米,有的人跳了6米,甚至有人跳到了8米!这个差距太大了,多少有点打击人。
现在,老师为了让比赛更公平,他决定自己重新设定一个规则。他说:“我们将所有人的跳跃距离,都按照比例缩小到1米到3米之间。这样,每个人的跳跃距离就都差不多了。”
这就好比让老师执行了一次“批量归一化”,把所有的跳跃距离都处理到了一个相近的范围,也就更公平了。
对于神经网络来说,批量归一化就像是让网络在处理数据时,把所有特征的值都调整到一个附近的范围,这样处理过程就会更稳定,也更容易学习。
更大图像分辨率
用于图像分类的训练样本很多,而标注了边框的用于训练目标检测的样本相比而言就少了很多,因为标注边框的人工成本比较高。
所以目标检测模型通常都先用图像分类样本训练卷积层,提取图像特征,但这引出另一个问题,就是图像分类样本的分辨率不是很高。
所以YOLOv1使用ImageNet的图像分类样本采用 224 ∗ 224 作为输入,来训练CNN卷积层。
然后在训练目标检测时,检测用的图像样本采用更高分辨率的 448 ∗ 448 像素图像作为输入,但这样不一致的输入分辨率肯定会对模型性能有一定影响。
所以YOLOv2在采用 224 ∗ 224 图像进行分类模型预训练后,再采用 448 ∗ 448 高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448 ∗ 448 的分辨率。
然后再使用 448 ∗ 448 的检测样本进行训练,缓解了分辨率突然切换造成的影响,最终通过使用高分辨率,mAP提升了4%。
这就像我们让一组小朋友在一个大型乒乓球桌上训练乒乓球。
在这个早期的阶段,老师把球桌缩小为一半的大小,让小朋友们更容易掌握基本技能。
这就像初始化的过程,和YOLOv2在小的224*224分辨率图像上进行分类模型预训练相类似。
然后,当小朋友们熟悉了游戏规则和基础技巧后,老师就把桌子扩大到原始大小,这时,小朋友可能会首先感到困难,因为场地变大了,他们需要跑动得更多。
但是他们已经掌握了基本技能,所以很快就能适应大范围的游戏。
这就像YOLOv2再采用448*448高分辨率样本对分类模型进行微调。
小朋友的乒乓球技巧不断进步,达到了更高的水平,就像YOLOv2使用高分辨率,最终使mAP提升了4%。
而微调的过程,就像是缓解了一开始直接在大球桌上打球会遇到的困难。
引入passthrough层
YOLOv2在YOLOv1的基础上去掉了最后的全连接层,采用了卷积和anchor boxes来预测检测框。
由于使用卷积对特征图进行下采样会使很多细粒度特征的损失,导致小物体的识别效果不佳。故在YOLOv2Head侧中引入了passthrough layer结构,将特征图一分为四,并进行concat操作,保存了珍贵的细粒度特征。
首先我们可以想象一下我们正在玩一个游戏,游戏的目标是要找出画面中的一些物体,比如猫或者狗。
但是,这些猫或狗有的可能会很大,有的可能会很小,就像是他们距离我们的远近不同。
如果距离我们很远的那些小猫小狗,可能我们就很难看清楚他们的身影,更不用说要认出他们来。
在这个游戏中,我们就可以想象我们有一个“魔镜”一样的工具,这个工具可以帮我们把那些距离我们很远的小猫小狗放大。
那样我们就可以看清楚他们的样子,甚至还能看清楚它们身上详细的毛发,它们的眼睛的颜色,或者它们的皮肤的纹理等等详细部分,就像我们用了放大镜一样。
因为有了对这些细粒度特征的观察和理解,我们就可以更准确地分辨和区别不同的动物,甚至可以分别是什么品种的猫或狗,甚至可以推断出它们的年龄。
这个“魔镜”其实就是 passthrough 层的功能,他可以帮助我们在查找物体时,保留一些更小、更精细的信息。
那这个“魔镜”是如何工作的呢?
我们可以想象当我们在用这个“魔镜”查看画面时,它会把画面分成很多小的方格,然后在每个方格中找看看有没有我们要找的物体。
最强的地方就在于,即使在那些看起来没有我们要找的物体的方格中,它也能把这些方格中的信息提取出来,然后和其他方格中的信息一起,形成一个更“全面”的图片。
这样我们就可以更准确地找到所有的物体了。
YOLO v3
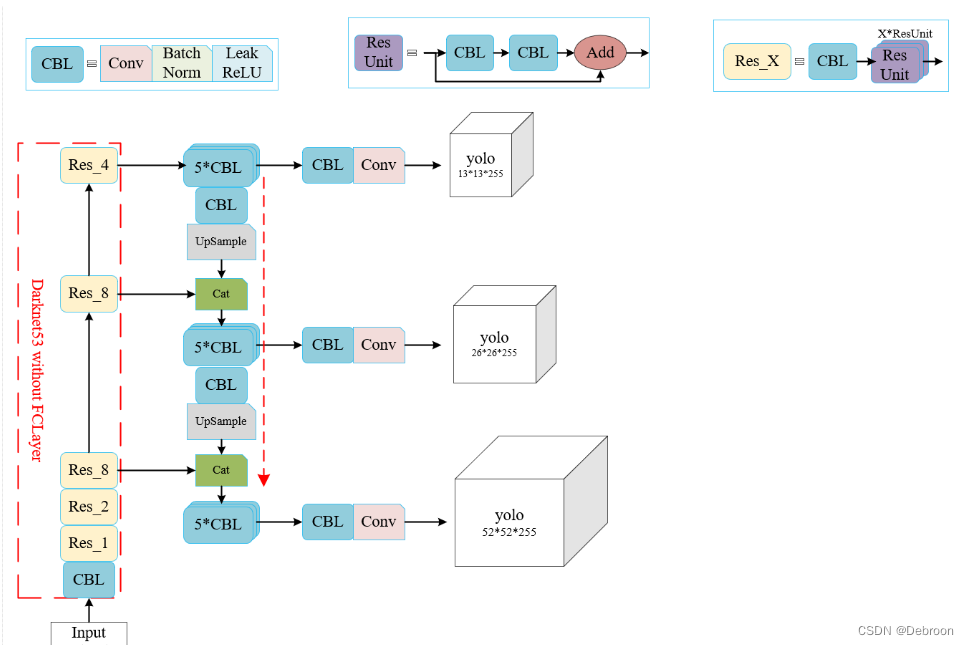
V3最大的改进就是网络结构,使其更适合小目标检测。
- 特征做的更细致,融入多持续特征图信息来预测不同规格物体
- 预测框更丰富了,3种scale,每种3个规格,一共9种
- softmax改进,预测多标签任务
三种尺度 * 三种宽高比的锚点
YOLOv3的锚点使用的是三种尺度(downsampling ratios)*三种宽高比(aspect ratios)。
通俗的讲,YOLOv3算法中使用了9个默认的边界框(anchor boxes),这9个边界框是由3种尺度和3种宽高比组成的。
在进行物体定位时,YOLOv3对每一个锚点(anchor box)都会做出一个预测,然后将预测值与实际边界框之间的IoU(Intersection over Union)进行比较,取IoU最大的那个锚点预测为最终的边界框。
我们正在看一个大型足球场上的比赛,并且我们要找出所有的足球。
现在,你没有眼镜,看不清楚足球场,但你有一个特殊的仪器,这个仪器可以帮助你找到这些足球。这个仪器有3种不同的镜头(相当于YOLOv3中的3种尺度),每个镜头有3种不同的聚焦能力(相当于3种不同的宽高比),总共9种不同的视角来寻找足球。
你首先使用第一个镜头和第一个聚焦能力,这可能有点虚化,但仍然可以大致找到一些足球的位置。然后,你换了第二镜头和第二种聚焦能力,这个视角可能更窄,但是对足球的形状和位置可能有更清晰的认识。最后,你再次换成第三个镜头和第三种聚焦能力来找到足球的位置。
在每一次的更换中,你都会寻找最适合眼前的足球形状和位置的镜头和聚焦能力,即选择让足球看起来最清楚的那个视角(最优的锚点选择)。
在这个例子中,“尺度” 可以理解为你观察足球场的"距离"。
例如,一个更大的尺度可能会让你观察到整个足球场,而一个更小的尺度可能使你更关注足球场上的某个特定区域。
不同的宽高比可以被理解为观察足球场的不同角度或视角。
如果我们或我们的视角更趋近于足球场的比较"宽"的一面,我们可能会有一个宽屏的视角来观察游戏,看到的是场地上的局部细节如球员位置、短距离传球以及角球策略等。
反之,如果我们的视角更趋近于足球场的相对"狭长"的一面,我们的观察就趋向全局,可以看清整个场地和所有球员,评估整体战术布局,比如球队的阵形、长距离传球以及对手的进攻和防守策略。
传统的锚点一般是预定义的一种尺寸和一种宽高比,适用于一种特定类型的对象。
例如,一个设计为检测人脸的模型可能会使用大小和宽高比都比较一致的锚点。这样的设计是依赖于特定任务的,如我们只需要识别一个特定大小和形状的对象时。
但是在很多情况下,对象的大小、形状和宽高比可能各不相同。
在这种场合下,在多尺度和多宽高比中选择锚点可以增强模型对于不同类型对象的检测能力。
例如,在一个街景图像中,需要识别的对象可能有很大的大小变化(楼房、汽车、行人等),并且形状各异(长方形的大巴、圆形的交通标志等)。在这种情况下,多尺度和多宽高比的锚点可以提供更全面、更精确的盖住这些对象。
更深的网络 Darknet53
v3 的Backbone在 v2 的基础上设计了Darknet-53结构。
Darknet-53的特点:Conv卷积模块+Residual Block残差块)串行叠加4次。
v3 优化了下采样方式(无池化层结构),采用卷积层来实现,而 v2 中采用池化层实现。
为什么没有直接使用Resnet?
