本文主要是介绍基于V-BLAST的ML检测算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、理论基础
二、核心程序
三、测试结果
一、理论基础
MIMO系统(Multiple-Input Multiple-Output)是指在发射端和接收端分别使用多个发射天线和接收天线,使信号通过发射端与接收端的多个天线传送和接收,从而改善通信质量。它能充分利用空间资源,通过多个天线实现多发多收,在不增加频谱资源和天线发射功率的情况下,可以成倍的提高系统信道容量,显示出明显的优势、被视为下一代移动通信的核心技术。
MIMO系统却能有效地利用多径的影响来提高系统容量。系统容量是干扰受限的,不能通过增加发射功率来提高系统容量。而采用MIMO结构不需要增加发射功率就能获得很高的系统容量。因此,将MIMO技术与OFDM技术相结合是下一代无线局域网发展的趋势。在OFDM系统中,采用多发射天线实际上就是根据需要在各个子信道上应用多发射天线技术,每个子信道都对应一个多天线子系统、一个多发射天线的OFDM系统。
信道均衡技术(Channel equalization)是指为了提高衰落信道中的通信系统的传输性能而采取的一种抗衰落措施。它主要是为了消除或者是减弱宽带通信时的多径时延带来的码间串扰ISI问题。V-BLAST空间多路复用系统一种模式。这种简化了的BLAST结构同样最先由贝尔实验室提出。它采用一种直接的天线与层的对应关系,即编码后的第k个子流直接送到第k根天线,不进行数据流与天线之间对应关系的周期改变,它的数据流在时间与空间上为连续的垂直列向量,称为V-BLAST(Vertical-BLAST)。由于V-BLAST中数据子流与天线之间只是简单的对应关系,因此在检测过程中,只要知道数据来自哪根天线即可以判断其是哪一层的数据,检测过程简单。
基于V-BLAST(Vertical-Bell Labs Layered Space-Time)的最大似然(Maximum Likelihood,ML)检测算法是一种用于多天线无线通信系统中的信号检测方法。它旨在通过最大化接收信号与所有可能发送信号之间的似然函数,来确定发送信号的可能性。
在多天线通信系统中,发送端使用多个天线发送信号,接收端也使用多个天线接收信号。V-BLAST ML检测算法通过逐层解码的方式,先解调出最可能的信号分量,然后在去除已解调信号分量的基础上,继续解调下一个可能的信号分量,以此类推,直到所有信号分量都被解调。
考虑一个MIMO(多输入多输出)系统,其中发送端有N个天线,接收端有M个天线。假设H是接收信号矩阵,x是发送信号向量,n是加性高斯白噪声向量,则接收信号可以表示为:
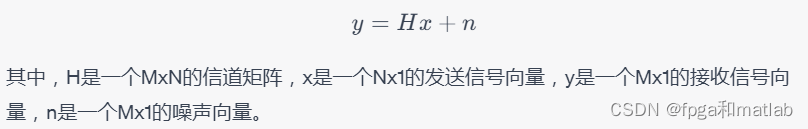
优势:
V-BLAST ML检测算法在多天线通信系统中具有一些优势:
-
逐层解码:V-BLAST算法可以通过逐层解码的方式,逐步解调出信号分量,从而减小了复杂度。
-
多路径利用:由于多天线系统可以利用信道中的多条路径,V-BLAST算法可以更有效地分离这些路径的信号。
-
高容量:V-BLAST算法在适当的天线数量和信道条件下,可以达到非常高的容量。
然而,需要注意的是,V-BLAST算法在实际应用中可能受到信道估计误差、噪声、多径衰落等因素的影响。因此,在实际部署中,可能需要结合其他技术来提高检测性能。
二、核心程序
.........................................................................