- 相同点:残差结构
- 不同点:发现resnet设计有一定冗余,所以换了。精度相当,但速度提升50%
Darknet-19 模型有 19 个卷积层和 5 个最大池化层。
19 使用了一些先进的特征,如批量标准化、高级激活和多尺度训练,性能已经很好了。
再加深网络深度,在处理更复杂的图像分析任务时,性能会更强。
此外,就是处理因为加深网络要处理掉梯度消失、梯度爆炸问题。
多尺度预测
它就像我们的眼睛,能帮我们看清楚屏幕上的图片上的东西在哪儿,它是什么形状,多大尺寸。
为了更准确地看见,YOLOv3用了一种很聪明的办法,它选取了9个不同大小的“镜头”。
这些窗户可以帮助它更好地观察和识别各种不同大小和形状的物体,就好像我们用放大镜看小东西,用望远镜看远东西一样。
YOLOv3就是依靠这些窗户,来帮我们预测图片上的物体的位置和形状。
想象一下,你正在看一张在公园的照片。在这张照片中,可能有远处的山的大看图,也可能有近处的小花小草。
这时,你就需要使用不同的“镜头”,让你能同时清楚地看到这些大的和小的物体。
特征金字塔网络FPN

YOLO从v3版本开始设计Neck结构,其中的特征融合思想最初在 FPN 网络中提出,在 YOLOv3 中进行结构的微调,最终成为YOLO后续系列不可或缺的部分。
FPN的思路剑指小目标,原来很多目标检测算法都是只采用高层特征进行预测,高层的特征语义信息比较丰富,但是分辨率较低,目标位置比较粗略。
假设在深层网络中,最后的高层特征图中一个像素可能对应着输出图像20×20的像素区域,那么小于20×20像素的小物体的特征大概率已经丢失。
与此同时,低层的特征语义信息比较少,但是目标位置准确,这是对小目标检测有帮助的。
FPN将高层特征与底层特征进行融合,从而同时利用低层特征的高分辨率和高层特征的丰富语义信息,并进行了多尺度特征的独立预测,对小物体的检测效果有明显的提升。
FPN这个网络的特点,就是先下采样,然后再上采样,上采样和下采样的这两个分支之间还有两个跨层融合连接。(也可以反过来,先上采样,再下采样)
如果你在看一个海洋的照片,你可以清楚的看到整个海洋的样子,这就像是首先在大尺度上获取的特征,可以看到整体的景象。但是如果你想看清楚照片中的一只小鱼,就需要使用放大镜,使得小鱼看上去就像是大鱼那么大,这就像在小尺度上获取的特征,可以看到详细的东西。
FPN就是这样的放大镜,它可以在不同的尺度上获取不同的特征,即在大尺度上能看到整体,在小尺度上能看到细节,这样就能更好地捕捉到图像的所有信息。
特征金字塔网络(FPN)主要解决了物体检测中的一个关键问题,即如何在不同大小的尺度上都能有效地检测到物体。
在过去的方法中,往往只使用了单一的尺度来提取特征,这意味着模型可能在检测大物体时表现得很好,但是在检测小物体时效果不佳,反之亦然。
FPN通过在多个尺度上提取特征,然后合并这些特征,使得模型既能在大尺度上看到整体,又能在小尺度上看到细节,因此无论物体的大小如何,都能被有效地检测到。
特征进行融合是什么?
想象一下你正在玩一款拼图游戏,这款游戏的目标是将一堆碎片拼成一张完整的图案。
每一个碎片就像是一个特征,它只代表图案的一小部分。
单独看这一个碎片,你可能无法知道完整图案是什么。
但是,如果你开始把碎片放在一起,你就可以开始看到更完整的图案。
这就像情况是从不同的视角获得的许多特征,然后将它们融合在一起,以获得一个更完整、更准确的图像,这就是“特征融合”的过程。
简单来说,就是把许多小的信息(或特征)合并在一起,以得到一个更大、更完整的信息。
上采样的技术是什么?
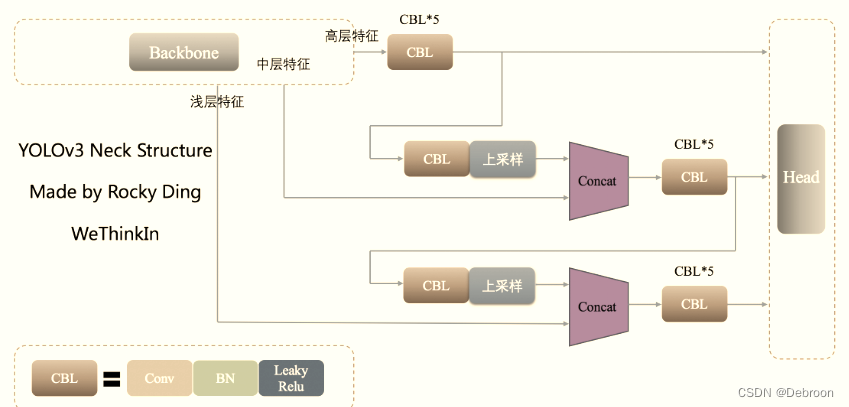
以年轻人(前面卷积层)、中年人(中面卷积层)、老年人(后面卷积层)来举例。
老年人经历最丰富,在中年人遇到难以抉择的问题时,问问老年人,从个人视角跳到全局视角,就能看清楚这到底是什么。
同理,年轻人分辩不清时也可以问中年人。
这样既可以各取所长,年轻人就擅长预测小尺度物体、中年人就擅长预测中尺度物体,谁擅长什么谁做什么。
如果捉摸不定,再结合不同的特征图融合方法,输出3尺度预测。
预测框数量上升为9
YOLO 是一种流行的对象检测算法,它的一个关键概念是做预测框。
在 YOLOv1 中,对于一个输入图像,该模型只使用两个预测框来对每个图像网格进行目标检测。
然而,这种方法有其限制,因为并非所有类型的对象都可以用一个或两个预测框有效地捕捉,一个网格有三个物体就误判或者遗落。
为了解决这个问题,YOLOv2 引入了一个改进的体系结构,其中对于每个图像网格有三个预测框。
这提供了额外的灵活性,能够更有效地捕捉多种形状和大小的目标对象。
然后在 YOLOv3 中,作者们进一步扩大了每个图像网格的预测框的数量,扩大到了九个,提供了更高的灵活性,这在检测多尺度和更为复杂的场景中尤其重要。
比方人脸检测,需要检测到的人脸可能有许多不同的大小和反转的角度,一个或两个预测框可能无法有效地捕捉所有这些差异。
但是使用更多的预测框,我们可以有更大的机会捕捉到更多的差异,从而提高我们模型的性能。
然而,增加预测框的数量也可能增加计算的复杂度和可能的误报率,因此进行这种选择时需要进行权衡。
多标签分类
YOLOv3在类别预测方面将YOLOv2的单标签分类改进为多标签分类,在网络结构中将YOLOv2中用于分类的softmax层修改为逻辑分类器。
多标签多分类问题,指一个样本(一个图片或者一个检测框)中含有多个物体或者多个label。
在YOLOv2中,算法认定一个目标只从属于一个类别,根据网络输出类别的得分最大值,将其归为某一类。
然而在一些复杂的场景中,单一目标可能含有多个物体、或者从属于多个类别。
Head侧将用于单标签分类的Softmax分类器改成多个独立的用于多标签分类的Logistic分类器,取消了类别之间的互斥,可以使网络更加灵活。
Logistic分类器主要用到Sigmoid函数,可以将输入约束在0到1的范围内,当一张图像经过特征提取后的某一检测框类别置信度经过sigmoid函数约束后如果大于设定的阈值,就表示该检测框负责的物体属于该类别。
损失函数解析
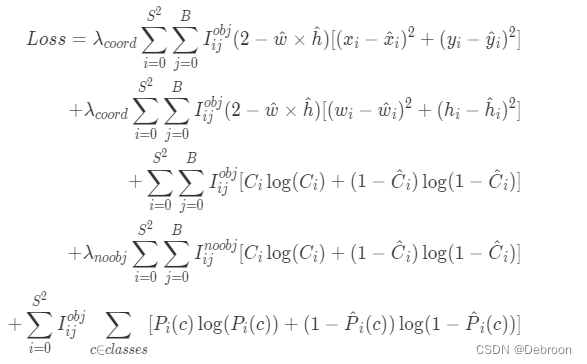
YOLOv3中置信度误差损失和分类误差损失都使用交叉熵来表示。
在处理多分类问题,特别是类别不平衡的情况时,交叉熵损失函数可以得到更好的结果。
YOLO v4
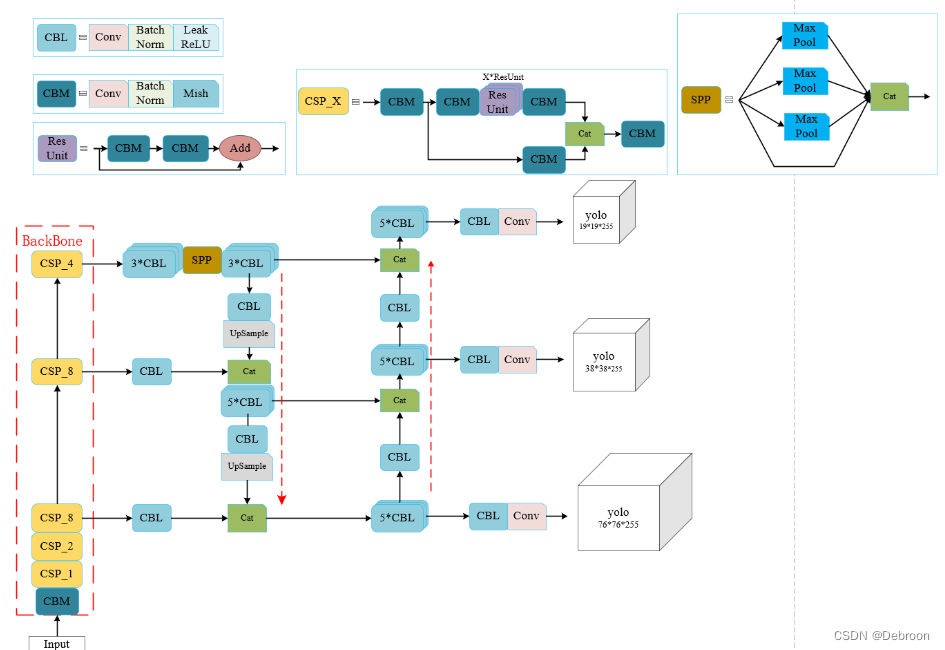
v4的Head侧沿用了YOLOv3的整体架构,主要是工程技巧,如数据增强、正则化、损失函数设计。
组合数据增强
将四个训练图像混合到一个图像中。
-
从数据集中随机选择4个图像。
-
将这4个图像合并到一个新的、更大的图像中。每个原始图像占据这个新图像的一个四分之一。
我们有很多不同的食材,比如面包、生菜、熟鸡肉、番茄等。你可以选择其中的四种食材,放在一起,就成了一个美味的三明治。
把四个训练图像混合到一个图像中,其实就像是我们做三明治一样。原本我们有四张不同的图片,每一张都有自己的特点和内容。
我们把这四张图片合在一起,就像把四种食材放在一起做成三明治那样,变成了一张新的图片。
将四张图像混合在一起创建新图像确实可以使模型在训练时遇到更多的场景和变化,这有助于提高模型的泛化能力。
泛化能力是指模型对未见过的新数据做出准确预测的能力。
新的损失函数 CIOU Loss 和 挑选机制 DIOU NMS
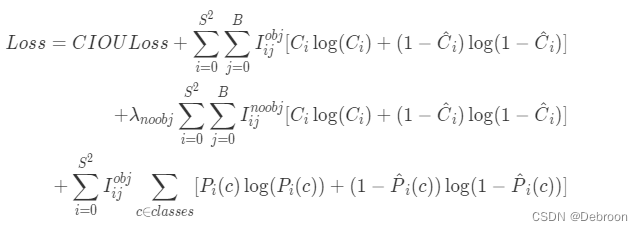
YOLOv4提出的一种新的损失函数,用于取代 v3 版本的MSE(均方误差)损失函数。
CIOU Loss不仅考虑了预测框(Bounding Box)与真实框之间的IOU(交并比)关系,还考虑了两者之间的距离及宽高比异构。
这样可以更精确地反映预测框的准确度,从而提高目标检测的精度。
原来的 YOLOv3 使用的是 IOU(交并比) 损失函数。这是通过计算预测框与实际目标框的交集与并集的比例来衡量预测精度的。
也就是说,交集越大,预测越准确。但是这种比例可能会忽略一些其他重要因素,比如目标形状的扭曲、预测框和实际框之间的相对位置等。
例如,比如我们在预测一只跑动中的狗,虽然 IOU 损失函数可能会成功地捕捉到狗的位置,但是如果我们的预测框将狗的身体拉伸变形,或者将预测框放在狗的头部而不是身体的中心,IOU损失函数可能会认为这是一个很好的预测。
在新的版本中,YOLOv3 实现了 CIOU Loss,这种损失函数在计算损失时不仅考虑预测框和真实框的IOU,还考虑了它们的中心点距离和宽长比,这样可以更好地处理目标变形和中心点偏移的问题。
传统的NMS方法只考虑了 检测框的IOU,而DIOU NMS进一步的考虑了检测框的中心点距离。
选择与最大置信度框中心距离较近,且IOU较大的框,将其进行抑制。
这样可以有效减少对相邻物体检测框的误抑制,提高了框选取的准确性。
原来的YOLOv3使用的是NMS(非极大值抑制)机制来挑选预测目标,这种方法是对所有预测框按照其置信度进行排序,选择置信度最高的框,然后移除与它重叠度高的其他框。这种方法可能会忽略一些靠近最优预测框但同样重要的目标。
例如,假设我们正在检测一张照片中的家庭成员,如果父亲和母亲站得很近,NMS可能只会选择一个人作为最优预测,将另一个人排除掉。
在新版本中,YOLOv3实现了DIOU NMS,这种方法在选择预测框时,除了考虑预测框的置信度,还会考虑预测框的位置和大小。
这就意味着,即使两个预测目标靠得很近,只要他们的位置和大小差别够大,新的方法也能同时选出它们。
引入生成对抗
自对抗训练就是模型先对自己制造难题,然后再训练自己解决这个难题,通过这种方法可以有效地提高模型的性能和泛化能力。
跨小批量标准化
标准化变成跨小批量标准化的区别,一个是全部标准化,一个是在每次比赛后都标准化一次。
为鼓励学生努力学习,从每个学期开一次家长会,到每周开一次家长会,那个反馈是每时每刻的。
空间注意力改为点注意力 CmBN
“点注意力”和“空间注意力”的主要区别在于它们关注的对象。空间注意力更关心“哪个区域”是重要的,而点注意力更关心"哪个点"是重要的。
具体实现方式可以大致分步描述如下:
在传统的空间注意模块(SAM)中:
- 将输入的图像特征(比如一张照片上的像素信息)送入最大池化层和平均池化层处理,池化层的作用是对输入的信息进行简化和压缩,减少计算量。
- 之后将池化层的输出送入一个卷积层,卷积层的作用是提取特征的一种操作,比如边缘、颜色、质地等。
- 最后,将卷积层的输出送入Sigmoid函数,Sigmoid函数的作用是将任何实数压缩到0和1之间,这样我们就得到了视觉注意力分布。
但是在YOLOv4中,点注意力的实现方式简化了这个过程:
- 首先将输入的图像特征直接送入一个卷积层,这样可以更直接地获取到图像的特征信息。
- 然后,将卷积层的输出送入Sigmoid函数,生成点注意力。
这两种方式的主要区别是原始的SAM对空间进行了重点关注,而在YOLOv4中,通过直接让卷积层处理输入特征,对每个点(像素)进行重点关注,这就是所谓的点注意力。
传统的空间注意力模型:就好比是你用一个放大镜,在看书的时候,不仅可以看到每个字,还可以看到每一页的整体内容,了解这一页上信息的大概分布。
然后根据这个大概的分布,再去找到重点的字或词。
点注意力模型:就好比是你不再使用放大镜,而是直接用眼睛去看每一个字,逐字逐句、只字不落地去仔细阅读。
因此,每一个字都是你的关注点。
这两者的区别就好比是“看森林”和“看树”。看森林能让你快速明了的了解整个景象,但可能会忽略掉一些细小的部分。
看树则可以仔细观察每一个树,每一片叶子,但可能会浪费时间,但准确性会更好。
在某些情况下,我们可能并不需要这么做,例如当我们可以明确知道我们要寻找的对象大概在图像的哪个位置时。
这时候采用空间注意力模型,“看森林”的方式,就可以在保证速度的同时,定位到我们感兴趣的部分。
批量PAN方法
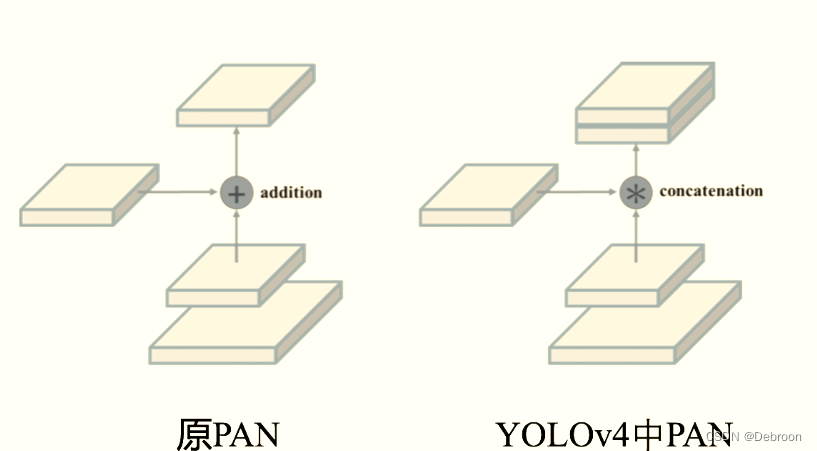
原有的PAN方法中,各个层之间的联系方式是通过直接连接,即将前面的信息直接传到后面的层次,有利于解决深度学习中的梯度消失和梯度爆炸问题。
在YOLOv4中,对PAN方式进行了一些修改,不再使用,而是引入了张量连接。
即将前面层的输出转化为一个张量,后面的层的输入也是一个张量,然后把这两个张量直接首尾相接,形成一个新的、更长的张量。
原本的PAN方法就好比一个小孩用他的玩具小跑车,一个一个的把乐高积木送到房间的另一边。但是这样做很慢,因为每次只能送一个积木。
然后,他们想出了一个新的办法。就像我们有时会把很多个乐高积木堆在一起然后一起搬,这样就可以一次搬更多的乐高积木。
一次性运送更多的数据,提高了运送效率。
CSPDarknet53(主干)
v4 的Backbone在 v3 的基础上,受CSPNet网络结构启发,将多个CSP子模块进行组合设计成为CSPDarknet53,并且使用了Mish激活函数。
CSPDarknet53总共有 72 层卷积层,遵循 YOLO 系列一贯的风格,这些卷积层都是 3×3 大小,步长为 2 的设置,能起到特征提取与逐步下采样的作用。
CSP子模块主要解决了由于梯度信息重复导致的计算量庞大的问题。
将基础层的特征图分成两部分,一部分直接与该阶段的末尾concat相连,另一部分经过局部Dense模块,从而既能保留Dense模块的特征复用,又能截断梯度流,避免大量的重复计算,同时可以保证准确率。
你可以将Darknet53想象为一个大厂房,里面有53个工人(也就是53层的神经网络)共同工作,制作出我们需要的产品。
而CSPDarknet53则更像是将这个厂房的工人分成两队,一部分人继续原来的工作,另一部分人则直接为最后的产品增加一些修饰,使得我们的产品更好。
再来看激活函数,你可以把它想象成工人对原料的处理方式。Leaky ReLU是一种处理方式,当原料好的时候,工人可以正常工作,当原料不好的时候,工人也会尽量处理,但是效果不太好。
Mish激活函数的示意图如下,其有三个主要特征:
- 无上界有下界。Mish向上无边界避免了由于封顶而导致的梯度饱和,加快训练过程。向下有边界有助于实现强正则化效果。
- 非单调函数。允许其在负半轴有稳定的微小负值,从而使梯度流更稳定。与ReLU负半轴的硬零边界相比,其梯度更平滑。
- 无穷连续性与光滑性。具有较好的泛化能力,提高训练结果的质量。
Mish处理方式则像是一个升级版的工人,无论原材料好坏,他都能把它处理得很好,所以在YOLOv4中,使用的是这种"升级版"的工人。
SPP附加模块(颈)
SPP结构又被称为空间金字塔池化,能将任意大小的特征图转换成固定大小的特征向量。
SPP模块代替了卷积层后的常规池化层,可以增加感受野,更能获取多尺度特征。
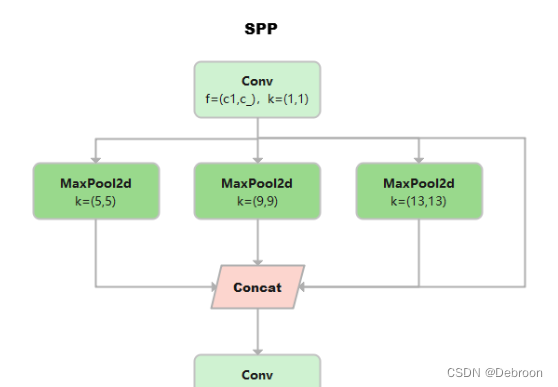
SPP(Spatial Pyramid Pooling)是一种空间金字塔池化的网络层,主要解决了如下两个问题:
-
输入尺寸不定的问题:传统的卷积神经网络(CNN)需要固定尺寸的输入,而在实际应用中,图像或者视频的尺寸却经常不一致。SPP层可以接收任何尺寸的输入,可以生成固定长度的输出,因此很好的解决了这个问题。
-
物体尺寸和位置的问题:SPP层通过在某一层上生成多个不同尺度的子区域,提取不同子区域的特征,并将它们连接起来以形成最后的输出。SPP层不仅可以编码物体的空间信息,包括物体的尺寸和位置,而且引入了图像的多级表示,能够在不同的空间尺度上捕获物体和形状。
SPP能够提高模型的性能。因为SPP层对于输入的尺寸是可适应的,这就意味着SPP层能在没有裁剪或者缩放的情况下,识别和处理任何尺寸的图像或视频。
此外,SPP还提高了模型对于物体的识别精度,因为它可以编码物体的位置和尺度信息。最后,因为SPP层允许模型在不同的空间尺度上处理图像,因此SPP层可以为卷积神经网络引入了一种形式的空间不变性。
记住,尽管SPP有这些优点,但也存在一些限制,比如它增加了模型的复杂性,通常会使训练变得更加复杂,同时它的输出需要通过全连接层,这会增加模型的参数量。这些都是在使用SPP层时需要考虑的因素。
我们的眼睛看到的物体都有不同大小和形状,但是我们的大脑可以对它们进行分类。
这就是SPP结构所做的。无论输入图像的大小如何,SPP都可以将其转化成统一大小的特征,用21个特征(或者更多)去描述这个输入图像。
这样,就像我们的大脑一样,神经网络也能准确地辨认出输入的物体,无论它的大小如何。
在YOLOv4中,具体的做法就是:分别利用四个不同尺度的最大池化对上层输出的特征图进行处理。
最大池化的池化核大小分别为13x13、9x9、5x5、1x1,其中1x1就相当于不处理。
就像我们在切水果的时候,把大西瓜切成小块,小块,再小块,最后切成我们想要的大小一样。
在处理特征图的时候,他们会用四个不同的“刀”去切,就像我们切西瓜一样。
这四把“刀”就是他们的四个不同的池化,大小分别为13x13、9x9、5x5、1x1,这就好比我们用四种不同大小的刀去切西瓜,大刀切大块,小刀切小块。
1x1的“刀”又是什么呢?这就好比我们有一把特殊的刀,不论切到什么东西,都保持原样,不会切成小块,这就是1x1的“刀”所做的事情。
这样做的好处就是,不论这个“照片”是大是小,最后都能切割成我们想要的样子。
用 PANet 来替代 FPN
PANet结构的四个主要部分:
-
FPN(Feature Pyramid Network):这是一种特征提取结构,其设计的目的是为了改善传统的卷积神经网络在处理尺度变化大的目标时的性能问题。通过将高层(高语义,低分辨率)和低层(低语义,高分辨率)的特征进行融合,FPN能在各个尺度上都能获得丰富的语义信息。
-
Bottom-up path augmentation:这个部分主要是为了更好地利用网络浅层的特征信息(比如边缘、形状等低级别特征),因为这些信息在实例分割任务中非常重要。
-
Adaptive feature pooling:这是一种特征融合的方法,它会根据每个ROI提取不同层级的特征进行融合,有助于提高模型的性能。
-
Fully-connected fusion:这是一个由前景/背景二分类全连接层构成的支路,通过与原有的分割支路(即全卷积网络,FCN)合并,能得到更精确的分割结果。
在YOLOv4中,作者采用了PANet作为参数聚合的方法,其主要目的是为了更好地利用不同层级上的特征信息。
这种设计使得YOLOv4能针对不同的检测器级别,都能从相应的主干层进行参数聚合,从而提升模型在处理不同尺度目标时的性能。
PANet通过增加Bottom-up path augmentation、Adaptive feature pooling 和 Fully-connected fusion功能强化了FPN的能力,使得模型在处理实例分割任务时有更好的表现。
这些优化功能让网络在处理高层和低层特征时更加强大,尤其对于处理小目标和复杂场景。
假设我们正在处理一个街景图像,其中既有大尺度的对象(如建筑物)也有小尺度的对象(如行人或者自行车)。如果只使用FPN,由于其对底层特征的忽略,可能会导致对于小目标检测的性能下降。
另一方面,仅使用FPN可能会缺乏对不同层特征的充分利用和融合。
然而,如果我们用PANet替换FPN,就能得到更好的结果。
首先,通过Bottom-up path augmentation,模型能更好地采用和利用浅层的特征,比如小目标的精细结构和形状信息。
然后通过Adaptive feature pooling,我们可以更有效地融合不同层级的特征,使得模型对大尺度和小尺度对象都有很好的识别能力。
最后,Fully-connected fusion可以通过合并分割网络和分类网络输出,得到更精确的实例边界,从而使得模型在复杂场景中有更好的表现。
总的来说,相对于FPN,PANet在充分利用特征信息,尤其是处理小目标和复杂场景时有显著的优势。
这使得模型在实例分割任务上的性能得到了显著提升。
YOLO v5
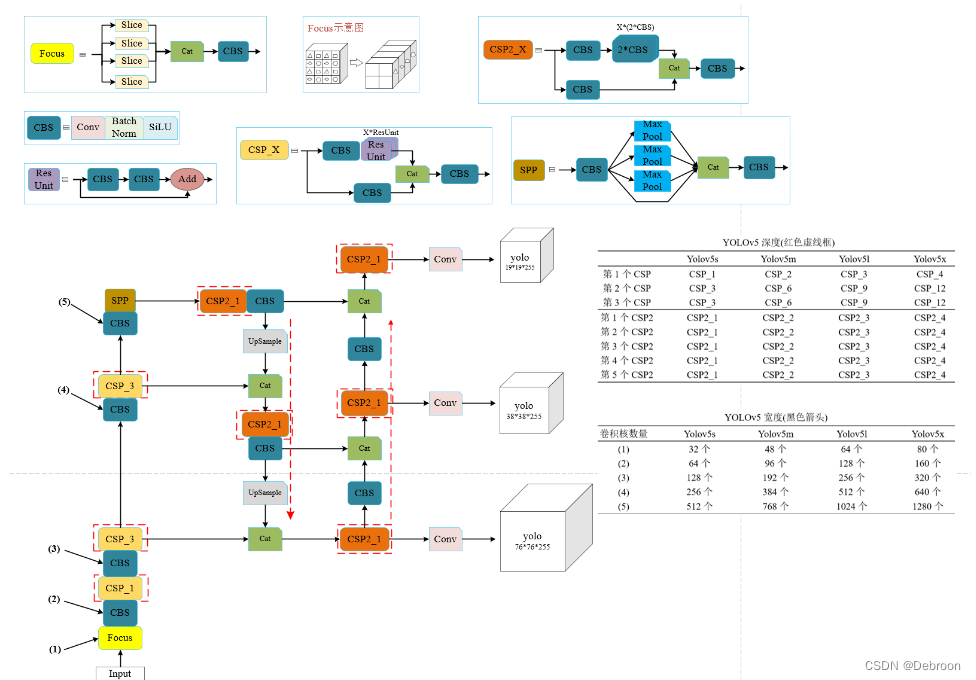
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。
主要的改进思路如下所示:
- 输入端:在模型训练阶段,提出了一些改进思路,如自适应锚框计算、自适应图片缩放;
- 基准网络:融合其它检测算法中的一些新思路,如Focus结构;
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间添加了SPP模块、FPN+PAN模块(这两结构上文有介绍);
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
自适应锚框
自适应锚框计算是计算机视觉中的一种技术,旨在在多尺度、多宽高比下捕获图像中的物体。
比如说我们要检测一张图片中的篮球和篮球框。篮球占据的像素面积较小,方向较为固定,形状较圆,对应的锚框可能会较小且接近正方形。
而篮球框占据的像素面积较大,方向可能有倾斜,形状接近矩形,对应的锚框就可能会较大且接近长方形。
通过聚类的方法,来从许多已标定的物体(比如,在训练集中)中“学习”出适合的锚框大小和宽高比。
在计算过程中,我们希望每个物体与其对应的锚框的交并比(IoU)尽可能大。
交并比反映了物体与锚框的匹配程度:完全匹配时IoU为1,完全不匹配时IoU为0。
通过调整锚框的属性,我们可以尽可能提高所有物体的总 IoU,使之适应各种目标,这就是自适应锚框计算的过程。
自适应图片缩放
为了应对输入图片尺寸 不一的问题,通常做法是将原图直接resize成统一大小,但是这样会造成目标变形,比如拉长。
实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。
为了进一步提升YOLOv5算法的推理速度。
为了避免这种情况的发生,YOLOv5采用了灰度填充的方式统一输入尺寸,避免了目标变形的问题。
灰度填充的核心思想就是将原图的长宽等比缩放对应统一尺寸,然后对于空白部分用灰色填充
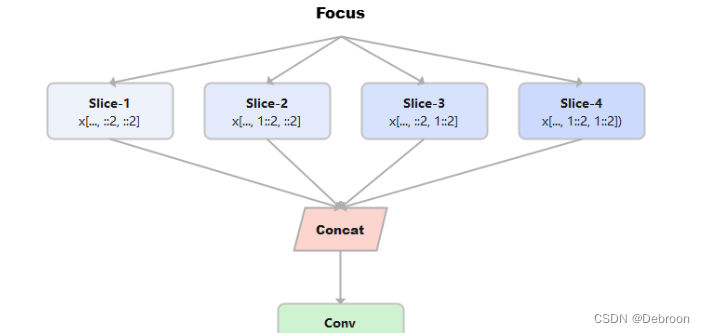
Focus结构
又称焦点结构,它是形式语言学中的一个概念,用于描绘句子中被强调或是对比的元素。焦点结构可以通过多种途径表达,包括句子的语法结构变化,词汇选择,词语位置的改变或是语调的强调等。
例如,对于这个问题:“你最喜欢吃什么?”