for i=1:length (snr_dB)snr(i)=10^(snr_dB(i)/10);blast_error_bit=0;mlblast_error_bit=0;mlblast1_error_bit=0;mlblast2_error_bit=0;for numm=1:2 %每一个SNR值计算多次,以增大数据量a=rand(1,a_length);for L=1:a_lengthif a(L)>0.5a(L)=1;else a(L)=0;endend %产生比特流a_mod=QAM(a_length,a); %进行调制,采用16QAM的方式a_=reshape(a_mod,Tx_n,length(a_mod)/Tx_n); %映射至四个天线端口m=1; %信号检测后输出信号的序列号,在这里对其进行初始化for ll=1:N_OFDMfor kk=N_DLRB*12:-1:1a1(kk,ll)=a_(1,(ll-1)*N_DLRB*12+abs(kk-N_DLRB*12)+1);a2(kk,ll)=a_(2,(ll-1)*N_DLRB*12+abs(kk-N_DLRB*12)+1);a3(kk,ll)=a_(3,(ll-1)*N_DLRB*12+abs(kk-N_DLRB*12)+1);a4(kk,ll)=a_(4,(ll-1)*N_DLRB*12+abs(kk-N_DLRB*12)+1); %进行资源映射a_all=[a1(kk,ll),a2(kk,ll),a3(kk,ll),a4(kk,ll)].'; %取出相同时频位置上的资源粒子,编为一组,进行信号检测sigma = 1/sqrt(2*Rx_n*snr(i)); %噪声的标准差,假设信号的能量为1awgn_noise = sigma/sqrt(2)*(randn(Rx_n,1)+j*randn(Rx_n,1)); %产生高斯白噪声H=(randn(Rx_n,Tx_n)+j*randn(Rx_n,Tx_n))/sqrt(2); %信道冲击响应矩阵r=H*a_all+awgn_noise ; %相同时频位置上接收到的数据%基于ZF的排序V-BLAST算法H=(randn(Rx_n,Tx_n)+j*randn(Rx_n,Tx_n))/sqrt(2);r=H*a_all+awgn_noise; %相同时频位置上接收到的数据mm=1:Tx_n;for ii=1:Tx_n G3=pinv(H); %滤波矩阵G_=sum(abs(G3).^2,2); [m_,ki]=min(G_); %找出功率最小的一行,该行的可靠性最高Z=G3(ki,:)*r;dec5(mm(ki),m)=quan_16QAM_1(Z); %量化判决过程 r=r-H(:,ki)*dec5(mm(ki),m);H(:,ki)=[];mm(ki)=[];end%基于ZF的有所保留的排序V-BLAST算法(1层,4个取值)mlblast_16=mlblast_qam_1(m,a_all,awgn_noise,Rx_n,Tx_n);dec6(:,m)=mlblast_16;%基于ZF的有所保留的排序V-BLAST算法(1层,2个取值)mlblast1_16=mlblast_qam_2(m,a_all,awgn_noise,Rx_n,Tx_n);dec7(:,m)=mlblast1_16;%基于ZF的有所保留的排序V-BLAST算法(1层,6个取值)mlblast2_16=mlblast_qam_3(m,a_all,awgn_noise,Rx_n,Tx_n);dec8(:,m)=mlblast2_16;m=m+1;endenddec5_=reshape(dec5,1,length(a_mod));dec_blast_zf2=demod_QAM(dec5_); %解调过程,对应于QPSKdec6__=reshape(dec6,1,length(a_mod));dec_mlblast=demod_QAM(dec6__); %解调过程,对应于QPSKdec7__=reshape(dec7,1,length(a_mod));dec_mlblast1=demod_QAM(dec7__); %解调过程,对应于QPSKdec8__=reshape(dec8,1,length(a_mod));dec_mlblast2=demod_QAM(dec8__); %解调过程,对应于QPSKerr_num_blast_zf2=error_count(a,dec_blast_zf2); %统计基于MMSE的V-BLAST算法下错误比特个数err_num_mlblast=error_count(a,dec_mlblast); %统计ZF算法下错误比特个数err_num_mlblast1=error_count(a,dec_mlblast1); %统计ZF算法下错误比特个数err_num_mlblast2=error_count(a,dec_mlblast2); %统计ZF算法下错误比特个数blast_error_bit=blast_error_bit+err_num_blast_zf2;mlblast_error_bit=mlblast_error_bit+err_num_mlblast;mlblast1_error_bit=mlblast1_error_bit+err_num_mlblast1;mlblast2_error_bit=mlblast2_error_bit+err_num_mlblast2;enderr_ber_blast_zf2(i)=blast_error_bit/(length(a)*numm) %统计BLAST算法下错误比特率 err_ber_mlblast(i)=mlblast_error_bit/(length(a)*numm)err_ber_mlblast1(i)=mlblast1_error_bit/(length(a)*numm)err_ber_mlblast2(i)=mlblast2_error_bit/(length(a)*numm)
end
up62三、测试结果

这篇关于基于V-BLAST的ML检测算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