我们可以用焦点结构来强调不同的答案:
- “我最喜欢吃的是巧克力。” — 在此句中,“巧克力”被设定为焦点,因为它是句子的新信息或关键信息。
Focus结构作用:
首先,我们设想有一只神奇的望远镜,这就是我们的Focus结构。
当我们通过这只望远镜观察一个场景时,它可以自动帮我们找出最重要的部分,也就是我们应该重点看的地方。
然后,就是我们的YOLO物体检测模型,继续处理。
我们会把整个场景分成很多小格子,然后我们的YOLO会去每个小格子里找有没有我们要找的物体,比如人、狗、猫。如果找到了,我们的相机就会记住它们在哪里,它们的大小是什么。
这样,我们就可以通过望远镜和相机,找到场景中所有的物体,知道它们的位置和大小了。
所以,Focus结构就像我们的智能望远镜,帮助我们找到重要的部分,而YOLO物体检测模型就像我们的智能相机,让我们可以找到每个小格子里的物体。
在大部分情况下,我们可能并不需要在图像的每一个小格子上进行物体检测,因为很多小格子内可能根本就没有我们感兴趣的物体。
这时候,如果有一个“智能望远镜”(Focus结构)能先帮我们将视线集中在最可能出现物体的区域,只对这些区域使用YOLO检测,我们就可以大大节省处理时间,整个检测过程也会更加高效。
总的来说,Focus结构作用就是在不降低物体检测准确率的前提下,尽可能地提高检测速度,让整个过程更加快捷方便。
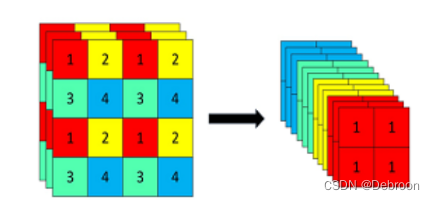
Focus模块在v5中是图片进入backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值。
类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失。
这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
跨网格匹配
YOLOv5的跨网格匹配策略在为ground-truth分配预测框时放宽了原先的限制。原先的规则在每个单元格上只为最中心的对象选择一个anchor box,但是这种方法在处理一些小、大或者密集的对象时,效果并不太好,因为这些对象可能不完全符合原先的规则。而YOLOv5的跨网格匹配策略放宽了这些限制。
特别地,这种跨网格匹配策略将ground-truth对象匹配到3个最佳的预测框,而不再是仅匹配到中心点落入的那个网格,这种方式改善了各种大小和形状的对象的匹配准确度,允许模型可以将一个对象分配到多个预测框,使得训练更加准确和稳定。
简单来说,跨网格匹配主要解决了两个问题:
- 提升了小目标、大目标、密集目标的检测性能,减少了误检和漏检的情况。
- 提高了模型训练的稳定性,加速模型的收敛速度。
假设你正在使用一个目标检测模型尝试识别一幅图像中的篮球。在原先的规则中,模型会选择每个单元格上最中心的篮球,然后为其分配一个anchor box。在此情况下,只要篮球的中心点落入某个单元格,那么该单元格就会被指定为代表篮球的anchor box。
然而,如果你在图像中有两个篮球密集堆叠或相互靠近,这会造成问题。由于这两个篮球的中心可能都落在同一个单元格中,原先的规则只会为其中一个篮球选择一个anchor box,而忽略另一个篮球。
为了解决这个问题,YOLOv5引入了跨网格匹配的策略。
在这种策略中,模型将寻找三个最佳的,而不仅仅是一个最佳的预测框,并将它们匹配给ground-truth对象,比如篮球。
所以,即使两个篮球的中心都落在同一个单元格中,如果它们是三个最佳预测框之一,那么每个篮球都会被匹配到一个anchor box。这种方法提高了模型对小目标、大目标、密集目标的检测性能,并且使模型训练更加稳定。
更精确的损失函数 GIOU_Loss
GIOU_Loss是一种测量预测边框和真实边框之间差异的损失函数,全名为Generalized Intersection over Union Loss。
它是在传统的IOU(Intersection over Union)基础上的扩展,除了考量预测边框与实际边框的交并比,还考虑一种更全面的举证,即预测边框与实际边框的大小和位置关系。
GIOU_Loss的好处主要有以下几点:
-
解决了IOU存在的问题:IOU只考虑了实际边框和预测边框之间的重叠程度,没有考虑到边框的位置关系。而GIOU_Loss不仅考虑了重叠程度,还考虑了边框的中心位置,因此在保证精度的同时,也更注重边框的位置准确性。
-
提升了训练稳定性:使用GIOU_Loss作为损失函数,可以使训练过程更稳定,帮助模型更快地收敛。
-
确保了更精确的边框回归:因为GIOU_Loss更全面地考虑了边框的各项特性,因此可以确保更精确的边框回归,从而提高模型的检测性能。
总的来说,GIOU_Loss是一种更好地度量预测边框和实际边框差距的损失函数,能够帮助模型实现更精确的边框预测,提高目标检测的效果。
SPP + PAN + CSP 设计
SPP + PAN 设计:

SPP + PAN + CSP 设计:
YOLOv5的Neck侧也使用了SPP模块和PAN模块,但是在PAN模块进行融合后,将YOLOv4中使用的常规CBL模块替换成借鉴CSPnet设计的CSP_v5结构,加强网络特征融合的能力。
CSP (Cross-Stage Partial Network) 是一种全新的卷积网络设计模式,其主要目标是提升网络的表现力,同时降低网络计算复杂度。
它的主要思想是将原来的一个完整的网络层进行等效拆分,形成了部分逐个独立的自循环和交叉连接的子网络。
常规CBL模块通常是串行的,在这个模块中,数据从卷积层传递到归一化层,再传递到激活层。
在CSPNet 中,一个CSP模块可以分为两个部分,一个是主干部分(或称为残差部分),之后是一个短的跨接路径。
与CBL模块相比,CSP结构增加了跨阶段的短连接。
如果我们将一层100个卷积核的卷积层,拆分为两个各有50个卷积核的卷积层,并行计算,然后再合并结果。
虽然卷积操作数目没有减少,但我们实际保存在内存中的特征图数量是减少了的,因为两个小的卷积层并行处理,所以不需要同时保存所有的特征图。
CSP结构的主要影响体现在内存消耗(减少50%的内存占用),参数数量和特征复用性上。
与常规CBL模块比较,CSP模块的设计可以减少训练时的特征图数量,进而减少内存消耗。
同时它可以增加特征图的复用性从而提高表示能力。
YOLOx
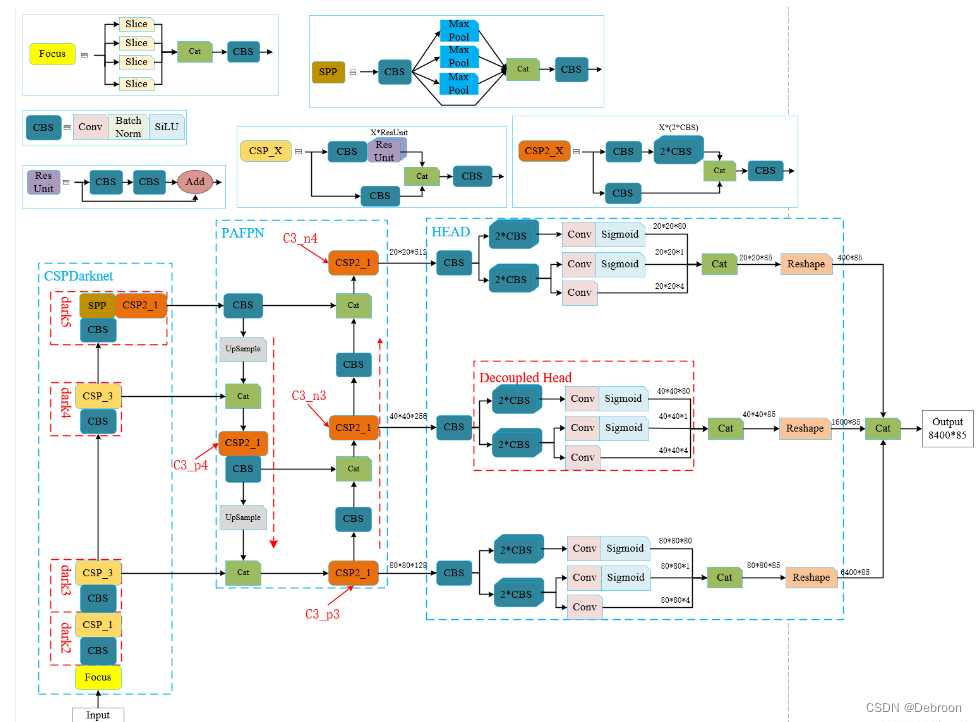
在选择Yolox的基准模型时,作者考虑到 Yolov4和Yolov5系列,从基于锚框的算法角度来说,可能有一些过度优化 ,因此最终选择了Yolov3系列。
不过也并没有直接选择Yolov3系列中标准的Yolov3算法,而是选择添加了spp组件,性能更优的Yolov3_spp版本 。
解耦头 Decoupled Head
YOLOX使用解耦头(Decoupled Head)是为了提高模型的性能和灵活性。
传统的目标检测算法(如YOLOv3和YOLOv4)通常使用单一的检测头(Detection Head)来预测目标的类别和位置。这种设计会导致类别和位置之间的耦合,可能限制了模型的性能。
解耦头的设计将目标的类别和位置分开预测,分别使用独立的子网络进行处理。
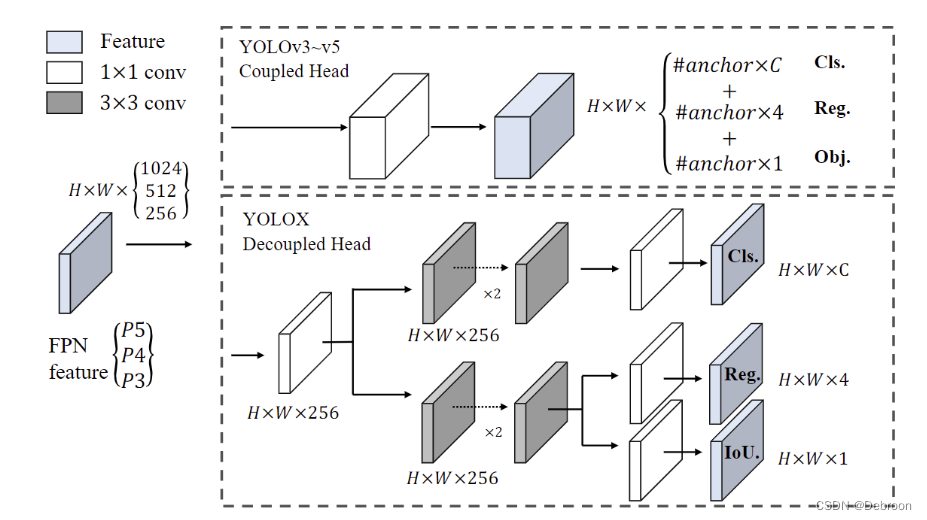
具体来说,YOLOX使用了两个独立的子网络:
- 一个是类别子网络,负责预测目标的类别信息
- 另一个是回归子网络,负责预测目标的位置信息
想象你在玩一个比赛游戏,在游戏中,你需要同时做两件事:跳跃和投篮。
如果你同时做这两个动作,可能会导致效果不好。
你可能既没有投篮,也没有跳得高。但如果你先跳跃,再投篮,你可能会做得更好。这就是解耦的概念。
同样,YOLOx也使用了解耦的想法,它把目标检测的两个任务 - 框回归(确定物体在图片中的位置)和类别分类(确定物体的种类)分开。
让模型先做一个任务,再做另一个,这样可以让模型更专注,也让任务之间互不干扰。
Anchor-Free
在传统的目标检测算法中,使用锚框(Anchor Boxes)来识别目标物体的位置和尺度。锚框是一些预定义的矩形框,通过在图像上以不同的尺度和宽高比进行密集采样,用于捕捉不同大小和形状的目标物体。
而在Anchor-Free目标检测算法中,不再依赖于预定义的锚框。相反,它直接通过网络结构来预测目标物体的位置和尺度,而不需要预先定义或采样锚框。
Anchor-Free算法的优点之一是减少了预定义的锚框的数量和大小的选择,减少了设计和调整的复杂性。此外,Anchor-Free方法对于不规则形状的目标物体有更好的适应性,因为它不依赖于预定义的矩形锚框。
YOLOx使用的anchor-free思想,比起YOLO系列中常规的anchor-based,在Head侧可以减少约三分之二的参数。
Anchor-Free算法则不依赖于预定义的锚框,而是直接在特征图上进行目标检测。它通过密集地将特征图划分为网格或像素级别,然后对每个位置进行目标分类和位置回归。这样,每个位置都可以直接预测目标的存在与否以及目标的位置信息。
Anchor-Free的优势包括:
-
增加目标检测的灵活性:Anchor-Free算法可以自适应地捕捉不同尺度和形状的目标,不受预定义锚框的限制。这使得算法更具适应性,可以更好地处理复杂的场景。
-
减少设计和计算的复杂性:由于不需要预定义锚框,Anchor-Free算法的设计更为简单,并且可以减少计算量和参数量,提高模型的效率。
-
提高目标检测性能:一些Anchor-Free算法已经在目标检测任务上取得了较好的性能表现,尤其在小目标和密集目标的检测上表现出优势。
然而,Anchor-Free算法也存在一些挑战,例如对于目标的定位和尺度较大的目标检测仍然具有一定的挑战。因此,在选择目标检测算法时,需要根据具体的应用场景和任务需求来综合考虑Anchor-Free和Anchor-Based算法的特点和优劣。
正负样本匹配策略 SimOTA
SimOTA 是YOLOX中使用的一种正负样本匹配策略,用于筛选与真实目标较为相似的锚框。
在目标检测中,需要将锚框与真实目标进行匹配,确定正样本和负样本。传统的匹配策略通常使用IoU来衡量锚框与真实目标之间的重叠程度。当IoU大于阈值时,将锚框视为正样本,小于阈值时,将锚框视为负样本。
而YOLOX中引入了SimOTA策略,通过计算锚框与真实目标的相似性来代替传统的IoU匹配。具体来说,SimOTA首先计算锚框和真实目标之间的相似性,然后将相似性与阈值进行比较,以决定正负样本的匹配。
相似性的计算使用了GIOU,它不仅考虑了目标的重叠程度,还考虑了目标的大小和形状的差异。
如果一个箱子很大且形状像一个球,那你就可以猜测它里面可能是一个篮球。这就相当于传统的IoU策略,也就是看箱子(锚框)和物体有多大程度的重叠。
但在YOLOx的SimOTA策略中,你不再只是看这个箱子是否像一个球。你还会想,如果这是一个篮球,那它应该有一定的重量和硬度。然后你会试着去摇箱子或者捏箱子,来看它是否和你想象的篮球一样。这就是SimOTA的工作方式,它不仅看重叠程度,也看其他的相似性因素,例如大小和形状。
这样,你就可以更准确地找出可能是篮球的箱子,从而在游戏中取得更好的成绩。这就是SimOTA在目标检测中的效果,提高了我们找出真正目标的准确率。
YOLOv5的正负样本分配策略是基于邻域匹配,并通过跨网格匹配策略增加正样本数量,从而使得网络快速收敛,但是该方法属于静态分配方法,并不会随着网络训练的过程而调整。
YOLOx使用的SimOTA能够算法动态分配正样本,进一步提高检测精度。
而且比起OTA由于使用了Sinkhorn-Knopp算法导致训练时间加长,SimOTA算法使用Top-K近似策略来得到样本最佳匹配,大大加快了训练速度。
损失函数 GIoU
IoU (Intersection over Union)、CIoU (Complete IoU)、DIoU (Distance IoU)和GIoU (Generalized IoU)都是常用的目标检测模型中计算预测框损失的方法,它们的主要区别在于如何衡量预测框和真实框之间的差距:
-
IoU(Intersection Over Union):是最基础的版本,通过计算预测框与真实框的交集与并集之比来得到损失。但是,当预测框与真实框无交集时,IoU 的值为0,这导致无法对这种情况进行有效优化。
例如,我们有一个目标在图像的左上角,但模型预测它在右下角,即便是位置偏差非常大,IoU值也为0。
-
GIoU(Generalized Intersection Over Union):在 IoU(重叠面积)的基础上 + 不重叠问题 ,引入了包围预测框和真实框的最小闭合框的概念,对预测框位置偏差极大的情况进行了优化。
例如,同样一个目标在图像的左上角,模型预测它在右下角,GIoU就会计算出一个扩大了的包围框,并依此计算出一个可优化的值。
-
DIoU (Distance IoU):在 GIoU (重叠面积 + 不重叠问题)的基础上 + 中心点距离的信息,包含了预测框和实际框中心点距离的因素,优化了模型对目标位置误差的评估。
例如,我们的目标在图像中心,模型预测到的位置在图像的边缘,虽然二者有一定的重叠,但预测框和真实框的中心点距离较远,使用DIoU,我们可以给予更大的惩罚。
-
CIoU (Complete IoU):在 DIoU(重叠面积 + 不重叠问题 + 中心点距离)的基础上 + 宽高比,进一步包含了目标框和预测框宽高比的差异,不仅关注位置和大小,还关注形状。
例如,真实目标是个瘦长形状(如自行车),如果模型预测出来的是个接近正方形的框,即便位置和大小接近正确,CIoU也会计算出较大的损失,因为形状的误差。
GIOU 与传统的 IOU 相比,主要优势在于能够解决 IOU 无法处理的两个问题:
-
当两个边界框没有交集时,IOU永远为0。这将导致无法区分两个不相交边界框的相对位置和距离。例如,与目标的实际边界框相比,一个预测边界框离得稍远些,另一个离得非常远,但IOU对它们的评估都是0。GIOU在这种情况下可以返回一个负值,以便更好地区分这些情况。
-
IOU只关注了目标区域的覆盖度,并没有对边界框位置的这种分布情况进行评估。GIOU在此基础上额外引入一个衡量预测边界框位置误差的因素。
总的来说,GIOU关注的是两个边界框的相对位置和尺寸,这使得它在对象检测任务中的性能优于IOU。
YOLO v6
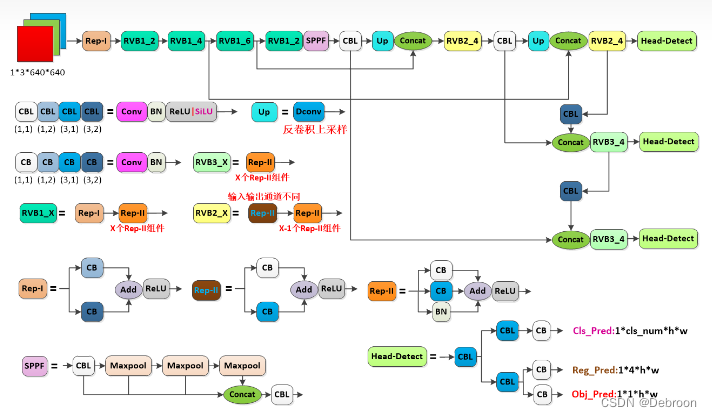
YOLOv6 主要在 Backbone、Neck、Head 以及训练策略等方面进行了诸多的改进:
- 统一设计了更高效的 Backbone 和 Neck :受到硬件感知神经网络设计思想的启发,基于 RepVGG style设计了可重参数化、更高效的骨干网络 EfficientRep Backbone 和 Rep-PAN Neck。
- 优化设计了更简洁有效的 Efficient Decoupled Head,在维持精度的同时,进一步降低了一般解耦头带来的额外延时开销。
- Head侧和YOLOx一样使用Anchor-free逻辑和SimOTA标签分配策略,并在其基础上改进了Decoupled Head(解耦检测头)结构,在损失函数中引入了SIoU边界框回归损失。
更改激活函数
swish函数要用到sigmoid函数。
sigmoid函数是由指数构成的,在移动设备上的计算成本要高得多,以及每次计算都是按照浮点数计算的。
数据转换是需要时间的,量化带来的性能提升会被这些额外引入的损耗消磨殆尽。
理论上,把激活函数改成 relu 就能提升 20% 性能。
骨干网络 EfficientRep Backbone
YOLOv5、YOLOX 使用的 主干网络 和 Neck 都基于 CSPNet 搭建,采用了多分支的方式和残差结构。
对于 GPU 等硬件来说,这种结构会一定程度上增加延时。
基于 RepVGG style 设计了可重参数化、更高效的骨干网络 EfficientRep Backbone 。
在神经网络的训练阶段,RepVGG结构利用多分支拓扑的设计,增加网络结构的复杂性,帮助网络提取更丰富和复杂的特征,提高模型的表现力。三个分支包含一个3x3的卷积层,一个1x1的卷积层以及一个恒等映射层。
但是,在实际部署阶段,为了提高计算效率和减小内存占用, 这三个分支会被等效融合为一个单一的3x3卷积。
3x3卷积是计算机视觉中常用的操作,尤其在专门的硬件(如GPU)上适用于大规模计算,有良好的硬件加速效果。由于单一的3x3卷积的计算能力往往高于多分支结构,所以能更有效地利用计算资源。
比如你的输入是一个4x4的矩阵,在RepVGG的训练阶段,它可能将这个4x4的矩阵同时通过3x3的卷积、1x1的卷积和恒等映射三个分支后再将结果进行加和,形成最终的结果。
在实际部署的时候,它将这三种操作等效转化为一个3x3的卷积操作,直接作用在4x4的矩阵上,得到的结果与训练阶段的结果一致,但计算效率大大提高。
同时检测多个目标特征 Rep PAN
通过将Rep PAN与YOLO结合,可以实现同时检测多个目标的高效目标检测。
YOLOv5是一个常见的实时图像检测模型,在其模型结构中使用了CSP-Block。而Rep-PAN则采用了RepBlock。
两者的主要区别在于,CSP-Block和RepBlock都是为了增加网络的深度和宽度,从而提取更复杂和丰富的特征,但是它们的设计理念和具体实现方法是不同的。
YOLOv5和Rep-PAN是两种计算机视觉模型,它们的主要区别在于它们处理图像数据的方法。就像你学习解决数学题一样,YOLOv5和Rep-PAN都是解决特定问题的方法。
它们都能从图像中识别出不同的物体,但是他们处理问题的方式不同。
YOLOv5像一个有特殊技能的人,它能快速地看到图像中的物体,但有时候可能会漏掉一些细节。
因为YOLOv5使用了一种叫做CSP-Block的技术,它会将图像分成几部分并分别处理,然后再将结果合并在一起。
就像一个团队中的队员各自负责一个部分,然后将各自的工作成果汇总在一起。
而Rep-PAN像是一个更加细致的人,它使用了一种叫做RepBlock的技术,这种技术会使用多种方法同时处理图像,然后再将结果合并。
就像一个团队中的队员同时负责多个任务,然后将所有任务的成果汇总在一起。
这两种方法都有它们的优点,因此选择哪种方法取决于你对速度和细节的需求。
例如,如果你需要快速处理图像,可能会选择YOLOv5;如果你需要更细节的处理,那么可能会选择Rep-PAN。
这就像你做作业时,做选择题可能会更快,但是做作文可能会需要更长的时间,但是你可以通过作文展示出更多的细节。
所以,你可以根据你的需求决定使用哪种方法。
损失函数 SIoU loss
之前版本的损失函数依赖于边界框回归指标的聚合,虽然考虑到检测框与ground truth之间的重叠面积、中心点距离,长宽比这三大因素,但是依然缺少了对检测框与ground truth之间方向的匹配性的考虑。
这种短缺导致收敛速度较慢且效率较低,因为预测框可能在训练过程中“四处游荡”并最终产生更差的模型。
v6 提出了一种新的损失函数 SIoU,其中考虑到所需回归之间的向量角度,重新定义了惩罚指标。
也就是说,对于同样的回归误差,之前的损失函数不会因为预测框偏向左上角或右下角而有所区别。
例如,假设图像中有一个真实的目标框,现在有两个预测框A和B,都离真实框有一定的距离。
假设预测框A偏离真实框在左上角,预测框B偏离真实框在右下角。
然而对于多数的损失函数,如IoU, GIoU等,它们只会计算预测框与真实框的重叠程度、距离等,而不会考虑这个"偏离"是向左上角还是向右下角。
也就是说,对于A和B这两个预测框,它们的损失值可能是相同的。
而 v6 版本中的新的 SIoU 损失函数则考虑了预测框相对于真实框偏离的方向。
这样就可以区分出框A和框B的误差程度,使得模型在学习过程中能更精确地修正预测框的位置,从而提高模型的性能并加快收敛速度。
SimOTA标签分配策略
YOLOv6中的SimOTA标签分配策略是为了解决对象检测中不同大小和形状的目标匹配问题。对象检测任务中,目标的大小和形状各不相同,因此,不同大小和形状的目标需要被匹配到不同大小的检测框。
传统的YOLO系列方法通常使用预设的大小和形状的锚框来匹配目标,但这种方式对匹配精度要求很高,且对于某些不规则大小和形状的目标,可能无法找到合适的锚框进行匹配。
而YOLOv6中,采用的SimOTA标签分配策略则通过计算目标和候选框之间的相似度,找出与目标最匹配的候选框,使得匹配过程更加精确,从而提高了目标检测的精度。
总结来说,SimOTA标签分配策略是要解决传统的YOLO系列方法对于锚框设定过于固定,不能灵活应对各种大小和形状的目标的问题。
假设我们有一箱各种各样的玩具,有简单的积木,有复杂的电动玩具,还有不同类型的拼图等等。我们要把这些玩具分配给一群小朋友玩。
SimOTA标签分配策略就像是一个规定,告诉我们如何给小朋友分配玩具。可能有以下的一些规则:
根据小朋友的年龄和能力:小朋友年龄大一些,能力强一些,我们给他复杂一点的玩具,比如电动玩具或者困难一些的拼图。小朋友年龄小一些,我们给他简单一些的玩具,比如积木。
根据玩具的类型和数量:如果有的玩具很多,可以给很多小朋友,如果有的玩具只有一个,可能只能给一个小朋友。
根据各个小朋友的喜好:如果有的小朋友特别喜欢积木,我们可能会优先给他积木。
以传统的YOLO方法为例,通常是为了匹配目标,预设了几种不同比例和大小的锚框。假设我们有一个预设的5x5的锚框,那么这个锚框如果要去匹配一个长方形的目标(比如10x5),或者一个比它大得多的目标(比如20x20),就会出现匹配不准确的情况。这就可能导致其训练出来的模型对于这些不同大小和形状的目标的检测效果不佳。
而在YOLOv6中,利用SimOTA标签分配策略,它并不直接使用预设的锚框去匹配目标,而是计算出所有可能的候选框与目标的相似度,然后选择与目标最相似的候选框作为其匹配对象。
所以无论目标是长方形的,还是比预设的锚框大得多,或者小得多,只要能找到与其最匹配的候选框,就能够使得匹配过程更加精确,提高目标检测的精度。
YOLO v7
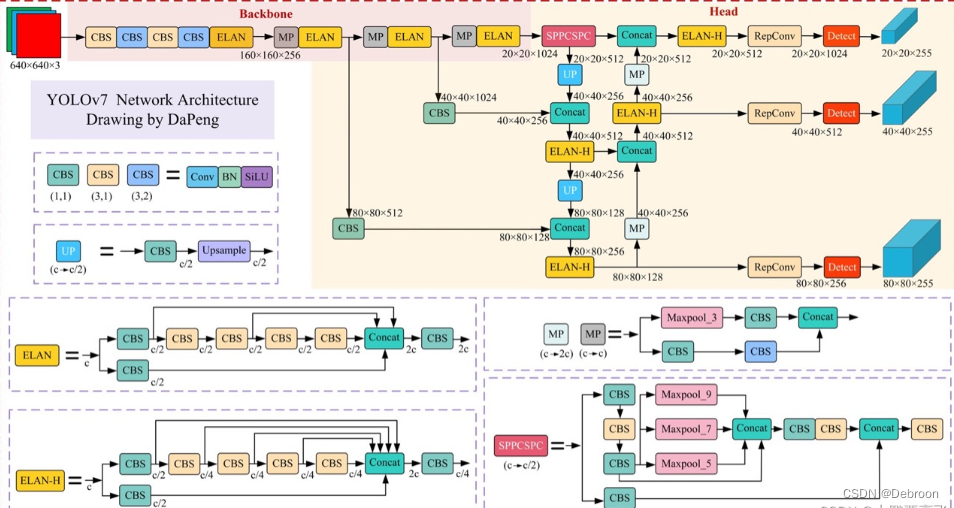
Backbone侧:YOLOv7在YOLOv5的基础上,设计了E-ELAN和MPConv结构。
Head侧:YOLOv7使用了和YOLOv5一样的损失函数,引入RepVGG style改造了Head网络结构,并使用了辅助头(auxiliary Head)训练以及相应的正负样本匹配策略。
E-ELAN
首先,ELAN(Efficient Local AttentionNormalization)模块和CSP(Cross Stage Partial)模块是两种针对现有网络结构的优化设计进行不同问题的解决。
ELAN模块主要解决的是注意力机制的问题。在很多神经网络结构中,自注意力机制是常见的一个策略,但是这种机制的计算量增加是非常显著的,特别是对于大规模的数据来说。为了解决这个问题,ELAN模块提出用一种更高效的局部注意力机制来代替原有的自注意力。局部注意力可以化简计算,并且可以减少计算资源消耗,从而在训练大规模数据时,可以提高训练效率。
注意力机制解决的问题:序列到序列模型中的长距离依赖问题: 在NLP中,长句子中的词语可能会相互影响。注意力机制可以帮助模型关注到输入序列中距离当前输出位置更远但是比较重要的位置,比如处理翻译或摘要等任务时。
我们不再尝试把所有信息压缩到一个固定长度的向量中,而是让模型在解码时根据需要选择关注哪些信息,大大解决了长距离依赖关系的问题。
CSP模块主要解决的是特征重用的问题。CSP网络通过部分地连接前一层的特征映射和后一层的特征映射,实现了更高效的特征融合和信息流通,提高了网络的性能,但对于一些不明显的或者是长距离的依赖关系可能会由于其浅层特征重用的特性而被削弱。
因此,两者并没有绝对的优劣之分,具体使用哪一种,需要根据具体的应用场景和问题来决定。
扩展的高效层聚合网络。提出的扩展ELAN (E-ELAN)完全不改变原架构的梯度传输路径,而是使用群卷积来增加添加特征的基数,并结合 以洗牌和合并基数的方式显示不同组的特性。
扩展的高效层聚合网络(E-ELAN)的目的是增强特征图之间的多样性,从而能够提取到更多样的特征,提高模型的表现。
在此过程中,群卷积被用来增加被添加特征的基数,这可能是通过增加特征图的数量来实现的。
“洗牌和合并基数的方式显示不同组的特性”,通过某种方式对特征图进行重新排序和整合,以更好地显示不同组的特征,这也是为了提高模型对于特征的利用效率。
“改进参数和计算的使用”,E-ELAN通过某种方式提高了模型参数的使用效率,也可能减小了计算的复杂性,从而让模型在保持相同表现的同时需要更少的计算资源。
假设我们有一个机器,它的任务是将苹果和香蕉分类。最开始的机器(就像ELAN模型)可能只能根据水果的颜色区分,比如苹果是红色的,香蕉是黄色的。
后来我们升级了机器(就像升级为E-ELAN模型),让它不仅能看颜色,还能看形状。于是机器可以更准确的做出分类,即使有些苹果是黄色的,有些香蕉是绿色的,机器也能准确判断因为苹果是圆形的,香蕉是长形的。
然后我们还进行了一些调整,让机器在看颜色和形状时更加聪明。比如,机器会先看颜色,如果颜色判断不出来,就再看形状。这样机器就可以更高效地进行分类任务。
这样,我们就改进了机器,让它既能看到更多的特征,又能更聪明地使用这些特征,完成任务的效率和准确度都有所提高。
MPConv
MPConv结构由常规卷积与maxpool双路径组成,增加模型对特征的提取融合能力。
辅助头 auxiliary Head
YOLOv7在Head侧引入了辅助头(auxiliary Head)进行训练。
用辅助头参与训练时,将对模型的训练进行深度监督。
将辅助头和检测头的损失进行融合,相当于在网络高层进行局部的模型集成操作,提升模型的整体性能。
相当于是多了一个"小助手"来帮助训练。就好比你在做作业的时候,有个聪明的小伙伴在一旁提供帮助,让你的作业变得更好。
这个辅助头的出现,不仅可以提供更丰富的信息,就像是学习时多了一个角度看问题,同时也可以让这两个头一起学习,像一个团队一样互相学习互相提升。
将YOLOv5和YOLOx的正负样本分配策略相结合
YOLOv7的正负样本分配策略正是围绕着检测头(lead head)与auxiliary Head进行设计,其主要是将YOLOv5和YOLOx的正负样本分配策略相结合:
-
使用YOLOv5的正负样本分配策略分配正样本。
-
使用YOLOx的正负样本分配策略确定正样本。
正样本就像是你要找的正确答案,负样本就像是你要避免的错误答案。但是在实际情况下,我们不可能完全知道所有的答案,所以就需要区分出哪些是正确的,哪些是错误的。
YOLOv7就像一个聪明的侦探,它先用一种方法找出可能的正样本,然后用另一种方法确定这些正样本是不是真的正确。这样做的好处就像是在做选择题时,先把肯定不对的选项排除,然后再在剩下的选项里选择最合适的。
这个过程,YOLOv7还引入了另外两个新的点子。
- 第一,它会让这两个头使用一样的样本匹配方法,就像是让两个人用同样的方法做题,这样可以互相验证结果是否正确。
- 第二,它会让辅助头的标准相对宽松一些,让它可以找到更多可能的答案,然后再由主头来从中挑选出最好的答案。
这个设计就像是在学习时,你有一个小伙伴帮你做预习,然后你在小伙伴的基础上进行深入的学习和理解,一起提高你们的学习成效。
SPPSCP + 优化的PAN

SPPCSP模块是在空间金字塔池化(SPP)模块的基础上进行优化的模块。
SPP模块可提取多尺度的特征图,增强模型对于不同尺度物体的检测能力。
CSP是Cross Stage Partial结构的缩写,其可以分解特征图并行计算,减少内存消耗并提高网络性能。
在SPPCSP模块中,通过将SPP模块的输出与其之前的特征图进行concat操作,使得模型可以同时学习到深层特征和浅层特征。
PAN模块是Path Aggregation Network的缩写,融合了不同层级的feature map,PAN模块可以使得模型在进行高级语义学习的同时,也能保留低级特征。
在这里,PAN模块使用了E-ELAN(Efficient Channel Shuffle Method for Lightweight and Effective Networks)结构。
E-ELAN是通过expand、shuffle 和 merge cardinality等策略对特征图进行处理,有助于提高特征图中的信息丰富度,进一步提高网络的识别能力。
- expand策略是将特征图中的各个通道进行扩张,以增加特征的复杂度。
- shuffle策略则是对扩张的各通道进行重排,以提高特征的丰富程度。
- merge cardinality则是通过减小通道数目来减少模型的计算量,从而提高模型的计算效率。
通过以上策略,使模型在不破坏原始梯度路径的前提下提高网络学习能力。
即在不改变基础网络训练过程中梯度反向传播的流程下,提高模型的学习效果和执行效率。
SPP,全称Spatial Pyramid Pooling,是空间金字塔池化。
CSP,全称Cross Stage Partial,提出将特征一分为二,一半进入下一层,一半直接与下一层输出合并,从而达到减少计算量和增强模型性能的效果。
结合这两者,就是SPPCSP模块。
而PAN,全称Path Aggregation Network,路径聚合网络,主要起到一个信息聚合的作用。
比如对于一个对象检测任务。如果我们只使用SPPCSP,那么网络首先会使用CSP模块将特征图分解,一部分进行下一步的计算,一部分保留。
然后使用SPP模块对分解的特征图进行金字塔池化处理,从而获取多尺度的特征信息。然后将池化后的特征图和保留的特征图进行合并。这样,网络就学习到了多尺度的特征信息。
但是,如果我们再加上优化的PAN模块,就可以进一步提升模型性能。
优化后的PAN模块可以将SPPCSP的输出,以及之前每个步骤的输出进行融合。
这样,可以让网络同时学习到在不同层次上的特征信息,进一步丰富了特征表示。
YOLO v8

-
Backbone:C3结构变成C2F结构
-
Head: 耦合头变成了解耦头,将分类和检测头分离、从 Anchor-Based 换成了 Anchor-Free
-
Loss :弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner正负样本匹配、并引入了 Distribution Focal Loss(DFL)
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
-
Train:引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作、模型的训练总 epoch 数从 300 提升到了 500
C3结构变成C2F结构
C3结构:
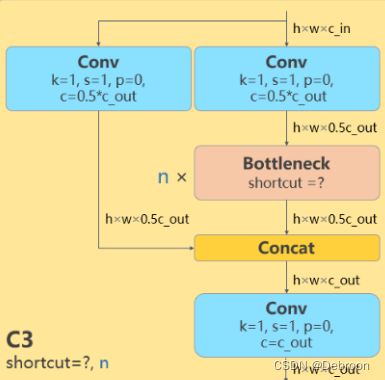
C2F结构:
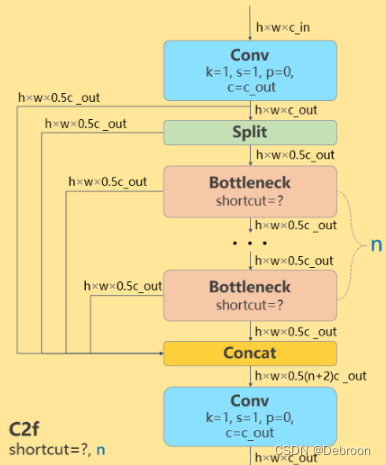
C3结构通过级联、交叉和连接的方式,将多个卷积层和池化层组合在一起。
C3结构的特点是在每个级联的层之间引入了交叉连接,可以促进多尺度特征的传递和整合,提高网络的表示能力和性能。
C2F结构通过在不同层级的特征图上进行特征融合和组合,以获得更丰富的语义信息和上下文关系。
C2F结构的特点是在网络的不同层级之间引入了跨层级的连接和信息交流,以提高目标检测的准确性和稳定性。
C3结构通过级联和交叉连接,将特征在同一级联中进行整合;而C2F结构通过跨层级连接,在不同层级的特征之间进行组合和整合。
让YOLOv8可以在保证内存轻量化的同时获得更加丰富的梯度流信息。
耦合头变成了解耦头,将分类和检测头分离
传统目标检测模型通常会使用一个综合的分支来同时处理目标的分类和位置回归任务。
而现在模型,分类和回归被解耦为两个独立的分支。分类分支用于预测目标的类别,回归分支用于预测目标的位置。
Distribution Focal Loss是一种损失函数,用于优化目标检测模型中的回归任务。
它在传统的Focal Loss基础上提出了一种积分形式的表示法,用于更准确地估计目标的位置和边界框。
这种积分形式的表示法可以更好地处理目标的不确定性和复杂性。
C3:
C2F:

如果我们在目标检测任务中,有一些物体存在重叠或者距离特别近的情况,用传统损失函数,可能会造成定位不准确的问题,尤其是在高度相似或复杂的背景中。之后解耦的思想出现,分类和定位任务分别进行,可以让模型更加注重自身任务的学习。
解耦后,检测任务用到的就是DFL,借助了分布思想,模型在计算物体的位置时,会考虑到物体位置的不确定性,而不再是简单地使用一个固定值来表示物体的位置。这就使模型能更好地处理那些位置不确定性比较大的情况,比如说物体形状不规则,或者是物体与物体之间有重叠等情况,提高了检测的准确度。
同时,对于分类任务,使用VFL,可以解决数据不平衡问题,给难分类样本更多的关注,进一步提高分类的准确性。
简单来说,通过结构解耦和相应的损失函数,使各个任务更加专注,可以解决复杂场景下的定位不准以及分类错误等问题,从而提升整体的检测性能。
损失函数 VFL + DFL + CIoU
一个head做目标识别,用Bbox Loss来衡量。bbox loss 是 CIoU和DFL。
一个head做分类,用BCE二分类交叉熵损失函数,衡量实际用的是VFL(Varifocal Loss)。
样本不均衡,正样本极少,负样本极多,需要降低负样本对 loss 的整体贡献了。
VFL独有的:
- 学习 IACS 得分( localization-aware 或 IoU-aware 的 classification score)
- 如果正样本的 gt_IoU 很高时,则对 loss 的贡献更大一些,可以让网络聚焦于那些高质量的样本上,也就是说训练高质量的正例对AP的提升比低质量的更大一些。
假设我们组织了一个寻宝比赛,选手们需要在一片森林里找到隐藏的宝藏。为了确定选手们找到宝藏的准确性,我们设定了一个评分系统 - IACS得分。如果选手能精确地找到宝藏的位置,他们将获得高分。
现在,有两种类型的线索 - 一些线索很明确,告诉你宝藏是在大树下的一个洞里(这就是我们说的高质量的样本)。还有一些线索很模糊,只告诉你宝藏在森林的某个地方(这就是我们说的低质量的样本)。
这种寻宝游戏的规则就像VFL算法的工作原理。它更倾向于使用那些更明确的线索去“寻宝”,也就是找到图片中对象的位置。因为使用这些高质量的线索,它更有可能找到准确的位置,从而得到更高的IACS分数。
所以,即使模糊的线索更多,我们的“侦探”还是会优先关注和学习那些明确的线索,这样它在未来找宝藏(识别图片中的对象)的时候,能更精确更快速。
这三个 loss 加权平均得到最终的 loss。
更好的激活函数
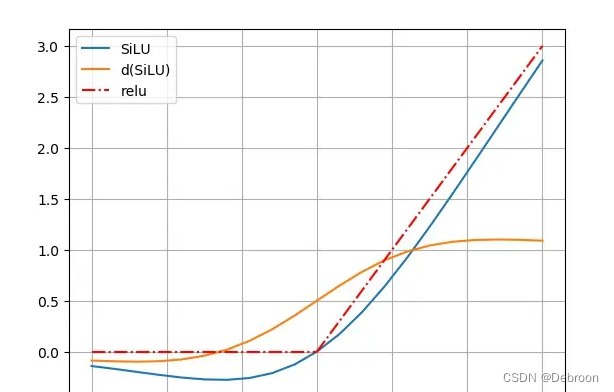
平滑,处处可导,更容易训练,比relu平滑)
x<0具有非单调性,函数值先降后增,-1以前是减函数,-1以后是增函数,对分布有重要意义。
样本匹配
首先,让我们理解下Anchor-Based方法。
这种方法的核心思路就像去钓鱼一样。
我们在海里抛出一些锚(Anchor),它们就像钩子,可以把某些鱼(即目标对象)挂住,然后再把鱼饵(样本)丢到最可能有鱼的地方。
这样我们就把搜索的范围缩小,只需要关注这些钩住的鱼。这样的方法能帮助我们减少挑选出目标的困难程度。
然而,Anchor-Based方法也有它的劣势,首先,它需要大量的计算和调节。
你可能需要抛出很多锚,甚至还需要调整锚的大小和形状,这就像针对不同的鱼类型调整鱼钩大小和鱼饵类型,这需要大量的精力和时间。
其次,还有许多超参数需要我们手动调整,比如我们需要决定什么样的鱼饵更可能吸引鱼,这个过程既耗费时间又可能不准确。
这时,Anchor-Free方法相当于我们把整个海洋视为一个整体,
我们不再专门投放某些锚去钓特定的鱼,而是直接去寻找最可能有鱼的地方。
这个方法更直接,快速,并且能达到和甚至超越基于Anchor的精度。
然后,我们设计了TaskAligned规则来更好的适应这个Anchor-Free的模型。
首先,我们希望一个好的预测模型应该可以把目标区域和背景区分得清楚,这就像我们希望能准确地知道哪些地方最可能有鱼。
其次,我们希望不重要的区域(背景)能在预测的过程中被忽略,这就像我们在探测整个海洋的时候,可以忽略那些不太可能有鱼的地方。
为了做到这一点,我们设计了一种锚点对齐标准(Alignment metric)来衡量每一个锚点预测的任务对齐水平,并集成到样本分配和损失函数里来动态的优化每个锚点的预测。
所以,到最后,我们就能建立一个有效的,能准确定位的,能忽视背景的预测模型。
这篇关于YOLO系列:YOLO v1-v8、YOLOx、PP-YOLOE、DAMO-YOLO、YOLOX-PAI 设计思路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









{kind=link}